
 Technologie-Peripheriegeräte
KI
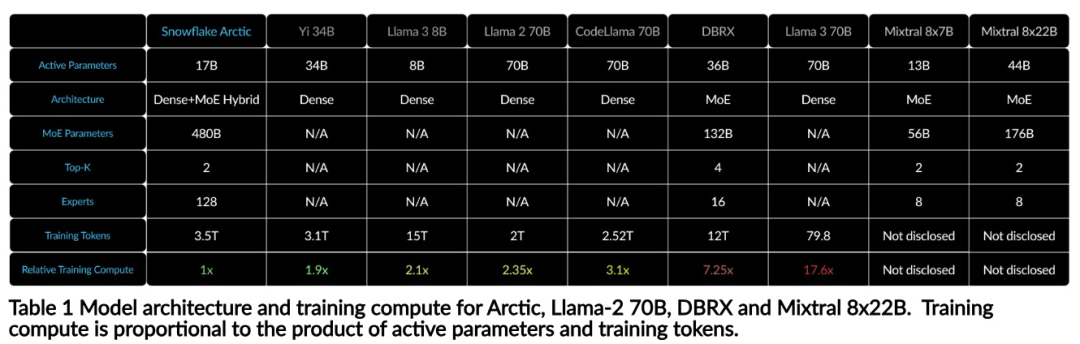
Mit nur 1/17 der Schulungskosten von Llama3, Snowflake Open-Source-128x3B-MoE-Modell
Technologie-Peripheriegeräte
KI
Mit nur 1/17 der Schulungskosten von Llama3, Snowflake Open-Source-128x3B-MoE-Modell
Mit nur 1/17 der Schulungskosten von Llama3, Snowflake Open-Source-128x3B-MoE-Modell

Snowflake schließt sich dem LLM-Nahkampf an.
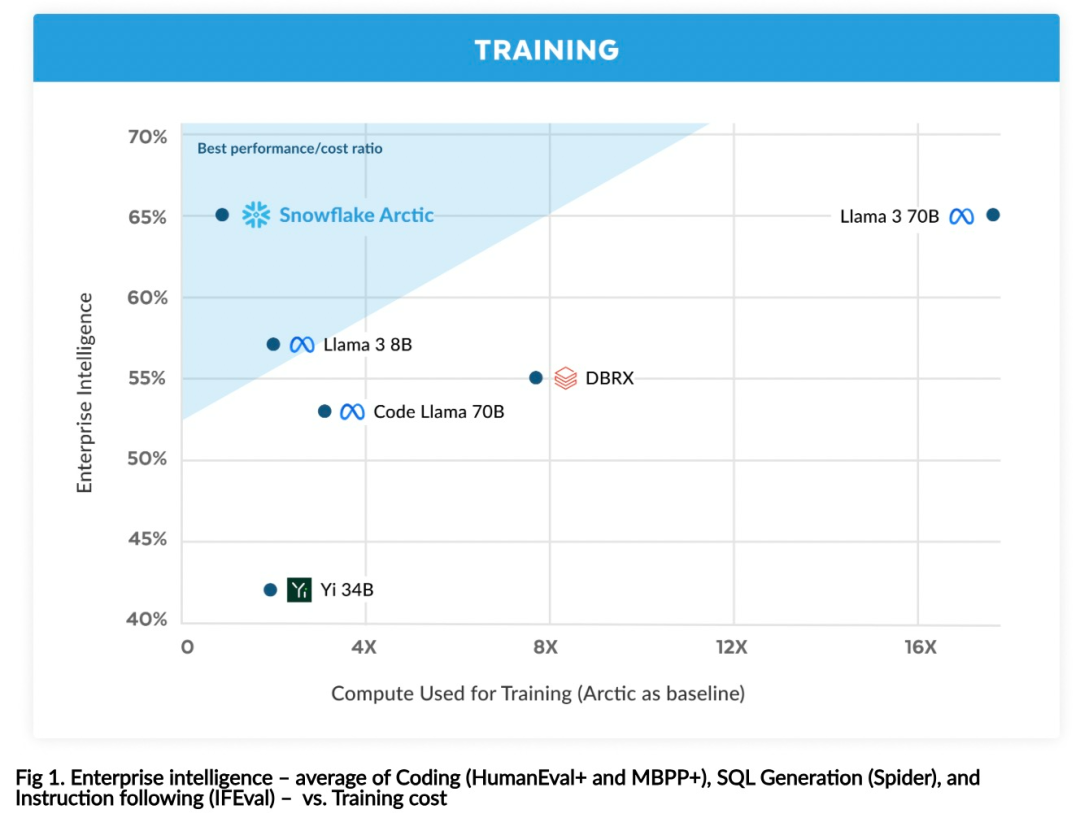
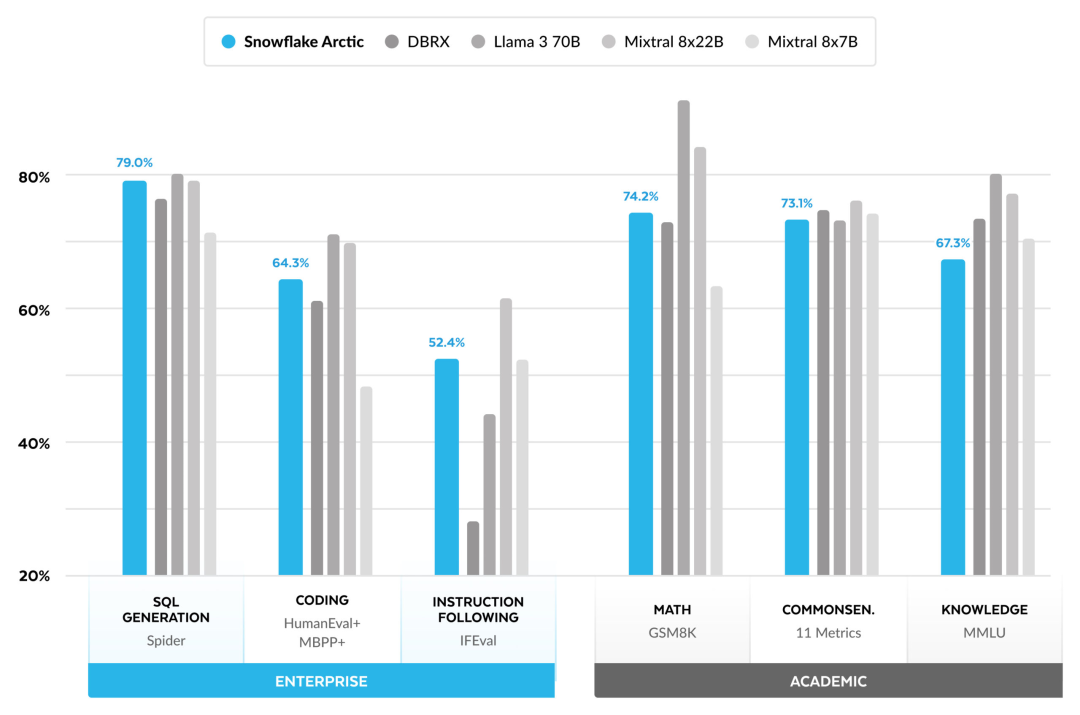
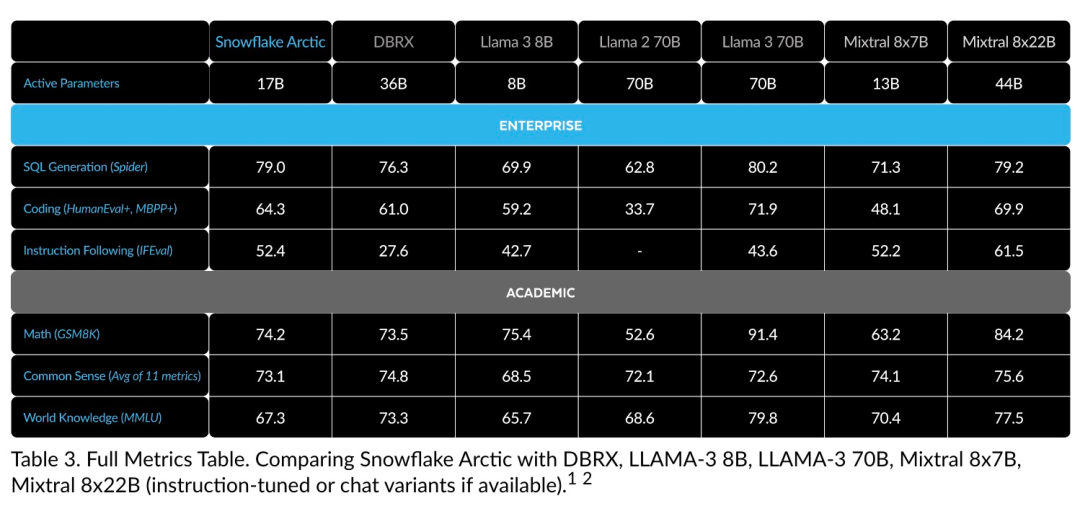
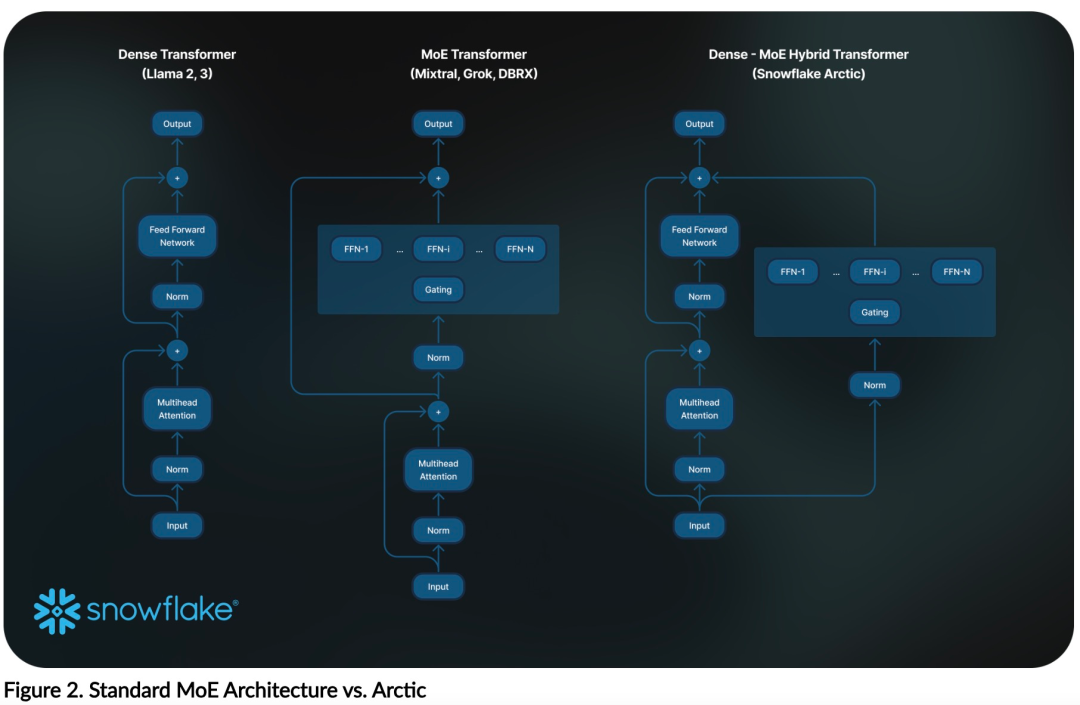
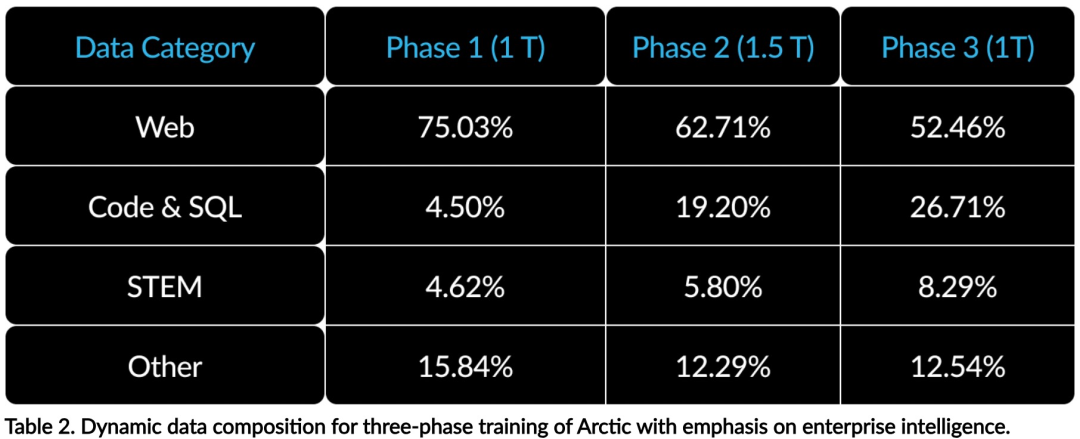
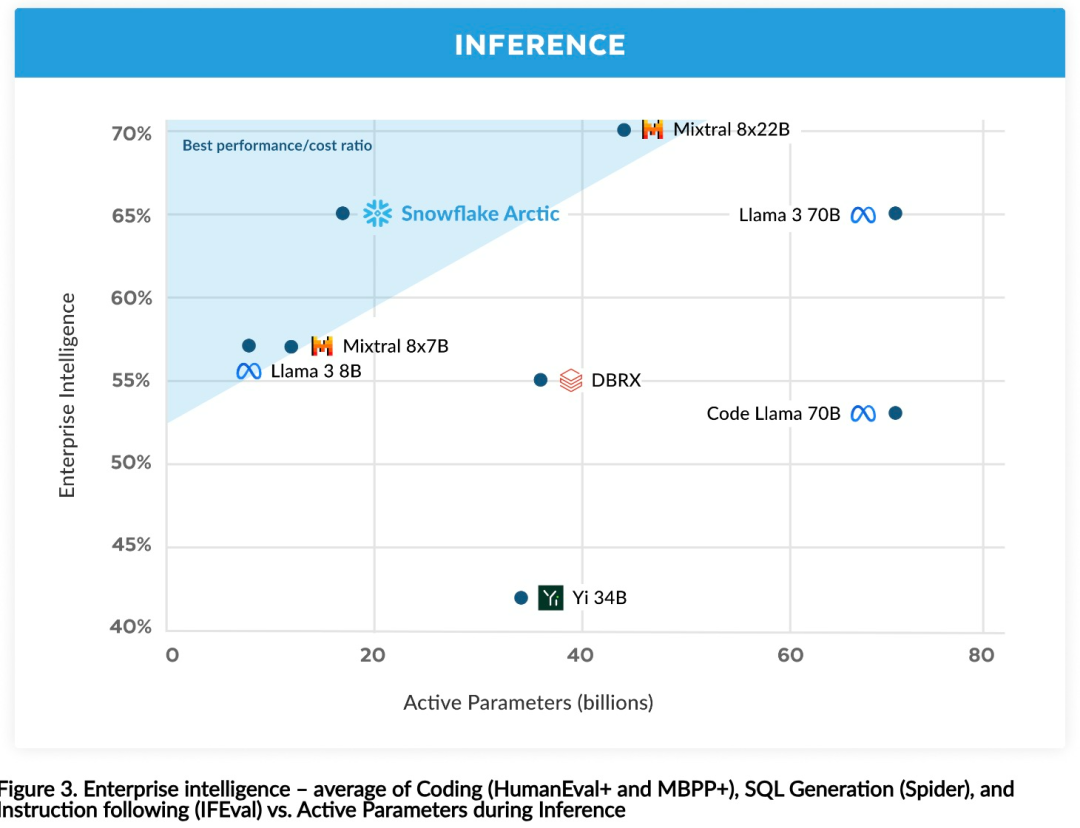
Effiziente Intelligenz: Arctic schneidet bei Unternehmensaufgaben wie SQL-Generierung, Programmierung und Befehlsverfolgung gut ab. , sogar vergleichbar mit Open-Source-Modellen, die mit höheren Rechenkosten trainiert wurden. Arctic setzt neue Maßstäbe für kostengünstige Schulungen und ermöglicht es Snowflake-Kunden, qualitativ hochwertige, maßgeschneiderte Modelle zu geringen Kosten für ihre Unternehmensanforderungen zu erstellen. Open Source: Arctic übernimmt die Apache 2.0-Lizenz und bietet offenen Zugriff auf Gewichte und Code, und Snowflake wird auch alle Datenlösungen und Forschungsergebnisse als Open Source bereitstellen.
Das obige ist der detaillierte Inhalt vonMit nur 1/17 der Schulungskosten von Llama3, Snowflake Open-Source-128x3B-MoE-Modell. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1384
1384
 52
52

 So setzen Sie das CGI -Verzeichnis in Apache
Apr 13, 2025 pm 01:18 PM
So setzen Sie das CGI -Verzeichnis in Apache
Apr 13, 2025 pm 01:18 PM
Um ein CGI-Verzeichnis in Apache einzurichten, müssen Sie die folgenden Schritte ausführen: Erstellen Sie ein CGI-Verzeichnis wie "CGI-bin" und geben Sie Apache-Schreibberechtigungen. Fügen Sie den Block "scriptalias" -Richtungsblock in die Apache-Konfigurationsdatei hinzu, um das CGI-Verzeichnis der URL "/cgi-bin" zuzuordnen. Starten Sie Apache neu.
 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 So überprüfen Sie die Debian OpenSSL -Konfiguration
Apr 12, 2025 pm 11:57 PM
So überprüfen Sie die Debian OpenSSL -Konfiguration
Apr 12, 2025 pm 11:57 PM
In diesem Artikel werden verschiedene Methoden eingeführt, um die OpenSSL -Konfiguration des Debian -Systems zu überprüfen, um den Sicherheitsstatus des Systems schnell zu erfassen. 1. Bestätigen Sie zuerst die OpenSSL -Version und stellen Sie sicher, ob OpenSSL installiert wurde und Versionsinformationen. Geben Sie den folgenden Befehl in das Terminal ein: Wenn OpenSslversion nicht installiert ist, fordert das System einen Fehler auf. 2. Zeigen Sie die Konfigurationsdatei an. Die Hauptkonfigurationsdatei von OpenSSL befindet sich normalerweise in /etc/ssl/opensl.cnf. Sie können einen Texteditor (z. B. Nano) verwenden: Sudonano/etc/ssl/openSSL.cnf Diese Datei enthält wichtige Konfigurationsinformationen wie Schlüssel-, Zertifikatpfad- und Verschlüsselungsalgorithmus. 3.. Verwenden Sie OPE
 So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
In diesem Artikel wird erläutert, wie die Leistung der Website verbessert wird, indem Apache -Protokolle im Debian -System analysiert werden. 1. Log -Analyse -Basics Apache Protokoll Datensätze Die detaillierten Informationen aller HTTP -Anforderungen, einschließlich IP -Adresse, Zeitstempel, URL, HTTP -Methode und Antwortcode. In Debian -Systemen befinden sich diese Protokolle normalerweise in /var/log/apache2/access.log und /var/log/apache2/error.log verzeichnis. Das Verständnis der Protokollstruktur ist der erste Schritt in der effektiven Analyse. 2. Tool mit Protokollanalyse Mit einer Vielzahl von Tools können Apache -Protokolle analysiert: Befehlszeilen -Tools: GREP, AWK, SED und andere Befehlszeilen -Tools.
 So löschen Sie mehr als Servernamen von Apache
Apr 13, 2025 pm 01:09 PM
So löschen Sie mehr als Servernamen von Apache
Apr 13, 2025 pm 01:09 PM
Um eine zusätzliche Servername -Anweisung von Apache zu löschen, können Sie die folgenden Schritte ausführen: Identifizieren und löschen Sie die zusätzliche Servername -Richtlinie. Starten Sie Apache neu, damit die Änderungen wirksam werden. Überprüfen Sie die Konfigurationsdatei, um Änderungen zu überprüfen. Testen Sie den Server, um sicherzustellen, dass das Problem behoben ist.
 So sehen Sie Ihre Apache -Version an
Apr 13, 2025 pm 01:15 PM
So sehen Sie Ihre Apache -Version an
Apr 13, 2025 pm 01:15 PM
Es gibt 3 Möglichkeiten, die Version auf dem Apache -Server anzuzeigen: Über die Befehlszeile (apachect -v- oder apache2CTL -v) überprüfen Sie die Seite Serverstatus (http: // & lt; Server -IP- oder Domänenname & GT;/Server -Status) oder die Apache -Konfigurationsdatei (Serversion: Apache/& lt; Versionsnummer & GT;).).
 So optimieren Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:15 PM
So optimieren Sie die CentOS -HDFS -Konfiguration
Apr 14, 2025 pm 07:15 PM
Verbesserung der HDFS -Leistung bei CentOS: Ein umfassender Optimierungshandbuch zur Optimierung von HDFs (Hadoop Distributed Dateisystem) auf CentOS erfordert eine umfassende Berücksichtigung der Hardware-, Systemkonfigurations- und Netzwerkeinstellungen. Dieser Artikel enthält eine Reihe von Optimierungsstrategien, mit denen Sie die HDFS -Leistung verbessern können. 1. Hardware -Upgrade und Auswahlressourcenerweiterung: Erhöhen Sie die CPU-, Speicher- und Speicherkapazität des Servers so weit wie möglich. Hochleistungs-Hardware: Übernimmt Hochleistungs-Netzwerkkarten und -Schalter, um den Netzwerkdurchsatz zu verbessern. 2. Systemkonfiguration Fine-Tuning-Kernel-Parameteranpassung: Modify /etc/sysctl.conf Datei, um die Kernelparameter wie TCP-Verbindungsnummer, Dateihandelsnummer und Speicherverwaltung zu optimieren. Passen Sie beispielsweise den TCP -Verbindungsstatus und die Puffergröße an
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
