
 Technologie-Peripheriegeräte
KI
Der multimodale große 8B-Text-Index ähnelt GPT4V. Byte, Huashan und Huake haben gemeinsam TextSquare vorgeschlagen
Technologie-Peripheriegeräte
KI
Der multimodale große 8B-Text-Index ähnelt GPT4V. Byte, Huashan und Huake haben gemeinsam TextSquare vorgeschlagen
Der multimodale große 8B-Text-Index ähnelt GPT4V. Byte, Huashan und Huake haben gemeinsam TextSquare vorgeschlagen


Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, reichen Sie bitte einen Artikel ein oder wenden Sie sich an die Berichts-E-Mail-Adresse. E-Mail-Adresse: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
In letzter Zeit haben multimodale große Modelle (MLLM) erhebliche Fortschritte im Bereich der textzentrierten VQA gemacht, insbesondere mehrere Closed-Source-Modelle wie GPT4V und Gemini, die in einigen Aspekten sogar eine übermenschliche Leistung zeigen der Fähigkeit. Die Leistung von Open-Source-Modellen liegt jedoch immer noch weit hinter Closed-Source-Modellen. In letzter Zeit haben viele bahnbrechende Studien, wie zum Beispiel: MonKey, LLaVAR, TG-Doc, ShareGPT4V usw., begonnen, sich auf das Problem unzureichender Anweisungen zu konzentrieren. Tuning-Daten. Obwohl diese Bemühungen bemerkenswerte Ergebnisse erzielt haben, gibt es immer noch einige Probleme, da Bildbeschreibungsdaten und VQA-Daten unterschiedlichen Domänen angehören, und es gibt Inkonsistenzen in der Granularität und dem Umfang der Darstellung von Bildinhalten. Darüber hinaus verhindert die relativ geringe Größe synthetischer Daten, dass MLLM sein volles Potenzial ausschöpfen kann.

Papiertitel: TextSquare: Scaling up Text-Centric Visual Instruction Tuning
Papieradresse: https://arxiv.org/abs/2404.12803
Um dies zu reduzieren
VQA-Datengenerierung
Square+ Strategiemethode umfasst vier Schritte: Selbstbefragung, Antwort, Begründung und Selbstbewertung. Die Selbstbefragung nutzt die Fähigkeiten von MLLM zur Text-Bild-Analyse und zum Verstehen, um Fragen im Zusammenhang mit dem Textinhalt im Bild zu generieren. Self-Answering liefert Antworten auf diese Fragen mithilfe verschiedener Aufforderungstechniken wie CoT und Few-Shot. Self-Reasoning nutzt die leistungsstarken Argumentationsfunktionen von MLLMs, um den Argumentationsprozess hinter dem Modell zu generieren. Die Selbstbewertung verbessert die Datenqualität und reduziert Verzerrungen, indem Fragen auf Gültigkeit, Relevanz für Bildtextinhalte und Antwortgenauigkeit bewertet werden. S Abbildung 1: Vergleich des Closed-Source- und des Open-Source-Modells von TextSquare und Advanced, und das durchschnittliche Ranking bei Benchmark für 10 Texte übertraf GPT4V (Rang 2,2 vs. 2,4). Die Forscher sammelten einen vielfältigen Satz von Bildern, die eine große Textmenge enthielten Erstellen Sie Square-10M aus verschiedenen öffentlichen Quellen, einschließlich Naturszenen, Diagrammen, Formularen, Quittungen, Büchern, PPT, PDF usw., und trainieren Sie auf der Grundlage dieses Datensatzes das auf Textverständnis ausgerichtete MLLM TextSquare-8B.
Wie in Abbildung 1 gezeigt, kann TextSquare-8B bei mehreren Benchmarks Ergebnisse erzielen, die mit GPT4V und Gemini vergleichbar oder besser sind, und übertrifft andere Open-Source-Modelle deutlich. TextSquare-Experimente bestätigten den positiven Einfluss von Inferenzdaten auf die VQA-Aufgabe und demonstrierten deren Fähigkeit, die Modellleistung zu verbessern und gleichzeitig Halluzinationen zu reduzieren. 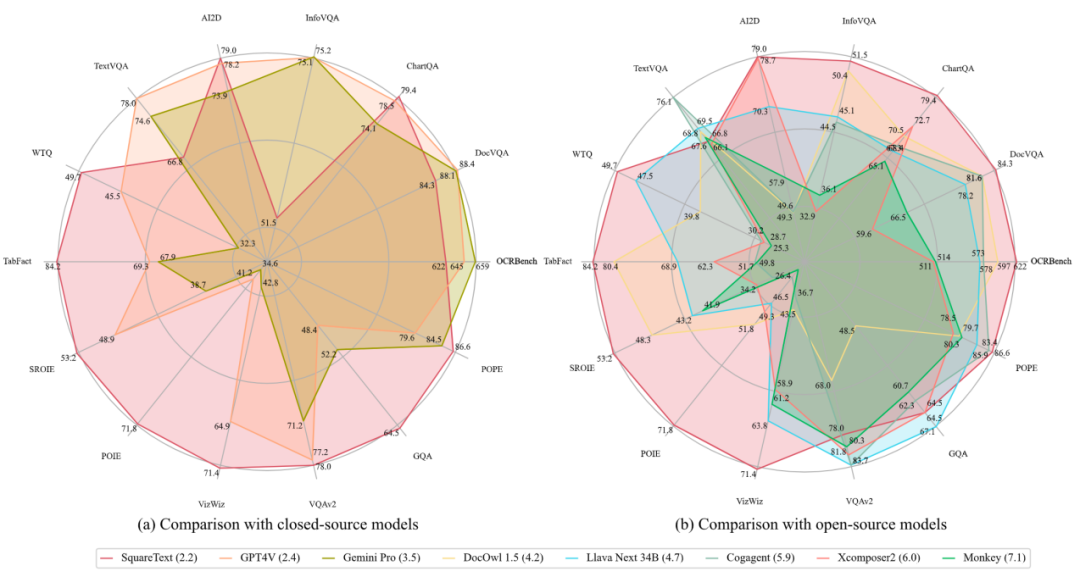
Das Hauptziel der Datenerfassungsstrategie besteht darin, ein breites Spektrum realer, textreicher Szenarien abzudecken. Zu diesem Zweck sammelten die Forscher 3,8 Millionen textreiche Bilder. Diese Bilder weisen unterschiedliche Merkmale auf. Diagramme und Tabellen konzentrieren sich beispielsweise auf Textelemente mit dichten statistischen Informationen. PPTs, Screenshots und WebImages sind für die Interaktion zwischen Text und hervorgehobenen visuellen Informationen konzipiert mit detailliertem und dichtem Text; Straßenansichten sind von Naturszenen abgeleitet. Die gesammelten Bilder bilden eine Abbildung von Textelementen in der realen Welt und bilden die Grundlage für die Untersuchung textzentrierter VQA.
Datengenerierung
Forscher nutzen die multimodalen Verständnisfunktionen von Gemini Pro, um Bilder aus bestimmten Datenquellen auszuwählen und VQA- und Inferenzkontextpaare über drei Stufen der Selbstbefragung, Selbstbeantwortung und Selbstinferenz zu generieren.
Selbstfrage: In dieser Phase werden einige Eingabeaufforderungen gegeben. Basierend auf diesen Eingabeaufforderungen führt Gemini Pro eine umfassende Analyse des Bildes durch und generiert auf der Grundlage des Verständnisses einige aussagekräftige Fragen. Da die Fähigkeit von allgemeinem MLLM, Textelemente zu verstehen, normalerweise schwächer ist als die von visuellen Modellen, verarbeiten wir den extrahierten Text mithilfe eines speziellen OCR-Modells zur Eingabeaufforderung vor.
Selbstbeantwortung: Gemini Pro verwendet Chain of Thought (CoT) und Few-Shot-Prompting (Few-Shot-Prompting) sowie andere Technologien, um Fragen zu generieren, um kontextbezogene Informationen anzureichern und die Zuverlässigkeit der generierten Antworten zu verbessern.
Selbstbegründung: In dieser Phase werden detaillierte Gründe für die Antwort generiert, wodurch Gemini Pro gezwungen wird, mehr über den Zusammenhang zwischen der Frage und den visuellen Elementen nachzudenken, wodurch Illusionen reduziert und genaue Antworten verbessert werden.
Datenfilterung
Während Selbstbefragung, Antworten und Argumentation effektiv sind, können die generierten Bild-Text-Paare mit illusorischem Inhalt, bedeutungslosen Fragen und falschen Antworten konfrontiert werden. Daher entwerfen wir Filterregeln basierend auf den Bewertungsfähigkeiten von LLM, um hochwertige VQA-Paare auszuwählen.
Selbstbewertung fordert Gemini Pro und andere MLLMs auf, festzustellen, ob die generierten Fragen sinnvoll sind und ob die Antworten ausreichen, um das Problem richtig zu lösen.
Multi-Prompt-Konsistenz Zusätzlich zur direkten Auswertung der generierten Inhalte fügen Forscher bei der Datengenerierung auch manuell Eingabeaufforderungen und Kontextraum hinzu. Ein korrektes und aussagekräftiges VQA-Paar sollte semantisch konsistent sein, wenn unterschiedliche Eingabeaufforderungen bereitgestellt werden.
Multi-Kontext-Konsistenz Die Forscher verifizierten das VQA-Paar weiter, indem sie vor der Frage unterschiedliche Kontextinformationen vorbereiteten.
TextSquare-8B
TextSquare-8B basiert auf der Modellstruktur von InternLM-Xcomposer2, einschließlich des visuellen Encoders von CLIP ViT-L-14-336, und die Bildauflösung wird basierend auf weiter auf 700 erhöht InternLM2-7B-ChatSFT Großes Sprachmodell LLM; ein Brückenprojektor, der visuelle und Text-Tokens ausrichtet.
Das Training von TextSquare-8B umfasst drei SFT-Stufen:
In der ersten Stufe wird das Modell mit vollständigen Parametern (Vision Encoder, Projektor, LLM) bei einer Auflösung von 490 verfeinert.
In der zweiten Stufe wird die Eingabeauflösung auf 700 erhöht und nur der Vision Encoder wird darauf trainiert, sich an die Auflösungsänderung anzupassen.
In der dritten Stufe erfolgt die weitere Feinabstimmung der Parameter mit einer Auflösung von 700.
TextSquare bestätigt, dass basierend auf dem Square-10M-Datensatz ein Modell mit 8B-Parametern und normalgroßer Bildauflösung eine bessere Leistung bei textzentrierter VQA erzielen kann als die meisten MLLMs, sogar Closed-Source-Modelle (GPT4V, Gemini Pro).
Experimentelle Ergebnisse
Abbildung 4(a) zeigt, dass TextSquare über einfache arithmetische Funktionen verfügt. Abbildung 4(b) zeigt die Fähigkeit, Textinhalte zu verstehen und eine ungefähre Position in dichtem Text anzugeben. Abbildung 4(c) zeigt die Fähigkeit von TextSquare, Tabellenstrukturen zu verstehen.

MLLM Benchmark
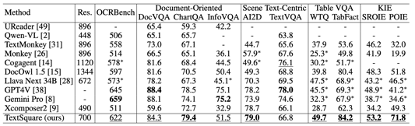
Dokumentorientierter Benchmark In der Dokumentenszene VQA Benckmark (DocVQA, ChartQA, InfographicVQA) beträgt die durchschnittliche Verbesserung 3,5 %, besser als bei allen Open-Source-Modellen, In den ChartQA-Daten liegt die Auflösung etwas höher als bei GPT4V und Gemini Pro, was kleiner ist als bei den meisten dokumentenorientierten MLLM. Wenn die Auflösung weiter verbessert wird, wird sich meines Erachtens auch die Modellleistung weiter verbessern . Monkey hat das bewiesen.
Scene Text-centric Benchmark Der VQA-Benchmark (TextVQA, AI2D) für natürliche Szenen hat SOTA-Ergebnisse erzielt, es gibt jedoch keine wesentliche Verbesserung im Vergleich zum Basis-Xcomposer2. Dies kann daran liegen, dass Xcomposer2 qualitativ hochwertige In- Domäne Die Daten sind vollständig optimiert.
Tabellen-VQA-Benchmark Im VQA-Benchmark (WTQ, TabFact) der Tabellenszene wurden Ergebnisse erzielt, die die von GPT4V und Gemini Pro weit übertreffen und jeweils andere SOTA-Modelle um 3 % übertreffen.
Textzentrierter KIE-Benchmark Extrahieren Sie die Schlüsselinformationen des Textzentrums aus dem KIE-Aufgaben-Benchmark (SROIE, POIE), konvertieren Sie die KIE-Aufgabe in eine VQA-Aufgabe und erzielen Sie die beste Leistung in beiden Datensätzen mit einem durchschnittliche Verbesserung von 14,8 %.
OCRBench Einschließlich 29 OCR-bezogener Bewertungsaufgaben wie Texterkennung, Formelerkennung, textzentriertes VQA, KIE usw. erzielte es die beste Leistung des Open-Source-Modells und wurde zum ersten 10B-Parameterwert Erreiche 600 Punkte Modell.
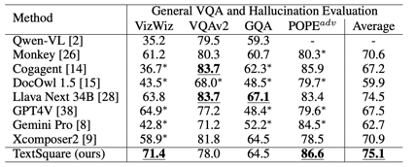
Allgemeiner VQA- und Halluzinationsbewertungs-Benchmark Im Vergleich zu Xconposer2 weist TextSquare keine signifikante Verschlechterung auf und behält immer noch die beste Leistung im allgemeinen VQA-Benchmark (VizWiz VQAv2, GQA, VisWiz und POPE). signifikante Leistung, 3,6 % höher als die besten Methoden, was die Wirksamkeit der Methode bei der Linderung von Modellhalluzinationen unterstreicht.
Ablationsexperiment

TextSquare weist in jedem Benchmark eine durchschnittliche Verbesserung von 7,7 % im Vergleich zu Xcomposer2 auf.
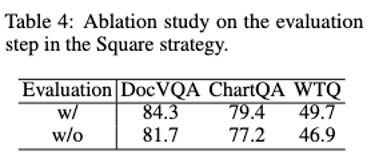
Nach dem Hinzufügen der Selbstbewertung wurde die Modellleistung erheblich verbessert.
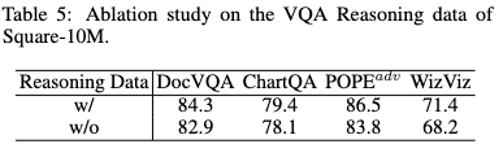
Das Hinzufügen von Inferenzdaten kann dazu beitragen, die Leistung erheblich zu verbessern und die Entstehung von Halluzinationen zu reduzieren.
Beziehung zwischen Datenskala und Konvergenzverlust und Modellleistung
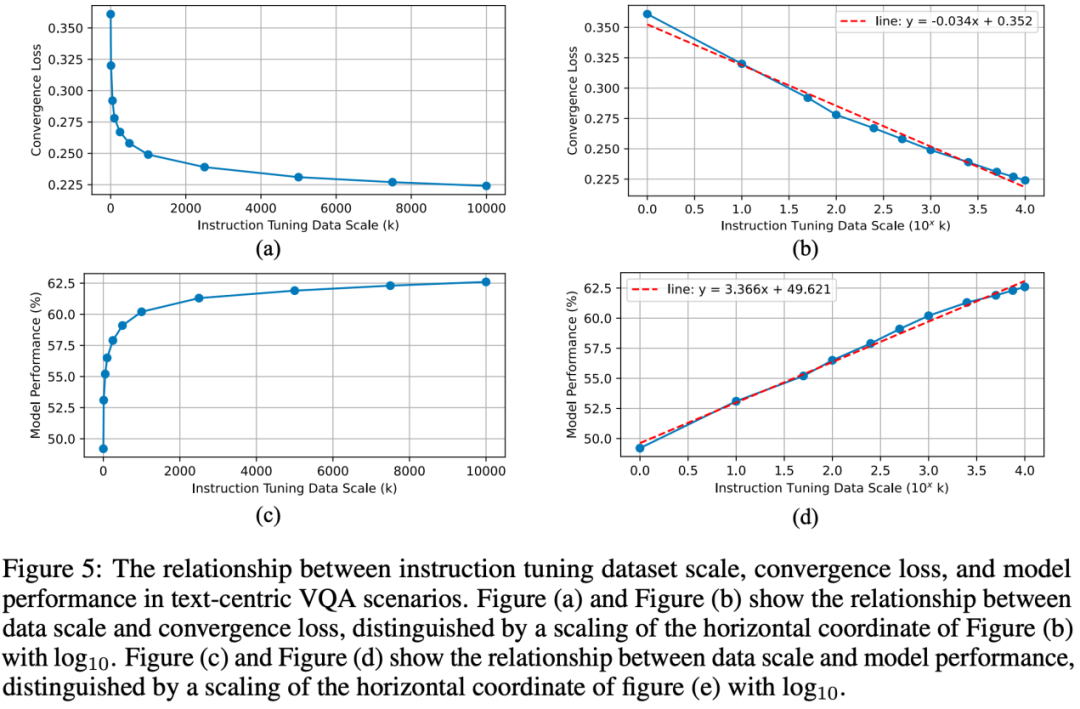
Mit zunehmender Datenskala nimmt der Verlust des Modells weiter ab und die Abnahmerate verlangsamt sich allmählich. Die Beziehung zwischen Konvergenzverlust und Befehlsskalierungsdaten nähert sich einer logarithmischen Funktion an.
Mit dem Wachstum der Befehlsoptimierungsdaten wird die Leistung des Modells immer besser, aber die Wachstumsrate verlangsamt sich weiter und entspricht in etwa der logarithmischen Funktion.
Im Allgemeinen gibt es in textzentrierten VQA-Szenarien ein entsprechendes Skalierungsgesetz in der Befehlsanpassungsphase, in dem die Modellleistung proportional zum Logarithmus der Datenskalierung ist, was die Konstruktion potenziell größerer Datensätze leiten und Modelle vorhersagen kann Leistung.
Zusammenfassung
In diesem Artikel schlugen die Forscher eine Square-Strategie zum Aufbau eines hochwertigen textzentrierten Befehlsoptimierungsdatensatzes (Square-10M) vor. Mithilfe dieses Datensatzes schnitt TextSquare-8B bei mehreren Benchmarks gut ab erreicht eine mit GPT4V vergleichbare Leistung und übertrifft kürzlich veröffentlichte Open-Source-Modelle bei verschiedenen Benchmarks deutlich.
Darüber hinaus leiteten die Forscher den Zusammenhang zwischen der Größe des Befehlsanpassungsdatensatzes, dem Konvergenzverlust und der Modellleistung ab, um den Weg für den Aufbau größerer Datensätze zu ebnen, und bestätigten, dass die Quantität und Qualität der Daten für die Modellleistung von entscheidender Bedeutung sind.
Abschließend wiesen die Forscher darauf hin, dass es als vielversprechende Forschungsrichtung gilt, die Quantität und Qualität der Daten weiter zu verbessern, um die Kluft zwischen Open-Source-Modellen und führenden Modellen zu verringern.
Das obige ist der detaillierte Inhalt vonDer multimodale große 8B-Text-Index ähnelt GPT4V. Byte, Huashan und Huake haben gemeinsam TextSquare vorgeschlagen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Der Autor von ControlNet hat einen weiteren Hit! Der gesamte Prozess der Generierung eines Gemäldes aus einem Bild, der in zwei Tagen 1,4.000 Sterne verdient
Jul 17, 2024 am 01:56 AM
Es ist ebenfalls ein Tusheng-Video, aber PaintsUndo ist einen anderen Weg gegangen. ControlNet-Autor LvminZhang begann wieder zu leben! Dieses Mal ziele ich auf den Bereich der Malerei. Das neue Projekt PaintsUndo hat nicht lange nach seinem Start 1,4.000 Sterne erhalten (die immer noch wahnsinnig steigen). Projektadresse: https://github.com/lllyasviel/Paints-UNDO Bei diesem Projekt gibt der Benutzer ein statisches Bild ein, und PaintsUndo kann Ihnen dabei helfen, automatisch ein Video des gesamten Malprozesses zu erstellen, vom Linienentwurf bis zum fertigen Produkt . Während des Zeichenvorgangs sind die Linienänderungen erstaunlich. Das Endergebnis des Videos ist dem Originalbild sehr ähnlich: Schauen wir uns eine vollständige Zeichnung an.
 Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die agentenlose Lösung von UIUC steht ganz oben auf der Liste der Open-Source-KI-Softwareentwickler und löst problemlos echte Programmierprobleme im SWE-Bench
Jul 17, 2024 pm 10:02 PM
Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com Die Autoren dieses Artikels stammen alle aus dem Team von Lehrer Zhang Lingming an der University of Illinois in Urbana-Champaign, darunter: Steven Code Repair; Doktorand im vierten Jahr, Forscher
 Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Posthume Arbeit des OpenAI Super Alignment Teams: Zwei große Modelle spielen ein Spiel und die Ausgabe wird verständlicher
Jul 19, 2024 am 01:29 AM
Wenn die Antwort des KI-Modells überhaupt unverständlich ist, würden Sie es wagen, sie zu verwenden? Da maschinelle Lernsysteme in immer wichtigeren Bereichen eingesetzt werden, wird es immer wichtiger zu zeigen, warum wir ihren Ergebnissen vertrauen können und wann wir ihnen nicht vertrauen sollten. Eine Möglichkeit, Vertrauen in die Ausgabe eines komplexen Systems zu gewinnen, besteht darin, vom System zu verlangen, dass es eine Interpretation seiner Ausgabe erstellt, die für einen Menschen oder ein anderes vertrauenswürdiges System lesbar ist, d. h. so vollständig verständlich, dass mögliche Fehler erkannt werden können gefunden. Um beispielsweise Vertrauen in das Justizsystem aufzubauen, verlangen wir von den Gerichten, dass sie klare und lesbare schriftliche Stellungnahmen abgeben, die ihre Entscheidungen erläutern und stützen. Für große Sprachmodelle können wir auch einen ähnlichen Ansatz verfolgen. Stellen Sie bei diesem Ansatz jedoch sicher, dass das Sprachmodell generiert wird
 Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Axiomatisches Training ermöglicht es LLM, kausales Denken zu erlernen: Das 67-Millionen-Parameter-Modell ist vergleichbar mit der Billionen-Parameter-Ebene GPT-4
Jul 17, 2024 am 10:14 AM
Zeigen Sie LLM die Kausalkette und es lernt die Axiome. KI hilft Mathematikern und Wissenschaftlern bereits bei der Forschung. Beispielsweise hat der berühmte Mathematiker Terence Tao wiederholt seine Forschungs- und Forschungserfahrungen mit Hilfe von KI-Tools wie GPT geteilt. Damit KI in diesen Bereichen konkurrenzfähig sein kann, sind starke und zuverlässige Fähigkeiten zum kausalen Denken unerlässlich. Die in diesem Artikel vorgestellte Forschung ergab, dass ein Transformer-Modell, das auf die Demonstration des kausalen Transitivitätsaxioms für kleine Graphen trainiert wurde, auf das Transitivitätsaxiom für große Graphen verallgemeinern kann. Mit anderen Worten: Wenn der Transformer lernt, einfache kausale Überlegungen anzustellen, kann er für komplexere kausale Überlegungen verwendet werden. Der vom Team vorgeschlagene axiomatische Trainingsrahmen ist ein neues Paradigma zum Erlernen des kausalen Denkens auf der Grundlage passiver Daten, nur mit Demonstrationen
 arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
arXiv-Artikel können als „Barrage' gepostet werden, die Diskussionsplattform von Stanford alphaXiv ist online, LeCun gefällt es
Aug 01, 2024 pm 05:18 PM
Prost! Wie ist es, wenn es bei einer Papierdiskussion auf Worte ankommt? Kürzlich haben Studenten der Stanford University alphaXiv erstellt, ein offenes Diskussionsforum für arXiv-Artikel, das es ermöglicht, Fragen und Kommentare direkt zu jedem arXiv-Artikel zu posten. Website-Link: https://alphaxiv.org/ Tatsächlich ist es nicht erforderlich, diese Website speziell zu besuchen. Ändern Sie einfach arXiv in einer beliebigen URL in alphaXiv, um den entsprechenden Artikel direkt im alphaXiv-Forum zu öffnen: Sie können die Absätze darin genau lokalisieren das Papier, Satz: Im Diskussionsbereich auf der rechten Seite können Benutzer Fragen stellen, um dem Autor Fragen zu den Ideen und Details des Papiers zu stellen. Sie können beispielsweise auch den Inhalt des Papiers kommentieren, wie zum Beispiel: „Gegeben an.“
 Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Ein bedeutender Durchbruch in der Riemann-Hypothese! Tao Zhexuan empfiehlt dringend neue Arbeiten vom MIT und Oxford, und der 37-jährige Fields-Medaillengewinner nahm daran teil
Aug 05, 2024 pm 03:32 PM
Kürzlich gelang der Riemann-Hypothese, die als eines der sieben großen Probleme des Jahrtausends bekannt ist, ein neuer Durchbruch. Die Riemann-Hypothese ist ein sehr wichtiges ungelöstes Problem in der Mathematik, das sich auf die genauen Eigenschaften der Verteilung von Primzahlen bezieht (Primzahlen sind Zahlen, die nur durch 1 und sich selbst teilbar sind, und sie spielen eine grundlegende Rolle in der Zahlentheorie). In der heutigen mathematischen Literatur gibt es mehr als tausend mathematische Thesen, die auf der Aufstellung der Riemann-Hypothese (oder ihrer verallgemeinerten Form) basieren. Mit anderen Worten: Sobald die Riemann-Hypothese und ihre verallgemeinerte Form bewiesen sind, werden diese mehr als tausend Sätze als Theoreme etabliert, die einen tiefgreifenden Einfluss auf das Gebiet der Mathematik haben werden, und wenn sich die Riemann-Hypothese als falsch erweist, dann unter anderem Auch diese Sätze werden teilweise ihre Gültigkeit verlieren. Neuer Durchbruch kommt von MIT-Mathematikprofessor Larry Guth und der Universität Oxford
 Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Unbegrenzte Videogenerierung, Planung und Entscheidungsfindung, erzwungene Verbreitung der nächsten Token-Vorhersage und vollständige Sequenzverbreitung
Jul 23, 2024 pm 02:05 PM
Derzeit sind autoregressive groß angelegte Sprachmodelle, die das nächste Token-Vorhersageparadigma verwenden, auf der ganzen Welt populär geworden. Gleichzeitig haben uns zahlreiche synthetische Bilder und Videos im Internet bereits die Leistungsfähigkeit von Diffusionsmodellen gezeigt. Kürzlich hat ein Forschungsteam am MITCSAIL (darunter Chen Boyuan, ein Doktorand am MIT) erfolgreich die leistungsstarken Fähigkeiten des Vollsequenz-Diffusionsmodells und des nächsten Token-Modells integriert und ein Trainings- und Sampling-Paradigma vorgeschlagen: Diffusion Forcing (DF). ). Papiertitel: DiffusionForcing:Next-tokenPredictionMeetsFull-SequenceDiffusion Papieradresse: https:/
 LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
LLM eignet sich wirklich nicht für die Vorhersage von Zeitreihen. Es nutzt nicht einmal seine Argumentationsfähigkeit.
Jul 15, 2024 pm 03:59 PM
Können Sprachmodelle wirklich zur Zeitreihenvorhersage verwendet werden? Gemäß Betteridges Gesetz der Schlagzeilen (jede Schlagzeile, die mit einem Fragezeichen endet, kann mit „Nein“ beantwortet werden) sollte die Antwort „Nein“ lauten. Die Tatsache scheint wahr zu sein: Ein so leistungsstarkes LLM kann mit Zeitreihendaten nicht gut umgehen. Zeitreihen, also Zeitreihen, beziehen sich, wie der Name schon sagt, auf eine Reihe von Datenpunktsequenzen, die in der Reihenfolge ihres Auftretens angeordnet sind. Die Zeitreihenanalyse ist in vielen Bereichen von entscheidender Bedeutung, einschließlich der Vorhersage der Ausbreitung von Krankheiten, Einzelhandelsanalysen, Gesundheitswesen und Finanzen. Im Bereich der Zeitreihenanalyse haben viele Forscher in letzter Zeit untersucht, wie man mithilfe großer Sprachmodelle (LLM) Anomalien in Zeitreihen klassifizieren, vorhersagen und erkennen kann. Diese Arbeiten gehen davon aus, dass Sprachmodelle, die gut mit sequentiellen Abhängigkeiten in Texten umgehen können, auch auf Zeitreihen verallgemeinert werden können.
