

Kürzlich Professor Yan Shuicheng Das Team hat gemeinsam das universelle visuelle multimodale große Sprachmodell Vitron auf Pixelebene veröffentlicht und als Open Source bereitgestellt.

Projekt-Homepage & Demo: https://www.php.cn/link/d8a3b2dde3181c8257e2e45efbd1e8aePapierlink: https://www.php.cn/link/0ec5ba 872f117 9835987f9028c4cc4df Open-Source-Code: https://www.php.cn/link/26d6e896db39edc7d7bdd357d6984c95
Dies ist ein robustes allgemeines visuelles multimodales Modell, das unterstützt alles von einer Reihe visueller Aufgaben vom visuellen Verständnis bis zur visuellen Generierung, von niedriger bis hoher Ebene, löst das Problem der Trennung von Bild- und Videomodellen, das die große Sprachmodellbranche seit langem plagt, und bietet ein umfassendes und einheitliches Verständnis und Generierung von statischen Bildern und dynamischen Videoinhalten. Das allgemeine visuelle multimodale Großmodell auf Pixelebene für Aufgaben wie Segmentierung und Bearbeitung legt den Grundstein für die ultimative Form des allgemeinen visuellen Großmodells der nächsten Generation , und markiert auch einen weiteren großen Schritt in Richtung allgemeiner künstlicher Intelligenz (AGI) für große Modelle.
Vitron bietet als einheitliches visuelles multimodales großes Sprachmodell auf Pixelebene umfassende Unterstützung für visuelle Aufgaben von niedriger bis hoher Ebene, kann komplexe visuelle Aufgaben bewältigen und Bilder verstehen und generieren und Videoinhalte, die ein leistungsstarkes visuelles Verständnis und Möglichkeiten zur Aufgabenausführung bieten. Gleichzeitig unterstützt Vitron den kontinuierlichen Betrieb mit Benutzern und ermöglicht so eine flexible Mensch-Computer-Interaktion, was das große Potenzial für ein einheitlicheres visuelles multimodales Universalmodell demonstriert.
Vitron-bezogene Dokumente, Codes und Demos wurden alle veröffentlicht. Seine einzigartigen Vorteile und sein Potenzial in Bezug auf Vollständigkeit, technologische Innovation, Mensch-Computer-Interaktion und Anwendungspotenzial haben nicht nur die multimodale Entwicklung gefördert Die Entwicklung großer Modelle bietet auch eine neue Richtung für die zukünftige Forschung an visuellen Großmodellen. Die aktuelle Entwicklung visueller großer Sprachmodelle (LLMs) hat erfreuliche Fortschritte gemacht. Die Community glaubt zunehmend, dass der Aufbau allgemeinerer und leistungsfähigerer multimodaler Großmodelle (MLLMs) der einzige Weg zur Erreichung allgemeiner künstlicher Intelligenz (AGI) sein wird. Allerdings gibt es bei der Umstellung auf ein multimodales allgemeines Modell (Generalist) noch einige zentrale Herausforderungen. Beispielsweise erreicht ein großer Teil der Arbeit kein feinkörniges visuelles Verständnis auf Pixelebene oder es fehlt eine einheitliche Unterstützung für Bilder und Videos. Oder die Unterstützung verschiedener Sehaufgaben reicht nicht aus und es handelt sich bei weitem nicht um ein universelles Großmodell. Um diese Lücke zu schließen, hat das Team kürzlich gemeinsam das Open-Source-Vitron-Vitron-Universal-Pixel-Level-Visual-Multimodal-Large-Language-Modell veröffentlicht. Vitron unterstützt eine Reihe visueller Aufgaben vom visuellen Verständnis bis zur visuellen Generierung, von niedriger bis hoher Ebene, einschließlich umfassendem Verständnis, Generierung, Segmentierung und Bearbeitung statischer Bilder und dynamischer Videoinhalte. 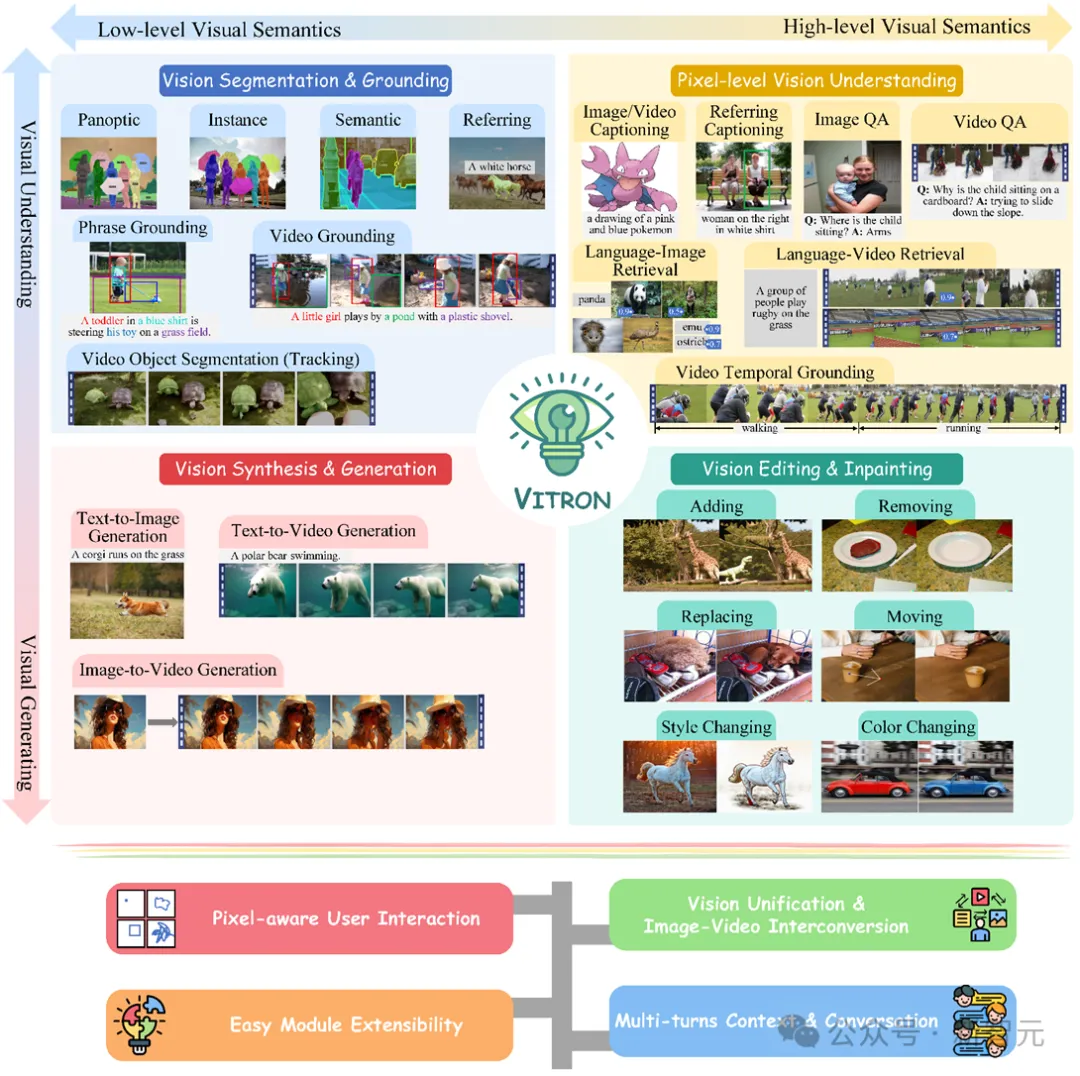 Die obige Abbildung zeigt umfassend die funktionale Unterstützung von Vitron für vier wichtige Sehaufgaben sowie seine wichtigsten Vorteile. Vitron unterstützt außerdem den kontinuierlichen Betrieb mit Benutzern, um eine flexible Mensch-Computer-Interaktion zu erreichen. Dieses Projekt demonstriert das große Potenzial eines einheitlicheren multimodalen allgemeinen Vision-Modells und legt den Grundstein für die ultimative Form der nächsten Generation großer allgemeiner Vision-Modelle. Vitron-bezogene Dokumente, Codes und Demos sind jetzt alle öffentlich.
Die obige Abbildung zeigt umfassend die funktionale Unterstützung von Vitron für vier wichtige Sehaufgaben sowie seine wichtigsten Vorteile. Vitron unterstützt außerdem den kontinuierlichen Betrieb mit Benutzern, um eine flexible Mensch-Computer-Interaktion zu erreichen. Dieses Projekt demonstriert das große Potenzial eines einheitlicheren multimodalen allgemeinen Vision-Modells und legt den Grundstein für die ultimative Form der nächsten Generation großer allgemeiner Vision-Modelle. Vitron-bezogene Dokumente, Codes und Demos sind jetzt alle öffentlich.
In den letzten Jahren haben große Sprachmodelle (LLMs) beispiellose leistungsstarke Fähigkeiten bewiesen und sie wurden nach und nach als technischer Weg zu AGI verifiziert. Multimodale große Sprachmodelle (MLLMs) entwickeln sich in vielen Communities schnell und werden durch die Einführung von Modulen, die eine visuelle Wahrnehmung ermöglichen, zu MLLMs erweitert, die leistungsstark und hervorragend im Bildverständnis sind . , wie BLIP-2, LLaVA, MiniGPT-4 usw. Gleichzeitig wurden auch MLLMs mit Schwerpunkt auf Videoverständnis eingeführt, wie z. B. VideoChat, Video-LLaMA, Video-LLaVA usw.
Anschließend versuchten Forscher hauptsächlich, die Fähigkeiten von MLLMs aus zwei Dimensionen weiter auszubauen. Einerseits versuchen Forscher, das Verständnis von MLLMs für das Sehen zu vertiefen, indem sie vom groben Verständnis auf Instanzebene zum feinkörnigen Verständnis von Bildern auf Pixelebene übergehen und so Funktionen zur visuellen Regionspositionierung (Regional Grounding) wie GLaMM und PixelLM erreichen , NExT-Chat und MiniGPT-v2 usw.
Andererseits versuchen Forscher, die visuellen Funktionen zu erweitern, die MLLMs unterstützen können. Einige Forschungsarbeiten haben damit begonnen, zu untersuchen, wie MLLMs nicht nur visuelle Eingabesignale verstehen, sondern auch die Generierung visueller Ausgabeinhalte unterstützen. Beispielsweise können MLLMs wie GILL und Emu flexibel Bildinhalte generieren, und GPT4Video und NExT-GPT realisieren die Videogenerierung.
Gegenwärtig ist sich die Community der künstlichen Intelligenz allmählich einig, dass sich der zukünftige Trend visueller MLLMs unweigerlich in Richtung hochgradig einheitlicher und stärkerer Fähigkeiten entwickeln wird. Trotz der zahlreichen von der Community entwickelten MLLMs besteht jedoch immer noch eine deutliche Lücke.
1. Fast alle vorhandenen visuellen LLMs behandeln Bilder und Videos als unterschiedliche Einheiten und unterstützen entweder nur Bilder oder nur Videos.
Forscher argumentieren, dass das Sehen sowohl statische Bilder als auch dynamische Videos umfassen sollte – beide sind Kernbestandteile der visuellen Welt und können in den meisten Szenarien sogar ausgetauscht werden. Daher ist es notwendig, ein einheitliches MLLM-Framework aufzubauen, das sowohl Bild- als auch Videomodalitäten unterstützen kann.
2. Derzeit ist die Unterstützung visueller Funktionen durch MLLMs noch unzureichend.
Die meisten Models sind nur in der Lage, Bilder oder Videos zu verstehen oder höchstens zu erzeugen. Forscher glauben, dass zukünftige MLLMs ein allgemeines großes Sprachmodell sein sollten, das ein breiteres Spektrum visueller Aufgaben und Operationen abdecken, eine einheitliche Unterstützung für alle visuellen Aufgaben erreichen und „eines für alle“-Fähigkeiten erreichen sollte. Dies ist für praktische Anwendungen von entscheidender Bedeutung, insbesondere bei der visuellen Erstellung, die häufig eine Reihe iterativer und interaktiver Vorgänge umfasst.
Benutzer beginnen beispielsweise zunächst mit Text und wandeln eine Idee mithilfe von Vincent-Diagrammen in visuelle Inhalte um. Anschließend verfeinern sie die ursprüngliche Idee und fügen weitere Details durch weitere feinkörnige Bildbearbeitung hinzu dynamische Inhalte; schließlich führen Sie mehrere Runden iterativer Interaktionen durch, z. B. Videobearbeitung, um die Erstellung zu verfeinern.
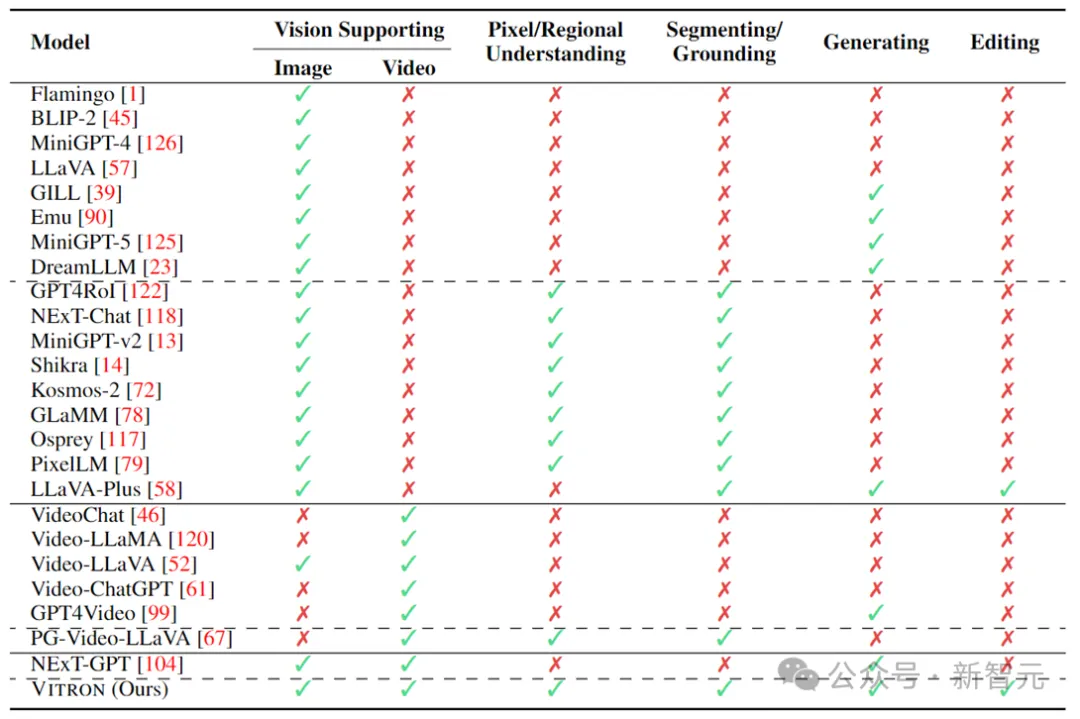
Die obige Tabelle fasst lediglich die Fähigkeiten des vorhandenen visuellen MLLM zusammen (nur einige Modelle sind repräsentativ enthalten und die Abdeckung ist unvollständig). Um diese Lücken zu schließen, schlägt das Team Vitron vor, ein allgemeines visuelles MLLM auf Pixelebene.
Das Gesamtgerüst von Vitron ist in der folgenden Abbildung dargestellt. Vitron übernimmt eine ähnliche Architektur wie bestehende verwandte MLLMs, einschließlich dreier Schlüsselteile: 1) visuelles Front-End- und Sprachcodierungsmodul, 2) zentrales LLM-Verständnis- und Textgenerierungsmodul und 3) Back-End-Benutzerantwort und Modulaufrufe für die visuelle Steuerung Modul. 🔜 Regionsbox-/Skizzen-Encoder.
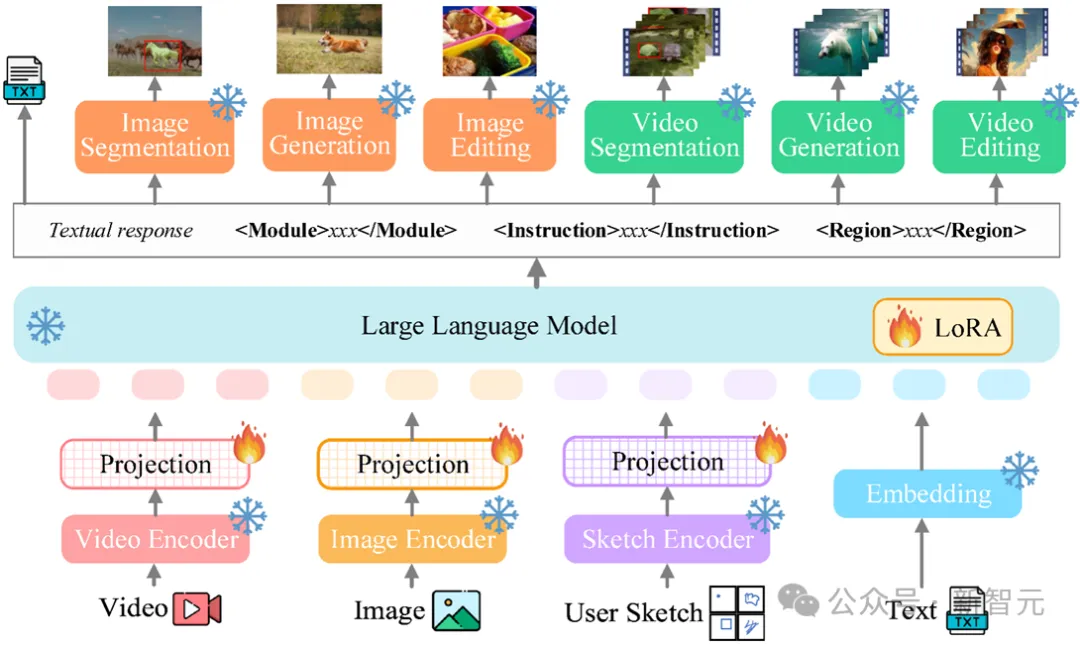
Core LLMVitron verwendet Vicuna (7B, v1.5), um Verständnis, Argumentation, Entscheidungsfindung und mehrere Runden der Benutzerinteraktion zu erreichen.
Backend-Modul:
Benutzerantwort und ModulaufrufVitron übernimmt eine textzentrierte Aufrufstrategie und integriert mehrere leistungsstarke und fortschrittliche Standard-Bild- und Videoverarbeitungsmodule (SoTA) für Dekodieren und Führen Sie eine Reihe visueller Terminalaufgaben von niedrigem bis hohem Niveau aus. Durch die Einführung einer textzentrierten Modulintegrationsaufrufmethode erreicht Vitron nicht nur eine Systemvereinheitlichung, sondern gewährleistet auch Ausrichtungseffizienz und Systemskalierbarkeit.
Basierend auf der oben genannten Architektur wird Vitron trainiert und feinabgestimmt, um ihm ein leistungsstarkes visuelles Verständnis und Fähigkeiten zur Aufgabenausführung zu verleihen. Das Modelltraining umfasst hauptsächlich drei verschiedene Phasen.
Schritt 1: Visual-verbales Gesamtausrichtungslernen. Die eingegebenen visuellen Sprachmerkmale werden in einem einheitlichen Merkmalsraum abgebildet, wodurch die eingegebenen multimodalen Signale effektiv verstanden werden können. Hierbei handelt es sich um ein grobkörniges visuell-linguistisches Ausrichtungslernen, das es dem System ermöglicht, eingehende visuelle Signale als Ganzes effektiv zu verarbeiten. Die Forscher nutzten für das Training vorhandene Bild-Untertitel-Paare (CC3M), Video-Untertitel-Paare (Webvid) und Region-Untertitel-Paare (RefCOCO).
Schritt 2: Feinkörnige Feinabstimmung der räumlich-zeitlichen visuellen Positionierungsanweisungen. Das System verwendet externe Module, um verschiedene visuelle Aufgaben auf Pixelebene auszuführen. LLM selbst wurde jedoch keinem feinkörnigen visuellen Training unterzogen, was das System daran hindern würde, ein echtes visuelles Verständnis auf Pixelebene zu erreichen. Zu diesem Zweck schlugen die Forscher ein Feinabstimmungstraining für räumlich-zeitliche visuelle Positionierungsanweisungen vor. Die Kernidee besteht darin, LLM in die Lage zu versetzen, die feinkörnige Räumlichkeit des Bildes und die spezifischen zeitlichen Eigenschaften des Videos zu lokalisieren.
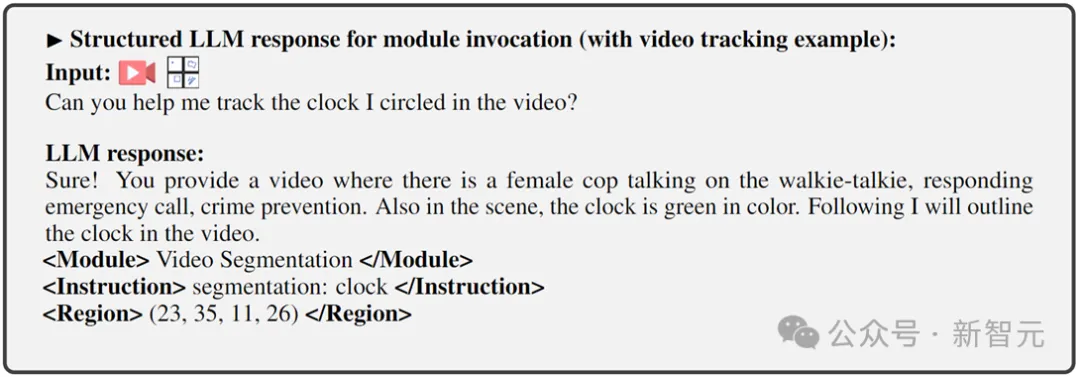
Schritt 3: Feinabstimmung des Ausgabeendes auf den Befehlsaufruf. Die oben beschriebene zweite Trainingsstufe verleiht dem LLM und dem Front-End-Encoder die Fähigkeit, das Sehen auf Pixelebene zu verstehen. Dieser letzte Schritt, die Feinabstimmung der Anweisungen für den Befehlsaufruf, zielt darauf ab, das System mit der Fähigkeit auszustatten, Befehle genau auszuführen, sodass LLM geeigneten und korrekten Aufruftext generieren kann. Da unterschiedliche Terminal-Vision-Aufgaben möglicherweise unterschiedliche Aufrufbefehle erfordern, schlugen die Forscher zur Vereinheitlichung vor, die Antwortausgabe von LLM in ein strukturiertes Textformat zu standardisieren, das Folgendes umfasst:
1) Benutzerantwortausgabe, direkte Antwort auf die Benutzereingabe
2) Modulname, um die Funktion oder Aufgabe anzugeben, die ausgeführt werden soll.
3) Rufen Sie den Befehl auf, um die Metaanweisung des Aufgabenmoduls auszulösen.
4) Region (optionale Ausgabe), die feinkörnige visuelle Funktionen angibt, die für bestimmte Aufgaben erforderlich sind, beispielsweise bei der Videoverfolgung oder visuellen Bearbeitung, wo Backend-Module diese Informationen benötigen. Für Regionen werden basierend auf dem Verständnis auf Pixelebene von LLM durch Koordinaten beschriebene Begrenzungsrahmen ausgegeben.
Forscher führten umfangreiche experimentelle Bewertungen von 22 gängigen Benchmark-Datensätzen und 12 Bild-/Video-Vision-Aufgaben auf Basis von Vitron durch. Vitron zeigt starke Fähigkeiten in vier großen visuellen Aufgabengruppen (Segmentierung, Verstehen, Generierung und Bearbeitung von Inhalten) und verfügt gleichzeitig über flexible Fähigkeiten zur Mensch-Computer-Interaktion. Das Folgende zeigt repräsentativ einige qualitative Vergleichsergebnisse:
Vision-Segmentierung
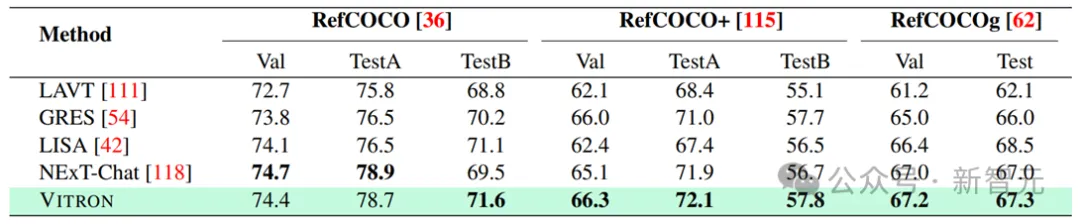
Ergebnisse der bildbezogenen Bildsegmentierung
Feinkörniges Vision-Verstehen
. 
Ergebnisse von Bildbezogenes Ausdrucksverständnis.
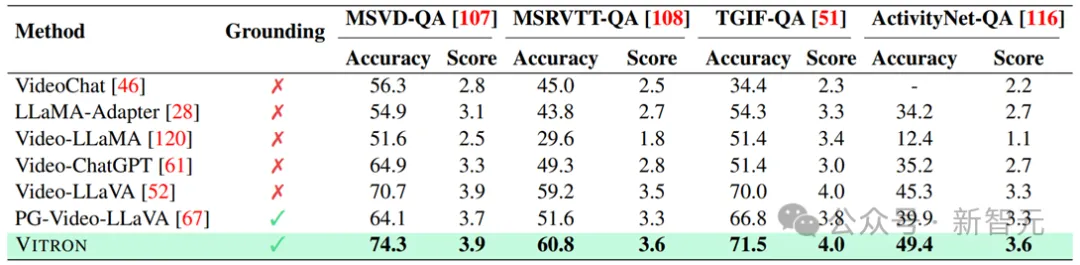
Ergebnisse zur Video-Qualitätssicherung – zur Video-Generierung
Vision-Bearbeitung
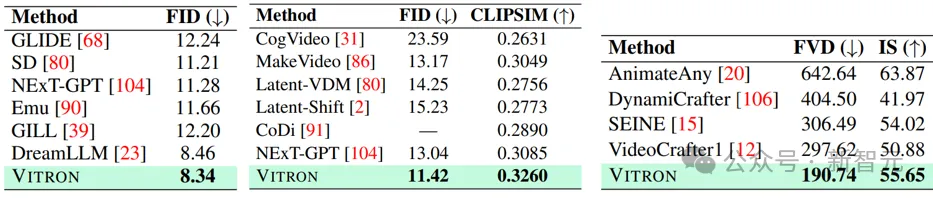
Bildbearbeitungsergebnisse
Bitte Ausführlichere experimentelle Inhalte und Details finden Sie im Artikel. 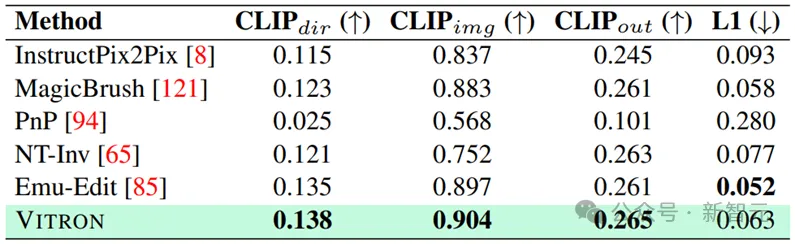
Generell zeigt diese Arbeit das große Potenzial der Entwicklung eines einheitlichen visuellen multimodalen allgemeinen Großmodells, legt eine neue Form für die nächste Generation der visuellen Großmodellforschung fest und geht den ersten Schritt. Obwohl das vom Team vorgeschlagene Vitron-System starke allgemeine Fähigkeiten aufweist, weist es dennoch seine eigenen Einschränkungen auf. Die folgenden Forscher listen einige Richtungen auf, die in Zukunft weiter erforscht werden könnten.
Systemarchitektur
Das Vitron-System verwendet immer noch einen Semi-Union- und Semi-Agent-Ansatz, um externe Tools aufzurufen. Obwohl diese aufrufbasierte Methode die Erweiterung und den Austausch potenzieller Module erleichtert, bedeutet dies auch, dass die Back-End-Module dieser Pipeline-Struktur nicht am gemeinsamen Lernen der Front-End- und LLM-Kernmodule teilnehmen.
Diese Einschränkung ist nicht förderlich für das Gesamtlernen des Systems, was bedeutet, dass die Leistungsobergrenze verschiedener visueller Aufgaben durch das Back-End-Modul begrenzt wird. Zukünftige Arbeiten sollten verschiedene Vision-Aufgabenmodule in eine einheitliche Einheit integrieren. Es bleibt eine Herausforderung, ein einheitliches Verständnis und eine einheitliche Ausgabe von Bildern und Videos zu erreichen und gleichzeitig Generierungs- und Bearbeitungsfunktionen durch ein einziges generatives Paradigma zu unterstützen. Derzeit besteht ein vielversprechender Ansatz darin, modularitätsbeständige Tokenisierung zu kombinieren, um die Vereinheitlichung des Systems für verschiedene Ein- und Ausgänge und verschiedene Aufgaben zu verbessern.
Benutzerinteraktivität
Im Gegensatz zu früheren Modellen, die sich auf eine einzelne Vision-Aufgabe konzentrierten (z. B. Stable Diffusion und SEEM), zielt Vitron darauf ab, eine tiefe Interaktion zwischen LLM und Benutzern zu ermöglichen, ähnlich wie in der DALL von OpenAI -E-Serie, Midjourney usw. Das Erreichen einer optimalen Benutzerinteraktivität ist eines der Kernziele dieser Arbeit.
Vitron nutzt vorhandenes sprachbasiertes LLM in Kombination mit entsprechenden Anpassungen der Anweisungen, um ein gewisses Maß an Interaktivität zu erreichen. Beispielsweise kann das System flexibel auf alle erwarteten Nachrichteneingaben des Benutzers reagieren und entsprechende visuelle Betriebsergebnisse erzeugen, ohne dass die Benutzereingaben genau mit den Bedingungen des Back-End-Moduls übereinstimmen müssen. Allerdings lässt diese Arbeit hinsichtlich der Verbesserung der Interaktivität noch viel Raum für Verbesserungen. In Anlehnung an das Closed-Source-Midjourney-System sollte das System den Benutzern unabhängig davon, welche Entscheidung LLM bei jedem Schritt trifft, aktiv Feedback geben, um sicherzustellen, dass seine Aktionen und Entscheidungen mit den Absichten der Benutzer übereinstimmen.
Modale Fähigkeiten
Derzeit integriert Vitron ein 7B Vicuna-Modell, dessen Fähigkeit, Sprache, Bilder und Videos zu verstehen, möglicherweise bestimmte Einschränkungen aufweist. Zukünftige Forschungsrichtungen könnten in der Entwicklung eines umfassenden End-to-End-Systems bestehen, beispielsweise in der Erweiterung des Maßstabs des Modells, um ein gründlicheres und umfassenderes Verständnis der Vision zu erreichen. Darüber hinaus sollten Anstrengungen unternommen werden, um LLM in die Lage zu versetzen, das Verständnis von Bild- und Videomodalitäten vollständig zu vereinheitlichen.
Das obige ist der detaillierte Inhalt vonYan Shuicheng übernahm die Verantwortung und etablierte die ultimative Form des „universellen visuellen multimodalen Großmodells'! Einheitliches Verständnis/Generierung/Segmentierung/Bearbeitung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 Häufig verwendete Shell-Befehle unter Linux
Häufig verwendete Shell-Befehle unter Linux
 Historisches Bitcoin-Preisdiagramm
Historisches Bitcoin-Preisdiagramm
 getelementbyid
getelementbyid








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



