


Kürzlich wurde der Artikel „Generative Dense Retrieval: Memory Can Be a Burden“ des Xiaohongshu-Suchalgorithmus-Teams von EACL 2024, einer internationalen Konferenz im Bereich der Verarbeitung natürlicher Sprache, als mündlich mit einer Akzeptanzrate angenommen von 11,32 % (144/1271).
In ihrer Arbeit schlugen sie ein neuartiges Information-Retrieval-Paradigma vor – Generative Dense Retrieval (GDR). Dieses Paradigma kann die Herausforderungen, denen sich das traditionelle generative Retrieval (GR) bei der Verarbeitung großer Datensätze gegenübersieht, gut lösen. Es ist vom Speichermechanismus inspiriert.
In der bisherigen Praxis verließ sich GR auf seinen einzigartigen Speichermechanismus, um eine tiefgreifende Interaktion zwischen Abfragen und Dokumentbibliotheken zu erreichen. Diese Methode, die auf der autoregressiven Codierung des Sprachmodells basiert, weist jedoch offensichtliche Einschränkungen bei der Verarbeitung großer Datenmengen auf, einschließlich unscharfer, feinkörniger Dokumentfunktionen, begrenzter Größe der Dokumentbibliothek und Schwierigkeiten bei der Indexaktualisierung.
Die von Xiaohongshu vorgeschlagene DDR übernimmt eine zweistufige Abrufidee von grob nach fein. Sie nutzt zunächst die begrenzte Speicherkapazität des Sprachmodells, um die Zuordnung von Abfragen zu Dokumenten zu realisieren, und verwendet dann den Vektor-Matching-Mechanismus Vervollständigen Sie die Zuordnung von Dokumenten zu Dokumenten. GDR mildert effektiv die inhärenten Nachteile von GR, indem es einen Vektor-Matching-Mechanismus für den Abruf dichter Mengen einführt.
Darüber hinaus entwarf das Team auch eine „speicherfreundliche Konstruktionsstrategie für Dokumentcluster-Identifikatoren“ und eine „Adaptive Negativ-Sampling-Strategie für Dokumentcluster“, um die Abrufleistung der beiden Stufen zu verbessern. Unter mehreren Einstellungen des Natural Questions-Datensatzes demonstrierte GDR nicht nur die Recall@k-Leistung von SOTA, sondern erreichte auch eine gute Skalierbarkeit bei gleichzeitiger Beibehaltung der Vorteile einer tiefen Interaktion, was neue Möglichkeiten für die zukünftige Forschung zum Informationsabruf eröffnet.
Textsuchwerkzeuge haben einen wichtigen Forschungs- und Anwendungswert. Traditionelle Suchparadigmen wie Sparse Retrieval (SR) basierend auf Wortabgleich und Dense Retrieval (DR) basierend auf semantischem Vektorabgleich, obwohl jedes seine eigenen Vorzüge hat, mit dem Aufkommen vorab trainierter Sprachmodelle, basierend auf diesem Der generative Abruf Es begann sich ein Paradigma herauszubilden. Die Anfänge des generativen Retrieval-Paradigmas basierten hauptsächlich auf semantischen Übereinstimmungen zwischen Abfragen und Kandidatendokumenten. Durch die Zuordnung von Abfragen und Dokumenten in denselben semantischen Raum wird das Abrufproblem von Kandidatendokumenten in ein dichtes Abrufproblem von Vektor-Matching-Graden umgewandelt. Dieses bahnbrechende Retrieval-Paradigma nutzt vorab trainierte Sprachmodelle und eröffnet neue Möglichkeiten für den Bereich der Textsuche. Das generative Retrieval-Paradigma steht jedoch immer noch vor Herausforderungen. Einerseits vorhandenes Pre-Training
Während des Trainingsprozesses generiert das Modell autoregressiv Identifikatoren relevanter Dokumente mit einer vorgegebenen Abfrage als Kontext. Dieser Prozess ermöglicht es dem Modell, sich den Kandidatenkorpus zu merken. Nachdem die Abfrage in das Modell gelangt ist, interagiert sie mit den Modellparametern und wird autoregressiv dekodiert, was implizit eine tiefe Interaktion zwischen der Abfrage und dem Kandidatenkorpus erzeugt, und diese tiefe Interaktion ist genau das, was SR und DR fehlt. Daher kann GR eine hervorragende Abrufleistung zeigen, wenn das Modell Kandidatendokumente genau speichern kann.
Obwohl der Speichermechanismus von GR nicht einwandfrei ist. Durch Vergleichsexperimente zwischen dem klassischen DR-Modell (AR2) und dem GR-Modell (NCI) haben wir bestätigt, dass der Speichermechanismus mindestens drei große Herausforderungen mit sich bringt:
Wir haben jeweils die Wahrscheinlichkeit berechnet, dass NCI und AR2 einen Fehler machen, wenn sie jedes Bit der Dokumentkennung von grob nach fein dekodieren. Für AR2 finden wir durch Vektorabgleich die Kennung, die dem relevantesten Dokument für eine bestimmte Abfrage entspricht, und zählen dann die ersten Fehlerschritte der Kennung, um die AR2 entsprechende Schritt-für-Schritt-Dekodierungsfehlerrate zu erhalten. Wie in Tabelle 1 gezeigt, schneidet NCI in der ersten Hälfte der Dekodierung gut ab, während die Fehlerrate in der zweiten Hälfte höher ist, und das Gegenteil gilt für AR2. Dies zeigt, dass NCI die grobkörnige Zuordnung des semantischen Raums von Kandidatendokumenten über die Gesamtspeicherdatenbank besser vervollständigen kann. Da die ausgewählten Features während des Trainingsprozesses jedoch durch die Suche bestimmt werden, ist es schwierig, sich die feinkörnige Zuordnung genau zu merken, sodass die Leistung bei der feinkörnigen Zuordnung schlecht ist.

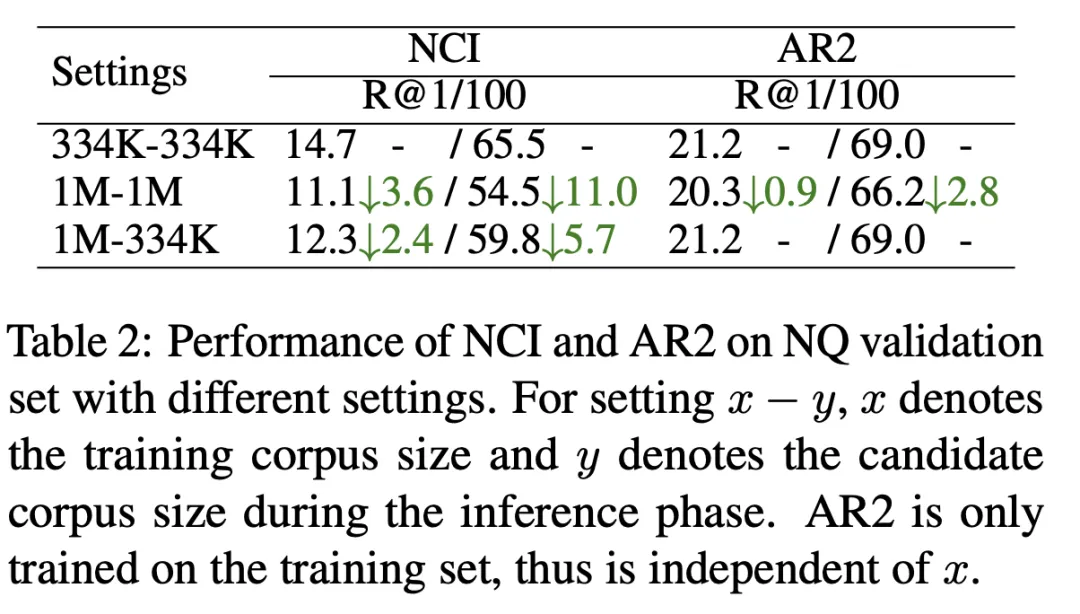
Wie in Tabelle 2 gezeigt, haben wir das NCI-Modell mit einer Kandidatendokumentbibliotheksgröße von 334 KB (erste Zeile) und einer Kandidatendokumentbibliotheksgröße von 1 MB (zweite Zeile) trainiert und getestet mit R@k-Anzeige. Die Ergebnisse zeigen, dass NCI auf R@100 11 Punkte verlor, verglichen mit AR2, das nur 2,8 Punkte verlor. Um den Grund zu untersuchen, warum die NCI-Leistung mit zunehmender Größe der Kandidatendokumentbibliothek deutlich abnimmt, haben wir die Testergebnisse des NCI-Modells, das auf der 1M-Dokumentbibliothek trainiert wurde, weiter getestet, wobei 334K als Kandidatendokumentbibliothek verwendet wurde (dritte Zeile). Im Vergleich zur ersten Zeile führt die Belastung von NCI, mehr Dokumente zu speichern, zu einer erheblichen Verringerung der Abrufleistung, was darauf hindeutet, dass die begrenzte Speicherkapazität des Modells seine Fähigkeit einschränkt, große Dokumentenbibliotheken von Kandidaten zu speichern.
Wenn ein neues Dokument zur Kandidatenbibliothek hinzugefügt werden muss, muss die Dokumentkennung aktualisiert und das Modell neu trainiert werden - Merken Sie sich alle Dokumente. Andernfalls führen veraltete Zuordnungen (Abfrage zu Dokument-ID und Dokument-ID zu Dokument) zu einer erheblichen Beeinträchtigung der Abrufleistung.
Die oben genannten Probleme behindern die Anwendung von GR in realen Szenarien. Aus diesem Grund glauben wir nach der Analyse, dass der Matching-Mechanismus von DR eine komplementäre Beziehung zum Speichermechanismus hat. Daher erwägen wir, ihn in GR einzuführen, um den Speichermechanismus beizubehalten und gleichzeitig seine Nachteile zu unterdrücken. Wir haben ein neues Paradigma für Generative Dense Retrieval (GDR) vorgeschlagen:
Unter Verwendung der Abfrage als Eingabe verwenden wir das Sprachmodell, um die Kandidatendokumentbibliothek zu speichern und autoregressiv k verwandte Dokumentcluster (CID) zu generieren, um sie zu vervollständigen die folgende Zuordnung:
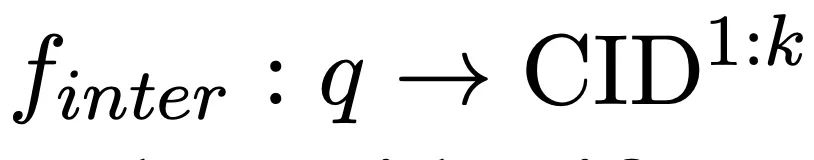
In diesem Prozess beträgt die Generierungswahrscheinlichkeit von CID:
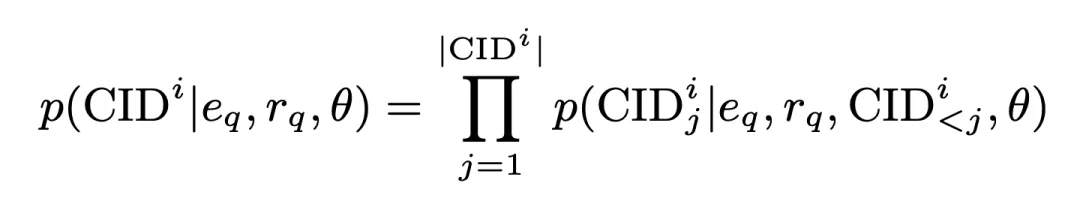
wobei
alle vom Encoder generierten Abfrageeinbettungen sind,
einer generiert durch den Encoder Dimensionsabfragedarstellung. Diese Wahrscheinlichkeit wird auch als Inter-Cluster-Matching-Score gespeichert und nimmt an nachfolgenden Operationen teil. Auf dieser Grundlage verwenden wir Standard-Kreuzentropieverlust, um das Modell zu trainieren:
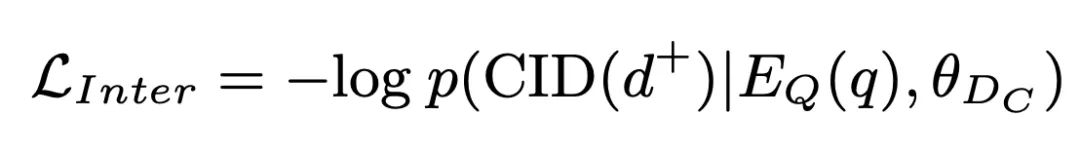
Wir rufen außerdem Kandidatendokumente aus Kandidatendokument-Clustern ab und vervollständigen Intra-Cluster-Matching. Cluster-Matching:
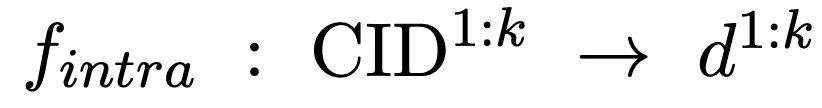
Wir führen einen Dokument-Encoder ein, um die Darstellung der Kandidatendokumente zu extrahieren, und dieser Prozess wird offline abgeschlossen. Berechnen Sie auf dieser Grundlage die Ähnlichkeit zwischen den Dokumenten im Cluster und der Abfrage als Intra-Cluster-Matching-Score:

In diesem Prozess wird der NLL-Verlust zum Trainieren des Modells verwendet:
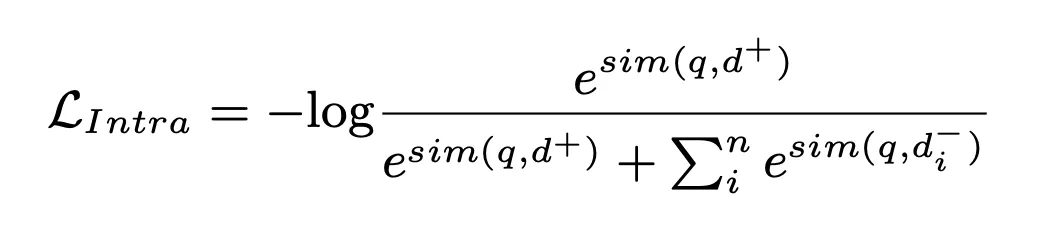
Schließlich berechnen wir den gewichteten Wert des Inter-Cluster-Matching-Scores und des Intra-Cluster-Matching-Scores des Dokuments, sortieren sie und wählen das Top K als abgerufene relevante Dokumente aus:
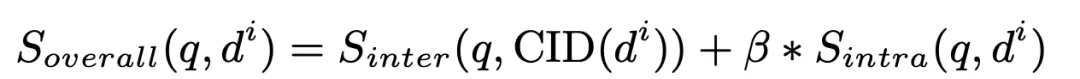
wo Beta ist in unserem Experiment auf 1 gesetzt.
Um die begrenzte Speicherkapazität des Modells voll auszunutzen und eine tiefe Interaktion zwischen der Abfrage und der Kandidatendokumentbibliothek zu erreichen, schlagen wir einen speicherfreundlichen Dokumentcluster vor Identifikatorkonstruktionsstrategie. Diese Strategie verwendet zunächst die Modellspeicherkapazität als Benchmark, um die Obergrenze der Anzahl der Dokumente im Cluster zu berechnen:
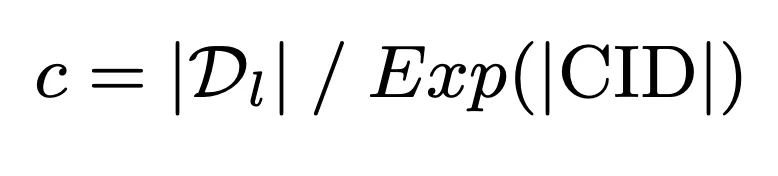
Auf dieser Grundlage wird die Dokumentencluster-ID durch den K-Means-Algorithmus weiter konstruiert Stellen Sie sicher, dass die Speicherlast des Modells seine Speicherkapazität nicht überschreitet:

GDR Das zweistufige Abruf-Framework bestimmt, dass die negativen Proben innerhalb des Clusters ausmachen einen größeren Anteil im Intra-Cluster-Matching-Prozess. Zu diesem Zweck verwenden wir die Dokumenten-Cluster-Aufteilung als Benchmark in der zweiten Trainingsstufe, um das Gewicht negativer Proben innerhalb des Clusters explizit zu erhöhen und so bessere Intra-Cluster-Matching-Ergebnisse zu erzielen:
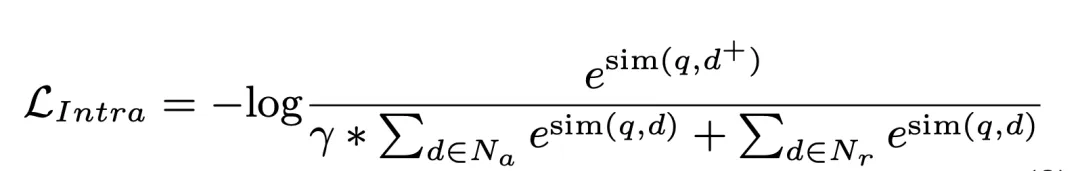
Der in den Experimenten verwendete Datensatz ist Natural Questions (NQ), der 58.000 Trainingspaare (Abfragen und zugehörige Dokumente) und 6.000 Validierungspaare sowie eine 21 Millionen Kandidatendokumentbibliothek enthält. Jede Abfrage verfügt über mehrere zugehörige Dokumente, wodurch höhere Anforderungen an die Abrufleistung des Modells gestellt werden. Um die Leistung von GDR auf Dokumentbasen unterschiedlicher Größe zu bewerten, haben wir verschiedene Einstellungen wie NQ334K, NQ1M, NQ2M und NQ4M erstellt, indem wir die verbleibenden Passagen aus dem vollständigen 21M-Korpus zu NQ334K hinzugefügt haben. GDR generiert CIDs für jeden Datensatz separat, um zu verhindern, dass die semantischen Informationen der größeren Kandidatendokumentbibliothek in den kleineren Korpus gelangen. Wir verwenden BM25 (Anserini-Implementierung) als SR-Basislinie, DPR und AR2 als DR-Basislinie und NCI als GR-Basislinie. Zu den Bewertungsmetriken gehören R@k und Acc@k.
Im NQ-Datensatz verbessert sich GDR im Durchschnitt um 3,0 bei der R@k-Metrik und belegt bei der Acc@k-Metrik den zweiten Platz. Dies zeigt, dass GDR die Vorteile des Speichermechanismus bei tiefer Interaktion und des Matching-Mechanismus bei feinkörniger Merkmalsunterscheidung durch einen Grob-zu-Fein-Abrufprozess maximiert.
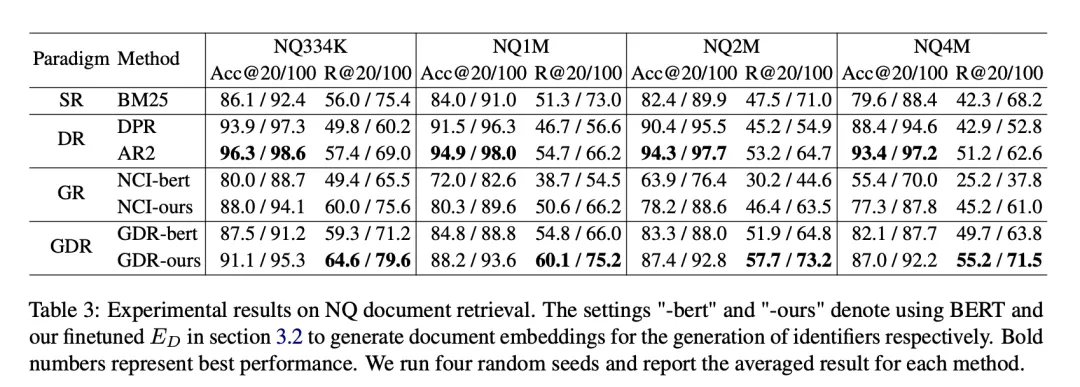
Wir stellen fest, dass bei der Skalierung des Kandidatenkorpus auf eine größere Größe die R@100-Reduktionsrate von SR und DR unter 4,06 % bleibt, während GR The ist Die Rückgangsrate in allen drei Expansionsrichtungen übersteigt 15,25 %. Im Gegensatz dazu erreicht GDR eine durchschnittliche R@100-Reduktionsrate von 3,50 %, was SR und DR ähnelt, indem der Speicherinhalt auf ein festes Volumen grobkörniger Korpusmerkmale konzentriert wird.
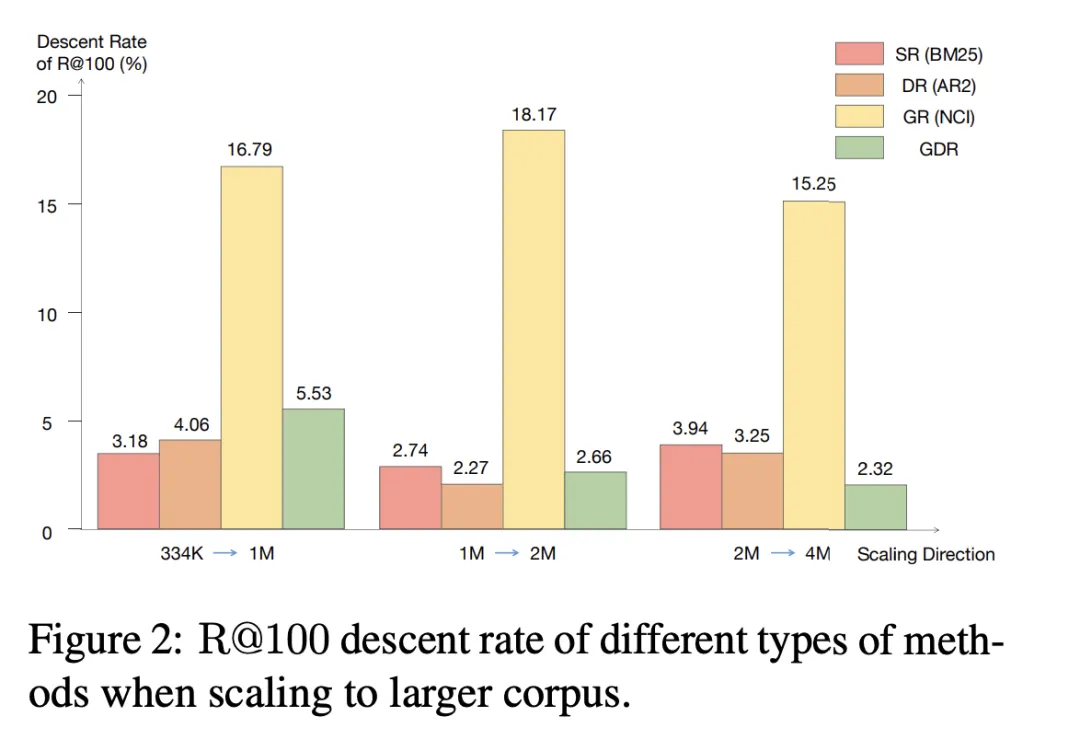
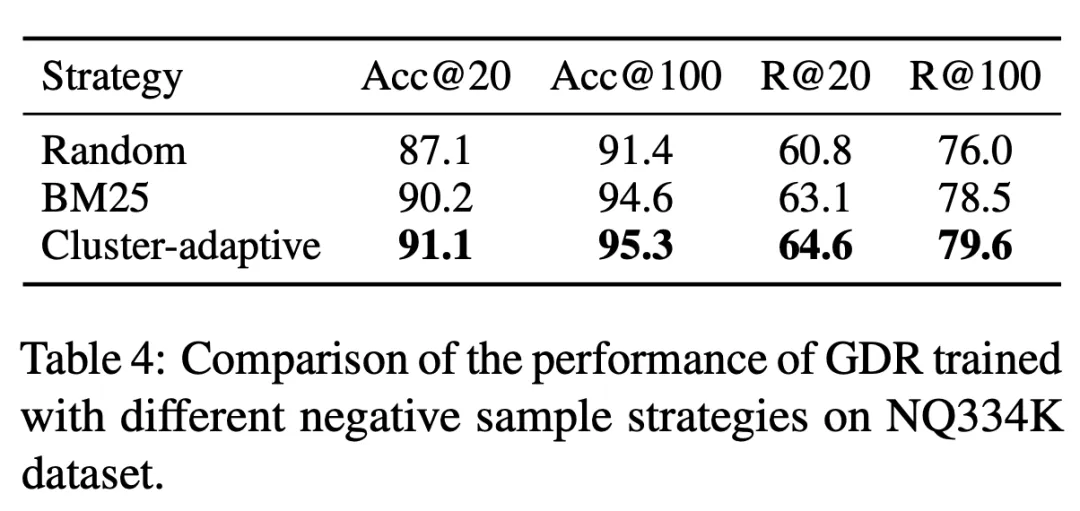
Tabelle 3 GDR-bert und GDR-ours stellen jeweils die entsprechende Modellleistung unter der traditionellen und unserer CID-Konstruktionsstrategie dar. Das Experiment beweist, dass die Verwendung von Speicher- Freundliche Dokumente Die Strategie zur Erstellung von Cluster-Identifikatoren kann die Speicherbelastung erheblich reduzieren und dadurch zu einer besseren Abrufleistung führen. Darüber hinaus zeigt Tabelle 4, dass die im GDR-Training verwendete adaptive Negativ-Sampling-Strategie für Dokumentcluster die feinkörnigen Matching-Fähigkeiten verbessert, indem sie differenziertere Signale innerhalb von Dokumentclustern bereitstellt. 3.4 Neues Dokument hinzugefügt 3.4 Neues Dokument hinzugefügt und gleichzeitig extrahiert der Dokument-Encoder Vektordarstellungen und aktualisiert Vektorindizes, wodurch die schnelle Erweiterung neuer Dokumente abgeschlossen wird. Wie in Tabelle 6 dargestellt, sinkt der R@100 von NCI beim Hinzufügen neuer Dokumente zum Kandidatenkorpus um 18,3 Prozentpunkte, während die Leistung von GDR nur um 1,9 Prozentpunkte sinkt. Dies zeigt, dass GDR die schwierige Skalierbarkeit des Speichermechanismus durch die Einführung eines Matching-Mechanismus lindert und gute Rückrufeffekte beibehält, ohne das Modell neu zu trainieren.
Begrenzt durch die Merkmale der autoregressiven Generierung von Sprachmodellen, obwohl GDR in der zweiten Stufe einen Vektor-Matching-Mechanismus einführt, der im Vergleich zu GR eine erhebliche Verbesserung der Abrufeffizienz erzielt, aber im Vergleich zu DR Es gibt immer noch viele Raum für Verbesserungen mit SR. Wir freuen uns auf weitere Forschung in der Zukunft, um das Verzögerungsproblem zu lindern, das durch die Einführung von Speichermechanismen in das Abruf-Framework verursacht wird.
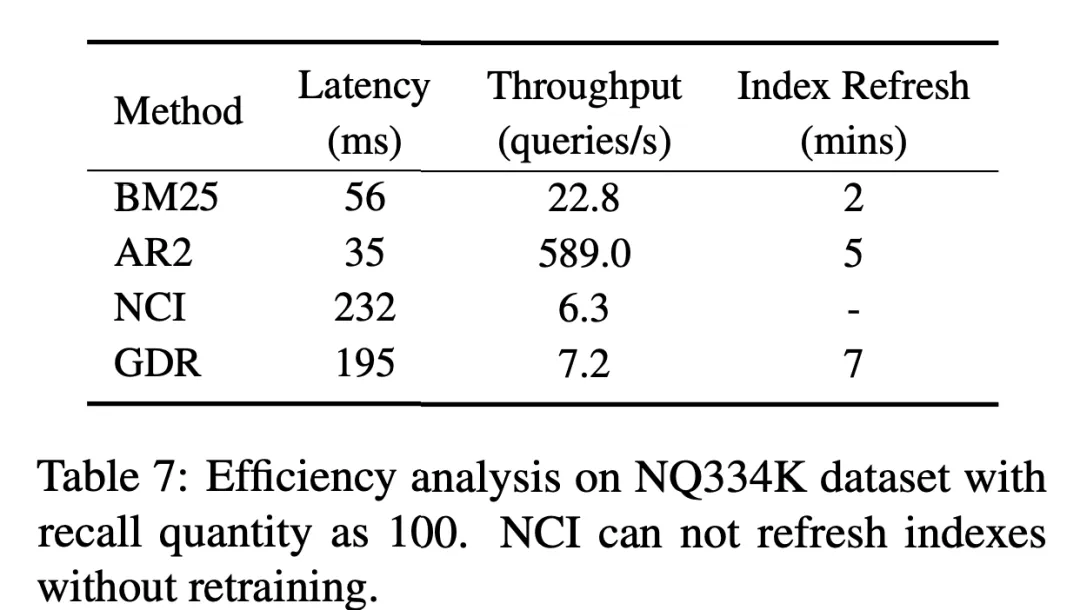
In dieser Studie haben wir den zweischneidigen Schwerteffekt des Gedächtnismechanismus beim Informationsabruf eingehend untersucht: Einerseits erreicht dieser Mechanismus eine tiefe Interaktion zwischen der Anfrage und dem Kandidaten Dokumentbibliothek: Es gleicht die Mängel des intensiven Abrufs aus. Andererseits erschweren die begrenzte Speicherkapazität des Modells und die Komplexität der Aktualisierung des Index den Umgang mit großen und sich dynamisch ändernden Dokumentenbibliotheken. Um dieses Problem zu lösen, kombinieren wir auf innovative Weise den Speichermechanismus und den Vektor-Matching-Mechanismus auf hierarchische Weise, sodass beide ihre Stärken maximieren, ihre Schwächen vermeiden und sich gegenseitig ergänzen können.
Wir schlagen ein neues Text-Retrieval-Paradigma vor: Generative Dense Retrieval (GDR). GDR Dieses Paradigma führt einen zweistufigen Abruf von grob nach fein für eine bestimmte Abfrage durch. Zuerst generiert der Speichermechanismus autoregressiv Dokument-Cluster-IDs, um die Abfrage Dokument-Clustern zuzuordnen, und dann berechnet der Vektor-Matching-Mechanismus die Beziehung zwischen den Die Abfrage und die Dokumentähnlichkeit vervollständigt die Zuordnung von Dokumentclustern zu Dokumenten.
Die speicherfreundliche Konstruktionsstrategie für Dokumentcluster-Identifikatoren stellt sicher, dass die Speicherbelastung des Modells seine Speicherkapazität nicht überschreitet, und erhöht den Inter-Cluster-Matching-Effekt. Die adaptive Negativ-Sampling-Strategie für den Dokumentencluster verbessert das Trainingssignal zur Unterscheidung negativer Proben innerhalb des Clusters und erhöht den Matching-Effekt innerhalb des Clusters. Umfangreiche Experimente haben gezeigt, dass GDR bei großen Kandidaten-Dokumentbibliotheken eine hervorragende Abrufleistung erzielen und effizient auf Dokumentbibliotheksaktualisierungen reagieren kann.
Als erfolgreicher Versuch, die Vorteile traditioneller Abrufmethoden zu integrieren, bietet das generative intensive Abrufparadigma die Vorteile einer guten Abrufleistung, einer starken Skalierbarkeit und einer robusten Leistung in Szenarien mit umfangreichen Kandidatendokumentbibliotheken. Da große Sprachmodelle ihr Verständnis und ihre Generierungsfähigkeiten weiter verbessern, wird die Leistung des generativen intensiven Abrufs weiter verbessert und eine breitere Welt für den Informationsabruf eröffnet.
Papieradresse: https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
Das obige ist der detaillierte Inhalt vonXiaohongshu interpretiert den Informationsabruf aus dem Gedächtnismechanismus und schlägt ein neues Paradigma vor, um EACL Oral zu erhalten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So ändern Sie Dateinamen stapelweise
So ändern Sie Dateinamen stapelweise
 Was bedeutet Element?
Was bedeutet Element?
 So verwenden Sie die Wertfunktion
So verwenden Sie die Wertfunktion
 Was ist der Grund, warum das Netzwerk nicht verbunden werden kann?
Was ist der Grund, warum das Netzwerk nicht verbunden werden kann?
 Häufig verwendete Ausdrücke in PHP
Häufig verwendete Ausdrücke in PHP
 Ist Python Front-End oder Back-End?
Ist Python Front-End oder Back-End?
 photoshare.db
photoshare.db
 Dogecoin-Handelsplattform
Dogecoin-Handelsplattform
 Zusammenfassung der Java-Grundkenntnisse
Zusammenfassung der Java-Grundkenntnisse








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



