
 Technologie-Peripheriegeräte
KI
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Technologie-Peripheriegeräte
KI
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |
Mit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |

FP8 und die geringere Gleitkomma-Quantifizierungsgenauigkeit sind nicht mehr das „Patent“ von H100!
Lao Huang wollte, dass jeder INT8/INT4 nutzt erzwungenermaßen mit der Ausführung von FP6 auf A100 ohne offizielle Unterstützung von NVIDIA.
Die Testergebnisse zeigen, dass die FP6-Quantisierung der neuen Methode TC-FPx auf A100 eine Geschwindigkeit aufweist, die nahe an INT4 liegt oder diese sogar gelegentlich übertrifft, und eine höhere Genauigkeit als letzteres aufweist .
Auf dieser Basis gibt es auch End-to-End-Unterstützung für große Modelle, die als Open Source bereitgestellt und in Deep-Learning-Inferenz-Frameworks wie DeepSpeed integriert wurde.
Dieses Ergebnis wirkt sich auch unmittelbar auf die Beschleunigung großer Modelle aus – unter diesem Rahmen ist der Durchsatz bei Verwendung einer einzelnen Karte zum Ausführen von Llama 2,65-mal höher als der von Doppelkarten.
Nachdem er es gelesen hatte, sagte ein Forscher für maschinelles Lernen, dass die Forschung von Microsoft als verrückt bezeichnet werden könne.
Emoticon-Pakete sind ebenfalls ab sofort online, seien Sie so:
NVIDIA: Nur H100 unterstützt FP8.
Microsoft: Gut, ich mache es selbst.

Welche Effekte kann dieses Framework also erzielen und welche Technologie steckt dahinter?
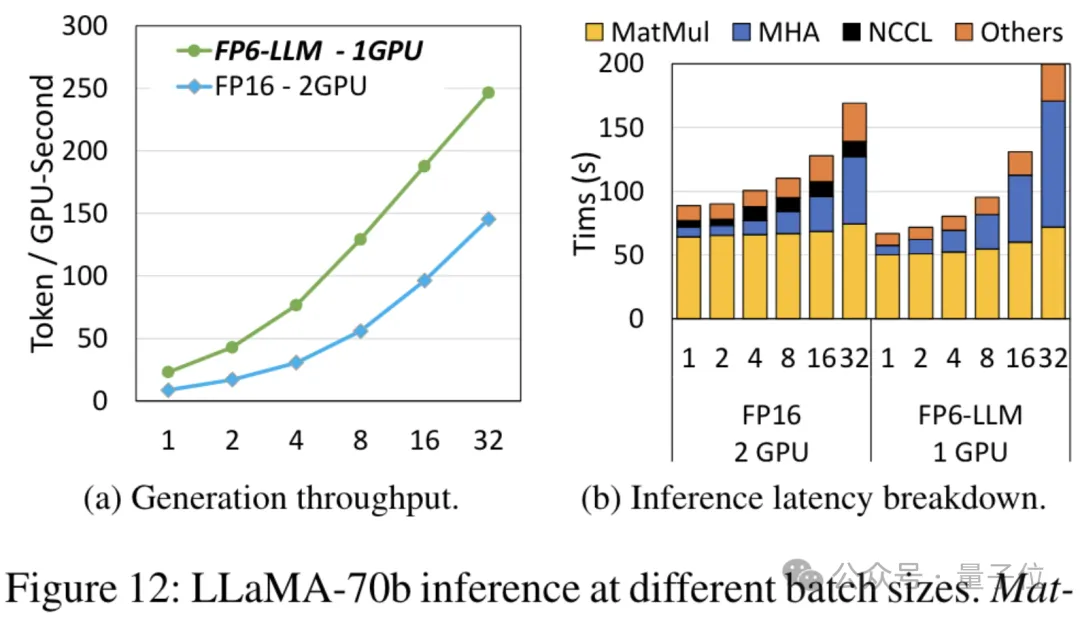
Bei Verwendung von FP6 zum Ausführen von Llama ist eine einzelne Karte schneller als zwei Karten.
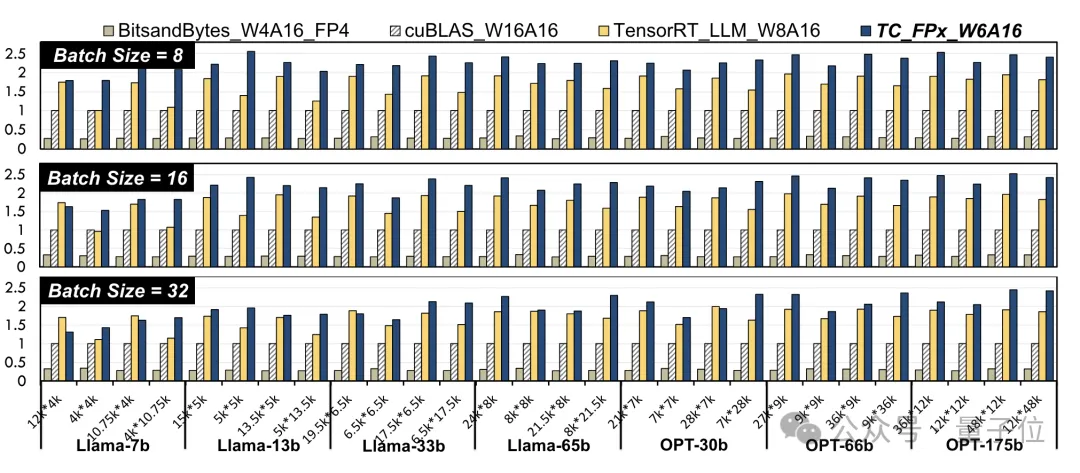
Die Verwendung von FP6-Genauigkeit auf A100 führt zu einer Leistungsverbesserung auf Kernel-Ebene. Die Forscher wählten lineare Schichten in Llama-Modellen und OPT-Modellen unterschiedlicher Größe aus und testeten sie mit CUDA 11.8 auf der NVIDIA A100-40GB GPU-Plattform. Die Ergebnisse sind im Vergleich zu NVIDIAs offizieller Geschwindigkeit cuBLAS
(W16A16)und TensorRT-LLM
(W8A16), TC-FPx(W6A16)Die maximale Geschwindigkeitsverbesserung beträgt das 2,6-fache bzw. das 1,9-fache. Im Vergleich zur 4-Bit-BitsandBytes-Methode (W4A16) beträgt die maximale Geschwindigkeitsverbesserung von TC-FPx das 8,9-fache. (W und A stellen die Bitbreite der Gewichtsquantisierung bzw. die Bitbreite der Aktivierungsquantisierung dar)
△Normalisierte Daten, wobei das cuBLAS-Ergebnis 1 istGleichzeitig wird auch der TC-FPx-Kern reduziert die Notwendigkeit eines DRAM-Speicherzugriffs und verbessert die DRAM-Bandbreitennutzung und Tensor-Core-Auslastung sowie die Auslastung von ALU- und FMA-Einheiten.
Das auf Basis von TC-FPx entwickelte
End-to-End-Inferenz-Framework FP6-LLM
bringt auch bei großen Modellen erhebliche Leistungsverbesserungen. 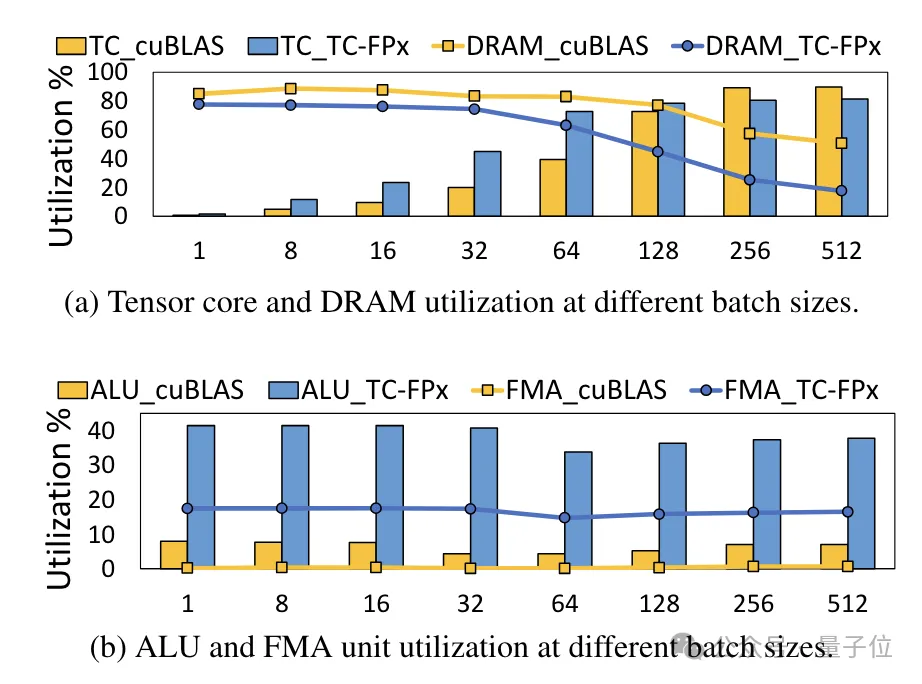
Für das Modell OPT-30B mit einer geringeren Anzahl von Parametern (FP16 verwendet auch eine einzelne Karte) bringt FP6-LLM auch eine deutliche Durchsatzverbesserung und Latenzreduzierung.
Und die maximale Stapelgröße, die von einer einzelnen Karte FP16 unter dieser Bedingung unterstützt wird, beträgt nur 4, aber FP6-LLM kann normal mit einer Stapelgröße von 16 arbeiten.
Wie hat das Microsoft-Team also die FP16-Quantisierung auf dem A100 erreicht?
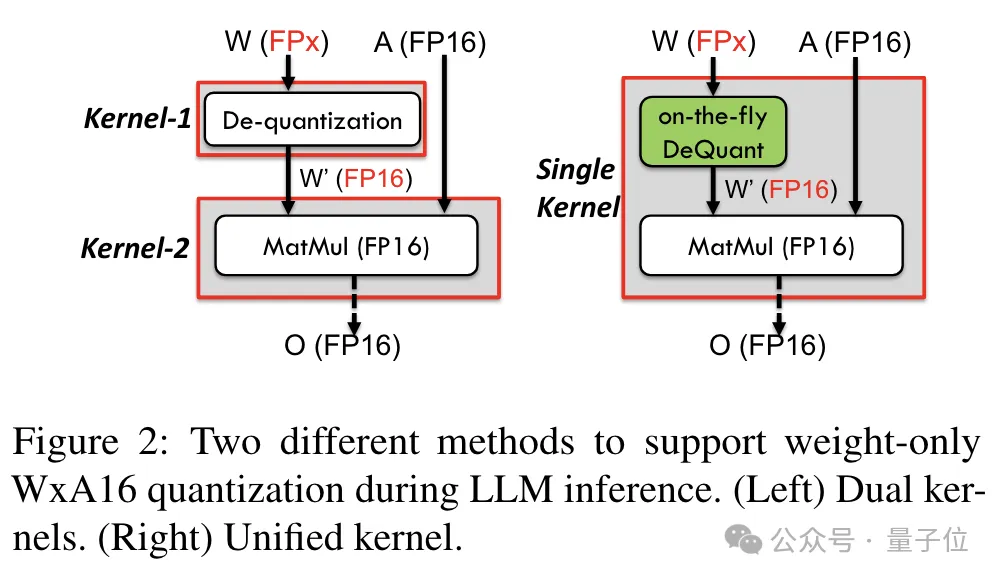
Neu gestaltete Kernel-Lösung
Um Präzision einschließlich 6 Bit zu unterstützen, hat das TC-FPx-Team eine einheitliche Kernel-Lösung entwickelt, die Quantisierungsgewichte unterschiedlicher Bitbreiten unterstützen kann. 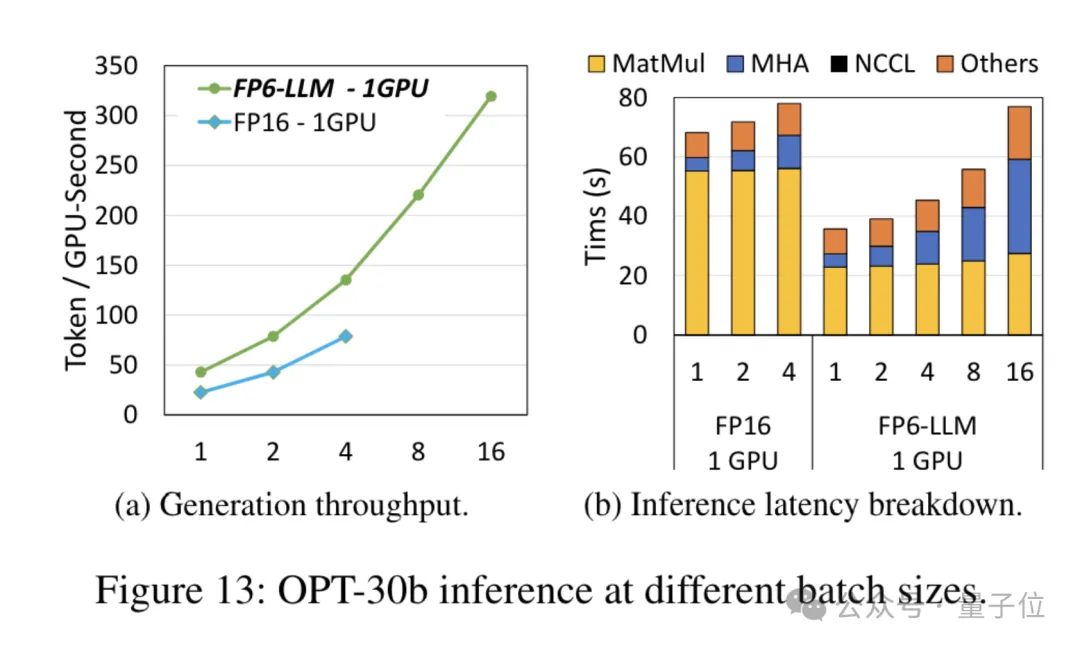
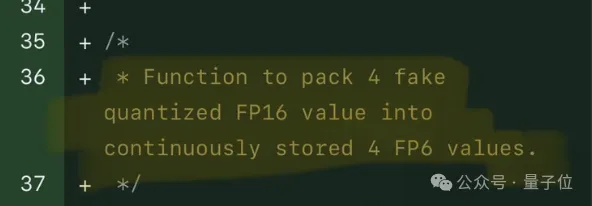
Gleichzeitig nutzte das Team auch die Bit-Level-Pre-Packaging-Technologie, um das Problem zu lösen, dass das GPU-Speichersystem nicht für Bitbreiten ohne Zweierpotenz geeignet ist (z. B. 6). -bisschen).
Konkret handelt es sich beim Vorpacken auf Bitebene um die Neuorganisation von Gewichtsdaten vor der Modellinferenz, einschließlich der Neuanordnung quantisierter 6-Bit-Gewichte, sodass auf sie auf eine GPU-speichersystemfreundliche Weise zugegriffen werden kann.
Da GPU-Speichersysteme außerdem normalerweise auf Daten in 32-Bit- oder 64-Bit-Blöcken zugreifen, packt die Pre-Packing-Technologie auf Bitebene auch 6-Bit-Gewichte, sodass sie in dieser ausgerichteten Form gespeichert und abgerufen werden können Blöcke.

Nach Abschluss der Vorverpackung nutzt das Forschungsteam die Parallelverarbeitungsfähigkeiten des SIMT-Kerns, um eine parallele Dequantisierung der FP6-Gewichte im Register durchzuführen und Gewichte im FP16-Format zu generieren.
Die dequantisierten FP16-Gewichte werden im Register rekonstruiert und dann an den Tensorkern gesendet. Die rekonstruierten FP16-Gewichte werden zur Durchführung von Matrixmultiplikationsoperationen verwendet, um die Berechnung der linearen Schicht abzuschließen.
In diesem Prozess nutzte das Team die Bit-Level-Parallelität des SMIT-Kerns, um die Effizienz des gesamten Dequantisierungsprozesses zu verbessern.
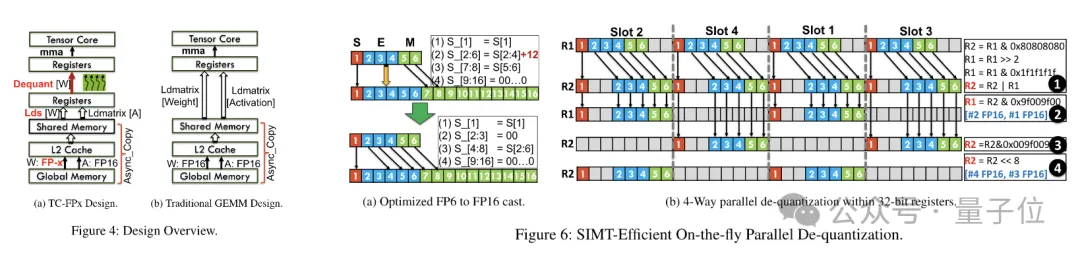
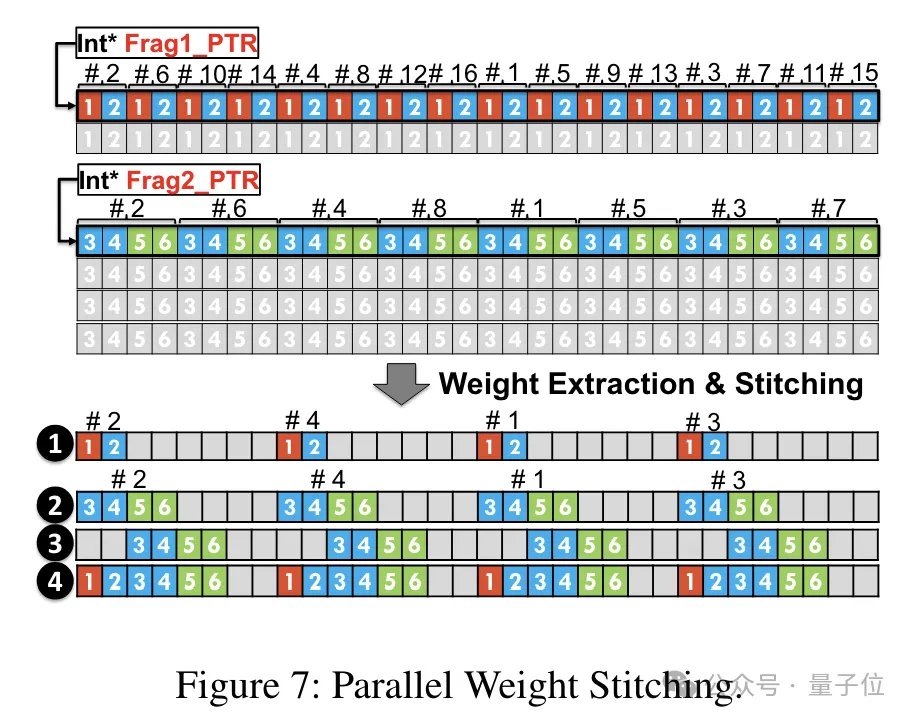
Um den parallelen Ablauf der Gewichtsrekonstruktionsaufgabe zu ermöglichen, verwendete das Team außerdem eine parallele Gewichtsspleißtechnologie.
Konkret ist jedes Gewicht in mehrere Teile unterteilt, und die Bitbreite jedes Teils ist eine Potenz von 2 (z. B. Division von 6 in 2+4 oder 4+2).
Vor der Dequantisierung werden die Gewichte zunächst aus dem gemeinsamen Speicher in Register geladen. Da jedes Gewicht in mehrere Teile aufgeteilt ist, muss das vollständige Gewicht zur Laufzeit auf Registerebene rekonstruiert werden.
Um den Laufzeitaufwand zu reduzieren, schlägt TC-FPx eine Methode zum parallelen Extrahieren und Spleißen von Gewichten vor. Dieser Ansatz verwendet zwei Registersätze, um Segmente von 32 FP6-Gewichten zu speichern und diese Gewichte parallel zu rekonstruieren.
Gleichzeitig muss zum parallelen Extrahieren und Zusammenfügen von Gewichten sichergestellt werden, dass das anfängliche Datenlayout bestimmte Reihenfolgeanforderungen erfüllt, sodass TC-FPx die Gewichtsfragmente vor der Ausführung neu anordnet.
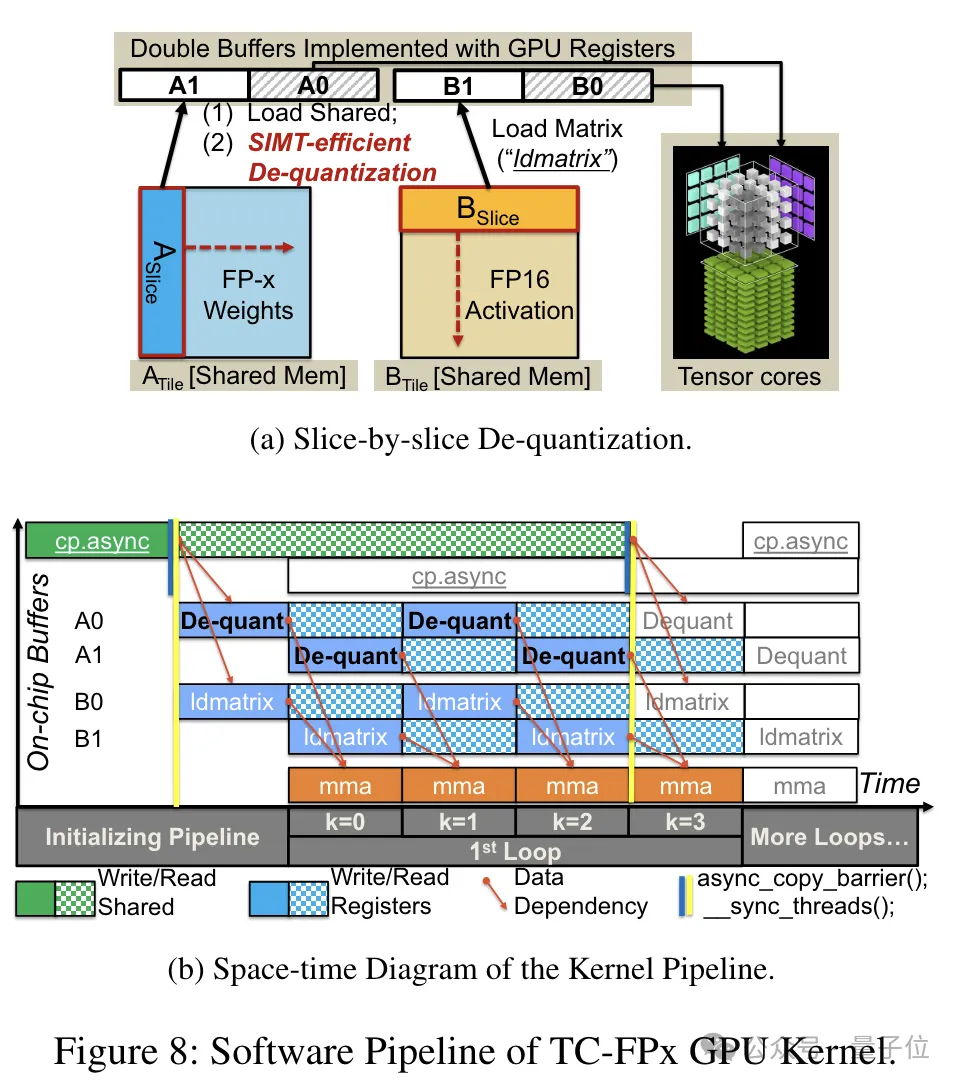
Darüber hinaus hat TC-FPx auch eine Software-Pipeline entwickelt, die den Dequantisierungsschritt mit der Matrixmultiplikationsoperation von Tensor Core integriert und so die Gesamtausführungseffizienz durch Parallelität auf Befehlsebene verbessert.
Papieradresse: https://arxiv.org/abs/2401.14112
Das obige ist der detaillierte Inhalt vonMit einer einzelnen Karte läuft Llama 70B schneller als mit zwei Karten, Microsoft hat gerade FP6 in A100 integriert |. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Was sind die sicheren und zuverlässigen digitalen Währungsplattformen?
Mar 17, 2025 pm 05:42 PM
Eine sichere und zuverlässige Plattform für digitale Währung: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top 10 Top -Currency -Handelsplattformen 2025 Cryptocurrency Trading Apps, die die Top Ten ringen
Mar 17, 2025 pm 05:54 PM
Top Ten Ten Virtual Currency Trading Platforms 2025: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Top 10 Cryptocurrency -Handelsplattformen, Top Ten empfohlene Apps für Währungshandelsplattformen
Mar 17, 2025 pm 06:03 PM
Zu den zehn Top -Kryptowährungsplattformen gehören: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Welcher der zehn besten Apps für virtuelle Währung ist die besten?
Mar 19, 2025 pm 05:00 PM
Top 10 Apps Rankings von Virtual Currency Trading: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundenbetreuung sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene sichere Apps mit sicheren Virtual Currency Software Top 10 Top 10 Digital Currency Trading Apps Ranking 2025
Mar 17, 2025 pm 05:48 PM
Empfohlene Safe Virtual Currency Software Apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundensupport sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Berechnung des C-Subscript 3-Index 5 C-Subscript 3-Index 5-Algorithmus-Tutorial
Apr 03, 2025 pm 10:33 PM
Die Berechnung von C35 ist im Wesentlichen kombinatorische Mathematik, die die Anzahl der aus 3 von 5 Elementen ausgewählten Kombinationen darstellt. Die Berechnungsformel lautet C53 = 5! / (3! * 2!), Was direkt durch Schleifen berechnet werden kann, um die Effizienz zu verbessern und Überlauf zu vermeiden. Darüber hinaus ist das Verständnis der Art von Kombinationen und Beherrschen effizienter Berechnungsmethoden von entscheidender Bedeutung, um viele Probleme in den Bereichen Wahrscheinlichkeitsstatistik, Kryptographie, Algorithmus -Design usw. zu lösen.
 Das Geheimnis hinter O1/Deepseek-R1 kann auch in multimodalen großen Modellen verwendet werden
Mar 12, 2025 pm 01:03 PM
Das Geheimnis hinter O1/Deepseek-R1 kann auch in multimodalen großen Modellen verwendet werden
Mar 12, 2025 pm 01:03 PM
Forscher der Shanghai Jiaotong University, Shanghai Ailab und der chinesischen Universität von Hongkong haben das Open-Source-Projekt zur Visual-RFT (visuelle Verbesserung der Feinabstimmung) gestartet, für das nur eine geringe Datenmenge erforderlich ist, um die Leistung des visuellen Sprachen-Big-Modells (LVLM) signifikant zu verbessern. Visual-RFT kombiniert geschickt die regelbasierte Verstärkungslernansatz von Deepseek-R1 mit dem RFT-Paradigma (Verstärkung der Verstärkung der Verstärkung) und erweitert diesen Ansatz erfolgreich vom Textfeld auf das Gesichtsfeld. Durch die Gestaltung der entsprechenden Regelprämien für Aufgaben wie die visuelle Unterkategorisierung und Objekterkennung überwindet die visuelle RFT die Einschränkungen der Deepseek-R1-Methode, die auf Text, mathematisches Denken und andere Bereiche beschränkt ist und eine neue Möglichkeit für das LVLM-Training bietet. Vis
 Wie kann man adaptives Layout der Y-Achse-Position in Webanmerkungen implementieren?
Apr 04, 2025 pm 11:30 PM
Wie kann man adaptives Layout der Y-Achse-Position in Webanmerkungen implementieren?
Apr 04, 2025 pm 11:30 PM
Der ad-axis-Position adaptive Algorithmus für Webanmerkungen In diesem Artikel wird untersucht, wie Annotationsfunktionen ähnlich wie Word-Dokumente implementiert werden, insbesondere wie man mit dem Intervall zwischen Anmerkungen umgeht ...
