
 Technologie-Peripheriegeräte
KI
WizardLM-2, das „sehr nah an GPT-4' ist, wurde von Microsoft dringend zurückgezogen. Was ist die Insider-Geschichte?
Technologie-Peripheriegeräte
KI
WizardLM-2, das „sehr nah an GPT-4' ist, wurde von Microsoft dringend zurückgezogen. Was ist die Insider-Geschichte?
WizardLM-2, das „sehr nah an GPT-4' ist, wurde von Microsoft dringend zurückgezogen. Was ist die Insider-Geschichte?

Vor einiger Zeit hat Microsoft einen eigenen Fehler begangen: Es hat WizardLM-2 großartig als Open-Source-Version bereitgestellt und es dann kurz darauf sauber zurückgezogen.
Aktuell verfügbare Release-Informationen für WizardLM-2, ein Open-Source-Großmodell, das „wirklich mit GPT-4 vergleichbar“ ist und eine verbesserte Leistung in komplexem Chat, Mehrsprachigkeit, Inferenz und Agentur bietet.
Die Serie umfasst drei Modelle: WizardLM-2 8x22B, WizardLM-2 70B und WizardLM-2 7B. Darunter:
- WizardLM-2 8x22B ist das fortschrittlichste Modell und das beste Open-Source-LLM basierend auf interner Bewertung für hochkomplexe Aufgaben.
- WizardLM-2 70B verfügt über Inferenzfunktionen auf höchstem Niveau und ist die erste Wahl in dieser Größenordnung;
- WizardLM-2 7B ist das schnellste Modell mit einer Leistung, die mit bestehenden führenden Open-Source-Modellen vergleichbar ist, die zehnmal größer sind.
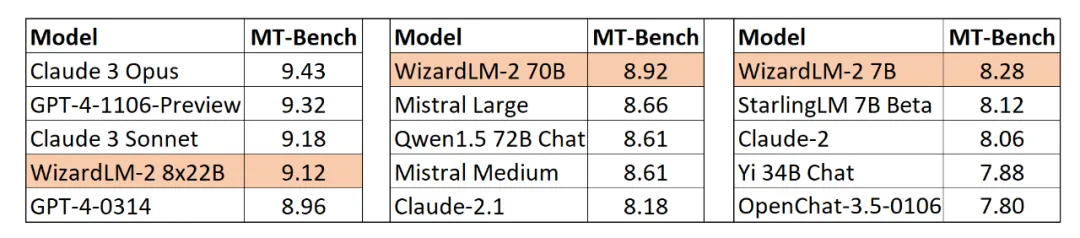
Darüber hinaus liegen die Fähigkeiten von WizardLM-28x22B laut menschlicher Präferenzbewertung „nur geringfügig hinter der GPT-4-1106-Vorschau, aber deutlich stärker als CommandRPlus und GPT4-0314.“

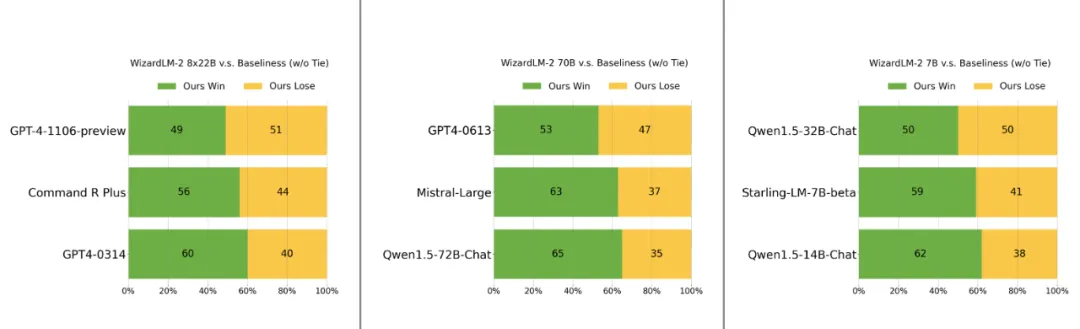
Wird es ein weiterer Open-Source-Meilenstein wie LLaMa 3?
Während alle damit beschäftigt waren, das Modell herunterzuladen, zog das Team plötzlich alles zurück: Blog, GitHub, HuggingFace bekamen alle 404.
Bildquelle: https://wizardlm.github.io/WizardLM2/
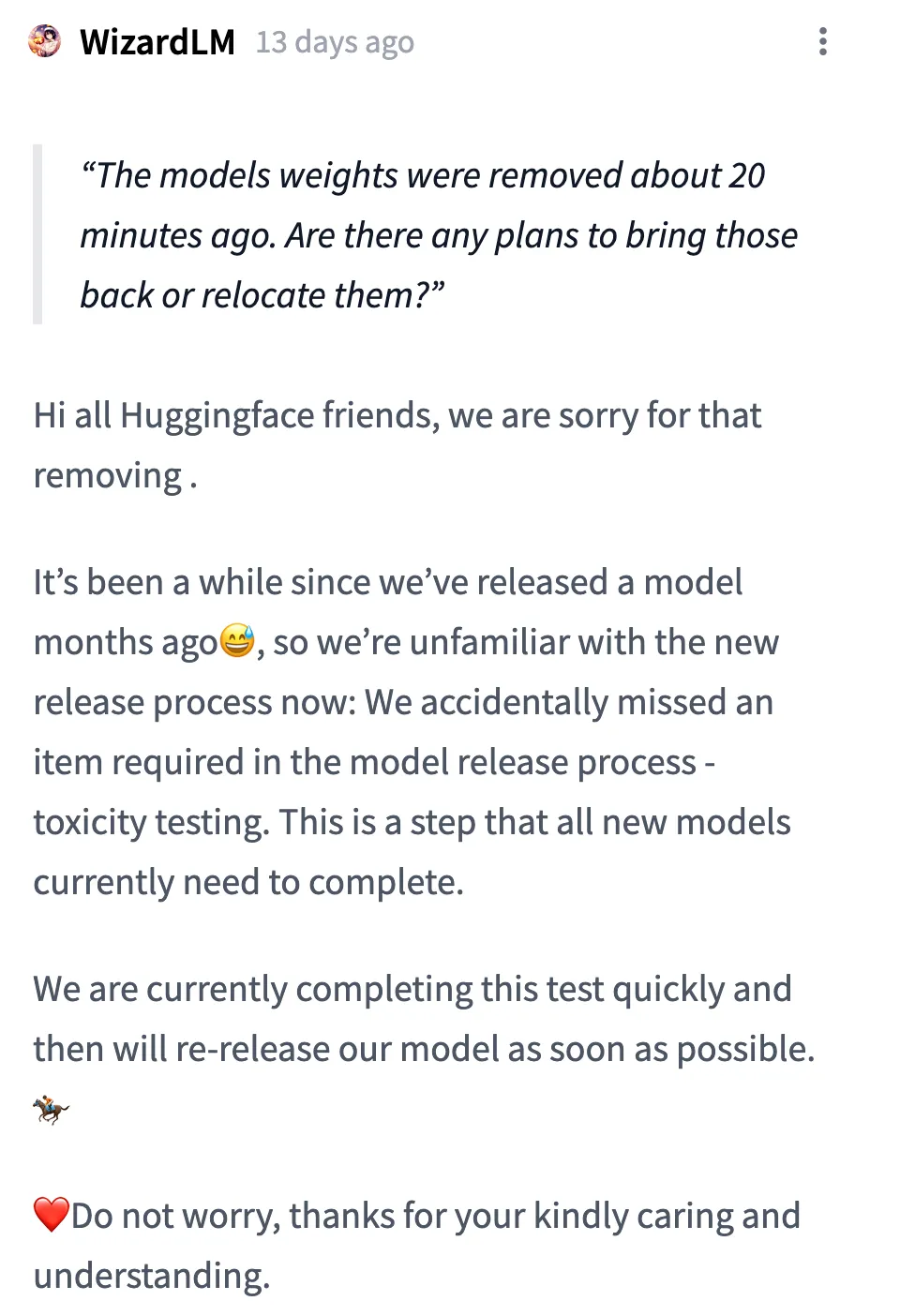
Die Erklärung des Teams lautet:
Hallo an alle Huggingface-Freunde! Entschuldigung, wir haben das Modell entfernt. Es ist schon eine Weile her, dass wir ein Modell von vor ein paar Monaten veröffentlicht haben, daher sind wir mit dem neuen Veröffentlichungsprozess jetzt nicht vertraut: Wir haben versehentlich einen notwendigen Punkt im Modellfreigabeprozess ausgelassen – die Toxizitätsprüfung. Dies ist ein Schritt, den derzeit alle neuen Modelle absolvieren müssen.
Wir schließen diesen Test derzeit zügig ab und werden unser Modell so schnell wie möglich erneut veröffentlichen. Machen Sie sich keine Sorgen, vielen Dank für Ihre Sorge und Ihr Verständnis.
Aber die Aufmerksamkeit und Diskussion der KI-Community zu WizardLM-2 hat nicht aufgehört. Es gibt mehrere Zweifel:

Erstens handelt es sich bei den gelöschten Open-Source-Projekten nicht nur um WizardLM-2. Die gesamte Arbeit der Wizard-Serie ist verschwunden, einschließlich der vorherigen WizardMath und WizardCoder.
Zweitens fragten einige Leute, warum der Blog auch gelöscht wurde, als die Modellgewichte gelöscht wurden? Wenn nur der Testteil fehlt, besteht keine Notwendigkeit, ihn vollständig zurückzuziehen.
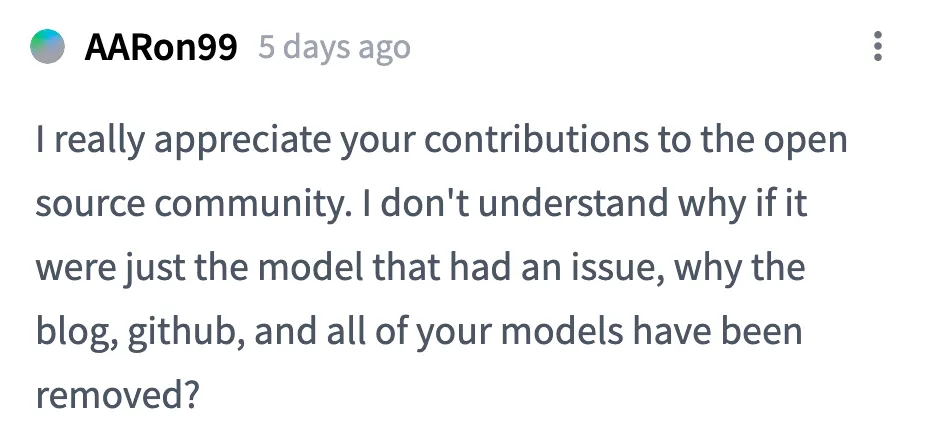

Die Erklärung des Teams lautet: „Gemäß den einschlägigen Vorschriften.“ Noch weiß es niemand.

Drittens gibt es auch Spekulationen, dass das Team hinter WizardLM gefeuert wurde und dass auch der Rückzug des Wizard-Serienprojekts erzwungen wurde.
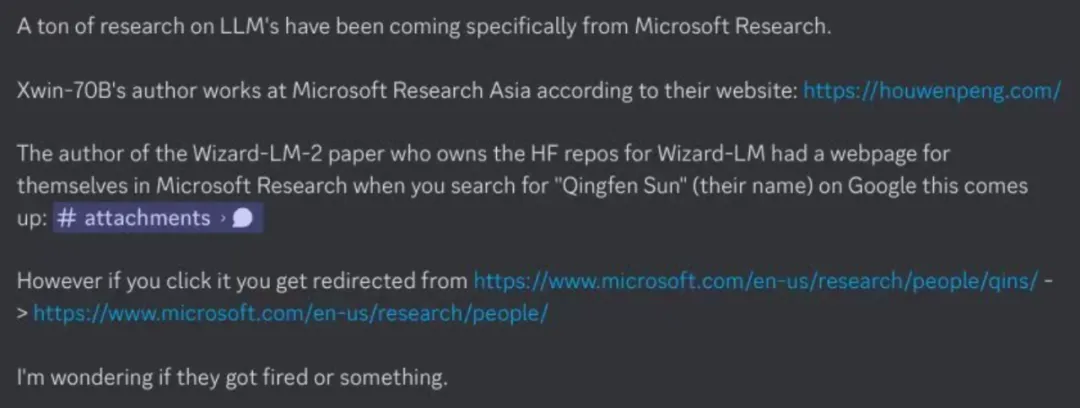
Diese Spekulation wurde jedoch vom Team dementiert:
Quelle: https://x.com/_Mira___Mira_/status/1783716276944486751
Bildquelle: https ://x.com/DavidFSWD/status/1783682898786152470
Und jetzt suchen wir nach dem Namen des Autors, und er ist nicht vollständig von der offiziellen Website von Microsoft verschwunden:
Quelle: https://www .microsoft.com/en-us/research/people/qins/
Viertens spekulieren einige Leute, dass Microsoft dieses Open-Source-Modell zurückgezogen hat, erstens weil die Leistung zu nahe an GPT-4 liegt, und zweitens wegen der technischen Roadmap mit OpenAI „Crash“.
Was ist die konkrete Route? Wir können einen Blick auf die technischen Details der Original-Blogseite werfen.
Das Team gab an, dass durch LLM-Training die vom Menschen erzeugten Daten in der Natur zunehmend erschöpft werden und KI-sorgfältig erstellte Daten und KI-Schritt-für-Schritt-überwachte Modelle der einzige Weg zu einer leistungsfähigeren KI sein werden.
Im vergangenen Jahr hat das Microsoft-Team ein synthetisches Trainingssystem entwickelt, das vollständig auf künstlicher Intelligenz basiert, wie in der folgenden Abbildung dargestellt.
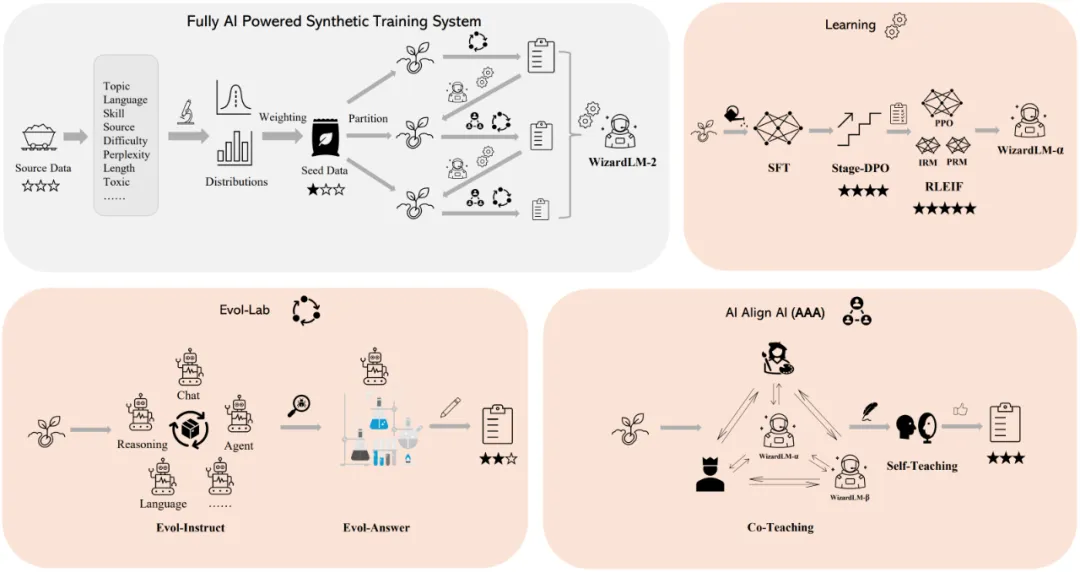
ist grob in mehrere Abschnitte unterteilt:

Datenvorverarbeitung:
- Datenanalyse: Verwenden Sie diese Pipeline, um die Verteilung verschiedener Attribute der neuen Quelldaten zu erhalten. Es hilft, ein vorläufiges Verständnis der Daten zu haben.
- Gewichtete Stichprobe: Die Verteilung der optimalen Trainingsdaten stimmt oft nicht mit der natürlichen Verteilung des menschlichen Chat-Korpus überein. Es ist notwendig, die Gewichtung jedes Attributs in den Trainingsdaten basierend auf experimentellen Erfahrungen anzupassen. Evol Lab:
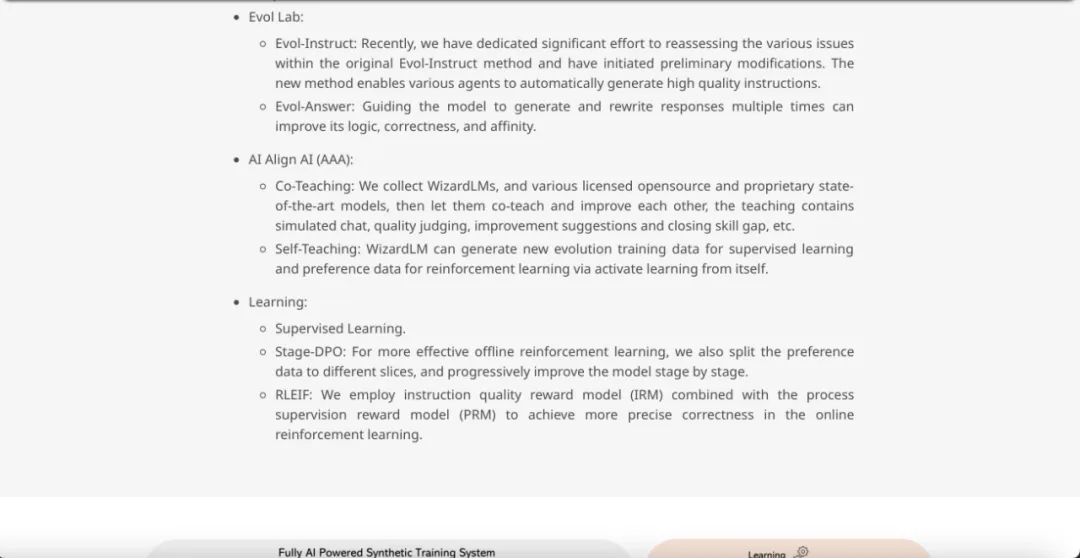
Nach anfänglichen Modifikationen ermöglicht die neue Methode verschiedenen Agenten, automatisch hochwertige Anweisungen zu generieren. Evol-Antwort: Führen Sie das Modell dazu, Antworten mehrmals zu generieren und neu zu schreiben, was seine Logik, Korrektheit und Affinität verbessern kann.
- AI Align AI (AAA):
Selbstlernen: WizardLM kann neue evolutionäre Trainingsdaten für überwachtes Lernen und Präferenzdaten für verstärkendes Lernen durch Aktivierungslernen generieren.
- Lernen:
Phase – DPO: Um das Offline-Reinforcement-Learning effektiver durchzuführen, werden die Vorzugsdaten in verschiedene Fragmente aufgeteilt und das Modell Schritt für Schritt verbessert.
- RLEIF: Verwendung einer Methode, die das Instruction Quality Reward Model (IRM) und das Process Supervision Reward Model (PRM) kombiniert, um eine präzisere Korrektheit beim Online-Reinforcement-Learning zu erreichen.
- Das Letzte, was ich sagen möchte, ist, dass alle Spekulationen umsonst sind. Freuen wir uns auf das Comeback von WizardLM-2.
Das obige ist der detaillierte Inhalt vonWizardLM-2, das „sehr nah an GPT-4' ist, wurde von Microsoft dringend zurückgezogen. Was ist die Insider-Geschichte?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Laravels Geospatial: Optimierung interaktiver Karten und großen Datenmengen
Apr 08, 2025 pm 12:24 PM
Verarbeiten Sie 7 Millionen Aufzeichnungen effizient und erstellen Sie interaktive Karten mit Geospatial -Technologie. In diesem Artikel wird untersucht, wie über 7 Millionen Datensätze mithilfe von Laravel und MySQL effizient verarbeitet und in interaktive Kartenvisualisierungen umgewandelt werden können. Erstes Herausforderungsprojektanforderungen: Mit 7 Millionen Datensätzen in der MySQL -Datenbank wertvolle Erkenntnisse extrahieren. Viele Menschen erwägen zunächst Programmiersprachen, aber ignorieren die Datenbank selbst: Kann sie den Anforderungen erfüllen? Ist Datenmigration oder strukturelle Anpassung erforderlich? Kann MySQL einer so großen Datenbelastung standhalten? Voranalyse: Schlüsselfilter und Eigenschaften müssen identifiziert werden. Nach der Analyse wurde festgestellt, dass nur wenige Attribute mit der Lösung zusammenhängen. Wir haben die Machbarkeit des Filters überprüft und einige Einschränkungen festgelegt, um die Suche zu optimieren. Kartensuche basierend auf der Stadt
 Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Wie man MySQL löst, kann nicht gestartet werden
Apr 08, 2025 pm 02:21 PM
Es gibt viele Gründe, warum MySQL Startup fehlschlägt und durch Überprüfung des Fehlerprotokolls diagnostiziert werden kann. Zu den allgemeinen Ursachen gehören Portkonflikte (prüfen Portbelegung und Änderung der Konfiguration), Berechtigungsprobleme (Überprüfen Sie den Dienst Ausführen von Benutzerberechtigungen), Konfigurationsdateifehler (Überprüfung der Parametereinstellungen), Datenverzeichniskorruption (Wiederherstellung von Daten oder Wiederaufbautabellenraum), InnoDB-Tabellenraumprobleme (prüfen IBDATA1-Dateien), Plug-in-Ladeversagen (Überprüfen Sie Fehlerprotokolle). Wenn Sie Probleme lösen, sollten Sie sie anhand des Fehlerprotokolls analysieren, die Hauptursache des Problems finden und die Gewohnheit entwickeln, Daten regelmäßig zu unterstützen, um Probleme zu verhindern und zu lösen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineers (Plattformen) benötigen Kreise
Apr 08, 2025 pm 12:27 PM
Remote Senior Backend Engineer Job Vacant Company: Circle Standort: Remote-Büro-Jobtyp: Vollzeitgehalt: 130.000 bis 140.000 US-Dollar Stellenbeschreibung Nehmen Sie an der Forschung und Entwicklung von Mobilfunkanwendungen und öffentlichen API-bezogenen Funktionen, die den gesamten Lebenszyklus der Softwareentwicklung abdecken. Die Hauptaufgaben erledigen die Entwicklungsarbeit unabhängig von RubyonRails und arbeiten mit dem Front-End-Team von React/Redux/Relay zusammen. Erstellen Sie die Kernfunktionalität und -verbesserungen für Webanwendungen und arbeiten Sie eng mit Designer und Führung während des gesamten funktionalen Designprozesses zusammen. Fördern Sie positive Entwicklungsprozesse und priorisieren Sie die Iterationsgeschwindigkeit. Erfordert mehr als 6 Jahre komplexes Backend für Webanwendungen
 Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
Kann MySQL JSON zurückgeben?
Apr 08, 2025 pm 03:09 PM
MySQL kann JSON -Daten zurückgeben. Die JSON_EXTRACT -Funktion extrahiert Feldwerte. Über komplexe Abfragen sollten Sie die Where -Klausel verwenden, um JSON -Daten zu filtern, aber auf die Leistungsauswirkungen achten. Die Unterstützung von MySQL für JSON nimmt ständig zu, und es wird empfohlen, auf die neuesten Versionen und Funktionen zu achten.
 Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Verstehen von Säureeigenschaften: Die Säulen einer zuverlässigen Datenbank
Apr 08, 2025 pm 06:33 PM
Detaillierte Erläuterung von Datenbanksäureattributen Säureattribute sind eine Reihe von Regeln, um die Zuverlässigkeit und Konsistenz von Datenbanktransaktionen sicherzustellen. Sie definieren, wie Datenbanksysteme Transaktionen umgehen, und sorgen dafür, dass die Datenintegrität und -genauigkeit auch im Falle von Systemabstürzen, Leistungsunterbrechungen oder mehreren Benutzern gleichzeitiger Zugriff. Säureattributübersicht Atomizität: Eine Transaktion wird als unteilbare Einheit angesehen. Jeder Teil schlägt fehl, die gesamte Transaktion wird zurückgerollt und die Datenbank behält keine Änderungen bei. Wenn beispielsweise eine Banküberweisung von einem Konto abgezogen wird, jedoch nicht auf ein anderes erhöht wird, wird der gesamte Betrieb widerrufen. begintransaktion; updateAccountsSetBalance = Balance-100WH
 Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
Master SQL Limit -Klausel: Steuern Sie die Anzahl der Zeilen in einer Abfrage
Apr 08, 2025 pm 07:00 PM
SQllimit -Klausel: Steuern Sie die Anzahl der Zeilen in Abfrageergebnissen. Die Grenzklausel in SQL wird verwendet, um die Anzahl der von der Abfrage zurückgegebenen Zeilen zu begrenzen. Dies ist sehr nützlich, wenn große Datensätze, paginierte Anzeigen und Testdaten verarbeitet werden und die Abfrageeffizienz effektiv verbessern können. Grundlegende Syntax der Syntax: SelectColumn1, Spalte2, ... Fromtable_Namelimitnumber_of_rows; number_of_rows: Geben Sie die Anzahl der zurückgegebenen Zeilen an. Syntax mit Offset: SelectColumn1, Spalte2, ... Fromtable_NamelimitOffset, Number_of_rows; Offset: Skip überspringen
 Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der Hauptschlüssel von MySQL kann null sein
Apr 08, 2025 pm 03:03 PM
Der MySQL -Primärschlüssel kann nicht leer sein, da der Primärschlüssel ein Schlüsselattribut ist, das jede Zeile in der Datenbank eindeutig identifiziert. Wenn der Primärschlüssel leer sein kann, kann der Datensatz nicht eindeutig identifiziert werden, was zu Datenverwirrung führt. Wenn Sie selbstsinkrementelle Ganzzahlsspalten oder UUIDs als Primärschlüssel verwenden, sollten Sie Faktoren wie Effizienz und Raumbelegung berücksichtigen und eine geeignete Lösung auswählen.
