
 Technologie-Peripheriegeräte
KI
Schließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt
Technologie-Peripheriegeräte
KI
Schließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt
Schließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt

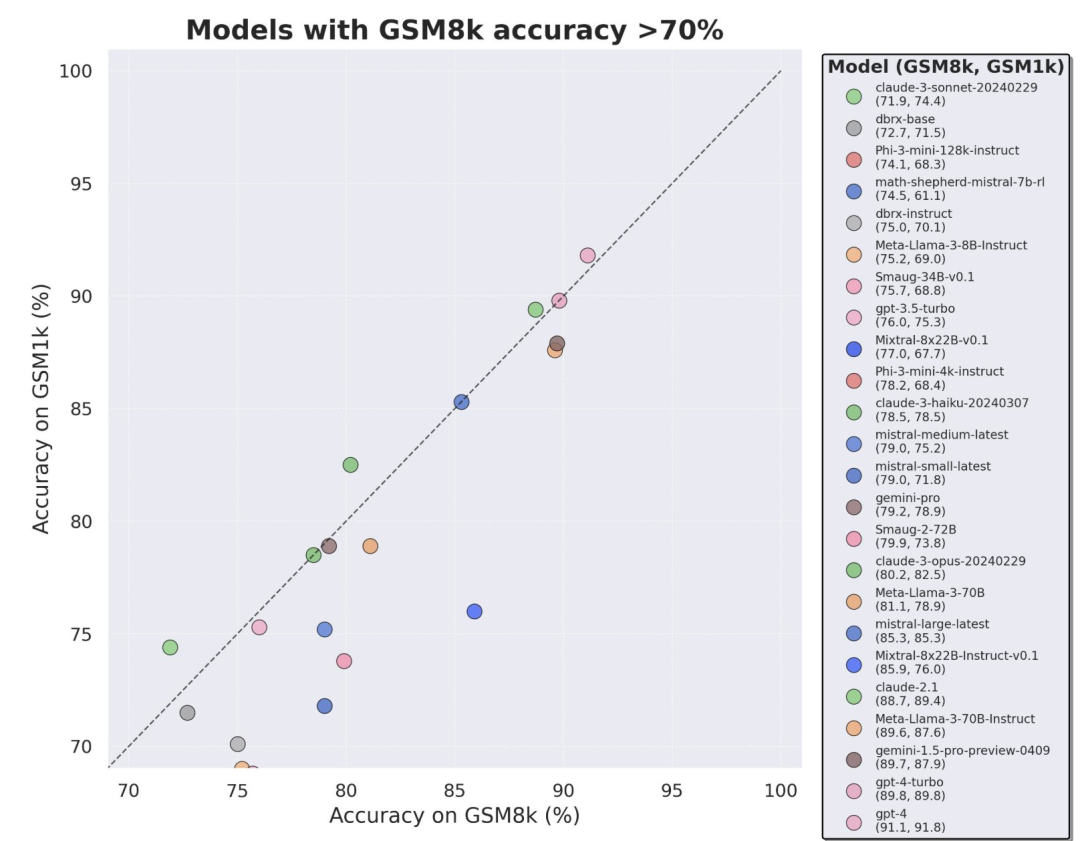
Die Verbesserung der Argumentationsfähigkeiten großer Sprachmodelle ist eine der wichtigsten Richtungen der aktuellen Forschung. Bei dieser Art von Aufgaben scheinen viele kleine Modelle, die kürzlich veröffentlicht wurden, gute Leistungen zu erbringen und solche Aufgaben gut zu bewältigen. Zum Beispiel Microsofts Phi-3, Mistral 8x22B und andere Modelle.
Forscher wiesen darauf hin, dass es im aktuellen Bereich der Großmodellforschung ein zentrales Problem gibt: Viele Studien versäumen es, die Fähigkeiten bestehender LLMs genau zu bewerten. Dies deutet darauf hin, dass wir mehr Zeit damit verbringen müssen, das aktuelle LLM-Fähigkeitsniveau zu bewerten und zu testen.

Das liegt daran, dass die meisten aktuellen Forschungsergebnisse Testsätze wie GSM8k, MATH, MBPP, HumanEval, SWEBench usw. als Benchmarks verwenden. Da das Modell anhand eines großen Datensatzes aus dem Internet trainiert wird, kann der Trainingsdatensatz Beispiele enthalten, die den Fragen im Benchmark sehr ähnlich sind.
Diese Art der Kontamination kann dazu führen, dass die Denkfähigkeit des Modells falsch eingeschätzt wird – Es kann sein, dass sie während des Trainingsprozesses einfach durch die Frage verwirrt werden und zufällig die richtige Antwort rezitieren.
Gerade wurde in einem Artikel von Scale AI eine eingehende Untersuchung der beliebtesten großen Modelle durchgeführt, darunter OpenAIs GPT-4, Gemini, Claude, Mistral, Llama, Phi, Abdin und andere Serien mit unterschiedlichen Parametermengen . Modell.
Die Testergebnisse bestätigen einen weit verbreiteten Verdacht: Viele Modelle sind durch Benchmark-Daten verunreinigt.
Papiertitel: A Careful Examination of Large Language Model Performance on Grade School Arithmetic
Papierlink: https://arxiv.org/pdf/2405.00332
Um Daten zu vermeiden Aufgrund der Verschmutzungsprobleme verwendeten die Forscher von Scale AI kein LLM oder andere synthetische Datenquellen und verließen sich bei der Erstellung des GSM1k-Datensatzes vollständig auf manuelle Annotation. Ähnlich wie GSM8k enthält GSM1k 1250 mathematische Probleme der Grundstufe. Um faire Benchmark-Tests zu gewährleisten, haben die Forscher ihr Bestes gegeben, um sicherzustellen, dass die Schwierigkeitsverteilung von GSM1k der von GSM8k ähnelt. Auf GSM1k verglichen die Forscher eine Reihe führender Open-Source- und Closed-Source-Sprachmodelle im großen Maßstab und stellten fest, dass das Modell mit der schlechtesten Leistung auf GSM1k 13 % schlechter abschnitt als auf GSM8k.
Besonders die Modellreihen Mistral und Phi, die für ihre geringe Stückzahl und hohe Qualität bekannt sind, weisen laut Testergebnissen von GSM1k durchweg Hinweise auf Überanpassung auf.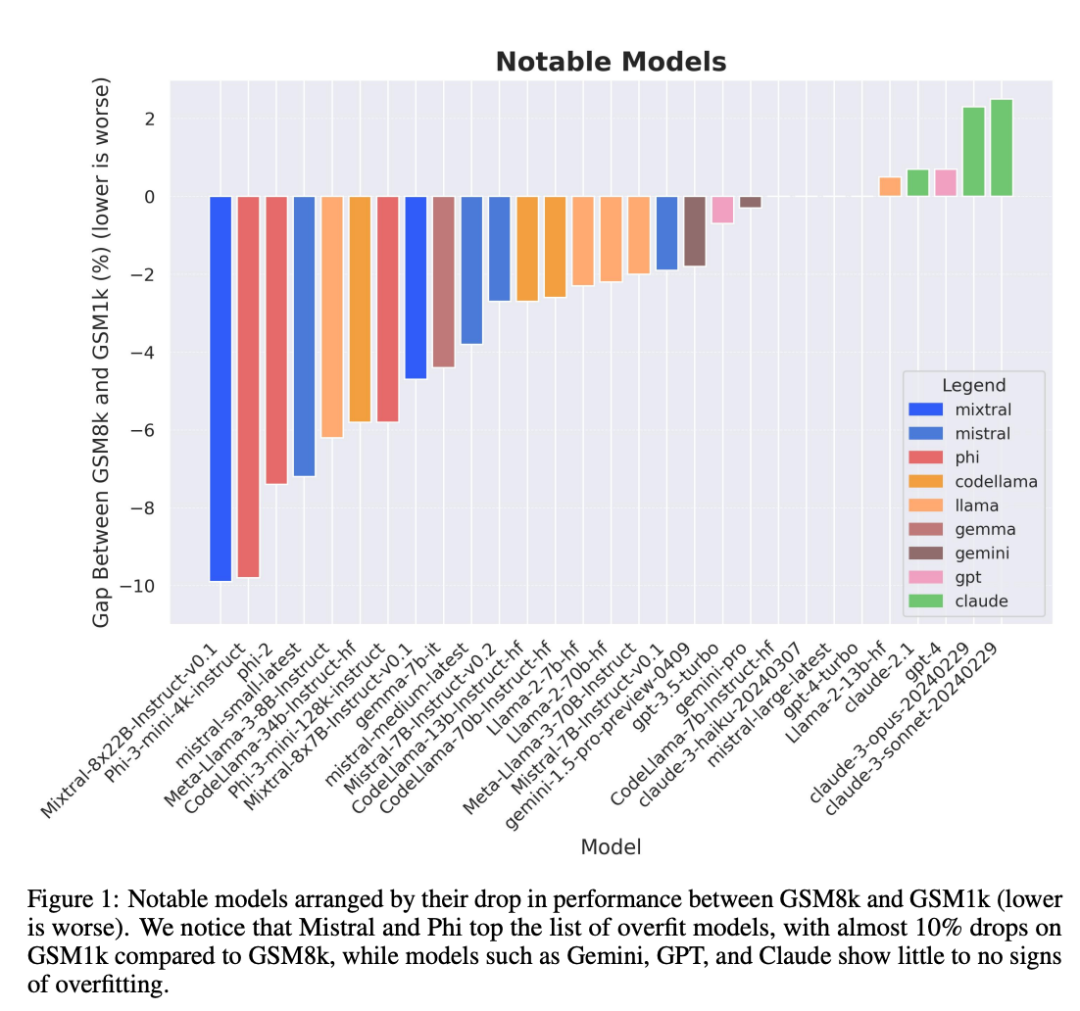
Allerdings haben die Serien Gemini, GPT, Claude und Llama2 nur sehr wenige Anzeichen einer Anpassung gezeigt. Darüber hinaus waren alle Modelle, einschließlich des am stärksten überangepassten Modells, immer noch in der Lage, erfolgreich auf neue mathematische Probleme der Grundschule zu verallgemeinern, wenn auch manchmal mit geringeren Erfolgsraten als in den Basisdaten angegeben.

GSM1k-Datensatz
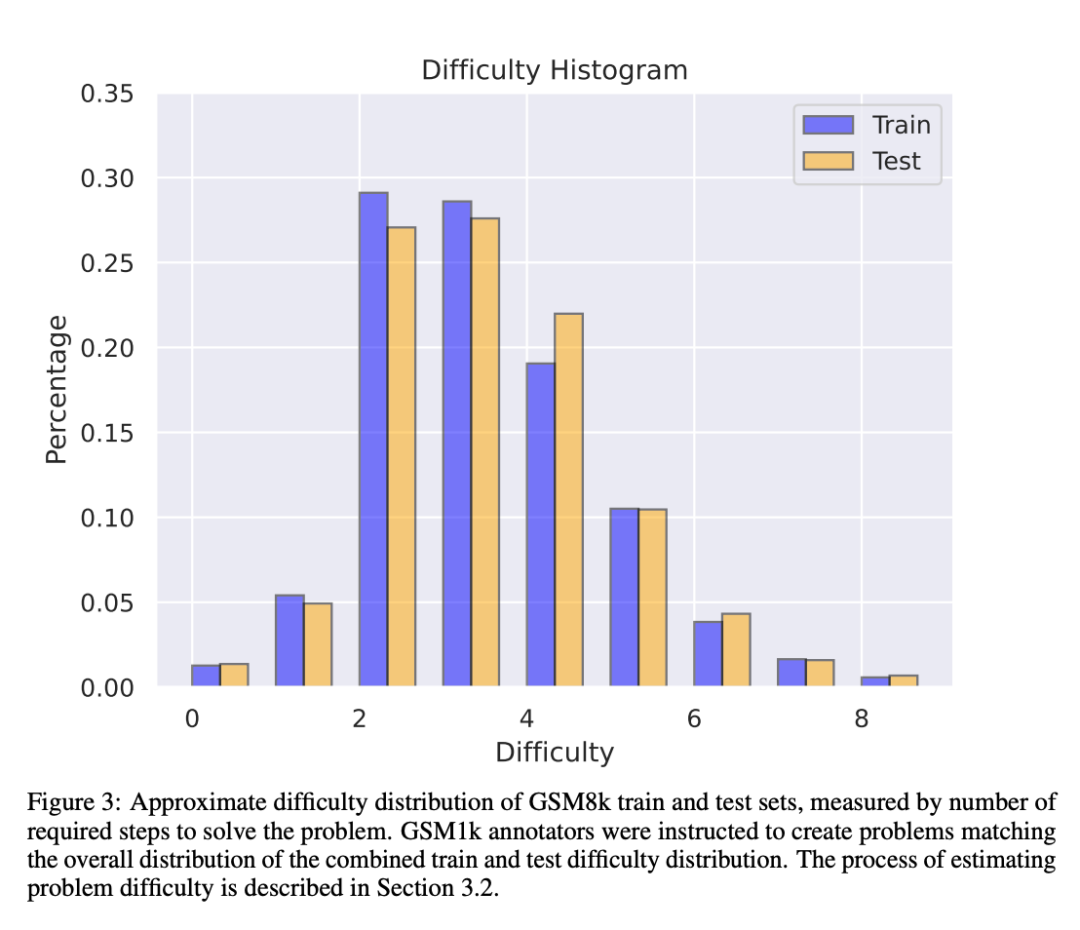
GSM1k enthält 1250 Mathematikfragen für die Grundschule. Diese Probleme können nur mit einfachen mathematischen Überlegungen gelöst werden. Scale AI zeigte jedem menschlichen Annotator drei Beispielfragen aus GSM8k und forderte ihn auf, neue Fragen mit ähnlichem Schwierigkeitsgrad zu stellen, was zum GSM1k-Datensatz führte. Forscher forderten menschliche Annotatoren auf, keine fortgeschrittenen mathematischen Konzepte zu verwenden und nur grundlegende Arithmetik (Addition, Subtraktion, Multiplikation und Division) zur Formulierung von Fragen zu verwenden. Wie bei GSM8k sind die Lösungen aller Probleme positive ganze Zahlen. Bei der Erstellung des GSM1k-Datensatzes wurde kein Sprachmodell verwendet.
Um Datenverschmutzungsprobleme mit dem GSM1k-Datensatz zu vermeiden, wird Scale AI den Datensatz zu diesem Zeitpunkt nicht öffentlich veröffentlichen, sondern das GSM1k-Bewertungsframework als Open Source bereitstellen, das auf dem LM Evaluation Harness von EleutherAI basiert.
Aber Scale AI verspricht: Der vollständige GSM1k-Datensatz wird unter der MIT-Lizenz veröffentlicht, nachdem zuerst eine der folgenden beiden Bedingungen erfüllt ist: (1) Es gibt drei Open-Source-Modelle, die auf verschiedenen vorab trainierten Grundmodelllinien basieren. Bis Ende 2025 eine Genauigkeit von 95 % auf GSM1k erreichen. Zu diesem Zeitpunkt ist es wahrscheinlich, dass Grundschulmathematik kein gültiger Maßstab für die Beurteilung der LLM-Leistung mehr sein wird.
Um proprietäre Modelle zu bewerten, werden Forscher Datensätze über APIs veröffentlichen. Der Grund für diesen Release-Ansatz liegt darin, dass die Autoren glauben, dass LLM-Anbieter im Allgemeinen keine API-Datenpunkte zum Trainieren von Modellmodellen verwenden. Wenn jedoch GSM1k-Daten über die API verloren gehen, haben die Autoren Datenpunkte beibehalten, die nicht im endgültigen GSM1k-Datensatz enthalten sind, und diese Backup-Datenpunkte werden mit GSM1k freigegeben, wenn die oben genannten Bedingungen erfüllt sind.
Sie hoffen, dass künftige Benchmark-Releases einem ähnlichen Muster folgen werden – sie werden zunächst nicht öffentlich veröffentlicht, sondern im Voraus versprochen, sie zu einem späteren Zeitpunkt oder wenn eine bestimmte Bedingung erfüllt ist, um Manipulationen zu verhindern.
Auch trotz der Bemühungen von Scale AI, maximale Konsistenz zwischen GSM8k und GSM1k sicherzustellen. Der Testsatz von GSM8k wurde jedoch öffentlich veröffentlicht und häufig für Modelltests verwendet, sodass GSM1k und GSM8k unter idealen Bedingungen nur Näherungswerte sind. Die folgenden Bewertungsergebnisse werden erhalten, wenn die Verteilungen von GSM8k und GSM1k nicht genau gleich sind.
Bewertungsergebnisse
Zur Bewertung des Modells verwendeten die Forscher den LM Evaluation Harness-Zweig von EleutherAI und verwendeten die Standardeinstellungen. Die laufenden Eingabeaufforderungen für GSM8k- und GSM1k-Probleme sind dieselben. Sie wählen zufällig 5 Proben aus dem GSM8k-Trainingssatz aus, was auch die Standardkonfiguration in diesem Bereich ist (vollständige Informationen zu Eingabeaufforderungen finden Sie in Anhang B).
Alle Open-Source-Modelle werden bei einer Temperatur von 0°C evaluiert, um die Wiederholbarkeit sicherzustellen. Das LM Assessment Kit extrahiert die letzte numerische Antwort in der Antwort und vergleicht sie mit der richtigen Antwort. Daher werden Modellantworten, die „richtige“ Antworten in einem Format liefern, das nicht mit der Stichprobe übereinstimmt, als falsch markiert.
Wenn das Modell bei Open-Source-Modellen mit der Bibliothek kompatibel ist, wird vLLM verwendet, um die Modellinferenz zu beschleunigen. Andernfalls wird standardmäßig die Standard-HuggingFace-Bibliothek für die Inferenz verwendet. Closed-Source-Modelle werden über die LiteLLM-Bibliothek abgefragt, die das API-Aufrufformat für alle evaluierten proprietären Modelle vereinheitlicht. Alle API-Modellergebnisse stammen aus Abfragen zwischen dem 16. und 28. April 2024 und verwenden Standardeinstellungen.
Die Forscher wählten die bewerteten Modelle aufgrund ihrer Beliebtheit aus und bewerteten auch mehrere weniger bekannte Modelle, die im OpenLLMLeaderboard einen hohen Rang einnahmen.
Interessanterweise fanden die Forscher dabei Beweise für das Goodhart-Gesetz: Viele Modelle schnitten bei GSM1k viel schlechter ab als bei GSM8k, was darauf hindeutet, dass sie sich hauptsächlich an der GSM8k-Benchmark orientierten und nicht die Modellschlussfähigkeiten wirklich verbesserten. Die Leistung aller Modelle ist im Anhang D unten dargestellt.
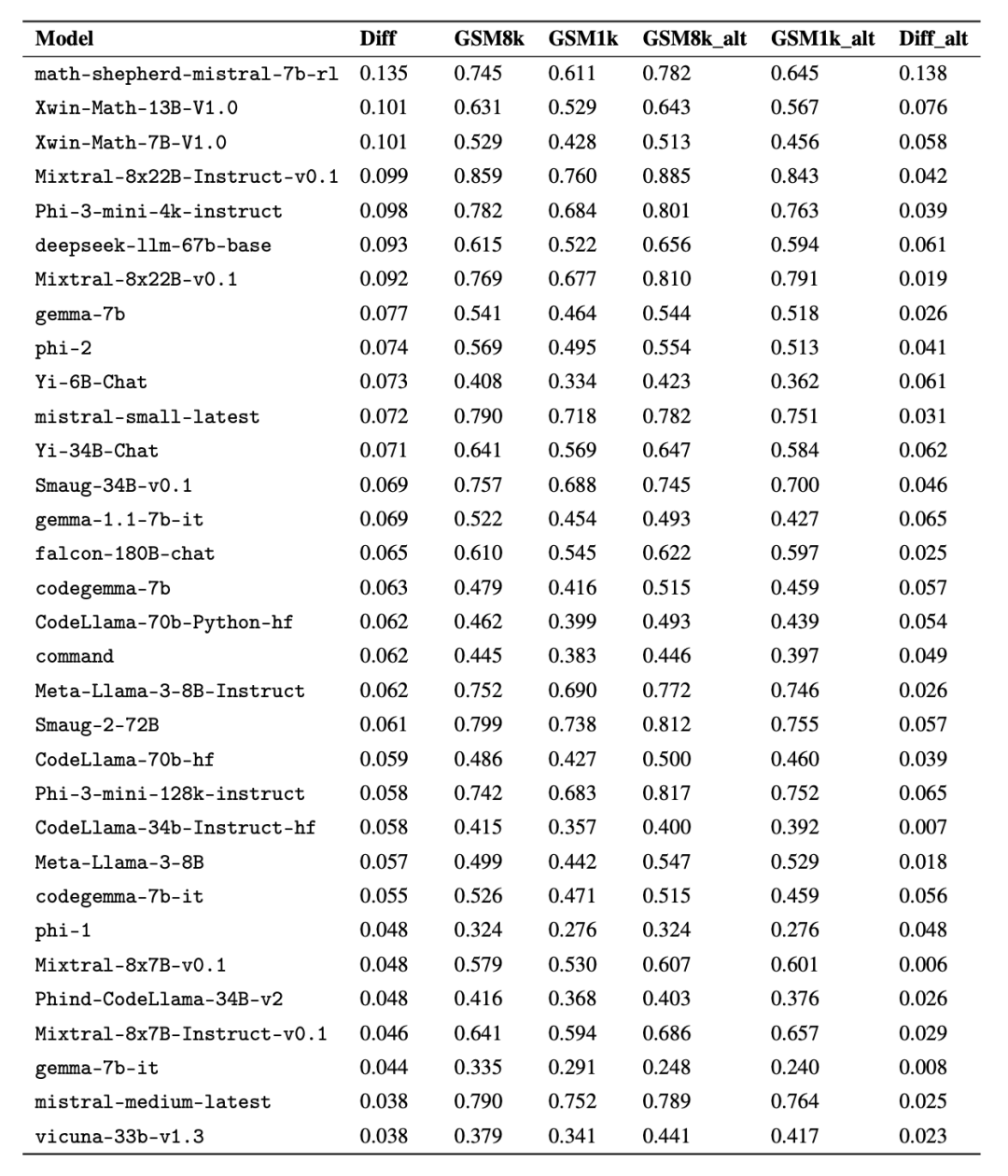
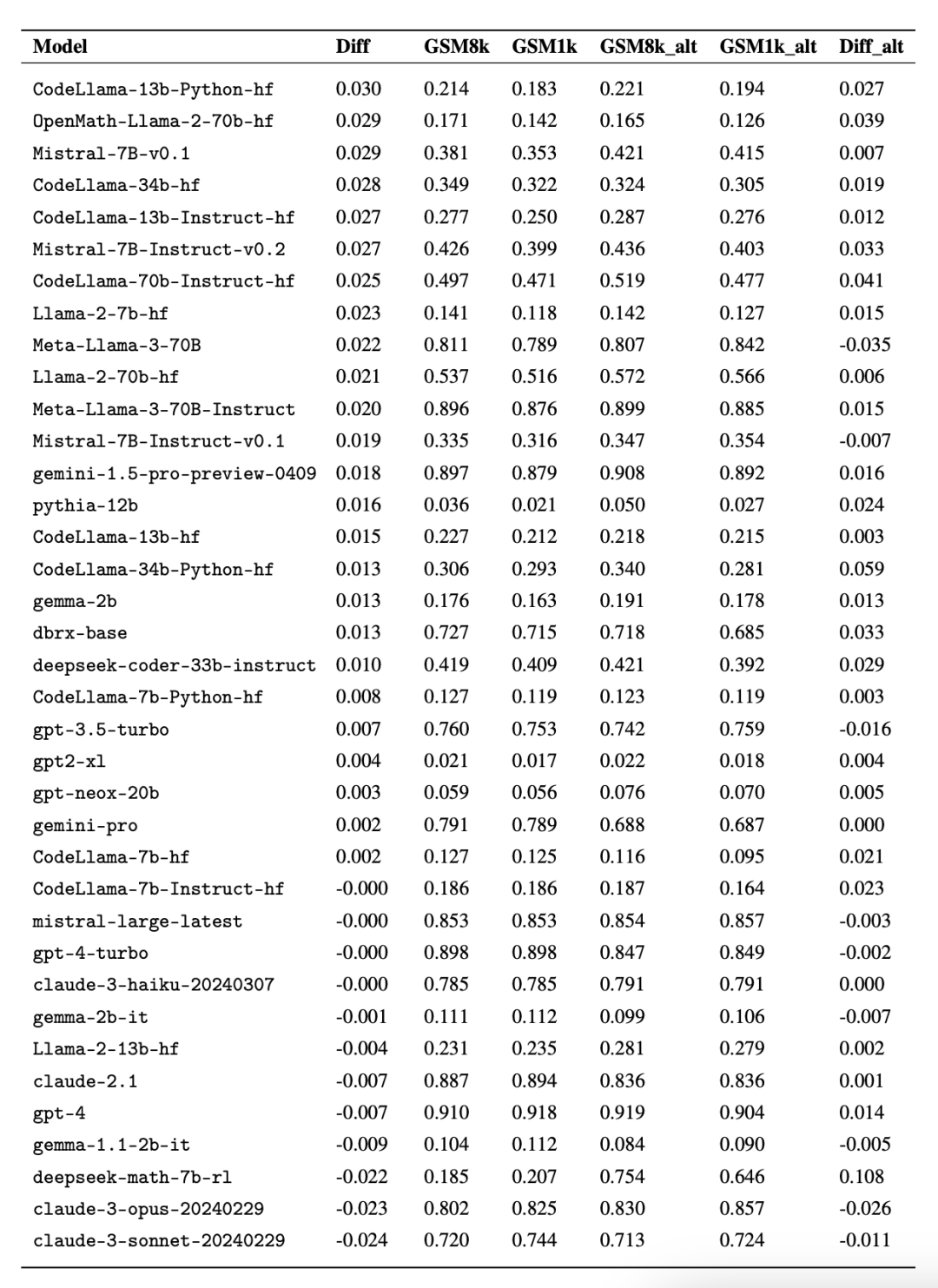
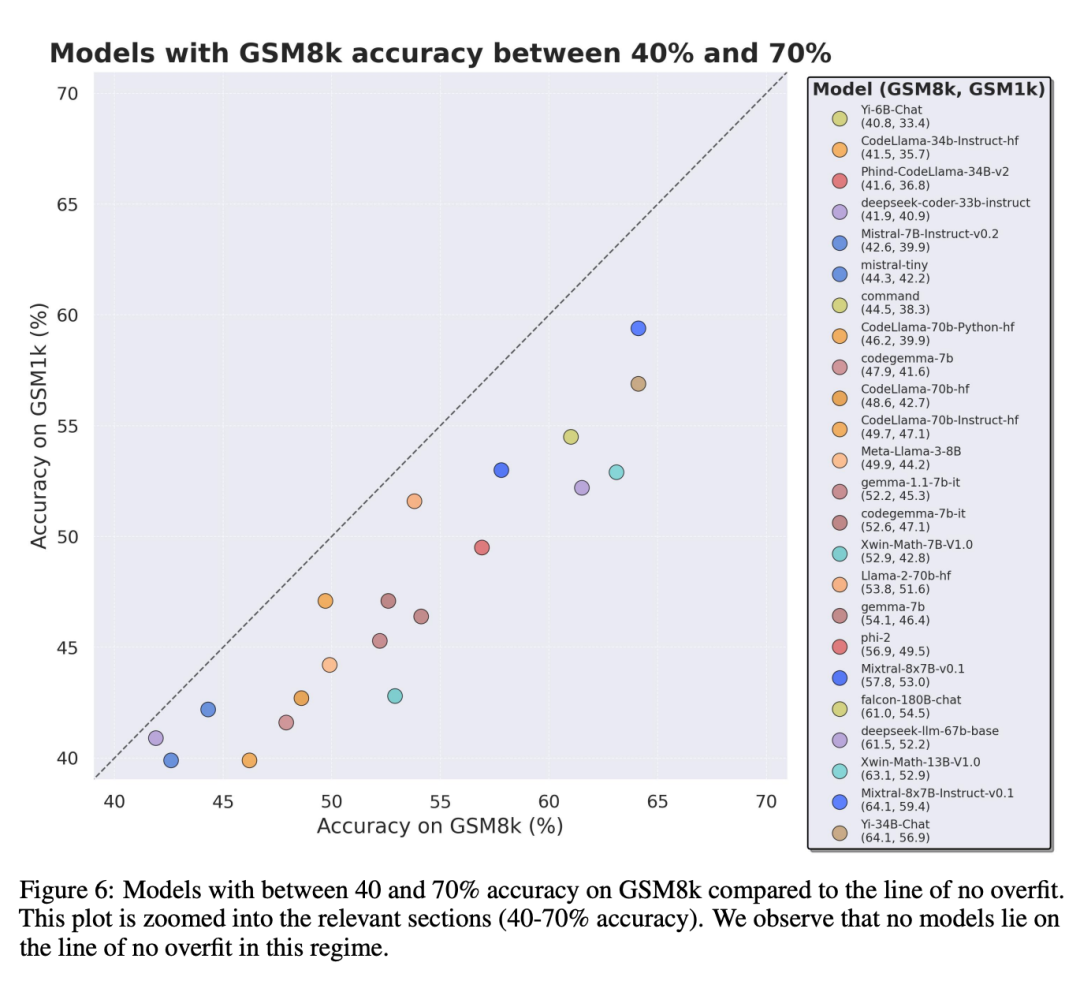
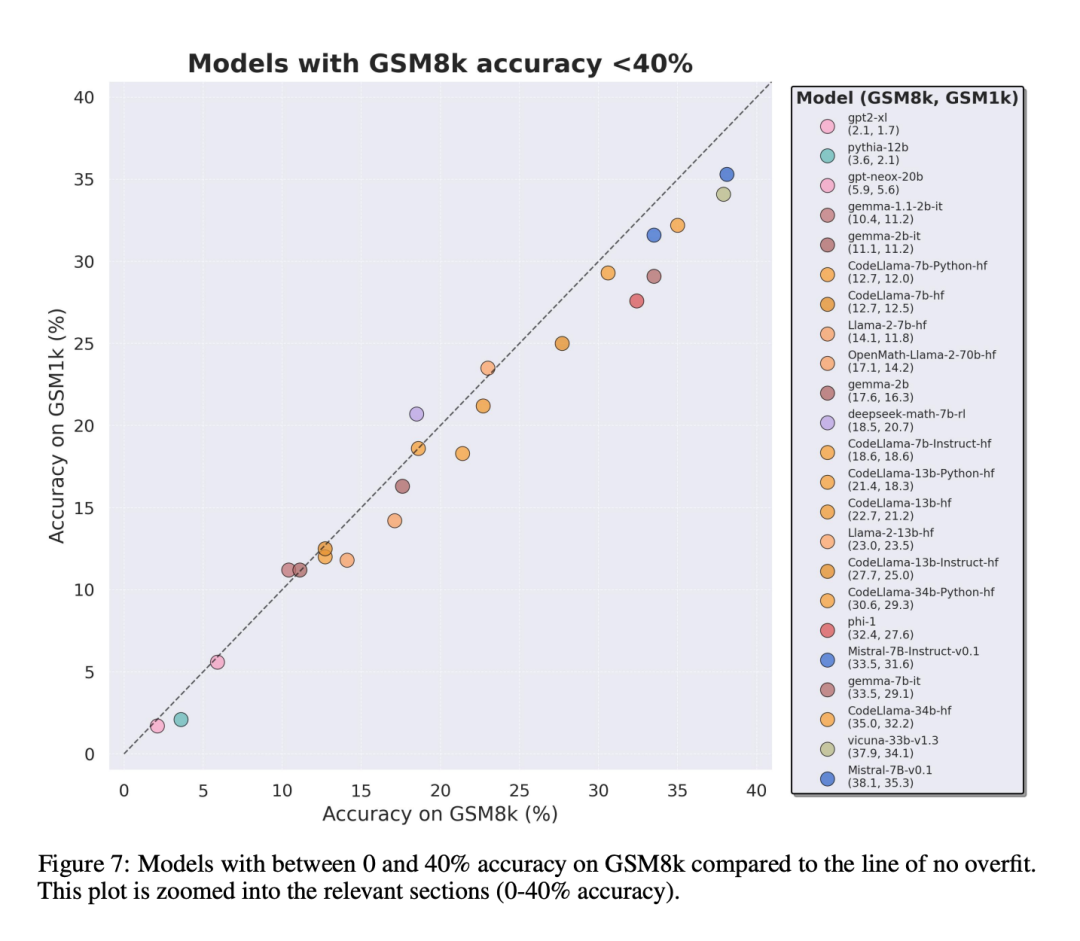
Um einen fairen Vergleich zu ermöglichen, haben die Forscher die Modelle nach ihrer Leistung auf GSM8k unterteilt und sie mit anderen Modellen mit ähnlicher Leistung verglichen (Abbildung 5, Abbildung 6, Abbildung 7).
Welche Schlussfolgerungen wurden gezogen?
Obwohl die Forscher objektive Bewertungsergebnisse mehrerer Modelle lieferten, gaben sie auch an, dass die Interpretation der Bewertungsergebnisse, wie die Interpretation von Träumen, oft eine sehr subjektive Aufgabe sei. Im letzten Teil des Papiers gehen sie auf eine subjektivere Art und Weise auf vier Implikationen der obigen Bewertung ein:
Schlussfolgerung 1: Einige Modellfamilien sind systematisch überfit
Obwohl es oft schwierig ist, dies anhand eines einzelnen Datenpunkts zu bestimmen oder Modellversionsschlussfolgerung, aber die Untersuchung der Modellfamilie und die Beobachtung von Überanpassungsmustern ermöglichen es, eine definitivere Aussage zu treffen. Einige Modellfamilien, darunter Phi und Mistral, zeigen in fast allen Modellversionen und -größen einen Trend zu einer stärkeren Systemleistung auf GSM8k als auf GSM1k. Es gibt andere Modellfamilien wie Yi, Xwin, Gemma und CodeLlama, die dieses Muster ebenfalls in geringerem Maße aufweisen.
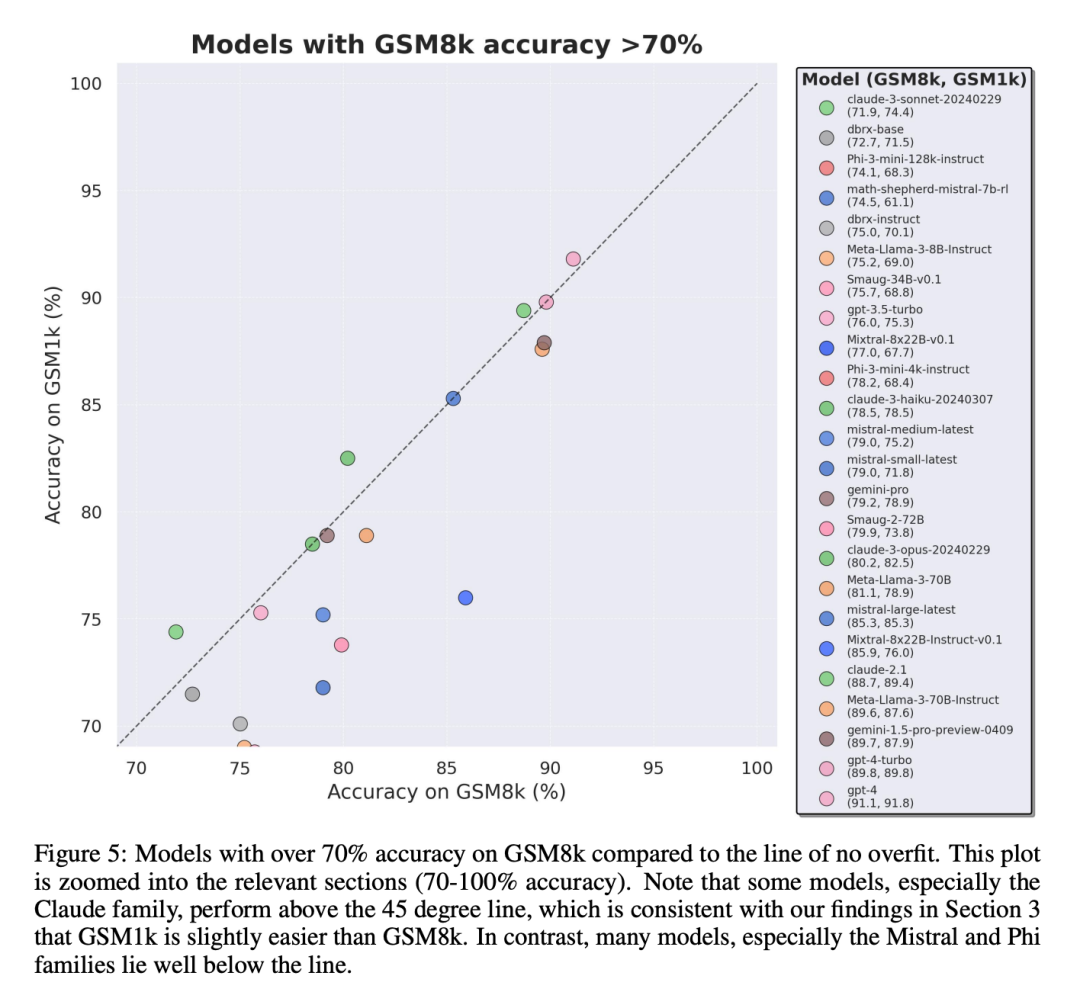
Schlussfolgerung 2: Andere Modelle, insbesondere Modelle der Spitzenklasse, zeigen keine Anzeichen einer Überanpassung.
Viele Modelle weisen in allen Leistungsbereichen leichte Anzeichen einer Überanpassung auf, insbesondere einschließlich des proprietären Mistral Large. Edge-Modelle innerhalb von , scheinen auf GSM8k und GSM1k eine ähnliche Leistung zu erbringen. In diesem Zusammenhang stellen die Forscher zwei mögliche Hypothesen auf: 1) Frontier-Modelle verfügen über ausreichend fortgeschrittene Argumentationsfähigkeiten, sodass sie, selbst wenn das GSM8k-Problem bereits in ihrem Trainingssatz aufgetaucht ist, auf neue Probleme verallgemeinert werden können Seien Sie vorsichtiger hinsichtlich der Datenkontamination.
Während es unmöglich ist, sich den Trainingssatz jedes Modells anzusehen und diese Annahmen zu bestimmen, ist ein Beweis für ersteres, dass Mistral Large das einzige Modell in der Mistral-Serie ist, das keine Anzeichen einer Überanpassung aufweist. Die Annahme, dass Mistral nur sicherstellt, dass sein größtes Modell frei von Datenverunreinigungen ist, erscheint unwahrscheinlich, daher bevorzugen Forscher, dass ein ausreichend leistungsfähiges LLM während des Trainings auch grundlegende Inferenzfähigkeiten erlernt. Wenn ein Modell lernt, gut genug zu argumentieren, um ein Problem mit einem bestimmten Schwierigkeitsgrad zu lösen, kann es auf neue Probleme verallgemeinern, selbst wenn GSM8k in seinem Trainingssatz vorhanden ist.
Schlussfolgerung 3: Das Überanpassungsmodell hat immer noch die Fähigkeit zu argumentieren
Eine der Sorgen vieler Forscher bezüglich der Modellüberanpassung besteht darin, dass das Modell keine Argumentation durchführen kann und sich nur die Antworten in den Trainingsdaten merkt, in diesem Artikel jedoch die Ergebnisse stützte diese Hypothese nicht. Die Tatsache, dass ein Modell übergeeignet ist, bedeutet nicht, dass seine Inferenzfähigkeiten schlecht sind, sondern lediglich, dass es nicht so gut ist, wie der Benchmark anzeigt. Tatsächlich haben Forscher herausgefunden, dass viele überangepasste Modelle immer noch in der Lage sind, neue Probleme zu begründen und zu lösen. Beispielsweise sank die Genauigkeit von Phi-3 zwischen GSM8k und GSM1k um fast 10 %, aber es löste immer noch mehr als 68 % der GSM1k-Probleme korrekt – Probleme, die in seiner Trainingsverteilung sicherlich nicht auftauchten. Diese Leistung ähnelt größeren Modellen wie dbrx-instruct, die fast 35-mal mehr Parameter enthalten. Auch unter Berücksichtigung der Überanpassung ist das Mistral-Modell immer noch eines der stärksten Open-Source-Modelle. Dies liefert weitere Belege für die Schlussfolgerung dieses Artikels, dass ein ausreichend leistungsstarkes Modell grundlegende Schlussfolgerungen lernen kann, selbst wenn die Benchmark-Daten versehentlich in die Trainingsverteilung gelangen, was bei den meisten Overfit-Modellen wahrscheinlich der Fall ist.
Schlussfolgerung 4: Datenkontamination ist möglicherweise keine vollständige Erklärung für Überanpassung.
Eine a priori natürliche Hypothese ist, dass die Hauptursache für Überanpassung Datenkontamination ist, beispielsweise im Vortraining oder in Anweisungen zur Erstellung des Modells Für den Feinabstimmungsteil wurde das Testset durchgesickert. Frühere Untersuchungen haben gezeigt, dass Modelle den Daten, die sie während des Trainings gesehen haben, höhere Log-Likelihoods zuordnen (Carlini et al. [2023]). Die Forscher testeten die Hypothese, dass Datenkontamination die Ursache für Überanpassung ist, indem sie die Wahrscheinlichkeit maßen, mit der das Modell Stichproben aus dem GSM8k-Testsatz generierte, und den Grad der Überanpassung mit GSM8k und GSM1k verglichen.
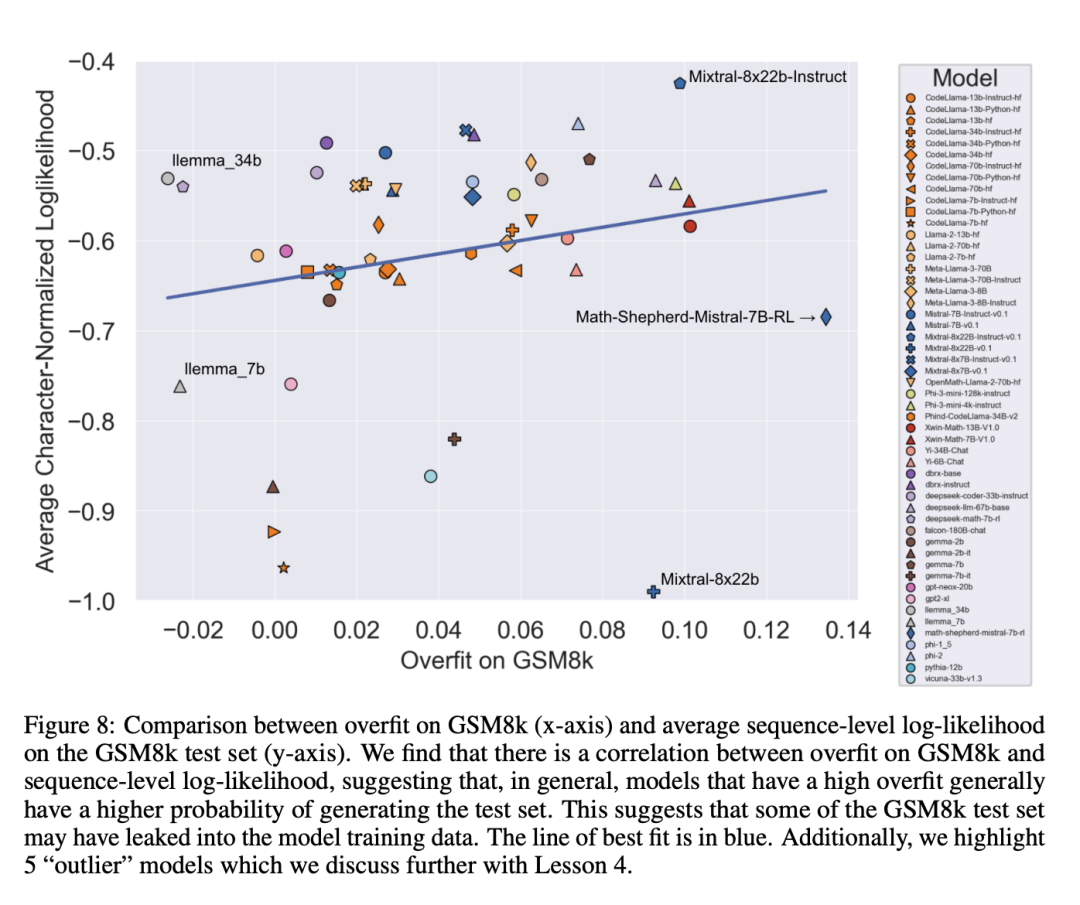
Forscher sagen, dass Datenverschmutzung möglicherweise nicht der einzige Grund ist. Sie beobachteten dies bei mehreren Ausreißern. Ein genauerer Blick auf diese Ausreißer zeigt, dass das Modell mit der niedrigsten Log-Likelihood pro Zeichen (Mixtral-8x22b) und das Modell mit der höchsten Log-Likelihood pro Zeichen (Mixtral-8x22b-Instruct) nicht nur Varianten desselben Modells sind. und weist einen ähnlichen Grad an Überanpassung auf. Interessanter ist, dass das am stärksten angepasste Modell (Math-Shepherd-Mistral-7B-RL (Yu et al. [2023])) eine relativ geringe Log-Likelihood pro Zeichen aufweist (Math Shepherd nutzt synthetische Daten und trainiert Belohnungsmodelle auf Daten auf Prozessebene ).
Daher stellten die Forscher die Hypothese auf, dass der Belohnungsmodellierungsprozess möglicherweise Informationen über die korrekten Inferenzketten für GSM8k durchsickern ließ, obwohl die Probleme selbst nie im Datensatz auftauchten. Schließlich stellten sie fest, dass das Llema-Modell eine hohe Log-Likelihood und eine minimale Überanpassung aufwies. Da diese Modelle Open Source sind und ihre Trainingsdaten bekannt sind, treten im Trainingskorpus mehrere Fälle des GSM8k-Problems auf, wie im Llema-Artikel beschrieben. Die Autoren stellten jedoch fest, dass diese wenigen Fälle nicht zu einer schwerwiegenden Überanpassung führten. Das Vorhandensein dieser Ausreißer deutet darauf hin, dass eine Überanpassung bei GSM8k nicht ausschließlich auf Datenverunreinigungen zurückzuführen ist, sondern auch durch andere indirekte Ursachen verursacht werden kann, beispielsweise dadurch, dass der Modellersteller Daten mit ähnlichen Eigenschaften wie die Basislinie als Trainingsdaten sammelt oder auf der Leistung basiert Benchmark wählt den endgültigen Modellprüfpunkt aus, auch wenn das Modell selbst den GSM8k-Datensatz möglicherweise zu keinem Zeitpunkt während des Trainings gesehen hat. Das Gegenteil ist auch der Fall: Eine geringe Datenverunreinigung führt nicht zwangsläufig zu einer Überanpassung.
Weitere Forschungsdetails finden Sie im Originalpapier.
Das obige ist der detaillierte Inhalt vonSchließlich untersuchte jemand die Überanpassung kleiner Modelle: Zwei Drittel von ihnen wiesen Datenverschmutzung auf, und Microsoft Phi-3 und Mixtral 8x22B wurden benannt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Der DeepMind-Roboter spielt Tischtennis und seine Vor- und Rückhand rutschen in die Luft, wodurch menschliche Anfänger völlig besiegt werden
Aug 09, 2024 pm 04:01 PM
Aber vielleicht kann er den alten Mann im Park nicht besiegen? Die Olympischen Spiele in Paris sind in vollem Gange und Tischtennis hat viel Aufmerksamkeit erregt. Gleichzeitig haben Roboter auch beim Tischtennisspielen neue Durchbrüche erzielt. Gerade hat DeepMind den ersten lernenden Roboteragenten vorgeschlagen, der das Niveau menschlicher Amateurspieler im Tischtennis-Wettkampf erreichen kann. Papieradresse: https://arxiv.org/pdf/2408.03906 Wie gut ist der DeepMind-Roboter beim Tischtennisspielen? Vermutlich auf Augenhöhe mit menschlichen Amateurspielern: Sowohl Vorhand als auch Rückhand: Der Gegner nutzt unterschiedliche Spielstile, und auch der Roboter hält aus: Aufschlagannahme mit unterschiedlichem Spin: Allerdings scheint die Intensität des Spiels nicht so intensiv zu sein wie Der alte Mann im Park. Für Roboter, Tischtennis
 Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Claude ist auch faul geworden! Netizen: Lernen Sie, sich einen Urlaub zu gönnen
Sep 02, 2024 pm 01:56 PM
Der Schulstart steht vor der Tür und nicht nur die Schüler, die bald ins neue Semester starten, sollten auf sich selbst aufpassen, sondern auch die großen KI-Modelle. Vor einiger Zeit war Reddit voller Internetnutzer, die sich darüber beschwerten, dass Claude faul werde. „Sein Niveau ist stark gesunken, es kommt oft zu Pausen und sogar die Ausgabe wird sehr kurz. In der ersten Woche der Veröffentlichung konnte es ein komplettes 4-seitiges Dokument auf einmal übersetzen, aber jetzt kann es nicht einmal eine halbe Seite ausgeben.“ !
 Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Die erste mechanische Klaue! Yuanluobao trat auf der Weltroboterkonferenz 2024 auf und stellte den ersten Schachroboter vor, der das Haus betreten kann
Aug 21, 2024 pm 07:33 PM
Am 21. August fand in Peking die Weltroboterkonferenz 2024 im großen Stil statt. Die Heimrobotermarke „Yuanluobot SenseRobot“ von SenseTime hat ihre gesamte Produktfamilie vorgestellt und kürzlich den Yuanluobot AI-Schachspielroboter – Chess Professional Edition (im Folgenden als „Yuanluobot SenseRobot“ bezeichnet) herausgebracht und ist damit der weltweit erste A-Schachroboter für heim. Als drittes schachspielendes Roboterprodukt von Yuanluobo hat der neue Guoxiang-Roboter eine Vielzahl spezieller technischer Verbesserungen und Innovationen in den Bereichen KI und Maschinenbau erfahren und erstmals die Fähigkeit erkannt, dreidimensionale Schachfiguren aufzunehmen B. durch mechanische Klauen an einem Heimroboter, und führen Sie Mensch-Maschine-Funktionen aus, z. B. Schach spielen, jeder spielt Schach, Überprüfung der Notation usw.
 Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der Weltroboterkonferenz wurde dieser Haushaltsroboter, der „die Hoffnung auf eine zukünftige Altenpflege' in sich trägt, umzingelt
Aug 22, 2024 pm 10:35 PM
Auf der World Robot Conference in Peking ist die Präsentation humanoider Roboter zum absoluten Mittelpunkt der Szene geworden. Am Stand von Stardust Intelligent führte der KI-Roboterassistent S1 drei große Darbietungen mit Hackbrett, Kampfkunst und Kalligraphie auf Ein Ausstellungsbereich, der sowohl Literatur als auch Kampfkunst umfasst, zog eine große Anzahl von Fachpublikum und Medien an. Durch das elegante Spiel auf den elastischen Saiten demonstriert der S1 eine feine Bedienung und absolute Kontrolle mit Geschwindigkeit, Kraft und Präzision. CCTV News führte einen Sonderbericht über das Nachahmungslernen und die intelligente Steuerung hinter „Kalligraphie“ durch. Firmengründer Lai Jie erklärte, dass hinter den seidenweichen Bewegungen die Hardware-Seite die beste Kraftkontrolle und die menschenähnlichsten Körperindikatoren (Geschwindigkeit, Belastung) anstrebt. usw.), aber auf der KI-Seite werden die realen Bewegungsdaten von Menschen gesammelt, sodass der Roboter stärker werden kann, wenn er auf eine schwierige Situation stößt, und lernen kann, sich schnell weiterzuentwickeln. Und agil
 Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Das Team von Li Feifei schlug ReKep vor, um Robotern räumliche Intelligenz zu verleihen und GPT-4o zu integrieren
Sep 03, 2024 pm 05:18 PM
Tiefe Integration von Vision und Roboterlernen. Wenn zwei Roboterhände reibungslos zusammenarbeiten, um Kleidung zu falten, Tee einzuschenken und Schuhe zu packen, gepaart mit dem humanoiden 1X-Roboter NEO, der in letzter Zeit für Schlagzeilen gesorgt hat, haben Sie vielleicht das Gefühl: Wir scheinen in das Zeitalter der Roboter einzutreten. Tatsächlich sind diese seidigen Bewegungen das Produkt fortschrittlicher Robotertechnologie + exquisitem Rahmendesign + multimodaler großer Modelle. Wir wissen, dass nützliche Roboter oft komplexe und exquisite Interaktionen mit der Umgebung erfordern und die Umgebung als Einschränkungen im räumlichen und zeitlichen Bereich dargestellt werden kann. Wenn Sie beispielsweise möchten, dass ein Roboter Tee einschenkt, muss der Roboter zunächst den Griff der Teekanne ergreifen und sie aufrecht halten, ohne den Tee zu verschütten, und ihn dann sanft bewegen, bis die Öffnung der Kanne mit der Öffnung der Tasse übereinstimmt , und neigen Sie dann die Teekanne in einem bestimmten Winkel. Das
 Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bekanntgabe der ACL 2024 Awards: Eines der besten Papers zum Thema Oracle Deciphering von HuaTech, GloVe Time Test Award
Aug 15, 2024 pm 04:37 PM
Bei dieser ACL-Konferenz haben die Teilnehmer viel gewonnen. Die sechstägige ACL2024 findet in Bangkok, Thailand, statt. ACL ist die führende internationale Konferenz im Bereich Computerlinguistik und Verarbeitung natürlicher Sprache. Sie wird von der International Association for Computational Linguistics organisiert und findet jährlich statt. ACL steht seit jeher an erster Stelle, wenn es um akademischen Einfluss im Bereich NLP geht, und ist außerdem eine von der CCF-A empfohlene Konferenz. Die diesjährige ACL-Konferenz ist die 62. und hat mehr als 400 innovative Arbeiten im Bereich NLP eingereicht. Gestern Nachmittag gab die Konferenz den besten Vortrag und weitere Auszeichnungen bekannt. Diesmal gibt es 7 Best Paper Awards (zwei davon unveröffentlicht), 1 Best Theme Paper Award und 35 Outstanding Paper Awards. Die Konferenz verlieh außerdem drei Resource Paper Awards (ResourceAward) und einen Social Impact Award (
 Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 und die umfassende Einführungskonferenz für neue Produkte wurden gemeinsam mit einer Reihe neuer Blockbuster-Produkte veröffentlicht
Aug 08, 2024 am 07:02 AM
Heute Nachmittag begrüßte Hongmeng Zhixing offiziell neue Marken und neue Autos. Am 6. August veranstaltete Huawei die Hongmeng Smart Xingxing S9 und die Huawei-Konferenz zur Einführung neuer Produkte mit umfassendem Szenario und brachte die Panorama-Smart-Flaggschiff-Limousine Xiangjie S9, das neue M7Pro und Huawei novaFlip, MatePad Pro 12,2 Zoll, das neue MatePad Air und Huawei Bisheng mit Mit vielen neuen Smart-Produkten für alle Szenarien, darunter die Laserdrucker der X1-Serie, FreeBuds6i, WATCHFIT3 und der Smart Screen S5Pro, von Smart Travel über Smart Office bis hin zu Smart Wear baut Huawei weiterhin ein Smart-Ökosystem für alle Szenarien auf, um Verbrauchern ein Smart-Erlebnis zu bieten Internet von allem. Hongmeng Zhixing: Huawei arbeitet mit chinesischen Partnern aus der Automobilindustrie zusammen, um die Modernisierung der Smart-Car-Industrie voranzutreiben
 Das erste große UI-Modell in China wird veröffentlicht! Das große Modell von Motiff ist der beste Assistent für Designer und optimiert den UI-Design-Workflow
Aug 19, 2024 pm 04:48 PM
Das erste große UI-Modell in China wird veröffentlicht! Das große Modell von Motiff ist der beste Assistent für Designer und optimiert den UI-Design-Workflow
Aug 19, 2024 pm 04:48 PM
Künstliche Intelligenz entwickelt sich schneller, als Sie sich vorstellen können. Seit GPT-4 die multimodale Technologie in die Öffentlichkeit gebracht hat, sind multimodale Großmodelle in eine Phase rasanter Entwicklung eingetreten, die sich allmählich von der reinen Modellforschung und -entwicklung hin zur Erforschung und Anwendung in vertikalen Bereichen verlagert und tief in alle Lebensbereiche integriert ist. Im Bereich der Schnittstelleninteraktion haben internationale Technologiegiganten wie Google und Apple in die Forschung und Entwicklung großer multimodaler UI-Modelle investiert, die als einziger Weg für die KI-Revolution im Mobiltelefon gelten. In diesem Zusammenhang wurde das erste groß angelegte UI-Modell in China geboren. Am 17. August stellte Motiff, ein Designtool im KI-Zeitalter, auf der IXDC2024 International Experience Design Conference sein unabhängig entwickeltes multimodales UI-Modell vor – das Motiff Model. Dies ist das weltweit erste UI-Design-Tool
