

Vor zwei Tagen veröffentlichte der Turing-Award-Gewinner Yann LeCun den langen Comic „Go to the Moon and Explore Yourself“ erneut, der unter Internetnutzern heftige Diskussionen auslöste.

In der Arbeit „Story Diffusion: Consistent Self-Attention for long-range image and video generation“ schlug das Forschungsteam eine neue Methode namens Story Diffusion zur Erzeugung konsistenter Bilder und Videos zur Beschreibung komplexer Situationen vor. Die Forschung zu diesen Comics stammt von Institutionen wie der Nankai University und ByteDance. ?? GitHub hat einen Betrag von 1.000 Sternen erhalten.

StoryDiffusion kann die Identität mehrerer Charaktere gleichzeitig aufrechterhalten und konsistente Charaktere über eine Reihe von Bildern hinweg generieren.
Darüber hinaus ist StoryDiffusion in der Lage, qualitativ hochwertige Videos zu generieren, die auf generierten konsistenten Bildern oder vom Benutzer eingegebenen Bildern basieren.

Wir wissen, dass die Aufrechterhaltung der Inhaltskonsistenz über eine Reihe generierter Bilder hinweg, insbesondere solche mit komplexen Themen und Details, eine erhebliche Herausforderung für diffusionsbasierte generative Modelle darstellt.
 Daher schlug das Forschungsteam eine neue Methode zur Berechnung der Selbstaufmerksamkeit vor, die als konsistente Selbstaufmerksamkeit bezeichnet wird, indem bei der Generierung von Bildern Verbindungen zwischen Bildern innerhalb eines Stapels hergestellt werden, um die Charaktere konsistent zu halten und thematisch konsistente Bilder ohne Schulung zu generieren.
Daher schlug das Forschungsteam eine neue Methode zur Berechnung der Selbstaufmerksamkeit vor, die als konsistente Selbstaufmerksamkeit bezeichnet wird, indem bei der Generierung von Bildern Verbindungen zwischen Bildern innerhalb eines Stapels hergestellt werden, um die Charaktere konsistent zu halten und thematisch konsistente Bilder ohne Schulung zu generieren.
Um diese Methode auf die Generierung langer Videos auszudehnen, führte das Forschungsteam einen semantischen Bewegungsprädiktor (Semantic Motion Predictor) ein, der Bilder in den semantischen Raum kodiert und Bewegungen im semantischen Raum vorhersagt, um Videos zu generieren. Dies ist stabiler als eine Bewegungsvorhersage, die nur auf dem latenten Raum basiert.


Abbildung 1: Von der StroyDiffusion des Teams generierte Bilder und Videos
Übersicht über die Methode
Die Methode des Forschungsteams kann in zwei Phasen unterteilt werden, wie in den Abbildungen 2 und 3 dargestellt.
In der ersten Stufe nutzt StoryDiffusion Consistent Self-Attention, um themenkonsistente Bilder auf schulungsfreie Weise zu generieren. Diese konsistenten Bilder können direkt beim Storytelling oder als Input für eine zweite Stufe verwendet werden. Im zweiten Schritt erstellt StoryDiffusion konsistente Übergangsvideos auf Basis dieser konsistenten Bilder.

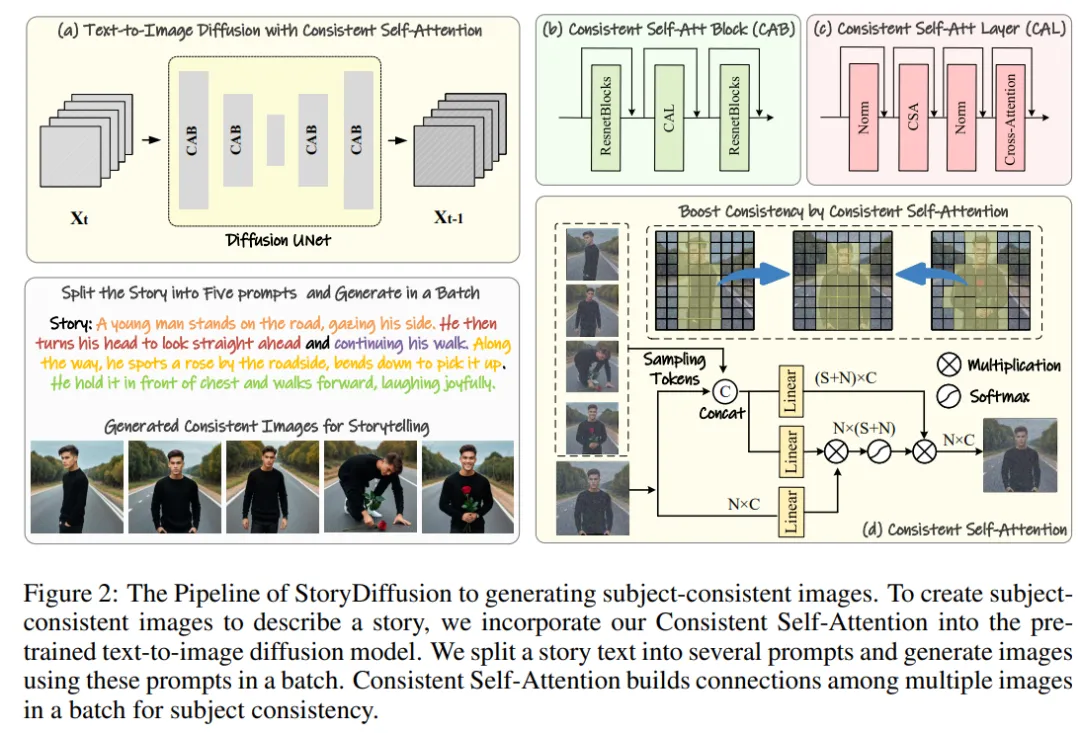
Abbildung 2: StoryDiffusion-Prozessübersicht zur Generierung themenkonsistenter Bilder
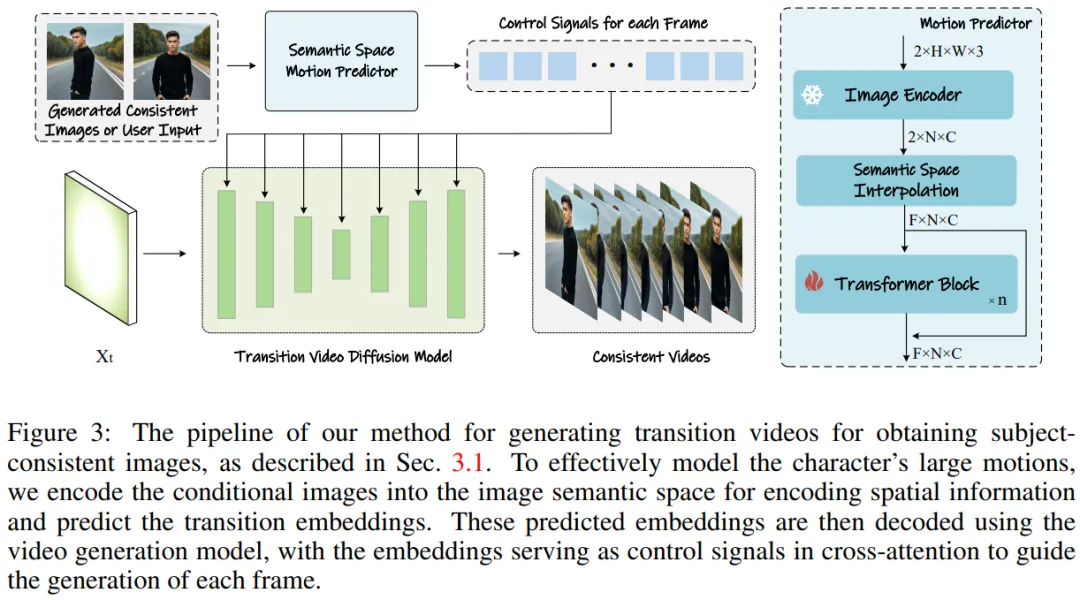 Abbildung 3: Methode zur Generierung von Übergangsvideos, um themenkonsistente Bilder zu erhalten.
Abbildung 3: Methode zur Generierung von Übergangsvideos, um themenkonsistente Bilder zu erhalten.
Das Forschungsteam führte die Methode ein, „wie man ohne Schulung konsistente Bilder mit einem Thema generiert“. Der Schlüssel zur Lösung des oben genannten Problems besteht darin, die Konsistenz der Zeichen in einem Bildstapel aufrechtzuerhalten. Das bedeutet, dass sie während des Generierungsprozesses Verbindungen zwischen einem Stapel von Bildern herstellen müssen.
Nachdem sie die Rolle verschiedener Aufmerksamkeitsmechanismen im Diffusionsmodell erneut untersucht hatten, wurden sie inspiriert, die Verwendung von Selbstaufmerksamkeit zu untersuchen, um die Konsistenz von Bildern innerhalb einer Reihe von Bildern aufrechtzuerhalten, und schlugen Konsistente Selbstaufmerksamkeit – Aufmerksamkeit vor ).
Das Forschungsteam fügt konsistente Selbstaufmerksamkeit in die ursprüngliche Selbstaufmerksamkeitsposition in der U-Net-Architektur des vorhandenen Bildgenerierungsmodells ein und verwendet die ursprünglichen Selbstaufmerksamkeitsgewichte wieder, um kein Training und Plug-and-Play beizubehalten Verwendete Funktionen.
Anhand gepaarter Token führt die Methode des Forschungsteams Selbstaufmerksamkeit auf eine Reihe von Bildern aus und fördert so Interaktionen zwischen verschiedenen Bildmerkmalen. Diese Art der Interaktion fördert die Konvergenz des Modells in Bezug auf Charaktere, Gesichter und Kleidung während der Generierung. Obwohl die Methode der konsistenten Selbstaufmerksamkeit einfach ist und keine Schulung erfordert, kann sie effektiv thematisch konsistente Bilder erzeugen.
Zur besseren Veranschaulichung zeigt das Forschungsteam den Pseudocode in Algorithmus 1.

Semantic Motion Predictor für die Videogenerierung
Das Forschungsteam schlug den Semantic Motion Predictor (Semantic Motion Predictor) vor, der Bilder in den semantischen Bildraum kodiert, um räumliche Informationen zu erfassen. Dies ermöglicht eine genauere Bewegung Vorhersage aus einem gegebenen Start-Frame und End-Frame.
Genauer gesagt verwenden sie in dem vom Team vorgeschlagenen semantischen Bewegungsprädiktor zunächst eine Funktion E, um eine Zuordnung von RGB-Bildern zu bildsemantischen Raumvektoren zu erstellen, um räumliche Informationen zu kodieren.
Das Team verwendete die lineare Ebene nicht direkt als Funktion E. Stattdessen verwendete es einen vortrainierten CLIP-Bildencoder als Funktion E, um seine Zero-Shot-Fähigkeit zur Verbesserung der Leistung zu nutzen.
Mit der Funktion E werden der gegebene Startrahmen F_s und der Endrahmen F_e in bildsemantische Raumvektoren K_s und K_e komprimiert.

Da die Methode des Teams keine Schulung erfordert und Plug-and-Play-fähig ist, verwendeten sie zwei Versionen von Stable Diffusion XL und Stable Diffusion 1.5 All, um themenkonsistente Bilder zu erstellen habe diese Methode implementiert. Um mit den verglichenen Modellen übereinzustimmen, verwendeten sie zum Vergleich dieselben vorab trainierten Gewichte für das Stable-XL-Modell.
Um konsistente Videos zu generieren, implementierten die Forscher ihre Forschungsmethode basierend auf dem Spezialmodell Stable Diffusion 1.5 und integrierten ein vorab trainiertes zeitliches Modul zur Unterstützung der Videogenerierung. Alle verglichenen Modelle verwenden einen klassifikatorfreien Guidance-Score von 7,5 und eine 50-stufige DDIM-Stichprobe.
Vergleich konsistenter Bilderzeugung
Das Team bewertete seinen Ansatz zur Erzeugung themenkonsistenter Bilder, indem es ihn mit zwei hochmodernen Methoden zur ID-Erhaltung verglich – IP-Adapter und Photo Maker.
Um die Leistung zu testen, generierten sie mithilfe von GPT-4 zwanzig Rollenanweisungen und einhundert Aktivitätsanweisungen zur Beschreibung spezifischer Aktivitäten.
Qualitative Ergebnisse sind in Abbildung 4 dargestellt: „StoryDiffusion ist in der Lage, hochkonsistente Bilder zu erzeugen. Während andere Methoden, wie IP-Adapter und PhotoMaker, möglicherweise Bilder mit inkonsistenter Kleidung oder eingeschränkter Textsteuerbarkeit erzeugen.“ Abbildung 4: Vergleich der konsistenten Bilderzeugung mit aktuellen Methoden Die Ergebnisse des quantitativen Vergleichs zeigen die Forscher in Tabelle 1. Die Ergebnisse zeigen: „StoryDiffusion des Teams erzielte bei beiden quantitativen Metriken die beste Leistung, was darauf hindeutet, dass die Methode gut zur Beschreibung der Eingabeaufforderung passt und gleichzeitig die Charaktereigenschaften beibehält, und zeigt ihre Robustheit.“ konsistente Bildgenerierung Im Hinblick auf die Übergangsvideogenerierung verglich das Forschungsteam zwei hochmoderne Methoden – SparseCtrl und SEINE – Es wurden Vergleiche angestellt, um die Leistung zu bewerten. Sie führten einen qualitativen Vergleich der Übergangsvideogenerierung durch und zeigten die Ergebnisse in Abbildung 5. Die Ergebnisse zeigen: „Die StoryDiffusion des Teams ist deutlich besser als SEINE und SparseCtrl, und das generierte Übergangsvideo ist sowohl reibungslos als auch im Einklang mit physikalischen Prinzipien.“ -Art-Methoden Vergleich der Videogenerierung Sie verglichen diese Methode auch mit SEINE und SparseCtrl und verwendeten vier quantitative Indikatoren, darunter LPIPSfirst, LPIPS-Frames, CLIPSIM-first und CLIPSIM-Frames, wie in Tabelle 2 gezeigt. Weitere technische und experimentelle Details finden Sie im Originalpapier. 
 Vergleich der Übergangsvideogenerierung
Vergleich der Übergangsvideogenerierung Tabelle 2: Quantitativer Vergleich mit dem aktuellen, hochmodernen Übergangsvideo-Generierungsmodell
Tabelle 2: Quantitativer Vergleich mit dem aktuellen, hochmodernen Übergangsvideo-Generierungsmodell
Das obige ist der detaillierte Inhalt vonLeCun auf dem Mond? Nankai und Byte öffnen StoryDiffusion als Open-Source-Lösung, um mehrteilige Comics und lange Videos kohärenter zu machen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie Ihren eigenen Git-Server
Erstellen Sie Ihren eigenen Git-Server
 Der Unterschied zwischen Git und SVN
Der Unterschied zwischen Git und SVN
 Git macht den eingereichten Commit rückgängig
Git macht den eingereichten Commit rückgängig
 So machen Sie einen Git-Commit-Fehler rückgängig
So machen Sie einen Git-Commit-Fehler rückgängig
 So vergleichen Sie den Dateiinhalt zweier Versionen in Git
So vergleichen Sie den Dateiinhalt zweier Versionen in Git
 So eröffnen Sie ein digitales Währungskonto
So eröffnen Sie ein digitales Währungskonto
 Proxy-Switchysharp
Proxy-Switchysharp
 Eine vollständige Liste häufig verwendeter öffentlicher DNS
Eine vollständige Liste häufig verwendeter öffentlicher DNS








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



