
 Technologie-Peripheriegeräte
KI
ICLR 2024 Spotlight |. Negative Label Mining erleichtert CLIP-basierte Aufgaben zur Erkennung von Out-of-Distribution
Technologie-Peripheriegeräte
KI
ICLR 2024 Spotlight |. Negative Label Mining erleichtert CLIP-basierte Aufgaben zur Erkennung von Out-of-Distribution
ICLR 2024 Spotlight |. Negative Label Mining erleichtert CLIP-basierte Aufgaben zur Erkennung von Out-of-Distribution

Da maschinelle Lernmodelle zunehmend in Open-World-Szenarien eingesetzt werden, ist die effektive Identifizierung und Verarbeitung von Out-of-Distribution-Daten (OOD) zu einem wichtigen Forschungsgebiet geworden. Das Vorhandensein von Daten außerhalb der Verteilung kann zu übermäßigem Vertrauen in das Modell und falschen Vorhersagen führen, was besonders bei sicherheitskritischen Anwendungen wie autonomem Fahren und medizinischer Diagnostik gefährlich ist. Daher ist die Entwicklung eines wirksamen OOD-Erkennungsmechanismus von entscheidender Bedeutung für die Verbesserung der Sicherheit und Zuverlässigkeit des Modells in praktischen Anwendungen.
Traditionelle OOD-Erkennungsmethoden konzentrieren sich hauptsächlich auf ein einzelnes Muster, insbesondere Bilddaten, während andere potenziell nützliche Informationsquellen, wie z. B. Textdaten, ignoriert werden. Mit dem Aufkommen von Visual-Language-Modellen (VLMs) haben sie eine starke Leistung in multimodalen Lernszenarien gezeigt, insbesondere bei Aufgaben, die das gleichzeitige Verständnis von Bildern und zugehörigen Textbeschreibungen erfordern. Bestehende auf VLMs basierende OOD-Erkennungsmethoden [3, 4, 5] nutzen nur die semantischen Informationen von ID-Tags und ignorieren dabei die leistungsstarke Null-Sample-Fähigkeit des VLMs-Modells und den sehr breiten semantischen Raum, den VLMs erklären können. Auf dieser Grundlage glauben wir, dass VLMs ein großes ungenutztes Potenzial bei der OOD-Erkennung haben, insbesondere, dass sie Bild- und Textinformationen umfassend nutzen können, um die Erkennungsergebnisse zu verbessern.
Dieser Artikel dreht sich um drei Fragen:
1 Sind die Informationen von Nicht-ID-Tags hilfreich für die Zero-Shot-OOD-Erkennung?
2. Wie kann man Informationen gewinnen, die für die OOD-Erkennung bei Nullproben nützlich sind?
3. Wie nutzt man die gewonnenen Informationen für die OOD-Erkennung bei Nullproben?
In diesem Projekt schlagen wir einen innovativen Ansatz namens NegLabel vor, der VLMs zur OOD-Erkennung nutzt. Die NegLabel-Methode führt speziell einen „negativen Label“-Mechanismus ein. Diese negativen Labels weisen erhebliche semantische Unterschiede zu bekannten ID-Kategorie-Labels auf. Durch die Analyse und den Vergleich der Affinität und Art von Bildern und ID-Labels und negativen Labels kann NegLabel effektiv zwischen Verteilungen unterscheiden, die dazu gehören Proben außerhalb des Modells, wodurch die Fähigkeit des Modells zur Identifizierung von OOD-Proben erheblich verbessert wird.
NegLabel hat in mehreren Zero-Shot-OOD-Erkennungs-Benchmarks eine überragende Leistung erzielt. Bei großen Datensätzen wie ImageNet-1k können 94,21 % AUROC und 25,40 % FPR95 erreicht werden. Im Vergleich zu auf VLMs basierenden OOD-Erkennungsmethoden erfordert NegLabel nicht nur keine zusätzlichen Trainingsprozesse, sondern weist auch eine überlegene Leistung auf. Darüber hinaus zeigt NegLabel eine hervorragende Vielseitigkeit und Robustheit auf verschiedenen VLM-Architekturen.

ØPapier-Link: https://arxiv.org/pdf/2403.20078.pdf
ØCode-Link: https://github.com/tmlr-group/NegLabel
Ich werde es Ihnen beim nächsten Teilen kurz vorstellen unsere kürzlich veröffentlichten Forschungsergebnisse zur Out-of-Distribution-Erkennung auf der ICLR 2024.
Vorkenntnisse

Einführung in die Methode
Der Kern von NegLabel ist die Einführung des „Negativ-Label“-Mechanismus, der durch die Analyse und den Vergleich des Bildes mit der ID erhebliche semantische Unterschiede zu bekannten ID-Kategorie-Labeln aufweist Label und Negativlabel Mit seiner Affinität kann NegLabel effektiv Proben unterscheiden, die außerhalb der Verteilung liegen, wodurch die Fähigkeit des Modells zur Identifizierung von OOD-Proben erheblich verbessert wird.
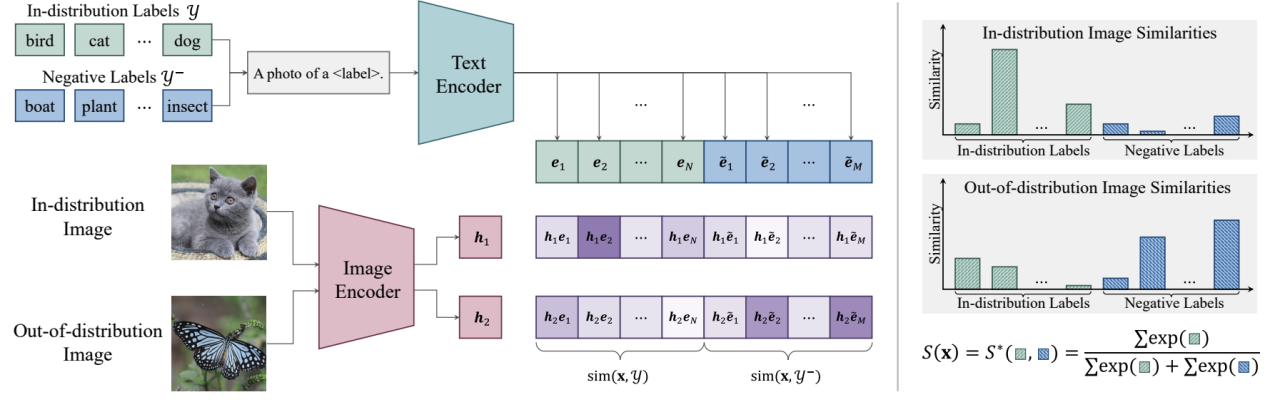
Abbildung 1. Übersicht über NegLabel
1 Wie wählt man negative Labels aus?

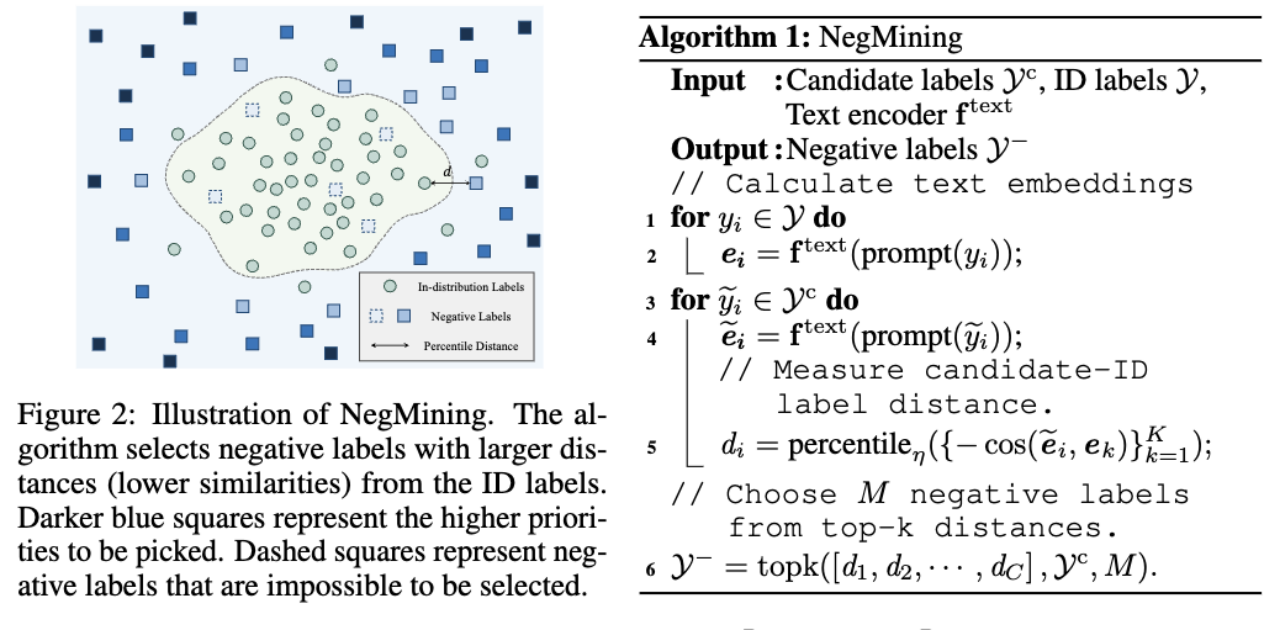
2. Wie verwendet man negative Etiketten zur OOD-Erkennung?


3. Wie kann man verstehen, dass negative Proben den OOD-Nachweis bei Nullproben fördern können?

Experimentelle Ergebnisse
Unsere Forschungsarbeit liefert mehrdimensionale experimentelle Ergebnisse, um die Leistung und den zugrunde liegenden Mechanismus unserer vorgeschlagenen Methode zu verstehen.
Wie in der folgenden Tabelle gezeigt, kann die in diesem Artikel vorgeschlagene Methode im Vergleich zu vielen Benchmark-Methoden und fortschrittlichen Methoden mit hervorragender Leistung bei großen Datensätzen (wie ImageNet) bessere Ergebnisse bei der Erkennung außerhalb der Verteilung erzielen.
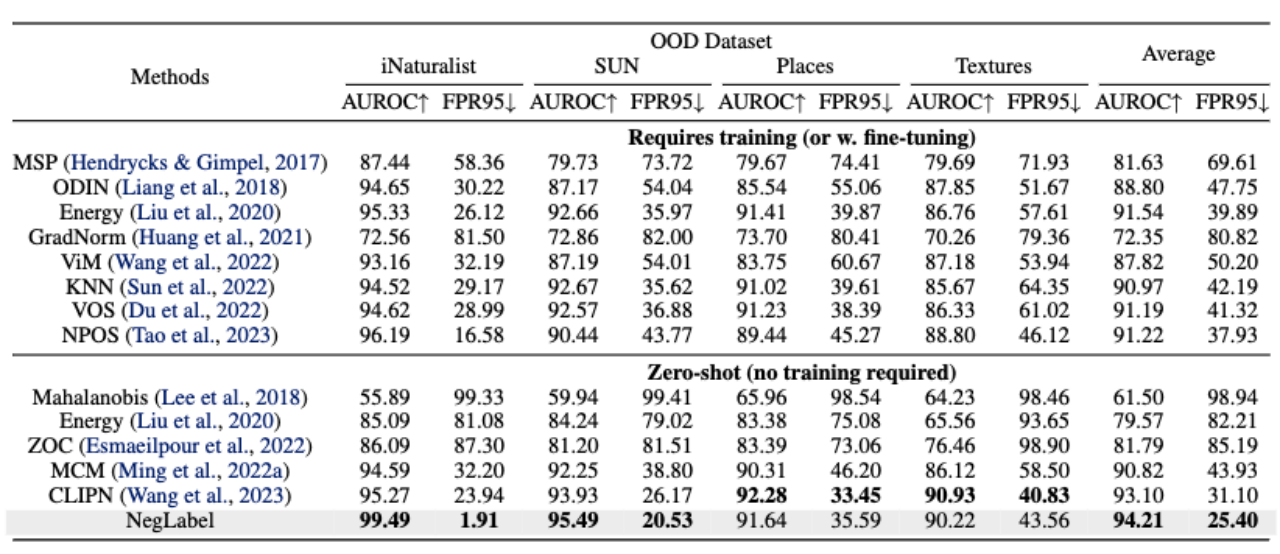
Darüber hinaus weist die Methode in diesem Artikel, wie in der folgenden Tabelle gezeigt, eine bessere Robustheit auf, wenn ID-Daten einer Domänenmigration unterzogen werden.
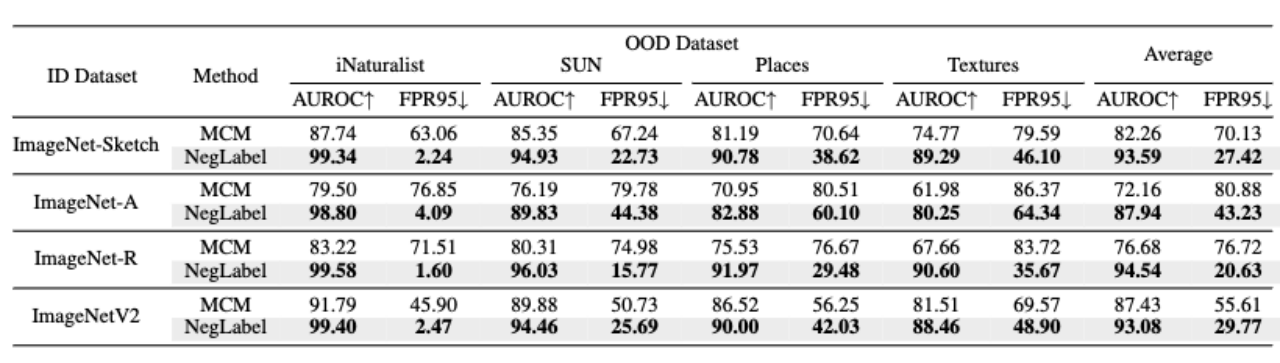
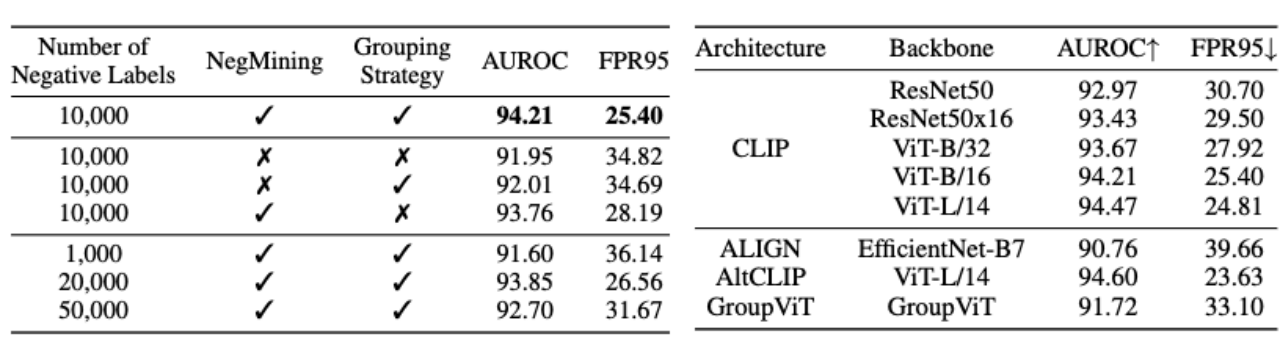
In den folgenden beiden Tabellen haben wir Ablationsexperimente für jedes Modul von NegLabel und die Struktur von VLMs durchgeführt. Wie aus der Tabelle links ersichtlich ist, können sowohl der NegMining-Algorithmus als auch die Gruppierungsstrategie die Leistung der OOD-Erkennung effektiv verbessern. Die Tabelle rechts zeigt, dass der von uns vorgeschlagene NegLabel-Algorithmus eine gute Anpassungsfähigkeit an VLMs unterschiedlicher Struktur aufweist.
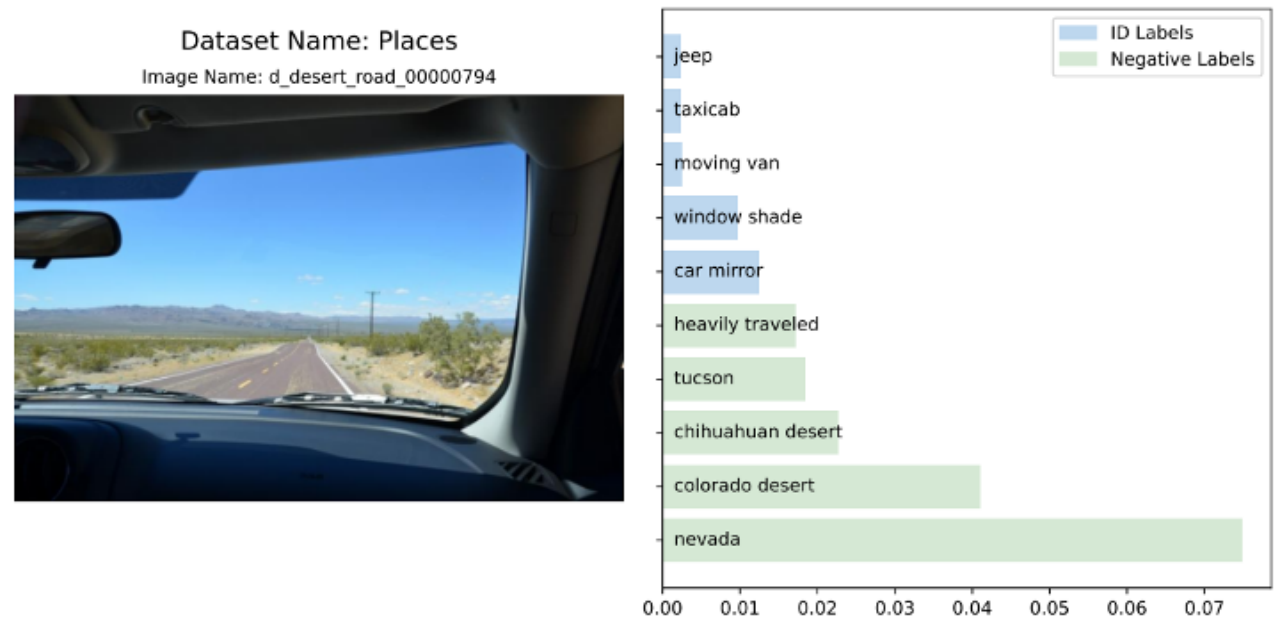
Wir haben auch eine visuelle Analyse der Affinität verschiedener Eingabebilder für ID-Tags und negative Tags durchgeführt. Weitere detaillierte Experimente und Ergebnisse finden Sie im Originalartikel.

Referenzen
[1] Hendrycks, D. und Gimpel, K. Eine Basis für die Erkennung falsch klassifizierter und nicht verteilter Beispiele in neuronalen Netzen.
[2] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark und andere. In ICML, 2021.
3] Sepideh Esmaeilpour, Bing Liu, Eric Robertson und Lei Shu. Null-Schuss-Außerverteilungserkennung basierend auf dem vorab trainierten Modellclip.
[4] Yifei Ming, Ziyang Cai, Jiuxiang Gu, Yiyou Sun, Wei Li und Yixuan Li beschäftigen sich mit der Erkennung außerhalb der Verteilung mit Vision-Language-Darstellungen.
[5] Hualiang Wang, Yi Li, Huifeng Yao und Xiaomeng Li -Shot-Ood-Erkennung: Lehrclip, um Nein zu sagen.
[6] Christiane Fellbaum: Eine elektronische Lexikondatenbank
Das obige ist der detaillierte Inhalt vonICLR 2024 Spotlight |. Negative Label Mining erleichtert CLIP-basierte Aufgaben zur Erkennung von Out-of-Distribution. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
Welche Bibliotheken werden für die Operationen der schwimmenden Punktzahl in Go verwendet?
Apr 02, 2025 pm 02:06 PM
In der Bibliothek, die für den Betrieb der Schwimmpunktnummer in der GO-Sprache verwendet wird, wird die Genauigkeit sichergestellt, wie die Genauigkeit ...
 Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
Gitee Pages statische Website -Bereitstellung fehlgeschlagen: Wie können Sie einzelne Dateien 404 Fehler beheben und beheben?
Apr 04, 2025 pm 11:54 PM
GitePages statische Website -Bereitstellung fehlgeschlagen: 404 Fehlerbehebung und Auflösung bei der Verwendung von Gitee ...
 Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen entwickelt oder von bekannten Open-Source-Projekten bereitgestellt?
Apr 02, 2025 pm 04:12 PM
Welche Bibliotheken in GO werden von großen Unternehmen oder bekannten Open-Source-Projekten entwickelt? Bei der Programmierung in Go begegnen Entwickler häufig auf einige häufige Bedürfnisse, ...
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
 Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie gibt ich die mit dem Modell in Beego Orm zugeordnete Datenbank an?
Apr 02, 2025 pm 03:54 PM
Wie kann man im Beegoorm -Framework die mit dem Modell zugeordnete Datenbank angeben? In vielen BeEGO -Projekten müssen mehrere Datenbanken gleichzeitig betrieben werden. Bei Verwendung von BeEGO ...
 Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Wie löste ich das Problem des Typs des user_id -Typs bei der Verwendung von Redis -Stream, um Nachrichtenwarteschlangen in GO -Sprache zu implementieren?
Apr 02, 2025 pm 04:54 PM
Das Problem der Verwendung von RETISTREAM zur Implementierung von Nachrichtenwarteschlangen in der GO -Sprache besteht darin, die Go -Sprache und Redis zu verwenden ...
 Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Wie erhalten Sie die Daten der Versandregion der Überseeversion? Was stehen einige vorgefertigte Ressourcen zur Verfügung?
Apr 01, 2025 am 08:15 AM
Frage Beschreibung: Wie erhalten Sie die Daten der Versandregion der Überseeversion? Gibt es bereitgestellte Ressourcen? Werden Sie im grenzüberschreitenden E-Commerce oder im globalisierten Geschäft genau ...
 Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Bedarf die Produktion von H5 -Seiten eine kontinuierliche Wartung?
Apr 05, 2025 pm 11:27 PM
Die H5 -Seite muss aufgrund von Faktoren wie Code -Schwachstellen, Browserkompatibilität, Leistungsoptimierung, Sicherheitsaktualisierungen und Verbesserungen der Benutzererfahrung kontinuierlich aufrechterhalten werden. Zu den effektiven Wartungsmethoden gehören das Erstellen eines vollständigen Testsystems, die Verwendung von Versionstools für Versionskontrolle, die regelmäßige Überwachung der Seitenleistung, das Sammeln von Benutzern und die Formulierung von Wartungsplänen.
