
 Technologie-Peripheriegeräte
KI
58 Zeilen Code skalieren Llama 3 bis 1 Million Kontexte, jede fein abgestimmte Version ist anwendbar
Technologie-Peripheriegeräte
KI
58 Zeilen Code skalieren Llama 3 bis 1 Million Kontexte, jede fein abgestimmte Version ist anwendbar
58 Zeilen Code skalieren Llama 3 bis 1 Million Kontexte, jede fein abgestimmte Version ist anwendbar

Llama 3, der majestätische König von Open Source, ursprüngliches Kontextfenster hat eigentlich nur... 8k, was mich die Worte „es riecht so gut“ herunterschlucken ließ.
Ab 32.000 sind heute 100.000 üblich. Ist dies beabsichtigt, um Platz für Beiträge zur Open-Source-Community zu schaffen?
Die Open-Source-Community hat sich diese Gelegenheit sicherlich nicht entgehen lassen:
Jetzt kann jede fein abgestimmte Version von Llama 3 70b mit nur 58 Codezeilen automatisch auf 1048k (eine Million) Kontext skaliert werden.
Dahinter verbirgt sich ein LoRA, extrahiert aus einer fein abgestimmten Version von Llama 3 70B Instruct, das einen guten Kontext erweitert. Die Datei ist nur 800 MB groß.
Als nächstes können Sie Mergekit verwenden, um es zusammen mit anderen Modellen derselben Architektur auszuführen oder es direkt mit dem Modell zusammenzuführen.
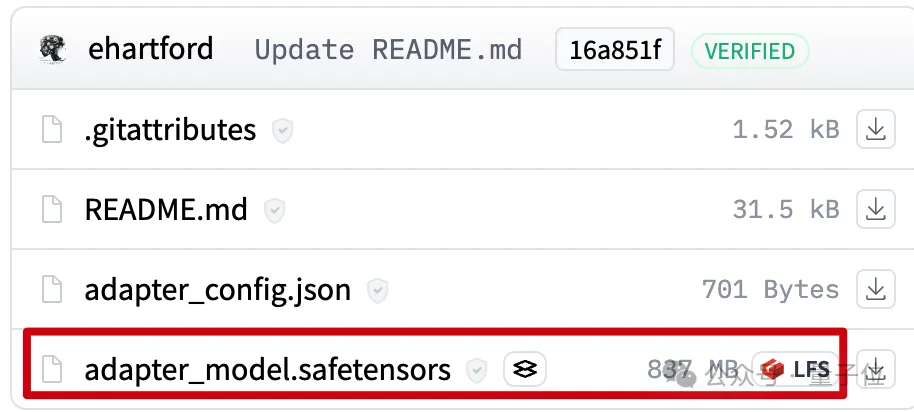
Die fein abgestimmte Version des verwendeten 1048k-Kontexts hat im beliebten Nadel-im-Heuhaufen-Test gerade eine durchweg grüne Punktzahl (100 % Genauigkeit) erreicht.
Ich muss sagen, dass die Geschwindigkeit des Fortschritts von Open Source exponentiell ist.
Wie 1048k kontextuelles LoRA erstellt wurde
Erstens stammt die 1048k kontextuelle Version des fein abgestimmten Llama 3-Modells von Gradient AI, einem Startup für KI-Lösungen für Unternehmen.

Das entsprechende LoRA stammt vom Entwickler Eric Hartford Durch den Vergleich der Unterschiede zwischen dem fein abgestimmten Modell und der Originalversion werden die Parameteränderungen extrahiert.
Er erstellte zunächst eine kontextbezogene 524-KB-Version und aktualisierte dann die 1048-KB-Version.
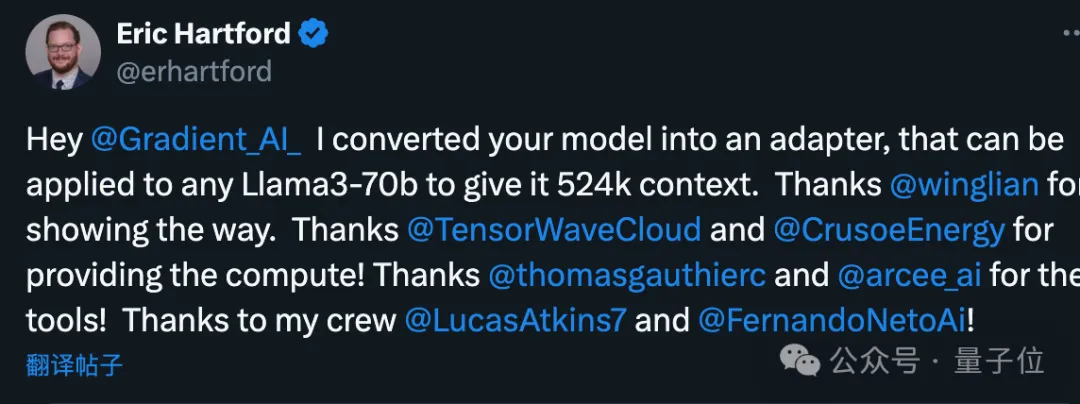
Zunächst setzte das Gradient-Team das Training auf Basis des ursprünglichen Llama 3 70B Instruct fort und erlangte Llama-3-70B-Instruct-Gradient-1048k.
Die spezifische Methode lautet wie folgt:
- Positionskodierung anpassen: Verwenden Sie NTK-fähige Interpolation, um die optimale Planung von RoPE-Theta zu initialisieren und zu optimieren, um den Verlust von Hochfrequenzinformationen nach der Erweiterung zu verhindern Länge
- Progressives Training: Verwenden Sie die vom UC Berkeley Pieter Abbeel-Team vorgeschlagene Blockwise RingAttention-Methode, um die Kontextlänge des Modells zu erweitern
Es ist erwähnenswert, dass das Team die Parallelisierung auf Ring Attention geschichtet hat Durch eine benutzerdefinierte Netzwerktopologie werden große GPU-Cluster besser genutzt, um Netzwerkengpässe zu bewältigen, die durch die Übertragung vieler KV-Blöcke zwischen Geräten verursacht werden.
Letztendlich wird die Modelltrainingsgeschwindigkeit um das 33-fache erhöht.
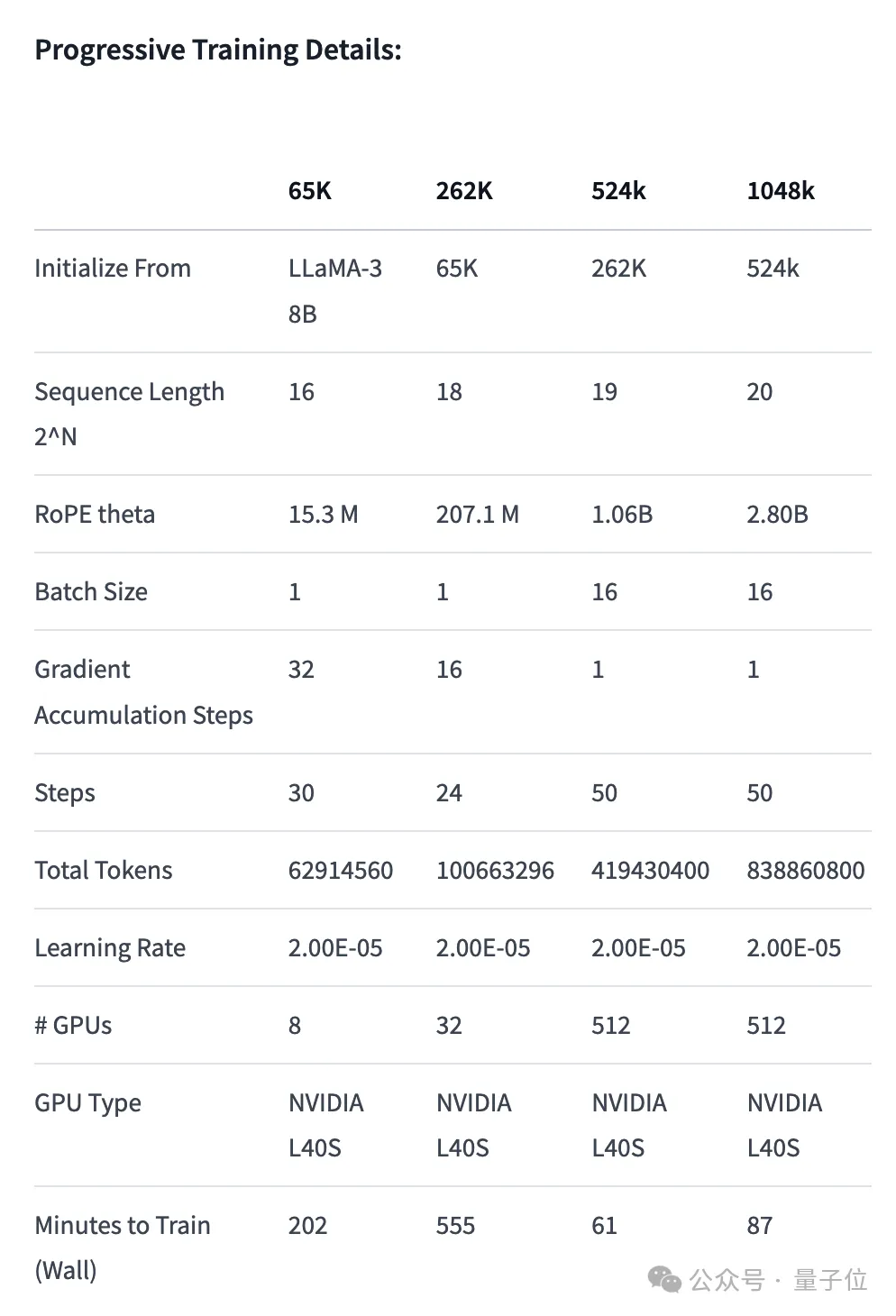
Bei der Leistungsbewertung des Langtextabrufs treten nur in der schwierigsten Version Fehler auf, wenn die „Nadel“ in der Mitte des Textes versteckt ist.

Nachdem Sie das fein abgestimmte Modell mit erweitertem Kontext haben, verwenden Sie das Open-Source-Tool Mergekit, um das fein abgestimmte Modell und das Basismodell zu vergleichen und den Unterschied in den Parametern zu extrahieren, um LoRA zu werden.
Mit Mergekit können Sie die extrahierte LoRA auch in andere Modelle mit derselben Architektur zusammenführen.
Der Merge-Code ist ebenfalls Open Source auf GitHub von Eric Hartford und ist nur 58 Zeilen lang.
Es ist unklar, ob diese LoRA-Zusammenführung mit Llama 3 funktioniert, das auf Chinesisch abgestimmt ist.
Es ist jedoch zu erkennen, dass die chinesische Entwicklergemeinschaft dieser Entwicklung Aufmerksamkeit geschenkt hat.
524k-Version LoRA: https://huggingface.co/cognitivecomputations/Llama-3-70B-Gradient-524k-adapter
1048k-Version LoRA: https://huggingface.co/ kognitive Berechnungen/Llama-3-70B-Gradient-1048k-adapter
Merge-Code: https://gist.github.com/ehartford/731e3f7079db234fa1b79a01e09859ac
Das obige ist der detaillierte Inhalt von58 Zeilen Code skalieren Llama 3 bis 1 Million Kontexte, jede fein abgestimmte Version ist anwendbar. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Was tun, wenn der Git -Download nicht aktiv ist
Apr 17, 2025 pm 04:54 PM
Auflösung: Wenn die Git -Download -Geschwindigkeit langsam ist, können Sie die folgenden Schritte ausführen: Überprüfen Sie die Netzwerkverbindung und versuchen Sie, die Verbindungsmethode zu wechseln. Optimieren Sie die GIT-Konfiguration: Erhöhen Sie die Post-Puffer-Größe (GIT-Konfiguration --global http.postbuffer 524288000) und verringern Sie die Niedriggeschwindigkeitsbegrenzung (GIT-Konfiguration --global http.lowSpeedLimit 1000). Verwenden Sie einen GIT-Proxy (wie Git-Proxy oder Git-LFS-Proxy). Versuchen Sie, einen anderen Git -Client (z. B. Sourcetree oder Github Desktop) zu verwenden. Überprüfen Sie den Brandschutz
 So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
Befolgen Sie die folgenden Schritte, um ein Git -Repository zu löschen: Bestätigen Sie das Repository, das Sie löschen möchten. Lokale Löschen des Repositorys: Verwenden Sie den Befehl rm -RF, um seinen Ordner zu löschen. Löschen Sie ein Lager aus der Ferne: Navigieren Sie zu den Lagereinstellungen, suchen Sie die Option "Lager löschen" und bestätigen Sie den Betrieb.
 So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
So laden Sie GIT -Projekte auf lokale Herd herunter
Apr 17, 2025 pm 04:36 PM
Um Projekte lokal über Git herunterzuladen, befolgen Sie die folgenden Schritte: Installieren Sie Git. Navigieren Sie zum Projektverzeichnis. Klonen des Remote-Repositorys mit dem folgenden Befehl: Git Clone https://github.com/username/repository-name.git.git
 So aktualisieren Sie den Code in Git
Apr 17, 2025 pm 04:45 PM
So aktualisieren Sie den Code in Git
Apr 17, 2025 pm 04:45 PM
Schritte zur Aktualisierung von Git -Code: CODEHOUSSCHAFTEN:
 Wie löste ich das effiziente Suchproblem in PHP -Projekten? Typense hilft Ihnen, es zu erreichen!
Apr 17, 2025 pm 08:15 PM
Wie löste ich das effiziente Suchproblem in PHP -Projekten? Typense hilft Ihnen, es zu erreichen!
Apr 17, 2025 pm 08:15 PM
Bei der Entwicklung einer E-Commerce-Website habe ich auf ein schwieriges Problem gestoßen: Wie kann ich effiziente Suchfunktionen in großen Mengen an Produktdaten erzielen? Herkömmliche Datenbanksuche sind ineffizient und haben eine schlechte Benutzererfahrung. Nach einigen Nachforschungen entdeckte ich den Suchmaschinen-Artensense und löste dieses Problem durch seine offizielle PHP-Client-Artense-/Artense-Php, die die Suchleistung erheblich verbesserte.
 Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Wie man Git Commit benutzt
Apr 17, 2025 pm 03:57 PM
Git Commit ist ein Befehl, mit dem Dateien Änderungen an einem Git -Repository aufgezeichnet werden, um einen Momentaufnahme des aktuellen Status des Projekts zu speichern. So verwenden Sie dies wie folgt: Fügen Sie Änderungen in den temporären Speicherbereich hinzu, schreiben Sie eine prägnante und informative Einreichungsnachricht, um die Einreichungsnachricht zu speichern und zu beenden, um die Einreichung optional abzuschließen: Fügen Sie eine Signatur für die Einreichungs -Git -Protokoll zum Anzeigen des Einreichungsinhalts hinzu.
 So reichen Sie leere Ordner in Git ein
Apr 17, 2025 pm 04:09 PM
So reichen Sie leere Ordner in Git ein
Apr 17, 2025 pm 04:09 PM
Um einen leeren Ordner in Git einzureichen, befolgen Sie einfach die folgenden Schritte: 1. Erstellen Sie einen leeren Ordner; 2. Fügen Sie den Ordner zum Staging -Bereich hinzu; 3. Senden Sie Änderungen und geben Sie eine Commit -Nachricht ein. 4. (Optional) Drücken Sie die Änderungen in das Remote -Repository. HINWEIS: Der Name eines leeren Ordners kann nicht beginnen. Wenn der Ordner bereits vorhanden ist, müssen Sie Git Add -Force zum Hinzufügen verwenden.
 Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Der Code -Konflikt bezieht sich auf einen Konflikt, der auftritt, wenn mehrere Entwickler denselben Code -Stück ändern und GIT veranlassen, sich zu verschmelzen, ohne automatisch Änderungen auszuwählen. Zu den Auflösungsschritten gehören: Öffnen Sie die widersprüchliche Datei und finden Sie den widersprüchlichen Code. Führen Sie den Code manuell zusammen und kopieren Sie die Änderungen, die Sie in den Konfliktmarker halten möchten. Löschen Sie die Konfliktmarke. Änderungen speichern und einreichen.
