
 Technologie-Peripheriegeräte
KI
Durchschauen Sie 3D-Darstellungen und generative Modelle von Objekten: NUS-Team schlägt Röntgen vor
Technologie-Peripheriegeräte
KI
Durchschauen Sie 3D-Darstellungen und generative Modelle von Objekten: NUS-Team schlägt Röntgen vor
Durchschauen Sie 3D-Darstellungen und generative Modelle von Objekten: NUS-Team schlägt Röntgen vor


- Projekthomepage: https://tau-yihouxiang.github.io/projects/X-Ray/X-Ray.html
- Papieradresse: https://arxiv.org/abs/ 2404.14329 Derzeit entwickelt sich die künstliche Intelligenz im Bereich der menschlichen Intelligenz rasant weiter. In der Computer Vision ist die Technologie zur Bild- und Videoerzeugung immer ausgereifter geworden, und Modelle wie Midjourney und Stable Video Diffusion sind weit verbreitet. Allerdings stehen generative Modelle im Bereich der 3D-Vision noch vor Herausforderungen.
- Die aktuelle 3D-Modellgenerierungstechnologie basiert normalerweise auf der Generierung und Rekonstruktion von Mehrwinkelvideos, wie z. B. dem SV3D-Modell, das schrittweise 3D aufbaut, indem es Mehrwinkelvideos generiert und neuronale Strahlungsfelder (NeRF) oder 3D-Gaußsche glatte Modelle kombiniert ( 3D-Objekt mit Gaußscher Splatting-Technologie. Diese Methode ist hauptsächlich auf die Generierung einfacher, nicht selbstverdeckter dreidimensionaler Objekte beschränkt und kann die interne Struktur des Objekts nicht darstellen, wodurch der gesamte Generierungsprozess komplex und unvollkommen wird, was die Komplexität und Grenzen dieser Technologie zeigt.
- Der Grund dafür ist, dass es derzeit an einer flexiblen, effizienten und einfach zu verallgemeinernden 3D-Darstellung (3D-Darstellung) mangelt.

Abbildung 1. Röntgenserialisierte 3D-Darstellung
National University of Singapore (NUS) Dr. Hu Run leitete ein Forschungsteam, um ein neues 3D-Röntgenbild zu veröffentlichen, das sequenziert werden kann Es kann die Oberflächenform und Textur von Objekten aus der Perspektive der Kamera genau wiedergeben. Es kann die Videogenerierungsfunktion vollständig nutzen, um Modellvorteile zu generieren und die internen und externen 3D-Strukturen zu generieren Objekt gleichzeitig.
In diesem Artikel werden die Prinzipien, Vorteile und breiten Anwendungsaussichten der Röntgentechnologie ausführlich erläutert.

Abbildung 2. Vergleich mit renderbasierten 3D-Modellgenerierungsmethoden.
Technische Innovation: 3D-Darstellung der Innen- und Außenflächen des Objekts
In jeder Strahlrichtung werden L dreidimensionale Attributdaten, einschließlich Tiefe, Normalenvektor, Farbe usw., einzeln am Schnittpunkt mit der Objektoberfläche aufgezeichnet und dann werden diese Daten in der Form L×H×B organisiert Um die Erstellung eines beliebigen 3D-Modells zu realisieren, ist dies die vom Team vorgeschlagene Röntgendarstellungsmethode.
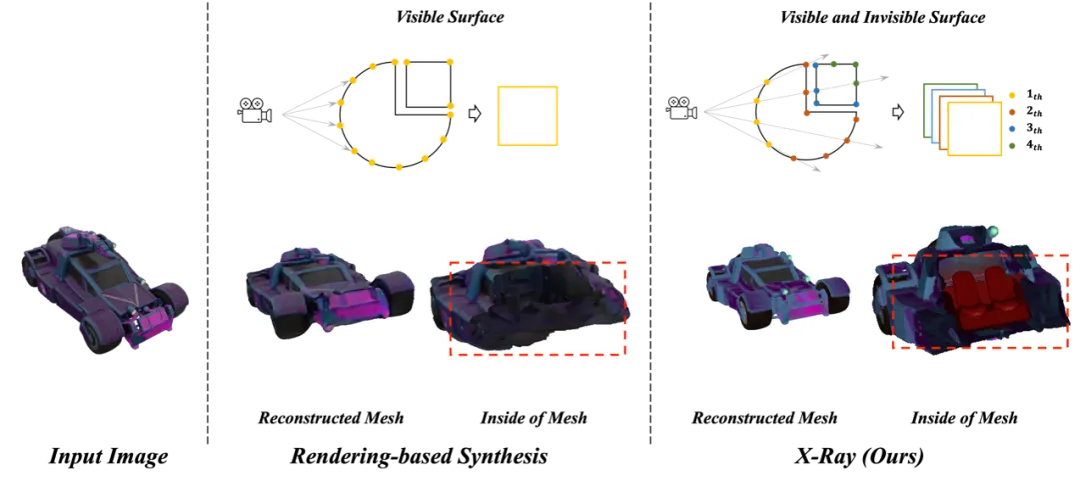
Abbildung 3. Röntgenprobenproben mit verschiedenen Schichten.
1. Kodierungsprozess: Konvertieren Sie das 3D-Modell in ), um die Eigenschaften
aller Oberflächen aufzuzeichnen, die jeder Kamerastrahl mit dem Objekt schneidet, einschließlich der Tiefe
 , des Normalenvektors
, des Normalenvektors
und der Farbe
usw. der Oberfläche. Zur Vereinfachung der Anzeige wird dies durch dargestellt, ob an der Stelle eine Oberfläche vorhanden ist.
Dann kann durch Erhalten aller Kamerastrahlen und anderer Schnittflächenpunkte ein vollständiger Röntgen-3D-Ausdruck erhalten werden, wie im folgenden Ausdruck und in Abbildung 3 dargestellt. 
Konvertieren Sie ein beliebiges 3D-Modell durch den Kodierungsprozess in Röntgen. Es ist das gleiche wie das Videoformat und hat eine andere Anzahl von Bildern. Normalerweise reicht die Anzahl der Bilder L=8 aus, um ein 3D-Objekt darzustellen. 2. Dekodierungsprozess: Röntgenbild in 3D-Modell Generierung eines Röntgenmodells. Der spezifische Prozess umfasst zwei Prozesse: den Punktwolken-Generierungsprozess und den Punktwolken-Oberflächenrekonstruktionsprozess.
Röntgenbild in Punktwolke:
Röntgenbild lässt sich problemlos in eine Punktwolke umwandeln. Zusätzlich zu den Positionskoordinaten des 3D-Punkts verfügt jeder Punkt in der Punktwolke auch über eine Farbe und einen Normalenvektor Information.
- wobei r_0 und r_d der Startpunkt bzw. die normalisierte Richtung des Kamerastrahls sind, kann durch die Verarbeitung jedes Kamerastrahls eine vollständige Punktwolke erhalten werden.
Punktwolke in dreidimensionales Netz: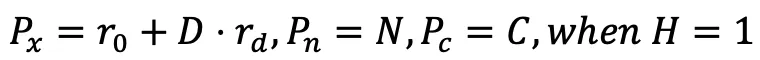
Der nächste Schritt ist der Prozess der Umwandlung der Punktwolke in ein dreidimensionales Netz. Dies ist eine Technologie, die seit vielen Jahren untersucht wird, da diese Punkte vorliegen Wolken haben Normalenvektoren, daher wird der Screened Poisson-Algorithmus verwendet, um die Punktwolke direkt in ein dreidimensionales Netzmodell umzuwandeln, das das endgültige 3D-Modell darstellt.
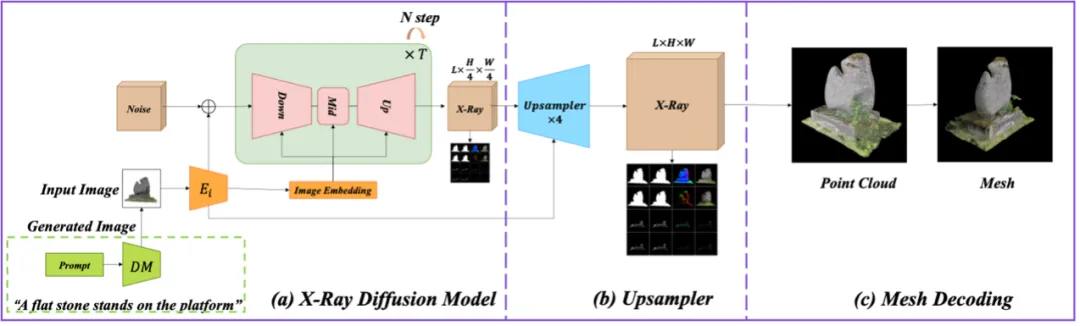
- 3D-Modellgenerierung basierend auf RöntgendarstellungUm hochauflösende, vielfältige 3D-Röntgenmodelle zu generieren, verwendete das Team eine Videodiffusionsmodellarchitektur, die Videoformaten ähnelt. Diese Architektur kann kontinuierlich 3D-Informationen verarbeiten und die Qualität von Röntgenaufnahmen durch Upsampling-Module verbessern, um hochpräzise 3D-Ausgaben zu erzeugen. Das Diffusionsmodell ist für die schrittweise Generierung detaillierter 3D-Bilder aus verrauschten Daten verantwortlich, während das Upsampling-Modul die Bildauflösung und -details verbessert, um hohen Qualitätsstandards gerecht zu werden. Die spezifische Struktur ist in Abbildung 4 dargestellt.
Das Diffusionsmodell nutzt latenten Raum bei der Röntgenerzeugung und erfordert normalerweise eine benutzerdefinierte Entwicklung eines Vektorquantisierungs-Variations-Autoencoders (VQ-VAE) [3] für die Datenkomprimierung. Dieser Prozess Der Mangel an vorgefertigten Modellen erhöht den Schulungsaufwand.
Um den hochauflösenden Generator effektiv zu trainieren, hat das Team eine Kaskadensynthesestrategie eingeführt, um mithilfe von Technologien wie Imagen und Stable Cascaded schrittweise von niedriger zu hoher Auflösung zu trainieren, um sich an begrenzte Rechenressourcen anzupassen und die Qualität von Röntgenbildern zu verbessern.
Insbesondere wird die 3D-U-Net-Architektur in Stable Video Diffusion als Diffusionsmodell verwendet, um Röntgenbilder mit niedriger Auflösung zu erzeugen und Merkmale aus 2D-Bildern und 1D-Zeitreihen durch einen räumlich-zeitlichen Aufmerksamkeitsmechanismus zu extrahieren, um die Verarbeitung zu verbessern und zu erklären Röntgenfähigkeiten, die für qualitativ hochwertige Ergebnisse von entscheidender Bedeutung sind.
Röntgen-Upsampling-Modell
Das Diffusionsmodell in der vorherigen Stufe kann nur Röntgenbilder mit niedriger Auflösung aus Text oder anderen Bildern erzeugen. In den folgenden Schritten liegt der Schwerpunkt auf der Aufwertung dieser niedrig aufgelösten Röntgenbilder auf höhere Auflösungen.
Das Team untersuchte zwei Hauptmethoden: Punktwolken-Upsampling und Video-Upsampling.
Da bereits eine grobe Darstellung von Form und Aussehen vorliegt, ist die Codierung dieser Daten in eine Punktwolke mit Farbe und Normalen ein unkomplizierter Prozess.
Die Darstellungsstruktur der Punktwolke ist jedoch zu locker und für eine dichte Vorhersage nicht geeignet. Herkömmliche Upsampling-Techniken für Punktwolken erhöhen normalerweise einfach die Anzahl der Punkte, was möglicherweise nicht effektiv genug ist, um Attribute wie Textur und Farbe zu verbessern. Um den Prozess zu vereinfachen und die Konsistenz in der gesamten Pipeline sicherzustellen, haben wir uns für die Verwendung eines Video-Upsampling-Modells entschieden.
Dieses Modell basiert auf dem raumzeitlichen VAE-Decoder von Stable Video Diffusion (SVD) und wurde von Grund auf speziell darauf trainiert, synthetisierte Röntgenbilder um den Faktor 4 hochzurechnen und dabei die ursprüngliche Anzahl an Schichten beizubehalten. Der Decoder ist in der Lage, Aufmerksamkeitsoperationen unabhängig auf Rahmenebene und hierarchischen Ebenen durchzuführen. Dieser zweischichtige Aufmerksamkeitsmechanismus verbessert nicht nur die Auflösung, sondern auch die Gesamtqualität des Bildes erheblich. Diese Funktionen machen das Video-Upsampling-Modell zu einer besser koordinierten und effizienteren Lösung bei der Erzeugung hochauflösender Röntgenaufnahmen.
Abbildung 4: 3D-Modellgenerierungsrahmen basierend auf Röntgendarstellung, einschließlich Röntgendiffusionsmodell und Röntgen-Upsampling-Modell.
Experiment
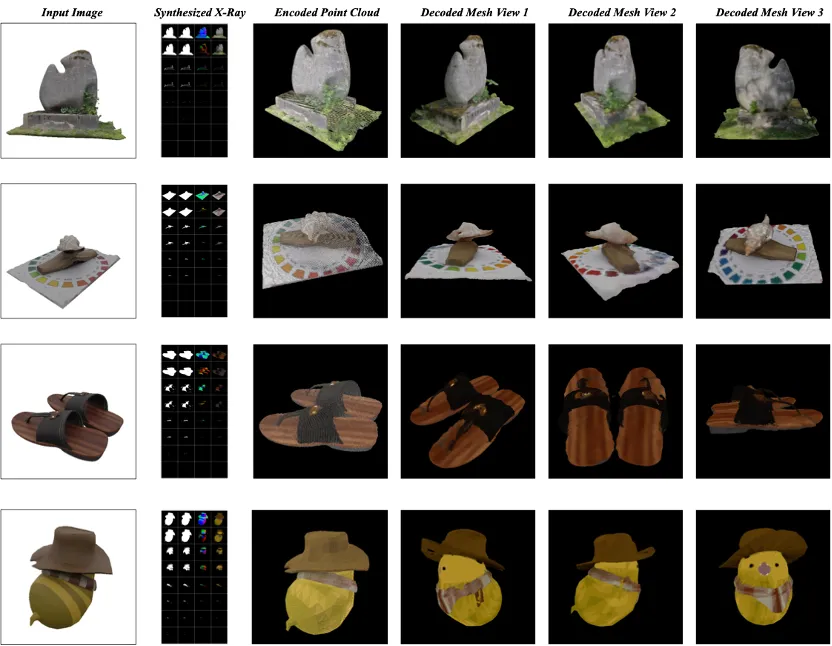
1. Datensatz:
Das Experiment verwendete eine gefilterte Teilmenge des Objaverse-Datensatzes, aus der Einträge mit fehlenden Texturen und unzureichenden Hinweisen entfernt wurden.
Diese Teilmenge enthält über 60.000 3D-Objekte. Für jedes Objekt werden 4 Kameraansichten zufällig ausgewählt, die Azimutwinkel von -180 bis 180 Grad und Höhenwinkel von -45 bis 45 Grad abdecken, und der Abstand von der Kamera zum Mittelpunkt des Objekts ist auf 1,5 festgelegt.
Verwenden Sie dann die Blender-Software zum Rendern und generieren Sie die entsprechende Röntgenaufnahme mithilfe des von der Trimesh-Bibliothek bereitgestellten Ray-Casting-Algorithmus. Durch diese Prozesse können über 240.000 Bildpaare und Röntgendatensätze erstellt werden, um generative Modelle zu trainieren.
2. Implementierungsdetails:
Das Röntgendiffusionsmodell basiert auf der raumzeitlichen UNet-Architektur, die bei Stable Video Diffusion (SVD) verwendet wird, mit geringfügigen Anpassungen: Das Modell ist für die Synthese von 8 Kanälen konfiguriert: 1 Trefferkanal, 1 Tiefenkanal und 6 normale Kanäle, im Vergleich auf die 4 Kanäle des ursprünglichen Netzwerks.
Angesichts der erheblichen Unterschiede zwischen Röntgenbildgebung und herkömmlichem Video wurde das Modell von Grund auf trainiert, um die große Lücke zwischen Röntgen- und Videobereich zu schließen. Das Training fand über eine Woche auf 8 NVIDIA A100 GPU-Servern statt. Während dieses Zeitraums wurde die Lernrate mithilfe des AdamW-Optimierers bei 0,0001 gehalten.
Da unterschiedliche Röntgenbilder eine unterschiedliche Anzahl von Schichten haben, füllen oder beschneiden Sie sie zur besseren Stapelverarbeitung und Schulung auf die gleichen 8 Schichten. Die Bildgröße jeder Schicht beträgt 64 x 64. Für das Upsampling-Modell beträgt die Ausgabe der L-Schicht immer noch 8, aber die Auflösung jedes Frames wird auf 256 x 256 erhöht, was die Details und Klarheit der vergrößerten Röntgenaufnahme verbessert. Die Ergebnisse sind in den Abbildungen 5 und 6 dargestellt . Abbildung 5: Bild zu Röntgen und zur 3D-Modellgenerierung Die Möglichkeiten sind endlos
 Mit der kontinuierlichen Weiterentwicklung der maschinellen Lern- und Bildverarbeitungstechnologie sind die Anwendungsaussichten von X-Ray unendlich vielfältig.
Mit der kontinuierlichen Weiterentwicklung der maschinellen Lern- und Bildverarbeitungstechnologie sind die Anwendungsaussichten von X-Ray unendlich vielfältig.
In Zukunft könnte diese Technologie mit Augmented Reality (AR) und Virtual Reality (VR)-Technologie kombiniert werden, um ein vollständig immersives 3D-Erlebnis für Benutzer zu schaffen. Davon können auch Bildungs- und Ausbildungsbereiche profitieren, etwa durch die Bereitstellung intuitiverer Lernmaterialien und Simulationsexperimente durch 3D-Rekonstruktion.

Das obige ist der detaillierte Inhalt vonDurchschauen Sie 3D-Darstellungen und generative Modelle von Objekten: NUS-Team schlägt Röntgen vor. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
So löschen Sie ein Repository von Git
Apr 17, 2025 pm 04:03 PM
Befolgen Sie die folgenden Schritte, um ein Git -Repository zu löschen: Bestätigen Sie das Repository, das Sie löschen möchten. Lokale Löschen des Repositorys: Verwenden Sie den Befehl rm -RF, um seinen Ordner zu löschen. Löschen Sie ein Lager aus der Ferne: Navigieren Sie zu den Lagereinstellungen, suchen Sie die Option "Lager löschen" und bestätigen Sie den Betrieb.
 So stellen Sie eine Verbindung zum öffentlichen Netzwerk von Git Server her
Apr 17, 2025 pm 02:27 PM
So stellen Sie eine Verbindung zum öffentlichen Netzwerk von Git Server her
Apr 17, 2025 pm 02:27 PM
Das Verbinden eines Git -Servers mit dem öffentlichen Netzwerk enthält fünf Schritte: 1. Einrichten der öffentlichen IP -Adresse; 2. Öffnen Sie den Firewall -Port (22, 9418, 80/443); 3. Konfigurieren Sie den SSH -Zugriff (Generieren Sie Schlüsselpaare, erstellen Benutzer). 4. Konfigurieren Sie HTTP/HTTPS -Zugriff (installieren Server, Konfigurieren Sie Berechtigungen); 5. Testen Sie die Verbindung (mit SSH -Client- oder Git -Befehlen).
 So fügen Sie öffentliche Schlüssel zum Git -Konto hinzu
Apr 17, 2025 pm 02:42 PM
So fügen Sie öffentliche Schlüssel zum Git -Konto hinzu
Apr 17, 2025 pm 02:42 PM
Wie füge ich einem Git -Konto einen öffentlichen Schlüssel hinzu? Schritt: Generieren Sie ein SSH -Schlüsselpaar. Kopieren Sie den öffentlichen Schlüssel. Fügen Sie einen öffentlichen Schlüssel in Gitlab oder GitHub hinzu. Testen Sie die SSH -Verbindung.
 Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Wie man mit Git -Code -Konflikt umgeht
Apr 17, 2025 pm 02:51 PM
Der Code -Konflikt bezieht sich auf einen Konflikt, der auftritt, wenn mehrere Entwickler denselben Code -Stück ändern und GIT veranlassen, sich zu verschmelzen, ohne automatisch Änderungen auszuwählen. Zu den Auflösungsschritten gehören: Öffnen Sie die widersprüchliche Datei und finden Sie den widersprüchlichen Code. Führen Sie den Code manuell zusammen und kopieren Sie die Änderungen, die Sie in den Konfliktmarker halten möchten. Löschen Sie die Konfliktmarke. Änderungen speichern und einreichen.
 So generieren Sie SSH -Schlüssel in Git
Apr 17, 2025 pm 01:36 PM
So generieren Sie SSH -Schlüssel in Git
Apr 17, 2025 pm 01:36 PM
Um sich sicher eine Verbindung zu einem Remote -Git -Server herzustellen, muss ein SSH -Schlüssel mit öffentlichen und privaten Schlüssel generiert werden. Die Schritte zur Generierung eines SSH -Schlüssels sind wie folgt: Öffnen Sie das Terminal und geben Sie den Befehl SSH -Keygen -t RSA -B 4096 ein. Wählen Sie den Schlüsselspeicherort aus. Geben Sie einen Kennwortphrase ein, um den privaten Schlüssel zu schützen. Kopieren Sie den öffentlichen Schlüssel auf den Remote -Server. Speichern Sie den privaten Schlüssel ordnungsgemäß, da dies die Anmeldeinformationen für den Zugriff auf das Konto sind.
 Wie man ssh nach Git erkennt
Apr 17, 2025 pm 02:33 PM
Wie man ssh nach Git erkennt
Apr 17, 2025 pm 02:33 PM
Um SSH durch Git zu erkennen, müssen Sie die folgenden Schritte ausführen: Generieren Sie ein SSH -Schlüsselpaar. Fügen Sie den öffentlichen Schlüssel zum Git -Server hinzu. Konfigurieren Sie Git so, dass sie SSH verwenden. Testen Sie die SSH -Verbindung. Lösen Sie mögliche Probleme gemäß den tatsächlichen Bedingungen.
 Wie man Git Commit trennen
Apr 17, 2025 pm 02:36 PM
Wie man Git Commit trennen
Apr 17, 2025 pm 02:36 PM
Verwenden Sie Git, um Code separat einzureichen und die Verfolgung und unabhängige Arbeitsfähigkeit für detaillierte Änderungen bereitzustellen. Die Schritte sind wie folgt: 1. Fügen Sie die geänderten Dateien hinzu; 2. Senden spezifischer Änderungen; 3. Wiederholen Sie die obigen Schritte; V.
 So erstellen Sie einen Git -Server
Apr 17, 2025 pm 12:57 PM
So erstellen Sie einen Git -Server
Apr 17, 2025 pm 12:57 PM
Das Erstellen eines Git -Servers umfasst: Installieren von Git auf dem Server. Erstellen Sie Benutzer und Gruppen, die den Server ausführen. Erstellen Sie ein Git -Repository -Verzeichnis. Initialisieren Sie das nackte Repository. Konfigurieren Sie die Einstellungen für Zugriffssteuerung. Starten Sie den SSH -Service. Zugriff auf den Benutzer gewähren. Testen Sie die Verbindung.
