
 Java
javaLernprogramm
Einführung in die Java-Grundlagen für praktische Anwendungen: Praktische Analyse von Big Data
Java
javaLernprogramm
Einführung in die Java-Grundlagen für praktische Anwendungen: Praktische Analyse von Big Data
Einführung in die Java-Grundlagen für praktische Anwendungen: Praktische Analyse von Big Data

Dieses Tutorial hilft Ihnen dabei, Fähigkeiten in der Big-Data-Analyse zu erlernen, von den Java-Grundlagen bis hin zu praktischen Anwendungen. Enthält Java-Grundlagen (Variablen, Kontrollfluss, Klassen usw.), Big-Data-Tools (Hadoop-Ökosystem, Spark, Hive) und praktische Fälle: Abrufen von Flugdaten von OpenFlights. Nutzen Sie Hadoop, um Daten zu lesen und zu verarbeiten und die häufigsten Flughäfen für Flugziele zu analysieren. Verwenden Sie Spark, um einen Drilldown durchzuführen und den neuesten Flug zu Ihrem Ziel zu finden. Verwenden Sie Hive, um Daten interaktiv zu analysieren und die Anzahl der Flüge an jedem Flughafen zu zählen.

Java-Grundlagen zur praktischen Anwendung: Praktische Analyse von Big Data
Einführung
Mit dem Aufkommen des Big-Data-Zeitalters ist die Beherrschung der Fähigkeiten zur Big-Data-Analyse von entscheidender Bedeutung geworden. Dieses Tutorial führt Sie vom Einstieg in die Java-Grundlagen bis zur Verwendung von Java für die praktische Big-Data-Analyse.
Java-Grundlagen
- Variablen, Datentypen und Operatoren
- Kontrollfluss (if-else, for, while)
- Klassen, Objekte und Methoden
- Arrays und Sammlungen (Listen, Karten, Mengen)
Big-Data-Analysetools
- Hadoop-Ökosystem (Hadoop, MapReduce, HDFS)
- Spark
- Hive
Praktischer Fall: Flugdaten mit Java analysieren
Schritt 1: Daten abrufen
Flug herunterladen Daten aus dem OpenFlights-Datensatz.
Schritt 2: Daten mit Hadoop lesen und schreiben
Daten mit Hadoop und MapReduce lesen und verarbeiten.
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlightStats {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Flight Stats");
job.setJarByClass(FlightStats.class);
job.setMapperClass(FlightStatsMapper.class);
job.setReducerClass(FlightStatsReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
public static class FlightStatsMapper extends Mapper<Object, Text, Text, IntWritable> {
@Override
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] line = value.toString().split(",");
context.write(new Text(line[1]), new IntWritable(1));
}
}
public static class FlightStatsReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values) {
sum += value.get();
}
context.write(key, new IntWritable(sum));
}
}
}Schritt 3: Verwenden Sie Spark für die weitere Analyse
Verwenden Sie Spark DataFrame und SQL-Abfragen, um die Daten zu analysieren.
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class FlightStatsSpark {
public static void main(String[] args) {
SparkSession spark = SparkSession.builder().appName("Flight Stats Spark").getOrCreate();
Dataset<Row> flights = spark.read().csv("hdfs:///path/to/flights.csv");
flights.createOrReplaceTempView("flights");
Dataset<Row> top10Airports = spark.sql("SELECT origin, COUNT(*) AS count FROM flights GROUP BY origin ORDER BY count DESC LIMIT 10");
top10Airports.show(10);
}
}Schritt 4: Verwenden Sie die interaktive Hive-Abfrage
Verwenden Sie die interaktive Hive-Abfrage, um die Daten zu analysieren.
CREATE TABLE flights (origin STRING, dest STRING, carrier STRING, dep_date STRING, dep_time STRING, arr_date STRING, arr_time STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; LOAD DATA INPATH 'hdfs:///path/to/flights.csv' OVERWRITE INTO TABLE flights; SELECT origin, COUNT(*) AS count FROM flights GROUP BY origin ORDER BY count DESC LIMIT 10;
Fazit
Durch dieses Tutorial beherrschen Sie die Grundlagen von Java und die Fähigkeiten, Java für die praktische Big-Data-Analyse einzusetzen. Wenn Sie Hadoop, Spark und Hive verstehen, können Sie große Datenmengen effizient analysieren und daraus wertvolle Erkenntnisse gewinnen.
Das obige ist der detaillierte Inhalt vonEinführung in die Java-Grundlagen für praktische Anwendungen: Praktische Analyse von Big Data. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
 Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Java -Programm, um das Kapselvolumen zu finden
Feb 07, 2025 am 11:37 AM
Kapseln sind dreidimensionale geometrische Figuren, die aus einem Zylinder und einer Hemisphäre an beiden Enden bestehen. Das Volumen der Kapsel kann berechnet werden, indem das Volumen des Zylinders und das Volumen der Hemisphäre an beiden Enden hinzugefügt werden. In diesem Tutorial wird erörtert, wie das Volumen einer bestimmten Kapsel in Java mit verschiedenen Methoden berechnet wird. Kapselvolumenformel Die Formel für das Kapselvolumen lautet wie folgt: Kapselvolumen = zylindrisches Volumenvolumen Zwei Hemisphäre Volumen In, R: Der Radius der Hemisphäre. H: Die Höhe des Zylinders (ohne die Hemisphäre). Beispiel 1 eingeben Radius = 5 Einheiten Höhe = 10 Einheiten Ausgabe Volumen = 1570,8 Kubikeinheiten erklären Berechnen Sie das Volumen mithilfe der Formel: Volumen = π × R2 × H (4
 Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Wie kann man Node.js oder Python -Dienste in Lampenarchitektur effizient integrieren?
Apr 01, 2025 pm 02:48 PM
Viele Website -Entwickler stehen vor dem Problem der Integration von Node.js oder Python Services unter der Lampenarchitektur: Die vorhandene Lampe (Linux Apache MySQL PHP) Architekturwebsite benötigt ...
 Java leicht gemacht: Ein Leitfaden für Anfänger zur Programmierleistung
Oct 11, 2024 pm 06:30 PM
Java leicht gemacht: Ein Leitfaden für Anfänger zur Programmierleistung
Oct 11, 2024 pm 06:30 PM
Java leicht gemacht: Ein Leitfaden für Anfänger zur leistungsstarken Programmierung Java ist eine leistungsstarke Programmiersprache, die in allen Bereichen von mobilen Anwendungen bis hin zu Systemen auf Unternehmensebene verwendet wird. Für Anfänger ist die Syntax von Java einfach und leicht zu verstehen, was es zu einer idealen Wahl zum Erlernen des Programmierens macht. Grundlegende Syntax Java verwendet ein klassenbasiertes objektorientiertes Programmierparadigma. Klassen sind Vorlagen, die zusammengehörige Daten und Verhaltensweisen organisieren. Hier ist ein einfaches Java-Klassenbeispiel: publicclassPerson{privateStringname;privateintage;
 Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Wie führe ich Ihre erste Spring -Boot -Anwendung in der Spring Tool Suite aus?
Feb 07, 2025 pm 12:11 PM
Spring Boot vereinfacht die Schaffung robuster, skalierbarer und produktionsbereiteter Java-Anwendungen, wodurch die Java-Entwicklung revolutioniert wird. Der Ansatz "Übereinkommen über Konfiguration", der dem Feder -Ökosystem inhärent ist, minimiert das manuelle Setup, Allo
 So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
So führen Sie das H5 -Projekt aus
Apr 06, 2025 pm 12:21 PM
Ausführen des H5 -Projekts erfordert die folgenden Schritte: Installation der erforderlichen Tools wie Webserver, Node.js, Entwicklungstools usw. Erstellen Sie eine Entwicklungsumgebung, erstellen Sie Projektordner, initialisieren Sie Projekte und schreiben Sie Code. Starten Sie den Entwicklungsserver und führen Sie den Befehl mit der Befehlszeile aus. Vorschau des Projekts in Ihrem Browser und geben Sie die Entwicklungsserver -URL ein. Veröffentlichen Sie Projekte, optimieren Sie Code, stellen Sie Projekte bereit und richten Sie die Webserverkonfiguration ein.
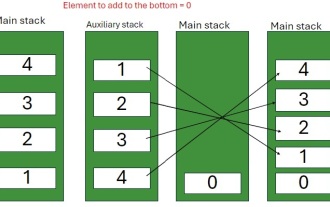 Java -Programm zum Einfügen eines Elements am unteren Rand eines Stapels
Feb 07, 2025 am 11:59 AM
Java -Programm zum Einfügen eines Elements am unteren Rand eines Stapels
Feb 07, 2025 am 11:59 AM
Ein Stapel ist eine Datenstruktur, die dem LIFO -Prinzip (zuletzt, zuerst heraus) folgt. Mit anderen Worten, das letzte Element, das wir einem Stapel hinzufügen, ist das erste, das entfernt wird. Wenn wir einem Stapel Elemente hinzufügen (oder drücken), werden sie oben platziert. vor allem der
