
 Technologie-Peripheriegeräte
KI
Fordern Sie OpenAI heraus, Microsofts selbst entwickelte streng geheime Waffe mit 500 Milliarden offengelegten Parametern! Der ehemalige Google DeepMind-Manager leitet das Team
Technologie-Peripheriegeräte
KI
Fordern Sie OpenAI heraus, Microsofts selbst entwickelte streng geheime Waffe mit 500 Milliarden offengelegten Parametern! Der ehemalige Google DeepMind-Manager leitet das Team
Fordern Sie OpenAI heraus, Microsofts selbst entwickelte streng geheime Waffe mit 500 Milliarden offengelegten Parametern! Der ehemalige Google DeepMind-Manager leitet das Team

Ohne OpenAI könnte Microsoft auch im Bereich KI führend werden!
Ausländische Medieninformationen verbreiteten die Nachricht, dass Microsoft intern sein erstes großes Modell MAl-1 mit 500 Milliarden Parametern entwickelt.

Dies ist für Nadella die Zeit, das Team anzuführen, um sich zu beweisen.
Nachdem Microsoft mehr als 10 Milliarden US-Dollar in OpenAI investiert hatte, erhielt Microsoft das Recht, das fortgeschrittene Modell GPT-3.5/GPT-4 zu nutzen, aber schließlich handelt es sich nicht um eine langfristige Lösung.
Es gab sogar Gerüchte, dass Microsoft auf eine IT-Abteilung von OpenAI reduziert wurde.
Wie jeder weiß, konzentrierte sich die LLM-Forschung von Microsoft im vergangenen Jahr hauptsächlich auf die Aktualisierung kleinerer Phi, wie beispielsweise der Open Source von Phi-3.
Was die Spezialisierung großer Modelle betrifft, mit Ausnahme der Turing-Serie, hat Microsoft keine internen Neuigkeiten bekannt gegeben.
Erst heute hat Kevin Scott, Chief Technology Officer von Microsoft, bestätigt, dass sich das große MAI-Modell tatsächlich in der Entwicklung befindet.

Offensichtlich besteht Microsofts geheimer Plan zur Vorbereitung großer Modelle darin, ein neues LLM zu entwickeln, das mit den Topmodellen von OpenAI, Google und Anthropic konkurrieren kann.
Immerhin hat Nadella einmal gesagt: „Es macht nichts, wenn OpenAI morgen verschwindet.“
„Wir haben Talente, Rechenleistung und Daten. Uns fehlt nichts. Wir sind unter ihnen, über ihnen und um sie herum.“

Es scheint, dass Microsofts Selbstvertrauen sich selbst übersteigt.

Selbst entwickeltes 500 Milliarden MAI-1-Großmodell
Berichten zufolge wird das MAI-1-Großmodell von Mustafa Suleyman, dem ehemaligen Chef von Google DeepMind, betreut.
Erwähnenswert ist, dass Suleyman vor seinem Eintritt bei Microsoft Gründer und CEO des KI-Start-ups Inflection AI war.
wurde 2022 gegründet. In einem Jahr führte er das Team zur Einführung des großen Modells Inflection (aktuell aktualisiert auf Version 2.5) und des KI-Assistenten Pi mit hohem EQ mit über einer Million täglichen Benutzern.
Da sie jedoch nicht das richtige Geschäftsmodell finden konnten, wechselten Suleyman, ein weiterer Lianchuang und die meisten Mitarbeiter im März zu Microsoft.

Mit anderen Worten, Suleyman und das Team sind für dieses neue Projekt MAI-1 verantwortlich und werden mehr Erfahrung mit hochmodernen Großmodellen einbringen.
Ich muss noch erwähnen, dass das MAI-1-Modell von Microsoft selbst entwickelt wurde und nicht vom Inflection-Modell übernommen wurde.
Laut zwei Microsoft-Mitarbeitern „unterscheidet sich MAI-1 von dem zuvor von Inflection veröffentlichten Modell.“ Der Trainingsprozess kann jedoch seine Trainingsdaten und -technologie nutzen.
Mit 500 Milliarden Parametern wird die Parameterskala von MAI-1 jedes von Microsoft in der Vergangenheit trainierte kleine Open-Source-Modell bei weitem übertreffen.
Dies bedeutet auch, dass mehr Rechenleistung und Daten erforderlich sind und die Schulungskosten ebenfalls hoch sind.
Um dieses neue Modell zu trainieren, hat Microsoft eine große Anzahl von Servern reserviert, die mit NVIDIA-GPUs ausgestattet sind, und Trainingsdaten zusammengestellt, um das Modell zu optimieren.
Einschließlich aus GPT-4 generiertem Text sowie verschiedenen Datensätzen aus externen Quellen (öffentliche Internetdaten).
Ich möchte sowohl große als auch kleine Modelle
Im Vergleich dazu hat GPT-4 nachweislich 1,8 Billionen Parameter, und KI-Unternehmen wie Meta und Mistral haben kleinere Open-Source-Modelle mit 70 Milliarden Parametern veröffentlicht.
Natürlich verfolgt Microsoft eine mehrgleisige Strategie, das heißt, große und kleine Modelle werden gemeinsam entwickelt.
Unter ihnen ist Phi-3 der Klassiker – ein kleines Modell, das in ein Mobiltelefon eingesetzt werden kann und dessen Mindestgröße von 3,8 B die Leistung von GPT-3,5 übertrifft.
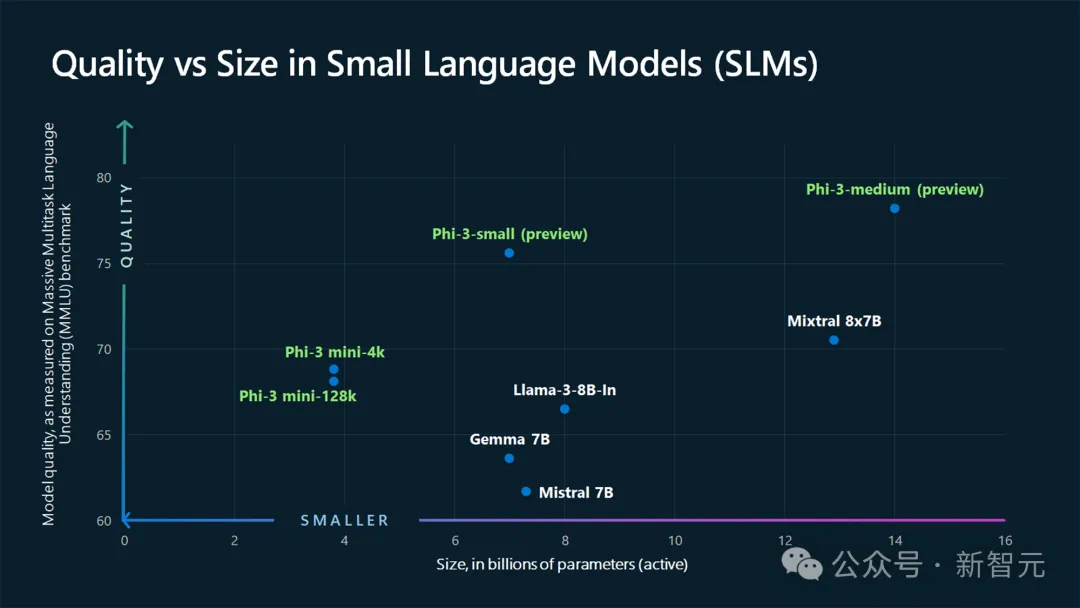
Phi-3 mini benötigt bei Quantisierung auf 4 Bit nur etwa 1,8 GB Speicher und kann mit iPhone14 12 Token pro Sekunde generieren.
Nachdem Internetnutzer die Frage aufgeworfen hatten: „Wäre es nicht besser, KI zu geringeren Kosten zu trainieren?“, antwortete Kevin Scott:
Dies ist keine Entweder-Oder-Beziehung. In vielen KI-Anwendungen verwenden wir eine Kombination aus großen, hochmodernen Modellen und kleineren, zielgerichteteren Modellen. Wir haben viel Arbeit geleistet, um sicherzustellen, dass SLM sowohl auf dem Gerät als auch in der Cloud gut funktioniert. Wir haben viel Erfahrung in der Schulung von SLM gesammelt und einige dieser Arbeiten sogar als Open Source bereitgestellt, damit andere sie studieren und nutzen können. Ich denke, dass diese Kombination aus Groß und Klein auf absehbare Zeit bestehen bleiben wird.
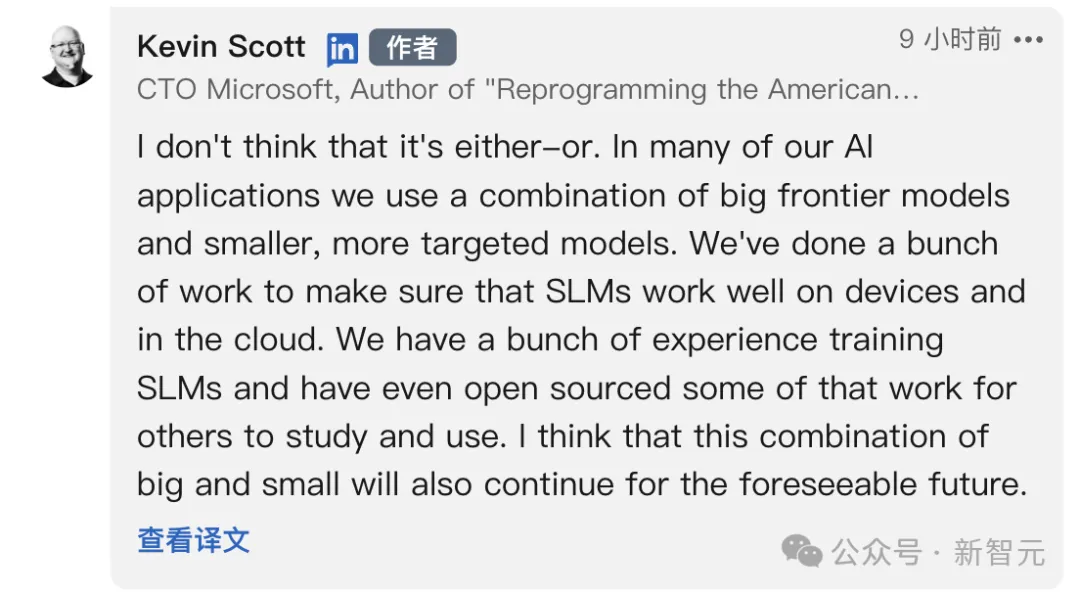
Dies zeigt, dass Microsoft nicht nur kostengünstige SLMs entwickeln muss, die in Anwendungen integriert und auf mobilen Geräten ausgeführt werden können, sondern auch größere und fortschrittlichere KI-Modelle entwickeln muss.
Aktuell bezeichnet sich Microsoft als „Copilot-Unternehmen“. Der auf KI basierende Copilot-Chatbot kann Aufgaben wie das Schreiben von E-Mails und das schnelle Zusammenfassen von Dokumenten erledigen.
Und wo liegen in Zukunft die nächsten Möglichkeiten?
Unter Berücksichtigung großer und kleiner Modelle zeigt sich, dass Microsoft voller Innovationskraft eher bereit ist, neue Wege in der KI zu gehen.
Möchten Sie nicht „IT“ für OpenAI sein?
Andererseits bedeutet das selbst entwickelte MAI-1 nicht, dass Microsoft OpenAI aufgeben wird.
In seinem Beitrag heute Morgen bekräftigte Chief Technology Officer Kevin Scott zunächst die solide „Freundschaft“ zwischen Microsoft und OpenAI seit fünf Jahren.
Wir haben für unseren Partner OpenAI große Supercomputer gebaut, um modernste KI-Modelle zu trainieren. Anschließend werden beide Unternehmen das Modell auf ihre eigenen Produkte und Dienstleistungen anwenden, um mehr Menschen zu nutzen.
Darüber hinaus wird jede neue Generation von Supercomputern leistungsfähiger sein als die vorherige Generation, sodass jedes von OpenAI trainierte Spitzenmodell fortschrittlicher sein wird als das letzte.
Wir werden diesen Weg weitergehen und kontinuierlich leistungsfähigere Supercomputer bauen, damit OpenAI Modelle trainieren kann, die in der gesamten Branche führend sind. Unsere Zusammenarbeit wird eine immer größere Wirkung haben.
Vor einiger Zeit enthüllten ausländische Medien, dass Microsoft und OpenAI ihre Kräfte zum Bau des KI-Supercomputers „Stargate“ gebündelt haben und dafür bis zu 115 Milliarden US-Dollar ausgeben werden.
Es wird gesagt, dass Supercomputing bereits 2028 eingeführt und vor 2030 weiter ausgebaut wird.

In der Vergangenheit haben Microsoft-Ingenieure dem Unternehmer Kyle Corbitt die Nachricht überbracht, dass Microsoft intensiv 100.000 H100 für OpenAI baut, um GPT-6 zu trainieren.

Es gibt verschiedene Anzeichen dafür, dass die Zusammenarbeit zwischen Microsoft und OpenAI nur noch stärker wird.
Darüber hinaus sagte Scott auch: „Neben der Zusammenarbeit mit OpenAI lässt Microsoft seit vielen Jahren MSR und verschiedene Produktteams KI-Modelle entwickeln.“
KI-Modelle sind in fast alle Produkte, Dienste und Abläufe von Microsoft eingedrungen. Manchmal müssen Teams auch Anpassungsarbeiten durchführen, sei es das Training eines Modells von Grund auf oder die Feinabstimmung eines vorhandenen Modells.
Es wird in Zukunft noch mehr ähnliche Situationen geben.
Einige dieser Modelle heißen Turing, MAI usw., andere heißen Phi und wir haben sie als Open Source bereitgestellt.
Obwohl mein Gesichtsausdruck vielleicht nicht so dramatisch ist, ist es die Realität. Für uns Geeks ist das eine sehr aufregende Realität, wenn man bedenkt, wie komplex das Ganze in der Praxis ist.
Entschlüsselung des „Turing“-Modells
Zusätzlich zu den Modellen der MAI- und Phi-Serie ist der Codename „Turing“ ein 2017 von Microsoft intern gestarteter Plan mit dem Ziel, ein großes Modell zu erstellen und es auf alle anzuwenden Produktlinien Mitte.

Nach drei Jahren Forschung und Entwicklung veröffentlichten sie im Jahr 2020 zum ersten Mal das 17-Milliarden-Parameter-T-NLG-Modell und stellten damit einen Rekord für das LLM mit der größten Parameterskala in der Geschichte auf.
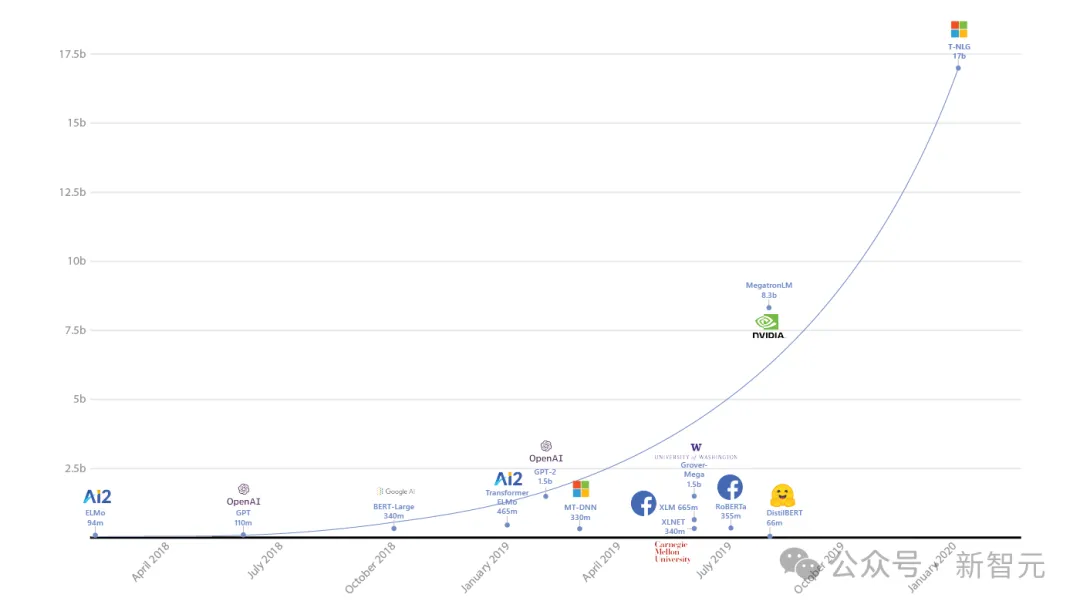
Im Jahr 2021 hat sich Microsoft mit NVIDIA zusammengetan, um das 530 Milliarden Parameter umfassende Megatron-Turing (MT-NLP) auf den Markt zu bringen, das bei einer Vielzahl natürlicher Sprachaufgaben „beispiellose“ Genauigkeit bewiesen hat.
Im selben Jahr wurde erstmals das visuelle Sprachmodell Turing Bletchley veröffentlicht.
Im August letzten Jahres wurde dieses multimodale Modell auf die V3-Version iteriert und in verwandte Produkte wie Bing integriert, um eine bessere Bildersuche zu ermöglichen.
Darüber hinaus veröffentlichte Microsoft 2021 und 2022 auch das „Turing Universal Language Representation Model“ – Versionen T-ULRv5 und T-ULRv6.
Derzeit wird das „Turing“-Modell in SmartFind beim Word- und Question Matching auf der Xbox verwendet.
Es gibt auch das vom Team entwickelte Bild-Superauflösungsmodell Turing Image Super-Resolution (T-ISR), das in Bing Maps angewendet wurde und die Qualität von Luftbildern für globale Benutzer verbessern kann.

Der konkrete Einsatzzweck des neuen MAI-1-Modells steht derzeit noch nicht fest und hängt von seiner Leistung ab.
Weitere Informationen zu MAI-1 werden übrigens möglicherweise erstmals auf der Microsoft Build Developer Conference vom 21. bis 23. Mai gezeigt.
Der nächste Schritt besteht darin, auf die Veröffentlichung von MAI-1 zu warten.
Das obige ist der detaillierte Inhalt vonFordern Sie OpenAI heraus, Microsofts selbst entwickelte streng geheime Waffe mit 500 Milliarden offengelegten Parametern! Der ehemalige Google DeepMind-Manager leitet das Team. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Offizielles iPhone 16 Pro und iPhone 16 Pro Max mit neuen Kameras, A18 Pro SoC und größeren Bildschirmen
Sep 10, 2024 am 06:50 AM
Offizielles iPhone 16 Pro und iPhone 16 Pro Max mit neuen Kameras, A18 Pro SoC und größeren Bildschirmen
Sep 10, 2024 am 06:50 AM
Apple hat endlich die Hüllen seiner neuen High-End-iPhone-Modelle entfernt. Das iPhone 16 Pro und das iPhone 16 Pro Max verfügen jetzt über größere Bildschirme im Vergleich zu ihren Gegenstücken der letzten Generation (6,3 Zoll beim Pro, 6,9 Zoll beim Pro Max). Sie erhalten einen verbesserten Apple A1
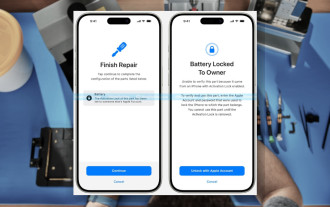 Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Anfang des Jahres kündigte Apple an, die Funktion „Aktivierungssperre“ auf iPhone-Komponenten auszuweiten. Dadurch werden einzelne iPhone-Komponenten wie Akku, Display, FaceID-Baugruppe und Kamerahardware effektiv mit einem iCloud-Konto verknüpft.
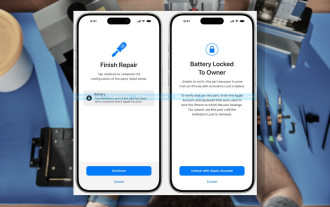 Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Anfang des Jahres kündigte Apple an, die Aktivierungssperre auf iPhone-Komponenten auszuweiten. Dadurch werden einzelne iPhone-Komponenten wie Akku, Display, FaceID-Baugruppe und Kamerahardware effektiv mit einem iCloud-Konto verknüpft.
 Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
In diesem Artikel werden die Schritte zum Registrieren und Herunterladen der neuesten App auf der offiziellen Website von Gate.io beschrieben. Zunächst wird der Registrierungsprozess eingeführt, einschließlich der Ausgabe der Registrierungsinformationen, der Überprüfung der E -Mail-/Mobiltelefonnummer und dem Ausfüllen der Registrierung. Zweitens wird erläutert, wie Sie die Gate.io -App auf iOS -Geräten und Android -Geräten herunterladen. Schließlich werden Sicherheits-Tipps betont, z. B. die Überprüfung der Authentizität der offiziellen Website, die Ermöglichung von zweistufiger Überprüfung und das Aufmerksamkeit von Phishing-Risiken, um die Sicherheit von Benutzerkonten und -vermögen zu gewährleisten.
 ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
Binance App Offizielle Installationsschritte: Android muss die offizielle Website besuchen, um den Download -Link zu finden. Wählen Sie die Android -Version zum Herunterladen und Installieren. Alle sollten auf die Vereinbarung über offizielle Kanäle achten.
 Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Wenn Sie bereits ein Gerät aus der iPhone 16-Reihe von Apple – genauer gesagt das 16 Pro/Pro Max – in die Hände bekommen haben, ist die Wahrscheinlichkeit groß, dass Sie kürzlich ein Problem mit dem Touchscreen hatten. Der Silberstreif am Horizont ist, dass Sie nicht allein sind – Berichte
 Laden Sie den Link des OUYI IOS -Versionsinstallationspakets herunter
Feb 21, 2025 pm 07:42 PM
Laden Sie den Link des OUYI IOS -Versionsinstallationspakets herunter
Feb 21, 2025 pm 07:42 PM
Ouyi ist ein weltweit führender Kryptowährungsaustausch mit seiner offiziellen iOS-App, die den Benutzern ein bequemes und sicheres Erlebnis für digitales Asset Management bietet. Benutzer können das Installationspaket Ouyi iOS -Version kostenlos über den in diesem Artikel bereitgestellten Download -Link herunterladen und die folgenden Hauptfunktionen genießen: Bequeme Handelsplattform: Benutzer können Hunderte von Kryptowährungen auf der OUYI IOS -App, einschließlich Bitcoin und Ethereum, problemlos kaufen und verkaufen und dotecoin. Sicherer und zuverlässiger Speicher: Ouyi nimmt fortschrittliche Sicherheitstechnologie ein, um den Benutzern einen sicheren und zuverlässigen digitalen Asset -Speicher zu bieten. 2FA, biometrische Authentifizierung und andere Sicherheitsmaßnahmen stellen sicher, dass Benutzervermögen nicht verletzt werden. Echtzeit-Marktdaten: Die OUYI IOS-App bietet Echtzeit-Marktdaten und -diagramme, sodass Benutzer die Verschlüsselung jederzeit erfassen können
 Wie löste ich das Problem des Fehlers 'Undefined Array Key '' 'Fehler beim Aufrufen von Alipay EasysDK mithilfe von PHP?
Mar 31, 2025 pm 11:51 PM
Wie löste ich das Problem des Fehlers 'Undefined Array Key '' 'Fehler beim Aufrufen von Alipay EasysDK mithilfe von PHP?
Mar 31, 2025 pm 11:51 PM
Problembeschreibung beim Aufrufen von Alipay EasysDK mithilfe von PHP nach dem Ausfüllen der Parameter gemäß dem offiziellen Code wurde während des Betriebs eine Fehlermeldung gemeldet: "undefiniert ...
