
 Technologie-Peripheriegeräte
KI
LeCun weitergeleitet, KI ermöglicht aphasischen Menschen wieder das Sprechen! NYU veröffentlicht neuen „Neural-Speech'-Decoder
Technologie-Peripheriegeräte
KI
LeCun weitergeleitet, KI ermöglicht aphasischen Menschen wieder das Sprechen! NYU veröffentlicht neuen „Neural-Speech'-Decoder
LeCun weitergeleitet, KI ermöglicht aphasischen Menschen wieder das Sprechen! NYU veröffentlicht neuen „Neural-Speech'-Decoder

Die Entwicklung der Gehirn-Computer-Schnittstelle (BCI) im Bereich der wissenschaftlichen Forschung und Anwendung hat in letzter Zeit große Aufmerksamkeit erregt. Die Menschen sind im Allgemeinen neugierig auf die Anwendungsaussichten von BCI.
Aphasie, die durch Defekte im Nervensystem verursacht wird, beeinträchtigt nicht nur das tägliche Leben der Patienten erheblich, sondern kann auch ihre berufliche Entwicklung und ihre sozialen Aktivitäten einschränken. Mit der rasanten Entwicklung von Deep Learning und Gehirn-Computer-Schnittstellentechnologie bewegt sich die moderne Wissenschaft in die Richtung, aphasischen Menschen durch neuronale Stimmprothesen dabei zu helfen, ihre Kommunikationsfähigkeiten wiederzuerlangen.
Das menschliche Gehirn hat eine Reihe aufregender Entwicklungen gemacht, und es gab viele Durchbrüche bei der Dekodierung von Signalen in Sprache, Operationen usw. Besonders erwähnenswert ist, dass Elon Musks Firma Neuralink mit ihrer bahnbrechenden Entwicklung der Gehirnschnittstellentechnologie ebenfalls bahnbrechende Fortschritte auf diesem Gebiet erzielt hat.
Das Unternehmen implantierte erfolgreich Elektroden in das Gehirn einer Testperson und ermöglichte so das Tippen, Spielen und andere Funktionen durch einfache Cursor-Bedienungen. Dies stellt einen weiteren Schritt in Richtung einer komplexeren neurosprachlichen/motorischen Dekodierung dar. Im Vergleich zu anderen Gehirn-Computer-Schnittstellentechnologien ist die Neuro-Sprachdekodierung komplexer und ihre Forschungs- und Entwicklungsarbeit basiert hauptsächlich auf einem speziellen Datenquellen-Elektrokortikogramm (ECoG).
Auf dem Bett kümmere ich mich hauptsächlich um die elektrodermalen Diagrammdaten, die ich während des Genesungsprozesses des Patienten erhalten habe. Die Forscher nutzten diese Elektroden, um Daten über die Gehirnaktivität während Lautäußerungen zu sammeln. Diese Daten verfügen nicht nur über ein hohes Maß an zeitlicher und räumlicher Auflösung, sondern haben auch bemerkenswerte Ergebnisse in der Sprachdekodierungsforschung erzielt und die Entwicklung der Gehirn-Computer-Schnittstellentechnologie erheblich vorangetrieben. Wir gehen davon aus, dass mithilfe dieser fortschrittlichen Technologien in Zukunft mehr Menschen mit neurologischen Störungen wieder die Freiheit zur Kommunikation erlangen werden.
Ein Durchbruch wurde in einer kürzlich in Nature veröffentlichten Studie erzielt, bei der quantisierte HuBERT-Merkmale als Zwischendarstellungen bei einem Patienten mit einem implantierten Gerät verwendet wurden, kombiniert mit einem vortrainierten Sprachsynthesizer, um diese Merkmale in Sprache umzuwandeln Die Methode verbessert nicht nur die Natürlichkeit der Sprache, sondern sorgt auch für eine hohe Genauigkeit.
Allerdings können die HuBERT-Funktionen die einzigartigen akustischen Eigenschaften des Sprechers nicht erfassen, und der erzeugte Klang ist normalerweise die Stimme eines einheitlichen Sprechers. Daher sind noch zusätzliche Modelle erforderlich, um diesen universellen Klang in die Stimme eines bestimmten Patienten umzuwandeln.
Ein weiterer bemerkenswerter Punkt ist, dass diese Studie und die meisten früheren Versuche eine nicht kausale Architektur verwendeten, was ihren praktischen Einsatz in Gehirn-Computer-Schnittstellenanwendungen, die kausale Operationen erfordern, möglicherweise einschränken.
Am 8. April 2024 veröffentlichten das New York University VideoLab und Flinker Lab gemeinsam eine bahnbrechende Forschungsarbeit in der Zeitschrift „Nature Machine Intelligence“.
 Bilder
Bilder
Link zum Papier: https://www.nature.com/articles/s42256-024-00824-8
Forschungsbezogener Code Open Source unter https://github.com/flinkerlab/ neural_speech_decoding
Weitere Beispiele für generierte Sprache unter: https://xc1490.github.io/nsd/
Diese Forschung mit dem Titel „Ein Framework zur neuronalen Sprachdekodierung, das Deep Learning und Sprachsynthese nutzt“ stellt einen innovativen differenzierbaren Sprachsynthesizer vor .
Dieser Synthesizer kombiniert ein leichtes Faltungs-Neuronales Netzwerk, um Sprache in eine Reihe interpretierbarer Sprachparameter wie Tonhöhe, Lautstärke und Formantenfrequenz zu kodieren und Sprache mithilfe differenzierbarer Techniken neu zu synthetisieren.
Diese Studie hat erfolgreich ein neuronales Sprachdekodierungssystem entwickelt, das gut interpretierbar und auf kleine Datensätze anwendbar ist, indem neuronale Signale diesen spezifischen Sprachparametern zugeordnet werden. Dieses System kann nicht nur Sprache mit hoher Wiedergabetreue und natürlichem Klang rekonstruieren, sondern auch eine empirische Grundlage für hohe Genauigkeit in zukünftigen Gehirn-Computer-Schnittstellenanwendungen liefern.
Das Forschungsteam sammelte Daten von insgesamt 48 Probanden und versuchte auf dieser Grundlage die Sprachdekodierung und legte damit eine solide Grundlage für die praktische Anwendung und Entwicklung hochpräziser Gehirn-Computer-Schnittstellentechnologie.
Turing-Award-Gewinner Lecun übermittelte ebenfalls den Forschungsfortschritt.
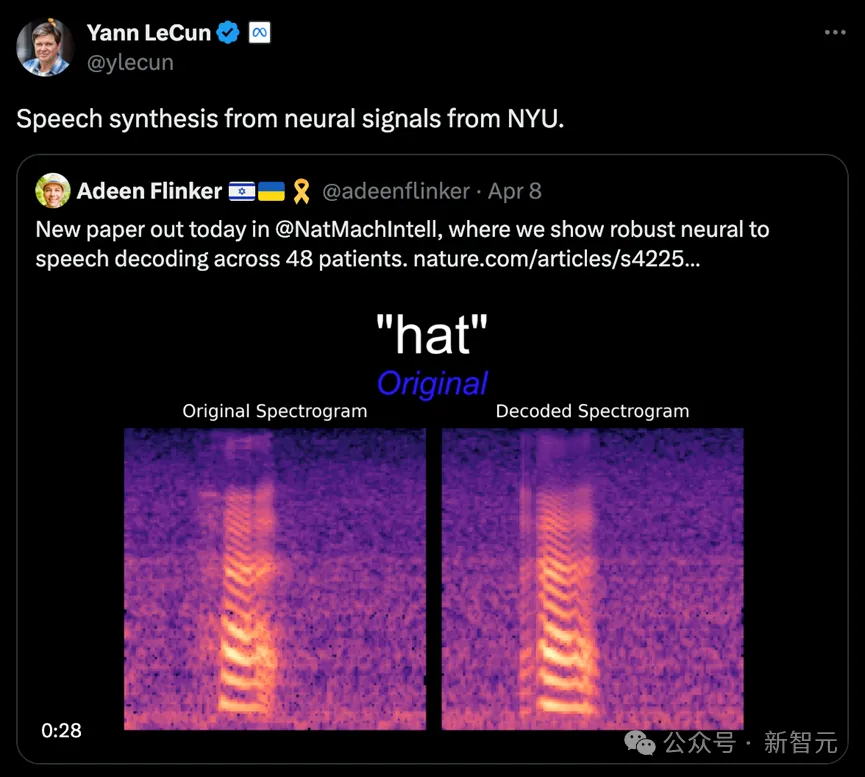 Bilder
Bilder
Forschungsstand
In der aktuellen Forschung zur neuronalen Signal-zu-Sprache-Dekodierung gibt es zwei zentrale Herausforderungen.
Das erste ist die Begrenzung des Datenvolumens: Um ein personalisiertes Neuronal-zu-Sprache-Dekodierungsmodell zu trainieren, beträgt die gesamte für jeden Patienten verfügbare Datenzeit normalerweise nur etwa zehn Minuten, was für Deep-Learning-Modelle sehr begrenzt ist die auf großen Mengen an Trainingsdaten basieren.
Zweitens erhöht die hohe Vielfalt der menschlichen Sprache auch die Komplexität der Modellierung. Selbst wenn dieselbe Person dasselbe Wort wiederholt ausspricht und buchstabiert, können sich Faktoren wie Sprechgeschwindigkeit, Intonation und Tonhöhe ändern, was die Konstruktion des Modells zusätzlich erschwert.
In frühen Versuchen verwendeten Forscher hauptsächlich lineare Modelle, um neuronale Signale in Sprache zu dekodieren. Diese Art von Modell erfordert nicht die Unterstützung eines großen Datensatzes und ist gut interpretierbar, ihre Genauigkeit ist jedoch normalerweise gering.
Mit der Weiterentwicklung der Deep-Learning-Technologie, insbesondere der Anwendung von Convolutional Neural Network (CNN) und Recurrent Neural Network (RNN), haben Forscher kürzlich Fortschritte bei der Simulation der intermediären latenten Darstellung von Sprache und der Verbesserung der Qualität synthetisierter Sprache erzielt Rede. Versuchen Sie es ausgiebig.
Zum Beispiel entschlüsseln einige Studien die Aktivität der Großhirnrinde in Mundbewegungen und wandeln sie dann in Sprache um. Obwohl diese Methode bei der Dekodierung leistungsfähiger ist, klingt die rekonstruierte Stimme oft nicht natürlich genug.
Darüber hinaus versuchen einige neue Methoden, Wavenet-Vocoder und Generative Adversarial Network (GAN) zu verwenden, um natürlich klingende Sprache zu rekonstruieren. Obwohl diese Methoden die Natürlichkeit des Klangs verbessern können, sind sie immer noch begrenzt in der Genauigkeit.
Hauptmodell-Framework
In dieser Studie demonstrierte das Forschungsteam ein innovatives Decodierungs-Framework von Elektroenzephalogramm-Signalen (ECoG) zu Sprache. Sie konstruierten einen niedrigdimensionalen latenten Repräsentationsraum, der durch ein leichtes Sprachkodierungs- und -dekodierungsmodell erzeugt wurde, das ausschließlich Sprachsignale verwendete.
Dieses Framework enthält zwei Kernteile: Erstens den ECoG-Decoder, der für die Umwandlung des ECoG-Signals in eine Reihe verständlicher akustischer Sprachparameter verantwortlich ist, wie z. B. Tonhöhe, ob es geäußert wird, Lautstärke und Formantenfrequenz usw. ; zweitens ist der Sprachsynthesizerteil verantwortlich für die Umwandlung dieser Parameter in ein Spektrogramm.
Durch den Aufbau eines differenzierbaren Sprachsynthesizers konnten die Forscher den ECoG-Decoder trainieren und gleichzeitig den Sprachsynthesizer optimieren, um gemeinsam den Fehler bei der Spektrogrammrekonstruktion zu reduzieren. Die starke Interpretierbarkeit dieses niedrigdimensionalen latenten Raums in Kombination mit den vom leichten vorab trainierten Sprachcodierer generierten Referenzsprachparametern macht das gesamte neuronale Sprachdecodierungsframework effizient und anpassungsfähig und löst so effektiv das Problem der Datenknappheit in diesem Bereich.
Darüber hinaus kann dieses Framework nicht nur natürliche Sprache erzeugen, die dem Sprecher sehr nahe kommt, sondern unterstützt auch das Einfügen mehrerer Deep-Learning-Modellarchitekturen in den ECoG-Decoder-Teil und kann kausale Operationen durchführen.
Das Forschungsteam verarbeitete die ECoG-Daten von 48 neurochirurgischen Patienten und nutzte verschiedene Deep-Learning-Architekturen (einschließlich Faltung, rekurrentes neuronales Netzwerk und Transformer), um die ECoG-Dekodierung zu erreichen.
Diese Modelle haben in Experimenten eine hohe Genauigkeit gezeigt, insbesondere bei denen, die die ResNet-Faltungsarchitektur verwenden. Dieser Forschungsrahmen erreicht nicht nur eine hohe Genauigkeit durch kausale Operationen und eine relativ niedrige Abtastrate (Abstand von 10 mm), sondern demonstriert auch die Fähigkeit, Sprache sowohl aus der linken als auch aus der rechten Gehirnhälfte effektiv zu dekodieren und so den Anwendungsbereich neuronaler Systeme zu erweitern Sprachdekodierung Zur rechten Gehirnhälfte.
 Bilder
Bilder
Eine der Kerninnovationen dieser Forschung ist die Entwicklung eines differenzierbaren Sprachsynthesizers, der die Effizienz der Sprachneusynthese erheblich verbessert und hochauflösendes Audio nahe am Original synthetisieren kann Klang .
Das Design dieses Sprachsynthesizers ist vom menschlichen Stimmsystem inspiriert und unterteilt die Sprache in zwei Teile: Stimme (hauptsächlich zur Simulation von Vokalen verwendet) und Unvoice (hauptsächlich zur Simulation von Konsonanten verwendet).
Im Sprachteil wird das Grundfrequenzsignal zunächst zur Erzeugung von Harmonischen verwendet und dann durch einen Filter geleitet, der aus den Formanten F1 bis F6 besteht, um die spektralen Eigenschaften des Vokals zu erhalten.
Für den Unvoice-Teil wird das entsprechende Spektrum durch eine spezifische Filterung des weißen Rauschens erzeugt. Ein lernbarer Parameter steuert das Mischungsverhältnis der beiden Teile zu jedem Zeitpunkt.
Abschließend wird das endgültige Sprachspektrum durch Anpassen des Lautstärkesignals und Hinzufügen von Hintergrundgeräuschen generiert.
Basierend auf diesem Sprachsynthesizer entwarf das Forschungsteam ein effizientes Sprachresynthese-Framework und ein neuronales Sprachdekodierungs-Framework. Eine detaillierte Rahmenstruktur finden Sie in Abbildung 6 des Originalartikels.
Forschungsergebnisse
1. Sprachdekodierungsergebnisse mit zeitlicher Kausalität
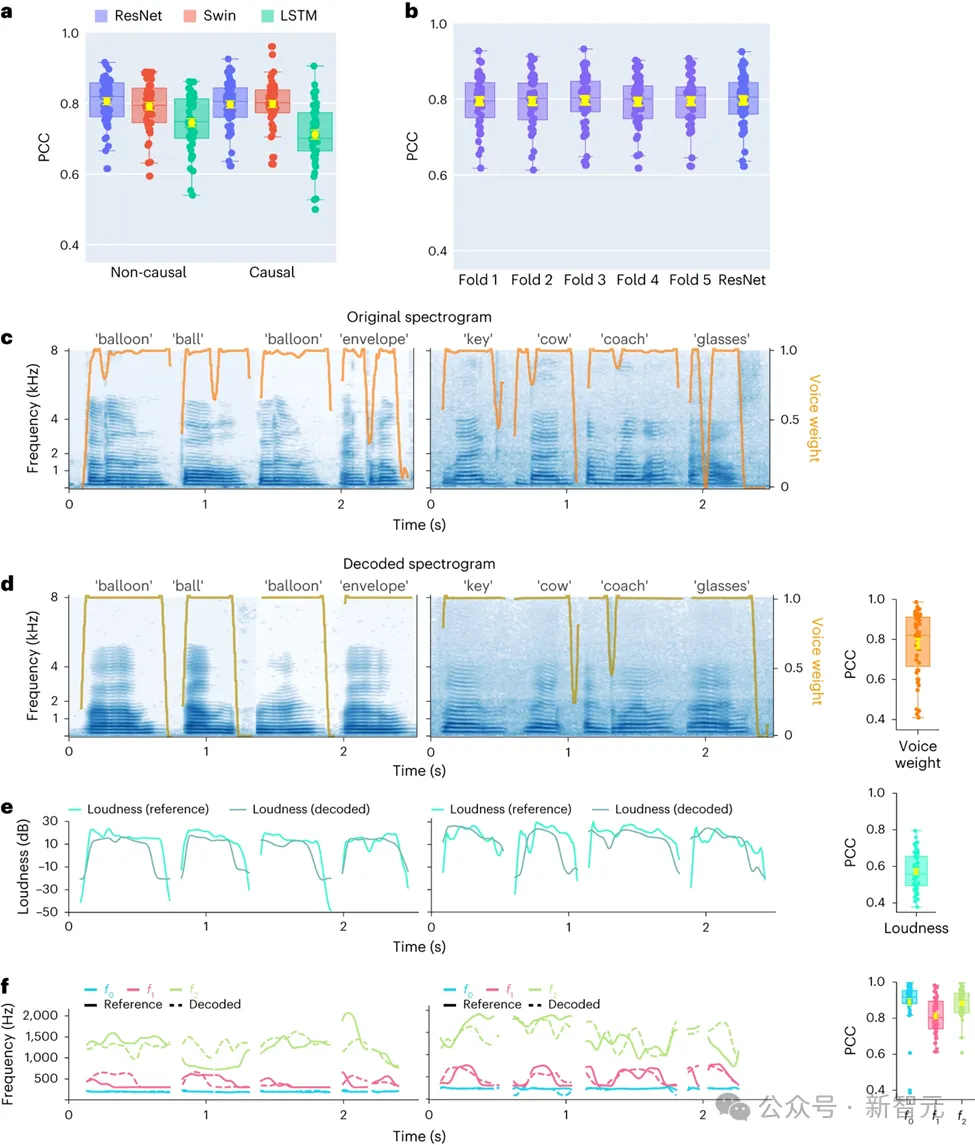
In dieser Studie verglichen die Forscher zunächst direkt verschiedene Modellarchitekturen, darunter Faltungsnetzwerke (ResNet), rekurrente neuronale Netzwerke (LSTM) und Transformer-Architekturen ( 3D Swin), um ihre Unterschiede in der Sprachdekodierungsleistung zu bewerten.
Es ist erwähnenswert, dass diese Modelle akausale oder kausale Operationen an Zeitreihen durchführen können.
 Bilder
Bilder
Bei der Anwendung der Gehirn-Computer-Schnittstelle (BCI) ist die Kausalität der Dekodierung von Modellen von großer Bedeutung: Kausalmodelle verwenden nur vergangene und aktuelle neuronale Signale, um Sprache zu erzeugen, nicht Ursache und Wirkung Das Modell bezieht sich auch auf zukünftige neuronale Signale, was in der Praxis nicht realisierbar ist.
Daher liegt der Schwerpunkt der Studie auf dem Vergleich der Leistung desselben Modells bei der Durchführung von kausalen und nicht-kausalen Operationen. Die Ergebnisse zeigen, dass selbst die kausale Version des ResNet-Modells eine mit der nicht-kausalen Version vergleichbare Leistung aufweist, ohne dass es einen signifikanten Leistungsunterschied zwischen den beiden gibt.
In ähnlicher Weise weisen die kausalen und nicht-kausalen Versionen des Swin-Modells eine ähnliche Leistung auf, aber die kausale Version des LSTM schneidet deutlich schlechter ab als seine nicht-kausale Version. Die Studie zeigte auch die durchschnittliche Dekodierungsgenauigkeit (Gesamtzahl von 48 Proben) für mehrere wichtige Sprachparameter, darunter Klanggewicht (ein Parameter, der Vokale von Konsonanten unterscheidet), Lautstärke, Grundfrequenz f0, erster Formant f1 und zweiter Formant f2.
Die genaue Rekonstruktion dieser Sprachparameter, insbesondere der Grundfrequenz, der Klanggewichtung und der ersten beiden Formanten, ist entscheidend für eine genaue Sprachdecodierung und eine natürliche Wiedergabe der Stimme des Teilnehmers.
Die Forschungsergebnisse zeigen, dass sowohl nicht-kausale als auch kausale Modelle sinnvolle Dekodierungseffekte liefern können, was positive Inspiration für zukünftige verwandte Forschung und Anwendungen bietet.
2. Forschung zur Sprachdekodierung und räumlichen Abtastrate neuronaler Signale der linken und rechten Gehirnhälfte
In der neuesten Studie untersuchten die Forscher den Leistungsunterschied bei der Sprachdekodierung zwischen der linken und rechten Gehirnhälfte weiter.
Traditionell konzentrierten sich die meisten Forschungen auf die linke Hemisphäre, die eng mit Sprache und Sprachfunktionen verbunden ist.
 Bilder
Bilder
Unser Verständnis der Fähigkeit der rechten Gehirnhälfte, verbale Informationen zu entschlüsseln, ist jedoch begrenzt. Um diesen Bereich zu erkunden, verglich das Forschungsteam die Dekodierungsleistung der linken und rechten Hemisphäre der Teilnehmer und überprüfte die Machbarkeit der Verwendung der rechten Hemisphäre zur Sprachwiederherstellung.
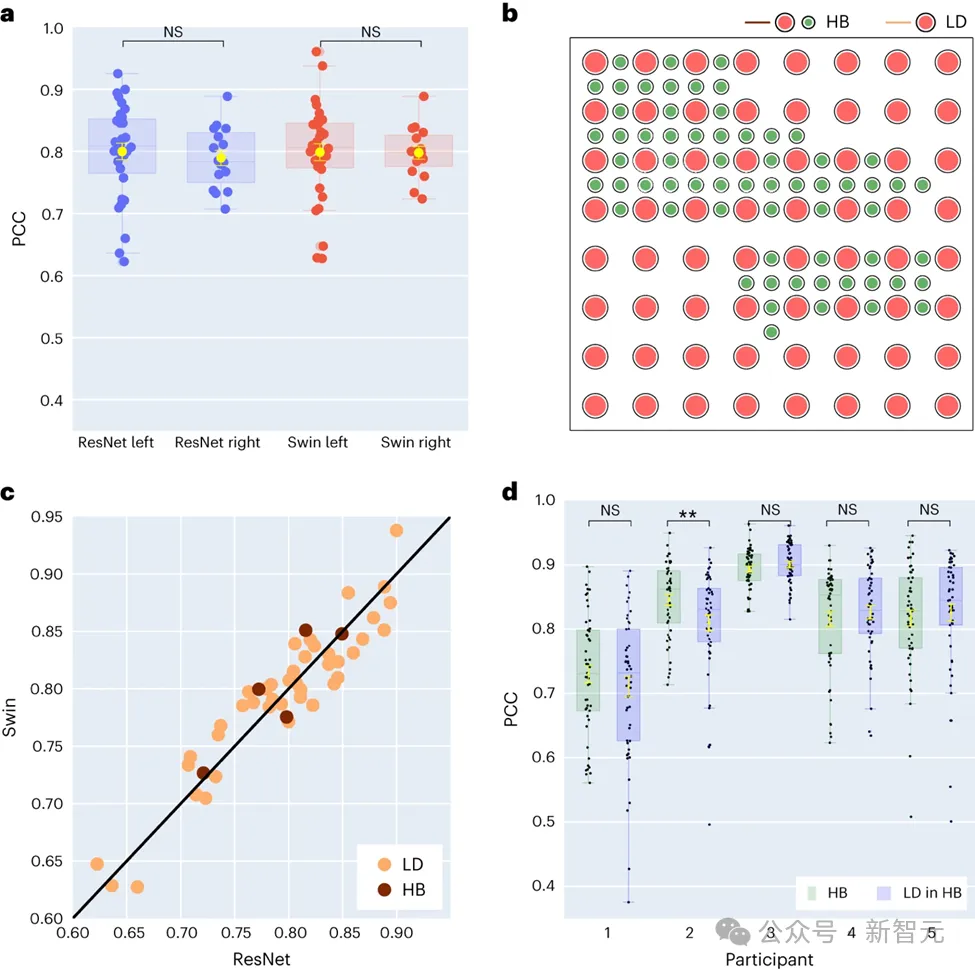
Von den 48 in der Studie erfassten Probanden hatten 16 ECoG-Signale von der rechten Gehirnhälfte. Durch den Vergleich der Leistung der ResNet- und Swin-Decoder stellten die Forscher fest, dass die rechte Hemisphäre auch Sprache effektiv dekodieren kann und dass ihre Wirkung der der linken Hemisphäre ähnelt. Die Entdeckung bietet eine mögliche Option zur Sprachwiederherstellung für Patienten mit einer Schädigung der linken Gehirnhälfte, die ihre Sprachfunktion verloren haben.
Die Forschung befasst sich auch mit dem Einfluss der Elektroden-Abtastdichte auf den Sprachdekodierungseffekt. Frühere Studien verwendeten meist Elektrodengitter mit höherer Dichte (0,4 mm), während die Dichte der in der klinischen Praxis üblicherweise verwendeten Elektrodengitter geringer ist (1 cm).
Fünf Teilnehmer dieser Studie verwendeten Hybrid-Elektrodengitter (HB), die hauptsächlich eine geringe Dichte aufweisen, denen jedoch einige zusätzliche Elektroden hinzugefügt wurden. Für die verbleibenden 43 Teilnehmer wurde eine Probenahme mit geringer Dichte durchgeführt.
Die Ergebnisse zeigen, dass die Decodierungsleistung dieser Hybrid-Abtastung (HB) der der herkömmlichen Abtastung mit niedriger Dichte (LD) ähnelt, was darauf hindeutet, dass das Modell Sprachinformationen effektiv aus unterschiedlichen Dichten von Elektrodengittern der Großhirnrinde lernen kann. Dieser Befund lässt darauf schließen, dass die in klinischen Umgebungen üblicherweise verwendeten Elektroden-Probenahmedichten ausreichen könnten, um zukünftige Gehirn-Computer-Schnittstellenanwendungen zu unterstützen.
3. Forschung zum Beitrag verschiedener Gehirnbereiche der linken und rechten Gehirnhälfte zur Sprachdekodierung
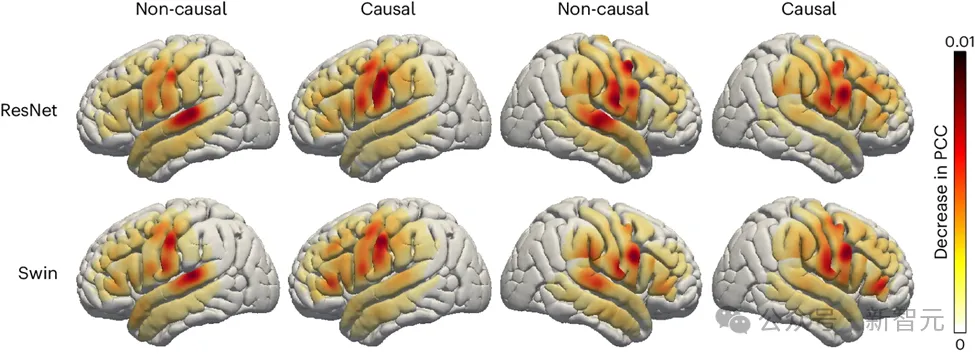
Die Forscher untersuchten auch die Rolle sprachbezogener Bereiche im Gehirn beim Sprachdekodierungsprozess, was Auswirkungen haben könnte Für die linke und rechte Gehirnhälfte der Zukunft sind Hemisphärische Implantate von Geräten zur Sprachwiederherstellung von großer Bedeutung. Um den Einfluss verschiedener Gehirnregionen auf die Sprachdekodierung zu beurteilen, verwendete das Forschungsteam eine Okklusionsanalyse.
Durch den Vergleich der kausalen und nicht-kausalen Modelle von ResNet- und Swin-Decodern ergab die Studie, dass im nicht-kausalen Modell die Rolle des auditorischen Kortex eine größere Rolle spielt. Dieses Ergebnis unterstreicht die Notwendigkeit, kausale Modelle in Echtzeit-Sprachdekodierungsanwendungen zu verwenden, die sich nicht auf zukünftige Neurofeedback-Signale verlassen können.
 Bilder
Bilder
Darüber hinaus zeigen Untersuchungen, dass der Beitrag des sensomotorischen Kortex, insbesondere des Bauchbereichs, zur Sprachdekodierung sowohl in der linken als auch in der rechten Gehirnhälfte ähnlich ist. Dieser Befund legt nahe, dass die Implantation einer neurologischen Prothese in die rechte Hemisphäre zur Wiederherstellung der Sprache eine praktikable Option sein könnte, und liefert wichtige Erkenntnisse für zukünftige Behandlungsstrategien.
Fazit (inspirierender Ausblick)
Das Forschungsteam entwickelte einen neuen Typ eines differenzierbaren Sprachsynthesizers, der ein leichtes Faltungs-Neuronales Netzwerk verwendet, um Sprache in eine Reihe interpretierbarer Parameter wie phonetische Höhe, Lautstärke und Formantenfrequenz zu kodieren usw. und verwenden Sie denselben differenzierbaren Synthesizer, um die Sprache neu zu synthetisieren.
Durch die Zuordnung neuronaler Signale zu diesen Parametern haben Forscher ein neuronales Sprachdekodierungssystem konstruiert, das gut interpretierbar und auf kleine Datensätze anwendbar ist und in der Lage ist, natürlich klingende Sprache zu erzeugen.
Dieses System zeigte bei 48 Teilnehmern ein hohes Maß an Reproduzierbarkeit, war in der Lage, Daten mit unterschiedlichen räumlichen Abtastdichten zu verarbeiten und war in der Lage, EEG-Signale von der linken und rechten Gehirnhälfte gleichzeitig zu verarbeiten, was seine Fähigkeit unter Beweis stellte. Großes Potenzial für Dekodierung.
Trotz erheblicher Fortschritte wiesen die Forscher auch auf einige aktuelle Einschränkungen des Modells hin, wie z. B. den Decodierungsprozess, der auf Sprachtrainingsdaten gepaart mit ECoG-Aufzeichnungen basiert und möglicherweise nicht auf Menschen mit Aphasie anwendbar ist.
In Zukunft hofft das Forschungsteam, eine Modellarchitektur zu etablieren, die mit Nicht-Grid-Daten umgehen und multipatienten- und multimodale EEG-Daten effektiver nutzen kann. Aufgrund der kontinuierlichen Weiterentwicklung der Hardware-Technologie und der rasanten Entwicklung der Deep-Learning-Technologie befindet sich die Forschung auf dem Gebiet der Gehirn-Computer-Schnittstelle noch in einem frühen Stadium, aber im Laufe der Zeit wird die Vision der Gehirn-Computer-Schnittstelle in Science-Fiction-Filmen schrittweise zunehmen Wirklichkeit werden.
Referenzen:
https://www.nature.com/articles/s42256-024-00824-8
Erster Autor dieses Artikels: Xupeng Chen (xc1490@nyu.edu), Ran Wang, Korrespondierender Autor: Adeen Flinker
Weitere Informationen zur Kausalität bei der Dekodierung neuronaler Sprache finden Sie in einem anderen Artikel der Autoren:
https://www.pnas.org/doi/10.1073/pnas.2300255120
Das obige ist der detaillierte Inhalt vonLeCun weitergeleitet, KI ermöglicht aphasischen Menschen wieder das Sprechen! NYU veröffentlicht neuen „Neural-Speech'-Decoder. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1209
24
52
1209
24

 Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Web3 Trading Platform Ranking_Web3 Globale Top Ten Summary Top Ten Summary
Apr 21, 2025 am 10:45 AM
Binance ist der Overlord des Global Digital Asset Trading -Ökosystems, und seine Merkmale umfassen: 1. Das durchschnittliche tägliche Handelsvolumen übersteigt 150 Milliarden US -Dollar, unterstützt 500 Handelspaare, die 98% der Mainstream -Währungen abdecken. 2. Die Innovationsmatrix deckt den Markt für Derivate, das Web3 -Layout und den Bildungssystem ab; 3. Die technischen Vorteile sind Millisekunden -Matching -Engines mit Spitzenvolumina von 1,4 Millionen Transaktionen pro Sekunde. 4. Compliance Progress hält 15 Länderlizenzen und legt konforme Einheiten in Europa und den Vereinigten Staaten ein.
 Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) Preisprognose 2025-2031: Wird WLD bis 2031 $ erreichen?
Apr 21, 2025 pm 02:42 PM
Worldcoin (WLD) fällt auf dem Kryptowährungsmarkt mit seinen einzigartigen biometrischen Überprüfungs- und Datenschutzschutzmechanismen auf, die die Aufmerksamkeit vieler Investoren auf sich ziehen. WLD hat mit seinen innovativen Technologien, insbesondere in Kombination mit OpenAI -Technologie für künstliche Intelligenz, außerdem unter Altcoins gespielt. Aber wie werden sich die digitalen Vermögenswerte in den nächsten Jahren verhalten? Lassen Sie uns den zukünftigen Preis von WLD zusammen vorhersagen. Die Preisprognose von 2025 WLD wird voraussichtlich im Jahr 2025 ein signifikantes Wachstum in WLD erzielen. Die Marktanalyse zeigt, dass der durchschnittliche WLD -Preis 1,31 USD mit maximal 1,36 USD erreichen kann. In einem Bärenmarkt kann der Preis jedoch auf rund 0,55 US -Dollar fallen. Diese Wachstumserwartung ist hauptsächlich auf Worldcoin2 zurückzuführen.
 Rangliste der Hebelbörsen im Währungskreis Die neuesten Empfehlungen der zehn meistgezogenen Börsen im Währungskreis
Apr 21, 2025 pm 11:24 PM
Rangliste der Hebelbörsen im Währungskreis Die neuesten Empfehlungen der zehn meistgezogenen Börsen im Währungskreis
Apr 21, 2025 pm 11:24 PM
Die Plattformen, die im Jahr 2025 im Leveraged Trading, Security und Benutzererfahrung hervorragende Leistung haben, sind: 1. OKX, geeignet für Hochfrequenzhändler und bieten bis zu 100-fache Hebelwirkung; 2. Binance, geeignet für Mehrwährungshändler auf der ganzen Welt und bietet 125-mal hohe Hebelwirkung; 3. Gate.io, geeignet für professionelle Derivate Spieler, die 100 -fache Hebelwirkung bietet; 4. Bitget, geeignet für Anfänger und Sozialhändler, die bis zu 100 -fache Hebelwirkung bieten; 5. Kraken, geeignet für stetige Anleger, die fünfmal Hebelwirkung liefert; 6. Bybit, geeignet für Altcoin -Entdecker, die 20 -fache Hebelwirkung bietet; 7. Kucoin, geeignet für kostengünstige Händler, die 10-fache Hebelwirkung bietet; 8. Bitfinex, geeignet für das Seniorenspiel
 Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Was bedeutet Cross-Chain-Transaktion? Was sind die Cross-Chain-Transaktionen?
Apr 21, 2025 pm 11:39 PM
Börsen, die Cross-Chain-Transaktionen unterstützen: 1. Binance, 2. Uniswap, 3. Sushiswap, 4. Kurvenfinanzierung, 5. Thorchain, 6. 1inch Exchange, 7. DLN-Handel, diese Plattformen unterstützen Multi-Chain-Asset-Transaktionen durch verschiedene Technologien.
 Top 10 Cryptocurrency Exchange -Plattformen Die weltweit größte Liste der digitalen Währung
Apr 21, 2025 pm 07:15 PM
Top 10 Cryptocurrency Exchange -Plattformen Die weltweit größte Liste der digitalen Währung
Apr 21, 2025 pm 07:15 PM
Börsen spielen eine wichtige Rolle auf dem heutigen Kryptowährungsmarkt. Sie sind nicht nur Plattformen, an denen Investoren handeln, sondern auch wichtige Quellen für Marktliquidität und Preisentdeckung. Der weltweit größte virtuelle Währungsbörsen gehören zu den Top Ten, und diese Börsen sind nicht nur im Handelsvolumen weit voraus, sondern haben auch ihre eigenen Vorteile in Bezug auf Benutzererfahrung, Sicherheit und innovative Dienste. Börsen, die über die Liste stehen, haben normalerweise eine große Benutzerbasis und einen umfangreichen Markteinfluss, und deren Handelsvolumen und Vermögenstypen sind häufig mit anderen Börsen schwer zu erreichen.
 Aavenomics ist eine Empfehlung, das Aave -Protokoll -Token zu ändern und Token -Rückkauf einzuführen, die die Quorum -Anzahl von Personen erreicht hat.
Apr 21, 2025 pm 06:24 PM
Aavenomics ist eine Empfehlung, das Aave -Protokoll -Token zu ändern und Token -Rückkauf einzuführen, die die Quorum -Anzahl von Personen erreicht hat.
Apr 21, 2025 pm 06:24 PM
Aavenomics ist ein Vorschlag zur Änderung des Aave -Protokoll -Tokens und zur Einführung von Token -Repos, die ein Quorum für Aavedao implementiert hat. Marc Zeller, Gründer der AAVE -Projektkette (ACI), kündigte dies auf X an und stellte fest, dass sie eine neue Ära für die Vereinbarung markiert. Marc Zeller, Gründer der Aave Chain Initiative (ACI), kündigte auf X an, dass der Aavenomics -Vorschlag das Modifizieren des Aave -Protokoll -Tokens und die Einführung von Token -Repos umfasst, hat ein Quorum für Aavedao erreicht. Laut Zeller ist dies eine neue Ära für die Vereinbarung. AVEDAO -Mitglieder stimmten überwiegend für die Unterstützung des Vorschlags, der am Mittwoch 100 pro Woche betrug
 Was sind die Hybrid -Blockchain -Handelsplattformen?
Apr 21, 2025 pm 11:36 PM
Was sind die Hybrid -Blockchain -Handelsplattformen?
Apr 21, 2025 pm 11:36 PM
Vorschläge für die Auswahl eines Kryptowährungsaustauschs: 1. Für die Liquiditätsanforderungen ist Priorität Binance, Gate.io oder OKX aufgrund seiner Bestelltiefe und der starken Volatilitätsbeständigkeit. 2. Compliance and Security, Coinbase, Kraken und Gemini haben strenge regulatorische Bestätigung. 3. Innovative Funktionen, Kucoins sanftes Stakel und Derivatdesign von Bitbit eignen sich für fortschrittliche Benutzer.
 Was sind die zehn besten Plattformen im Währungsaustauschkreis?
Apr 21, 2025 pm 12:21 PM
Was sind die zehn besten Plattformen im Währungsaustauschkreis?
Apr 21, 2025 pm 12:21 PM
Zu den Top -Börsen gehören: 1. Binance, das weltweit größte Handelsvolumen, unterstützt 600 Währungen und die Spot -Handhabungsgebühr beträgt 0,1%. 2. OKX, eine ausgewogene Plattform, unterstützt 708 Handelspaare, und die dauerhafte Vertragsabwicklungsgebühr beträgt 0,05%. 3. Gate.io deckt 2700 kleine Währungen ab, und die Gebühr für die Spot-Handhabung beträgt 0,1%-0,3%; 4. Coinbase, der US -Konformitäts -Benchmark, die Spot -Handhabungsgebühr beträgt 0,5%; 5. Kraken, die Top -Sicherheit und regelmäßige Reserveprüfung.
