Die AIxiv-Kolumne ist eine Kolumne, in der diese Website akademische und technische Inhalte veröffentlicht. In den letzten Jahren sind in der AIxiv-Kolumne dieser Website mehr als 2.000 Berichte eingegangen, die Spitzenlabore großer Universitäten und Unternehmen auf der ganzen Welt abdecken und so den akademischen Austausch und die Verbreitung wirksam fördern. Wenn Sie hervorragende Arbeiten haben, die Sie teilen möchten, können Sie gerne einen Beitrag leisten oder uns für die Berichterstattung kontaktieren. Einreichungs-E-Mail: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
Multimodale Fusion ist eine der Grundaufgaben der multimodalen Intelligenz. Die Motivation der multimodalen Fusion besteht darin, effektive Informationen aus verschiedenen Modalitäten gemeinsam zu nutzen, um die Genauigkeit und Stabilität nachgelagerter Aufgaben zu verbessern. Herkömmliche multimodale Fusionsmethoden basieren oft auf qualitativ hochwertigen Daten und lassen sich nur schwer an die komplexen und minderwertigen multimodalen Daten in realen Anwendungen anpassen. Eine Überprüfung der multimodalen Datenfusion geringer Qualität „Multimodal Fusion on Low-Quality“, gemeinsam veröffentlicht von der Tianjin-Universität, der Renmin-Universität China, der Singapore Agency for Science, Technology and Research, der Sichuan-Universität und der Xi'an-Universität Electronic Science and Technology and Harbin Institute of Technology (Shenzhen) Data: A Comprehensive Survey“ stellt die Fusionsherausforderungen multimodaler Daten aus einer einheitlichen Perspektive vor und sortiert die bestehenden Fusionsmethoden minderwertiger multimodaler Daten und potenzielle Entwicklungen Richtungen in diesem Bereich. http://arxiv.org/abs/2404.18947https://github.com/QingyangZhang/awesome-low-quality-multimodal-learning Traditionelles multimodales FusionsmodellMenschen nehmen die Welt wahr, indem sie Informationen aus mehreren Modalitäten fusionieren. Selbst wenn die Signale einiger Modalitäten unzuverlässig sind, ist der Mensch in der Lage, diese minderwertigen multimodalen Datensignale zu verarbeiten und die Umgebung wahrzunehmen. Obwohl beim multimodalen Lernen große Fortschritte gemacht wurden, mangelt es multimodalen Modellen des maschinellen Lernens immer noch an der Fähigkeit, multimodale Daten geringer Qualität in der realen Welt effektiv zusammenzuführen. In der Praxis wird die Leistung traditioneller multimodaler Fusionsmodelle in den folgenden Szenarien erheblich abnehmen: (1) Verrauschte multimodale Daten: Einige Merkmale einiger Modalitäten werden durch Rauschen gestört und gehen Originalinformationen verloren . In der realen Welt können unbekannte Umgebungsfaktoren, Sensorausfälle und Signalverluste während der Übertragung zu Rauschstörungen führen und dadurch die Zuverlässigkeit des multimodalen Fusionsmodells beeinträchtigen. (2)Fehlende multimodale Daten: Aufgrund verschiedener praktischer Faktoren können einige Modalitäten der tatsächlich erfassten multimodalen Datenproben fehlen. Beispielsweise können im medizinischen Bereich die multimodalen Daten, die sich aus den verschiedenen physiologischen Untersuchungsergebnissen der Patienten zusammensetzen, ernsthaft fehlen, und einige Patienten haben möglicherweise noch nie eine bestimmte Untersuchung erhalten. (3) Unausgeglichene multimodale Daten: Aufgrund des inkonsistenten Phänomens heterogener Codierungsattribute und Informationsqualitätsunterschieden zwischen Modalitäten tritt das Problem des unausgewogenen Lernens zwischen Modalitäten auf. Während des multimodalen Fusionsprozesses verlässt sich das Modell möglicherweise zu sehr auf bestimmte Modalitäten und ignoriert die potenziell wirksamen Informationen, die in anderen Modalitäten enthalten sind. (4) Dynamische multimodale Daten geringer Qualität: Aufgrund der Komplexität und Änderung der Anwendungsumgebung, unterschiedlicher Stichproben, unterschiedlicher Zeit und Raum weist die modale Qualität dynamische Änderungseigenschaften auf. Das Auftreten minderwertiger Modaldaten lässt sich oft nur schwer im Voraus vorhersagen, was die multimodale Fusion vor Herausforderungen stellt. Um die Art und Verarbeitungsmethoden minderwertiger multimodaler Daten vollständig zu charakterisieren, fasst dieser Artikel die aktuellen Methoden des maschinellen Lernens im Bereich der minderwertigen multimodalen Fusion zusammen und überprüft systematisch den Entwicklungsprozess in Dieses Gebiet wird weiter untersucht, und Fragen, die weiterer Forschung bedürfen, werden weiter untersucht. 
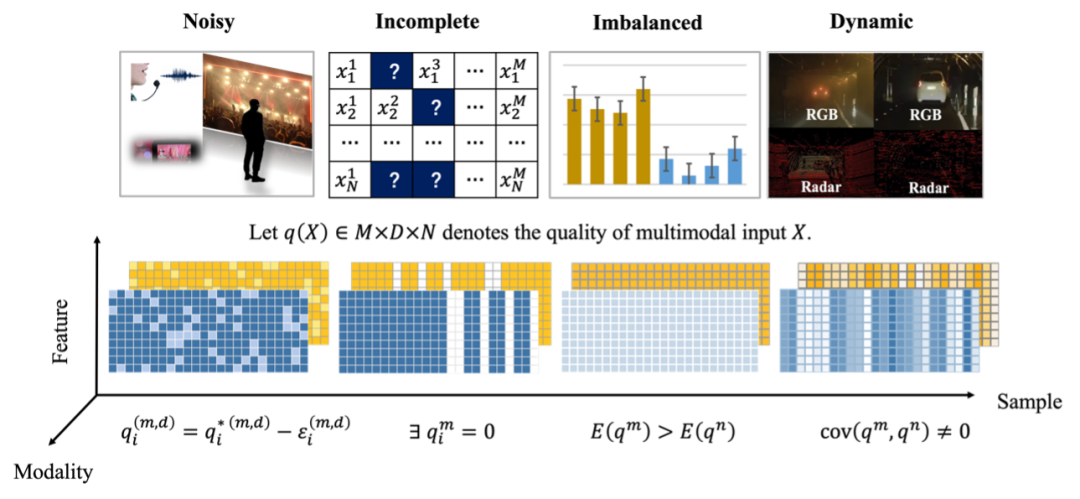
多 Abbildung 1. Schematische Darstellung der multimodalen Datenklassifizierung mit niedriger Qualität. Gelb und Blau stellen zwei Modi dar. Je dunkler die Farbe, desto höher die Qualität der Qualität: Rauschen ist eine der häufigsten Ursachen für die Verschlechterung der multimodalen Datenqualität. Dieser Artikel konzentriert sich hauptsächlich auf zwei Arten von Lärm: Modusbedingter multimodaler Lärm
. Diese Art von Lärm kann durch Faktoren wie Sensorfehler (z. B. Instrumentenfehler bei der medizinischen Diagnose), Umweltfaktoren (z. B. Regen und Nebel beim autonomen Fahren) verursacht werden und der Lärm ist auf bestimmte Funktionsniveaus innerhalb eines bestimmten Modus beschränkt.
(2) Crossmodales Rauschen auf semantischer Ebene. Diese Art von Rauschen wird durch die Fehlausrichtung der Semantik auf hoher Ebene zwischen den Modalitäten verursacht und ist schwieriger zu handhaben als multimodales Rauschen auf der Merkmalsebene. Glücklicherweise hat sich aufgrund der Komplementarität zwischen multimodalen Datenmodi und der Redundanz von Informationen die Kombination von Informationen aus mehreren Modalitäten zur Rauschunterdrückung als wirksame Strategie im multimodalen Fusionsprozess erwiesen. Methodenklassifizierung:
Multimodale Entrauschungsmethoden auf Funktionsebene hängen stark von den spezifischen Modalitäten ab, die an der eigentlichen Aufgabe beteiligt sind. Dieser Artikel dient hauptsächlich der Veranschaulichung der multimodalen Bildfusionsaufgabe als Beispiel. Bei der multimodalen Bildfusion umfassen die gängigen Entrauschungsmethoden gewichtete Fusion und gemeinsame Variation. Gewichtete FusionsmethodeAngesichts der Tatsache, dass Merkmalsrauschen zufällig ist und reale Daten einer bestimmten Verteilung unterliegen, wird der Einfluss von Rauschen durch gewichtete Summierung eliminiert; Die modale Bildvariationsentrauschung kann den Entrauschungsprozess in einen Optimierungsprozess zur Problemlösung umwandeln und ergänzende Informationen aus mehreren Modalitäten verwenden, um den Entrauschungseffekt zu verbessern. Kreuzmodales Rauschen auf semantischer Ebene resultiert aus schwach ausgerichteten oder falsch ausgerichteten multimodalen Stichprobenpaaren.
Bei der multimodalen Zielerkennungsaufgabe, bei der RGB- und Wärmebilder kombiniert werden, kann es aufgrund unterschiedlicher Sensoren zu geringfügigen Unterschieden kommen, obwohl in beiden Modalitäten dasselbe Ziel angezeigt wird. schwache Ausrichtung) in verschiedenen Modalitäten, was die genaue Schätzung von Positionsinformationen mit sich bringt.
Bei der Aufgabe des Inhaltsverständnisses in sozialen Medien können die semantischen Informationen, die in den Bild- und Textmodalitäten eines Beispiels (z. B. eines Weibo) enthalten sind, sehr unterschiedlich oder sogar irrelevant (völlig falsch ausgerichtet) sein, was weitere größere Herausforderungen mit sich bringt zur multimodalen Fusion. Zu den Möglichkeiten, mit modalübergreifendem semantischem Rauschen umzugehen, gehören Regelfilterung, Modellfilterung, rauschrobuste Modellregularisierung und andere Methoden. Zukunftsausblick:
Obwohl die Verarbeitung von Datenrauschen in klassischen maschinellen Lernaufgaben schon lange umfassend untersucht wurde, wird in multimodalen Szenarien untersucht, wie die Unterschiede zwischen Komplementarität und Konsistenz gemeinsam genutzt werden können Die Abschwächung der Auswirkungen von Lärm ist immer noch ein dringendes Forschungsproblem, das gelöst werden muss. Darüber hinaus ist die Lösung von Rauschen auf semantischer Ebene während des Vortrainings- und Inferenzprozesses multimodaler großer Modelle im Gegensatz zur herkömmlichen Rauschunterdrückung auf Merkmalsebene ein interessantes und äußerst herausforderndes Problem.
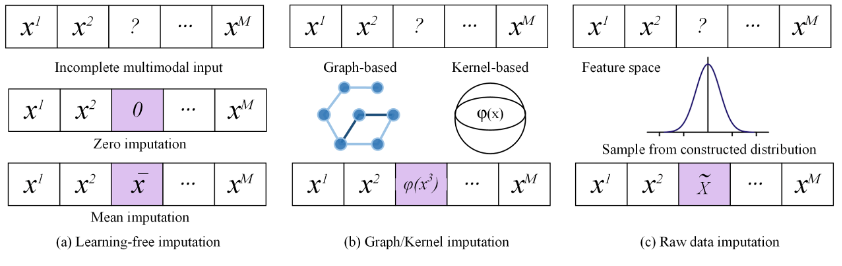
Tabelle 1. Klassifizierung multimodaler Fusionsmethoden für Rauschen Meldung multimodaler Datenfusionsmethoden In reale Szenarien Die gesammelten multimodalen Daten sind oft unvollständig. Aufgrund verschiedener Faktoren wie Schäden am Speichergerät und unzuverlässigem Datenübertragungsprozess verlieren multimodale Daten oft zwangsläufig einen Teil der modalen Informationen. Zum Beispiel: Im Empfehlungssystem stellen der Browserverlauf und die Bonität des Benutzers multimodale Daten dar. Aufgrund von Berechtigungs- und Datenschutzproblemen ist es jedoch oft unmöglich, alle modalen Informationen des Benutzers vollständig zu sammeln Multimodales Datensystem. In der medizinischen Diagnostik sind die multimodalen Diagnosedaten verschiedener Patienten aufgrund der begrenzten Ausstattung einiger Krankenhäuser und der hohen Kosten für spezifische Untersuchungen oft sehr unvollständig. Nach dem Klassifizierungsprinzip „ob eine explizite Vervollständigung fehlender multimodaler Daten erforderlich ist“ können fehlende multimodale Datenfusionsmethoden unterteilt werden in: (1) Vervollständigungsbasierte multimodale Fusionsmethode Die vervollständigungsbasierte multimodale Fusionsmethode umfasst modellunabhängige Vervollständigungsmethoden: wie das direkte Füllen fehlender Modi mit 0-Werten oder Restmodi. Vervollständigungsmethode von der Mittelwert; Vervollständigungsmethode basierend auf Diagramm oder Kernel: Diese Art von Methode lernt nicht direkt, wie die ursprünglichen multimodalen Daten vervollständigt werden, sondern erstellt für jede Modalität ein Diagramm oder einen Kernel und lernt dann Ähnlichkeits- oder Korrelationsinformationen zwischen Beispielpaaren und vervollständigen Sie dann die fehlenden Daten. Vervollständigen Sie direkt die ursprüngliche Feature-Ebene: Einige Methoden verwenden generative Modelle, wie z. B. das generative gegnerische Netzwerk GAN und seine Varianten. Vervollständigen Sie fehlende Features direkt. (2) Multimodale Fusionsmethode ohne Abschluss. Im Gegensatz zu vervollständigungsbasierten Methoden konzentrieren sich Methoden, die keine Vervollständigung erfordern, darauf, wie die nützlichen Informationen, die in den nicht fehlenden Modalitäten enthalten sind, genutzt werden können, um die bestmöglichen Darstellungen zu verschmelzen. Diese Art von Methode hat häufig negative Auswirkungen Die einheitliche Darstellung fügt Einschränkungen hinzu, sodass diese Darstellung die vollständigen Informationen der beobachtbaren Modaldaten widerspiegeln kann, um den Vervollständigungsprozess für die multimodale Fusion zu umgehen. Obwohl im In- und Ausland viele Methoden zur Lösung von Clustering-Problemen unvollständiger multimodaler Datenfusion bei klassischen maschinellen Lernaufgaben wie Klassifizierung und Klassifizierung vorgeschlagen wurden, gibt es noch einige tiefere Herausforderungen. Beispiel: Die Qualitätsbewertung von Abschlussdaten in fehlenden modalen Abschlussplänen wird oft übersehen.
Darüber hinaus ist die Strategie, a priori fehlende Datenstandortinformationen zu verwenden, um fehlende Modalitäten selbst zu maskieren, schwierig, die durch die fehlenden Modalitäten verursachte Informationslücke und das Informationsungleichgewicht auszugleichen.
Tabelle 2. Klassifizierung von Fusionsmethoden für fehlende multimodale Daten In vielen Fällen wird beim modalen Lernen normalerweise gemeinsames Training verwendet, um Daten aus verschiedenen Modalitäten zu integrieren und so die Gesamtleistung und Generalisierungsleistung zu verbessern das Model. Diese Art von weit verbreitetem gemeinsamen Trainingsparadigma, das ein einheitliches Lernziel verwendet, ignoriert jedoch die Heterogenität der Daten in verschiedenen Modalitäten.
Die Heterogenität verschiedener Modalitäten in Bezug auf Datenquellen und -formen
führt dazu, dass sie unterschiedliche Eigenschaften in Bezug auf Konvergenzgeschwindigkeit usw. aufweisen, was es für alle Modalitäten schwierig macht, gut verarbeitet und erlernt zu werden bringt gleichzeitig Schwierigkeiten für das multimodale gemeinsame Lernen mit sich
Andererseits spiegelt sich dieser Unterschied auch in der Qualität der einzelmodalen Daten
wider. Obwohl alle Modalitäten das gleiche Konzept beschreiben, unterscheiden sie sich in der Menge an Informationen, die sich auf das Zielereignis oder Zielobjekt beziehen. Tiefe neuronale Netze, die auf dem Maximum-Likelihood-Lernziel basieren, weisen gierige Lerneigenschaften auf, was zu multimodalen Modellen führt, die häufig auf qualitativ hochwertigen Modalitäten mit hochdiskriminierenden Informationen basieren und leichter zu erlernen sind, während andere modale Informationen nur unzureichend modelliert werden.
Um diese Herausforderungen anzugehen und die Lernqualität multimodaler Modelle zu verbessern, hat die entsprechende Forschung zum „ausgewogenen multimodalen Lernen“ in letzter Zeit große Aufmerksamkeit erhalten. Je nach unterschiedlichem Gleichgewichtswinkel können verwandte Methoden in Methoden basierend auf charakteristischen Unterschieden und Methoden basierend auf Qualitätsunterschieden
(1) Weit verbreitete multimodale gemeinsame Trainingsrahmen ignorieren häufig die inhärenten Unterschiede in den Lerneigenschaften
von Einzelmodaldaten, was sich negativ auf die Leistung des Modells auswirken kann. Die auf charakteristischen Unterschieden basierende Methode geht von den Unterschieden in den Lerneigenschaften jeder Modalität aus und versucht, dieses Problem im Hinblick auf Lernziele, Optimierung und Architektur zu lösen.
(2) Neuere Untersuchungen haben außerdem ergeben, dass multimodale Modelle oft „stark auf bestimmte hochwertige Informationsmodalitäten angewiesen sind“, während andere Modalitäten ignoriert werden, was zu einem unzureichenden Lernen aller Modalitäten führt. Auf Qualitätsunterschieden basierende Methoden gehen von dieser Perspektive aus und versuchen, dieses Problem zu lösen und die ausgewogene Nutzung verschiedener Modalitäten in multimodalen Modellen aus den Perspektiven von Lernzielen, Optimierungsmethoden, Modellarchitektur und Datenanreicherung zu fördern. Tabelle 3. Klassifizierung ausgewogener multimodaler Datenfusionsmethoden Die Lernmethode zielt hauptsächlich auf die Heterogenität multimodaler Daten ab. Unterschiede in den Lerneigenschaften oder der Datenqualität zwischen verschiedenen Modalitäten. Diese Methoden schlagen Lösungen aus verschiedenen Perspektiven vor, z. B. Lernziele, Optimierungsmethoden, Modellarchitektur und Datenverbesserung. Ausgewogenes multimodales Lernen ist derzeit ein boomendes Feld, in dem viele Theorie- und Anwendungsrichtungen noch nicht vollständig erforscht sind. Derzeitige Methoden beschränken sich beispielsweise hauptsächlich auf typische multimodale Aufgaben, bei denen es sich hauptsächlich um diskriminierende Aufgaben und einige generative Aufgaben handelt. Darüber hinaus müssen multimodale große Modelle auch modale Daten mit unterschiedlichen Qualitäten kombinieren. Auf dieser Grundlage wird erwartet, dass bestehende Modelle in multimodalen großen Modellszenarien erweitert werden. Erforschen oder entwerfen Sie neue Lösungen.
Dynamische multimodale FusionsmethodeDynamische multimodale Daten
bezieht sich auf die Tatsache, dass die Qualität der Modalitäten mit den Eingabeproben variiert Szenarien Dynamische Veränderungen. In autonomen Fahrszenarien erhält das System beispielsweise Straßenoberflächen- und Zielinformationen über RGB- und Infrarotsensoren. Bei guten Lichtverhältnissen kann die RGB-Kamera die Entscheidungsfindung des intelligenten Systems besser unterstützen, da sie die satte Textur und Farbe erfassen kann Informationen zum Ziel; Nachts, wenn nicht genügend Licht vorhanden ist, sind die vom Infrarotsensor bereitgestellten Wahrnehmungsinformationen jedoch zuverlässiger. Die Kernaufgabe der dynamischen multimodalen Fusionsmethode besteht darin, das Modell in die Lage zu versetzen, die Qualitätsänderungen verschiedener Modalitäten automatisch wahrzunehmen, um eine genaue und stabile Fusion durchzuführen. Tabelle 4. Klassifizierung dynamischer multimodaler Fusionsmethoden
Dynamische multimodale Fusionsmethoden können grob in drei Kategorien unterteilt werden:
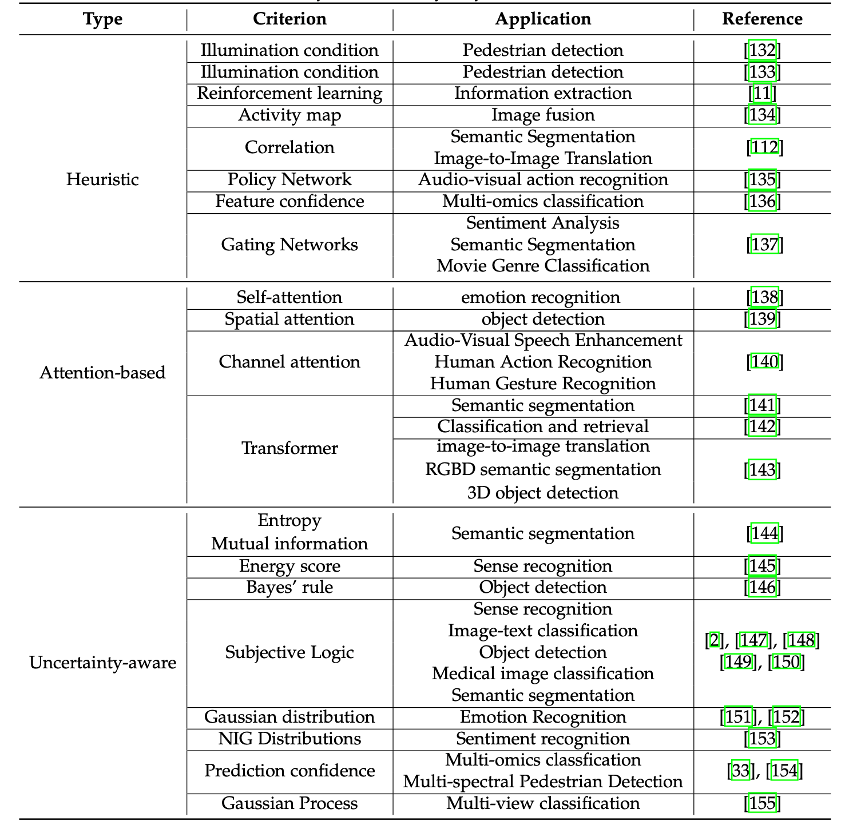
(1) Heuristische dynamische Fusionsmethode:
Die heuristische dynamische Fusion Die Methode basiert auf dem Verständnis des Algorithmusentwicklers für das Anwendungsszenario des multimodalen Modells und wird im Allgemeinen durch die Einführung eines gezielten „dynamischen Fusionsmechanismus“ erreicht. Zum Beispiel haben die Forscher in der multimodalen Zielerkennungsaufgabe der Zusammenarbeit zwischen RGB und thermischen Signalen heuristisch ein Beleuchtungswahrnehmungsmodul entworfen, um die Beleuchtungssituation des Eingabebildes dynamisch zu bewerten und die RGB- und Fusion-Gewichte dynamisch anzupassen thermischer Modalitäten zur Umweltanpassung. Bei hoher Helligkeit wird bei der Entscheidungsfindung hauptsächlich auf den RGB-Modus zurückgegriffen, und umgekehrt wird bei der Entscheidungsfindung hauptsächlich auf den Wärmemodus zurückgegriffen. (2) Dynamische Fusionsmethode basierend auf dem Aufmerksamkeitsmechanismus: Die dynamische Fusionsmethode basierend auf dem Aufmerksamkeitsmechanismus konzentriert sich hauptsächlich auf die Präsentationsschichtfusion. Der Aufmerksamkeitsmechanismus selbst weist dynamische Eigenschaften auf und kann daher natürlich in multimodalen dynamischen Fusionsaufgaben verwendet werden.
Selbstaufmerksamkeit, räumliche Aufmerksamkeit, Kanalaufmerksamkeit und Transformer sowie andere Mechanismen werden häufig bei der Konstruktion multimodaler Fusionsmodelle verwendet. Solche Methoden lernen automatisch, wie eine dynamische Fusion basierend auf Aufgabenzielen durchgeführt wird. Die auf dem Aufmerksamkeitsmechanismus basierende Fusion kann sich ohne explizite oder heuristische Anleitung bis zu einem gewissen Grad an dynamische multimodale Daten geringer Qualität anpassen. (3) Unsicherheitsbewusste dynamische Fusionsmethoden:
Unsicherheitsbewusste dynamische Fusionsmethoden haben oft
klarere und erklärbare Fusionsmechanismen. Anders als komplexe Fusionsmodi, die auf Aufmerksamkeitsmechanismen basieren, stützen sich unsicherheitsbewusste dynamische Fusionsmethoden auf Unsicherheitsschätzungen von Modalitäten (wie Evidenz, Energie, Entropie usw.), um sich an multimodale Daten geringer Qualität anzupassen.
Konkret kann die Unsicherheitswahrnehmung verwendet werden, um die Qualitätsänderungen jedes Modus der Eingabedaten zu charakterisieren. Wenn die Qualität einer bestimmten Modalität der Eingabestichprobe abnimmt, steigt die Unsicherheit der Entscheidungsfindung des Modells auf der Grundlage dieser Modalität, was eine klare Orientierung für den nachfolgenden Entwurf des Fusionsmechanismus bietet. Darüber hinaus können unsichere dynamische Fusionsmethoden im Vergleich zu Heuristiken und Aufmerksamkeitsmechanismen gute theoretische Garantien bieten.Obwohl die Überlegenheit unsicherheitsbewusster dynamischer Fusionsmethoden bei traditionellen multimodalen Fusionsaufgaben experimentell und theoretisch nachgewiesen wurde, ist dies in den multimodalen Modellen von SOTA (nicht) der Fall Dynamische Ideen sind zwar auf Fusionsmodelle wie CLIP/BLIP usw. beschränkt, haben aber auch großes Potenzial für die Erforschung und Anwendung. Darüber hinaus sind dynamische Fusionsmechanismen mit theoretischen Garantien oft auf die Entscheidungsebene beschränkt, es lohnt sich auch, darüber nachzudenken und sie zu erforschen. Das obige ist der detaillierte Inhalt vonMultimodale Datenfusion von geringer Qualität, mehrere Institutionen veröffentlichten gemeinsam ein Übersichtspapier. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

 Technologie-Peripheriegeräte
Technologie-Peripheriegeräte



 (2) Dynamische Fusionsmethode basierend auf dem Aufmerksamkeitsmechanismus:
(2) Dynamische Fusionsmethode basierend auf dem Aufmerksamkeitsmechanismus: 











 1379
1379
 52
52

 Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
Hadidb: Eine leichte, horizontal skalierbare Datenbank in Python
Apr 08, 2025 pm 06:12 PM
 Überwachen Sie MySQL und Mariadb -Tröpfchen mit Prometheus Mysql Exporteur
Apr 08, 2025 pm 02:42 PM
Überwachen Sie MySQL und Mariadb -Tröpfchen mit Prometheus Mysql Exporteur
Apr 08, 2025 pm 02:42 PM
 Git vs. GitHub: Versionskontrolle und Code -Hosting
Apr 11, 2025 am 11:33 AM
Git vs. GitHub: Versionskontrolle und Code -Hosting
Apr 11, 2025 am 11:33 AM
 So verwenden Sie das SQL Round -Feld
Apr 09, 2025 pm 06:06 PM
So verwenden Sie das SQL Round -Feld
Apr 09, 2025 pm 06:06 PM
 Kennwortrichtlinie Verstärkung und regelmäßige Implementierung von Skriptersatz
Apr 08, 2025 am 10:06 AM
Kennwortrichtlinie Verstärkung und regelmäßige Implementierung von Skriptersatz
Apr 08, 2025 am 10:06 AM
 Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
Überwachen Sie Redis Tröpfchen mit Redis Exporteur Service
Apr 10, 2025 pm 01:36 PM
 Was ist Git in einfachen Worten?
Apr 09, 2025 am 12:12 AM
Was ist Git in einfachen Worten?
Apr 09, 2025 am 12:12 AM
 So lesen Sie Redis Version Update History
Apr 10, 2025 pm 01:18 PM
So lesen Sie Redis Version Update History
Apr 10, 2025 pm 01:18 PM
