

In diesem Jahr wurden insgesamt 5 herausragende Paper Awards und 11 ehrenvolle Erwähnungen ausgewählt.
ICLR steht für International Conference on Learning Representations. Dieses Jahr findet die 12. Konferenz vom 7. bis 11. Mai in Wien, Österreich, statt.
In der Machine-Learning-Community ist die ICLR eine relativ „junge“ akademische Spitzenkonferenz. Sie wird von den Deep-Learning-Giganten und Turing-Award-Gewinnern Yoshua Bengio und Yann LeCun veranstaltet. Ihre erste Sitzung fand erst 2013 statt. Die ICLR erlangte jedoch schnell große Anerkennung bei akademischen Forschern und gilt als die führende akademische Konferenz zum Thema Deep Learning.
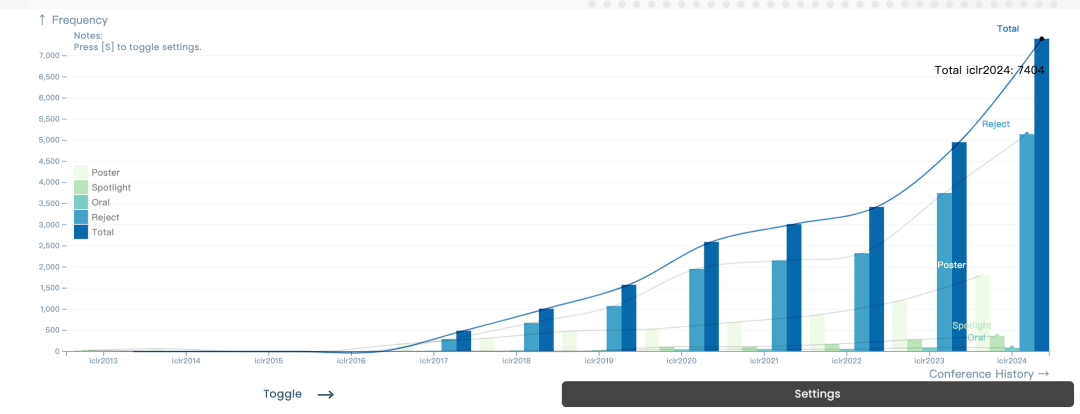
Bei dieser Konferenz wurden insgesamt 7262 Beiträge eingereicht und 2260 Beiträge angenommen. Die Gesamtannahmequote lag bei etwa 31 %, wie im letzten Jahr (31,8 %). Darüber hinaus liegt der Anteil der Spotlights-Beiträge bei 5 % und der Anteil der Oral-Beiträge bei 1,2 %.


Im Vergleich zu den Vorjahren ist die Beliebtheit von ICLR sowohl hinsichtlich der Teilnehmerzahl als auch der Anzahl der Papiereinreichungen deutlich gestiegen. R Für die vorherigen ICLR-Dissertationsdaten
Institution: New York University, Collège de France
Autor: Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane MallatDieser Artikel verallgemeinert das Bilddiffusionsmodell und ist wichtig eingehende Analyse des Gedächtnisses. Die Autoren untersuchen empirisch, wann ein Bilderzeugungsmodell vom Speichereingabemodus in den Generalisierungsmodus wechselt, und verbinden dies mit der Idee der harmonischen Analyse durch geometrisch adaptive harmonische Darstellung, wodurch dieses Phänomen aus der Perspektive der architektonischen Induktionsverzerrung weiter erklärt wird. Dieser Artikel behandelt einen wichtigen, fehlenden Teil unseres Verständnisses generativer Sehmodelle und hat große Auswirkungen auf die zukünftige Forschung.
Papier: Lernen interaktiver realer Simulatoren

UniSim
ist ein wichtiger Schritt in diese Richtung und eine technische Meisterleistung, da es eine einheitliche Schnittstelle nutzt, die auf textuellen Beschreibungen der visuellen Wahrnehmung und Kontrolle basiert, um Daten zu aggregieren und die neuesten Fortschritte in den Bereichen Vision und Sprache zu nutzen. Entwickelt, um Robotersimulatoren zu trainieren .Zusammenfassend untersucht dieser Artikel UniSim, einen Allzwecksimulator zum Erlernen realer Interaktionen durch generative Modelle, und unternimmt den ersten Schritt zum Aufbau eines Allzwecksimulators. UniSim kann beispielsweise simulieren, wie Menschen und Agenten mit der Welt interagieren, indem es Anweisungen auf hoher Ebene wie „Öffne eine Schublade“ und die visuellen Ergebnisse von Anweisungen auf niedriger Ebene simuliert.
Dieses Papier kombiniert große Datenmengen (einschließlich Internet-Text-Bild-Paare, umfangreiche Daten aus Navigation, menschlichen Aktivitäten, Roboteraktionen usw. sowie Daten aus Simulationen und Renderings) in einem bedingten Videogenerierungsrahmen. Durch die sorgfältige Orchestrierung umfangreicher Daten entlang verschiedener Achsen zeigt dieses Papier, dass UniSim erfolgreich Erfahrungen aus verschiedenen Datenachsen zusammenführen und über die Daten hinaus verallgemeinern kann, um durch eine feinkörnige Bewegungssteuerung statischer Szenen und Objekte umfassende Interaktionen zu ermöglichen.Wie in Abbildung 3 unten gezeigt, kann UniSim eine Reihe umfangreicher Aktionen simulieren, wie z. B. das Händewaschen, das Nehmen von Schüsseln, das Schneiden von Karotten und das Trocknen der Hände in einer Küchenszene Abbildung 3 zeigt zwei Navigationsszenen.右 Entspricht dem Navigationsszenario unten rechts oben in Abbildung 3

Das Navigationsszenario unten rechts oben in Abbildung 3

These: NIEMALS von Grund auf trainieren: Fairer Vergleich von Langsequenzen Modelle erfordern datengesteuerte Prioritäten
Papieradresse: https://openreview.net/forum?id=PdaPky8MUn

Papieradresse: https://openreview.net/forum?id=zMPHKOmQNb

Aufsatz: Amortizing intractable inference in large language models

Institution: DeepMind
Autor: Ian Gemp, Luke Marris, Georgios Piliouras
Papieradresse: https://open review .net/forum?id=cc8h3I3V4E
Dies ist ein sehr klar geschriebenes Papier, das wesentlich zum wichtigen Problem der Entwicklung effizienter und skalierbarer Nash-Löser beiträgt.
Artikel: Beyond Weisfeiler-Lehman: A Quantitative Framework for GNN Expressiveness
Institution: Peking University, Beijing Zhiyuan Artificial Intelligence Research Institute
Autor: Zhang Bohang Gai Jingchu Du Yiheng Ye Qiwei Hedi Wang Liwei
Papieradresse: https://openreview.net/forum?id=HSKaGOi7Ar
Die Ausdrucksfähigkeit von GNN ist ein wichtiges Thema, und aktuelle Lösungen weisen immer noch große Einschränkungen auf. Der Autor schlägt eine neue Expressivitätstheorie vor, die auf homomorphem Zählen basiert.
Artikel: Flow Matching on General Geometries
Institution: Meta
Autor: Ricky T. Q. Chen, Yaron Lipman
Papieradresse: https://openreview.net/forum?id=g7ohDlTITL
Dieser Artikel untersucht das herausfordernde, aber wichtige Problem der generativen Modellierung auf allgemeinen geometrischen Mannigfaltigkeiten und schlägt einen praktischen und effizienten Algorithmus vor. Die Arbeit ist hervorragend präsentiert und für ein breites Aufgabenspektrum vollständig experimentell validiert.
Artikel: Ist ImageNet 1 Video wert? Starke Bild-Encoder aus 1 langen, unbeschrifteten Video lernen
Institutionen: University of Central Florida, Google DeepMind, University of Amsterdam usw.
Autoren: Shashanka Venkataramanan, Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis
Papieradresse: https://openreview.net/forum?id=Yen1lGns2o
Dieses Papier schlägt eine neuartige selbstüberwachte Bild-Vortrainingsmethode vor , also durch Training aus kontinuierlichen Lernvideos. Dieses Papier stellt sowohl einen neuen Datentyp als auch eine Methode zum Lernen aus neuen Daten vor.
Artikel: Meta Continual Learning Revisited: Implicitly Enhancing Online Hessian Approximation via Variance Reduction
Institution: City University of Hong Kong, Tencent AI Lab, Xi'an Jiaotong University usw.
Autor: Yichen Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng und Ying Wei Reduktionsmethode. Die Methode funktioniert gut und hat nicht nur praktische Auswirkungen, sondern wird auch durch eine Bedauernsanalyse unterstützt.
Institution: University of Illinois at Urbana-Champaign, Microsoft
Autoren: Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao
Papieradresse: https://openreview.net/forum?id=uNrFpDPMyo
Dieser Artikel konzentriert sich auf das KV-Cache-Komprimierungsproblem (dieses Problem hat große Auswirkungen auf Transformer- basiertes LLM), mit einer einfachen Idee, die den Speicher reduziert und ohne teure Feinabstimmung oder Umschulung bereitgestellt werden kann. Diese Methode ist sehr einfach und hat sich als sehr effektiv erwiesen.
Institution: Stanford University, Columbia University
Autor: Yonatan Oren, Nicole Meister, Niladri S. Chatterji, Faisal Ladhak, Tatsunori Hashimoto
Papieradresse: https://openreview.net/forum?id=KS8mIvetg2
Dieses Papier verwendet eine einfache und elegante Methode, um zu testen, ob überwachte Lerndatensätze in große Sprachmodelle im Training einbezogen wurden.
Institution: Google DeepMind
Autor: Jonathan Richens, Tom Everitt
Papieradresse: https://openreview.net/forum?id= pOoKI3ouv1
Dieser Artikel macht große Fortschritte bei der Schaffung der theoretischen Grundlage für das Verständnis der Rolle des kausalen Denkens bei der Fähigkeit eines Agenten, auf neue Domänen zu verallgemeinern, mit Auswirkungen auf eine Reihe verwandter Bereiche.
Institution: Princeton University, Harvard University usw.
Autor: Gautam Reddy
Papieradresse : https://openreview.net/forum?id=aN4Jf6Cx69
Dies ist eine zeitgemäße und äußerst systematische Studie, die die Beziehung zwischen kontextbezogenem Lernen und gewichtsbezogenem Lernen untersucht, während wir beginnen, diese Phänomene zu verstehen.
Institution: Granica Computing
Autor: Germain Kolossov, Andrea Montanari, Pulkit Tandon
Aufsatzadresse: https://openreview .net/forum?id=HhfcNgQn6p
Dieses Papier legt eine statistische Grundlage für die Auswahl von Datenteilmengen fest und identifiziert die Mängel gängiger Datenauswahlmethoden.
Referenzlink: https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/
Das obige ist der detaillierte Inhalt von7262 Beiträge wurden eingereicht, ICLR 2024 wurde ein Hit und zwei inländische Beiträge wurden für herausragende Beiträge nominiert.. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



