
 Technologie-Peripheriegeräte
KI
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
Technologie-Peripheriegeräte
KI
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform
Anwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform


1. Der Hintergrund des Baus der 58-Porträt-Plattform
Lassen Sie mich zunächst den Hintergrund des Baus der 58-Porträt-Plattform mit Ihnen teilen.
1. Herkömmliche Profiling-Plattform
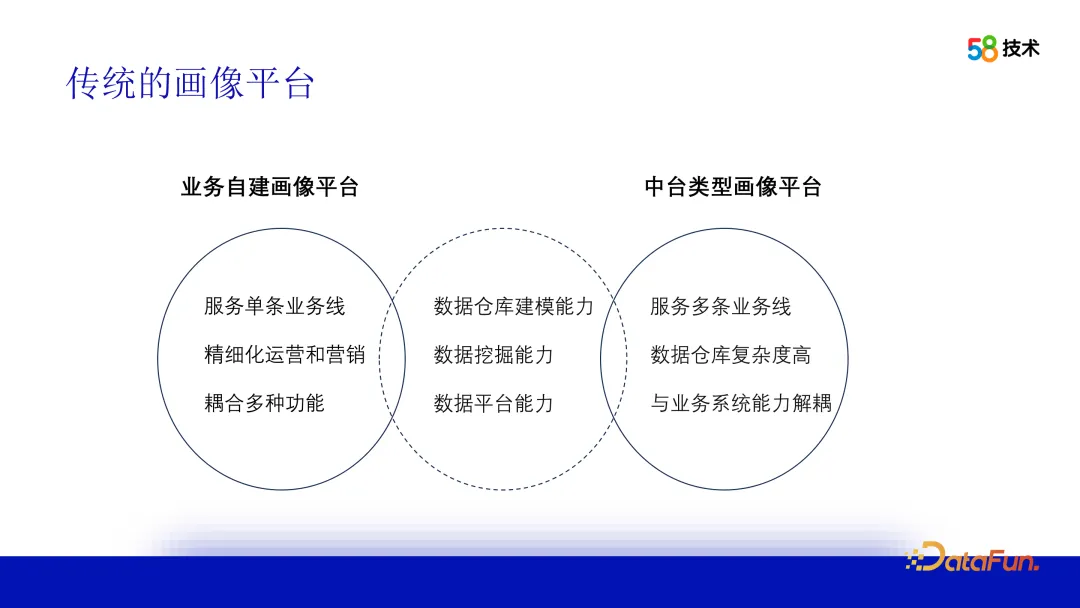
Der Aufbau einer Benutzer-Profiling-Plattform reicht nicht mehr aus, indem er auf Data-Warehouse-Modellierungsfunktionen, die Integration mehrzeiliger Daten und die Erstellung genauer Benutzerporträts setzt Außerdem ist es erforderlich, das Benutzerverhalten, die Interessen und Bedürfnisse zu verstehen und algorithmische Funktionen bereitzustellen. Schließlich muss es auch über Datenplattformfunktionen verfügen, um Benutzerporträtdaten effizient zu speichern, abzufragen und zu teilen sowie Porträtdienste bereitzustellen. Der Hauptunterschied zwischen einer selbst erstellten Business-Profiling-Plattform und einer Middle-Office-Profiling-Plattform besteht darin, dass die selbst erstellte Profiling-Plattform einen einzelnen Geschäftsbereich bedient und bei Bedarf angepasst werden kann. Die Mid-Office-Plattform bedient mehrere Geschäftsbereiche und ist komplex Modellierung und bietet allgemeinere Funktionen.
2. 58 Der Hintergrund des Aufbaus des mittleren Plattformporträts

58 Der Aufbau der Benutzerporträtplattform ist hauptsächlich auf die folgenden Geschäftsanforderungen zurückzuführen:
- Personalisierte Empfehlung: Die Geschäftsseite muss erstellen Tausende von Menschen basierend auf Benutzerporträts. Tausende Aspekte der Inhaltsverteilung.
- Verfeinerter Betrieb: Für den Produktbetrieb muss die Porträtplattform Funktionen wie Crowd Insight und Crowd Selection bereitstellen, um verfeinerte Betriebsaktivitäten für verschiedene Personengruppen durchzuführen.
- Nutzerwertsteigerung: Es ist dringend erforderlich, die Porträtplattform zu nutzen, um den Wert bestehender Nutzer zu steigern. 3. Vientiane Nutzen Sie den OneID-Dienst, um grundlegende Benutzerporträtdaten zu erstellen, Traffic- und Crowd-Einblicke zu kombinieren, Algorithmen zur intelligenten Generierung von Crowds zu verwenden und Materialien für präzises Marketing abzugleichen. Überwachen Sie gleichzeitig die Wirkung und recyceln Sie Daten, um die Strategie zu optimieren und die Menge zu iterieren. Bieten Sie Geschäftspartnern intelligente Wachstumslösungen, um präzise Abläufe und Geschäftswachstum zu erreichen. 2. Die Rolle des Algorithmus beim Aufbau der 58-Porträt-Plattform EtikettensystemDas andere ist der Aufbau von Plattformfunktionen.
1. Aufbau des Tag-Systems
Das Vientiane-Tag-System umfasst mehrere Kategorien wie soziale Attribute, geografische Lage, Verhaltensgewohnheiten, Präferenzattribute, Benutzerschichtung usw. mit insgesamt mehr als 1.500 Tags. Wir unterteilen sie entsprechend der Produktionsmethode in zwei Typen: 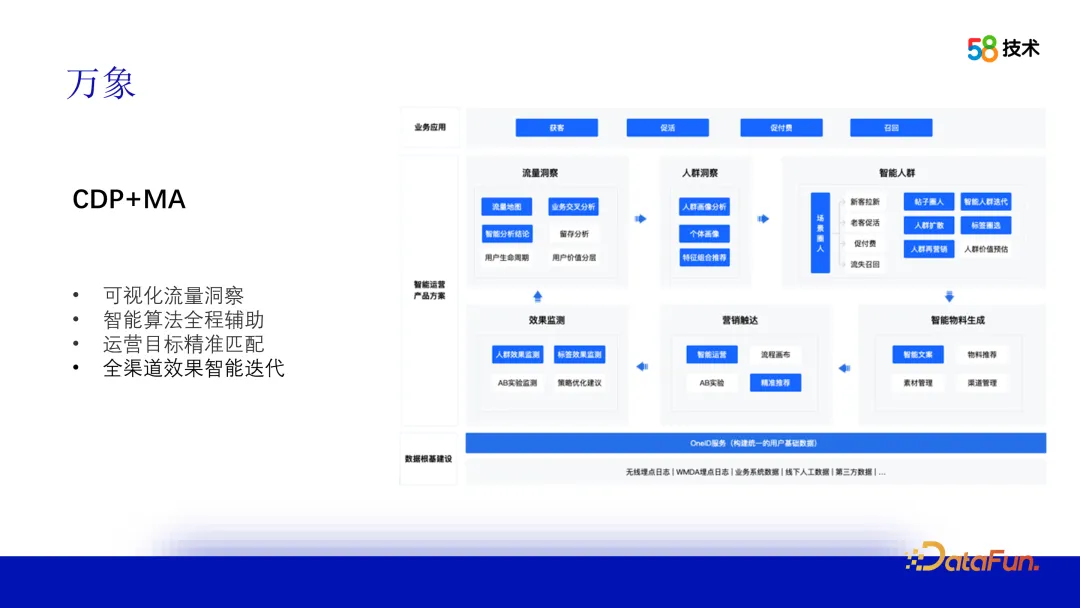
Fakten-Tags: Shucang-Schüler verwenden Statistiken oder Regeln, um mithilfe von SQL usw. zu entwickeln und zu produzieren. Algorithmus-Tags: Das Algorithmus-Team verarbeitet und produziert durch Data Mining und andere Mittel.
2. Beispiele für Algorithmus-Tags
Algorithmus-Tags können nach Datenquelle und Granularität klassifiziert werden. Beispielsweise handelt es sich bei der Datenquelle für Labels wie Geschlecht, Alter und Geschäftstrends im Allgemeinen um strukturierte Daten, die häufig als Klassifizierungsaufgabe verarbeitet werden. Die Modelle können XGBoost, DeepFM usw. sein. Es gibt auch Mietzweck-Tags, die den Zweck des Benutzers anhand des Textes der Beiträge identifizieren müssen, die der Benutzer durchsucht. Die Datenquelle dieses Tag-Typs sind unstrukturierte Daten, die mithilfe von Textklassifizierung und anderen Methoden verarbeitet werden können. Wenn Benutzer in unseren Inhaltspräferenz-Tags TopN-Beiträge in verschiedenen Unternehmen bevorzugen, müssen wir einen Offline-Empfehlungsprozess aufbauen, um solche Tags zu erstellen.
 3. Nehmen Sie das Inhaltspräferenz-Tag als Beispiel, um den Kennzeichnungsprozess zu erklären
3. Nehmen Sie das Inhaltspräferenz-Tag als Beispiel, um den Kennzeichnungsprozess zu erklären
Nehmen Sie das Inhaltspräferenz-Tag als Beispiel. Um dieses Tag zu erstellen, muss ein Offline-Empfehlungsprozess eingerichtet werden. Angesichts von Millionen oder mehr Beiträgen führen wir zunächst eine vorläufige Überprüfung in der Rückrufphase durch und verwenden dabei beliebte, regelbasierte, kollaborative Filterung und andere Methoden, wie das Convolutional Neural Network (LightGCN) und das Twin Towers (DSSM)-Modell in der Abbildung. Basierend auf den zurückgerufenen Beiträgen wird dann der Pointwise-Ansatz verwendet, um das CTR-Modell zu sortieren. Die endgültige Ausgabe sind die Top-N-Beiträge, an denen Benutzer am meisten interessiert sind. In praktischen Anwendungen können am Beispiel des Push-Szenarios Schlüsselattribute aus den Top-1-Beiträgen extrahiert werden, um personalisierte Texte zu generieren. Gleichzeitig kann die Landingpage die Detailseite des Top-1-Beitrags oder die Listenseite der Top-N-Beiträge sein.

Bei der Erstellung von Inhaltspräferenz-Tags unter Berücksichtigung der geografischen und Kategoriemerkmale des lokalen Unternehmens von 58 sind Benutzer in der Regel nur an Beiträgen aus bestimmten Regionen oder Kategorien in Empfehlungen interessiert. Daher kann es bei der Vektorisierung des Rückrufs (z. B. mithilfe des EGES-Modells) zu einer großen Anzahl von Posts außerhalb der Website oder außerhalb der Kategorie kommen. Um dieses Problem zu lösen, stellen wir die Stadtinformationen hexadezimal dar, ersetzen 0 durch -1 und fügen diese Codierung dann direkt in den zuvor generierten Vektor ein. Dadurch kann sichergestellt werden, dass Beiträge in derselben Stadt oder für denselben Zweck in die Ähnlichkeit einbezogen werden Die Berechnungen weisen die größte Ähnlichkeit auf und verbessern so die Genauigkeit des Rückrufs und der Empfehlung.
In der Sortierphase werden multimodale Informationen, einschließlich Textinhalte, verwendet, um die Genauigkeit von Empfehlungen zu verbessern. Beispielsweise kann der Beitragstitel als Textmerkmal durch Einbettung mithilfe vorab trainierter Modelle wie BERT und M3E dargestellt werden. Aufgrund der großen Anzahl an Beiträgen stellt dies jedoch eine Herausforderung für die Rechenressourcen dar. Um dieses Problem zu lösen, verwenden wir Spark NLP, eine Bibliothek zur Verarbeitung natürlicher Sprache, die auf Apache Spark Machine Learning basiert. Obwohl es in der nativen Bibliothek kein chinesisches BERT-Modell gibt, haben wir es durch einige Transformationen erfolgreich auf groß angelegte Offline-Inferenzen angewendet.
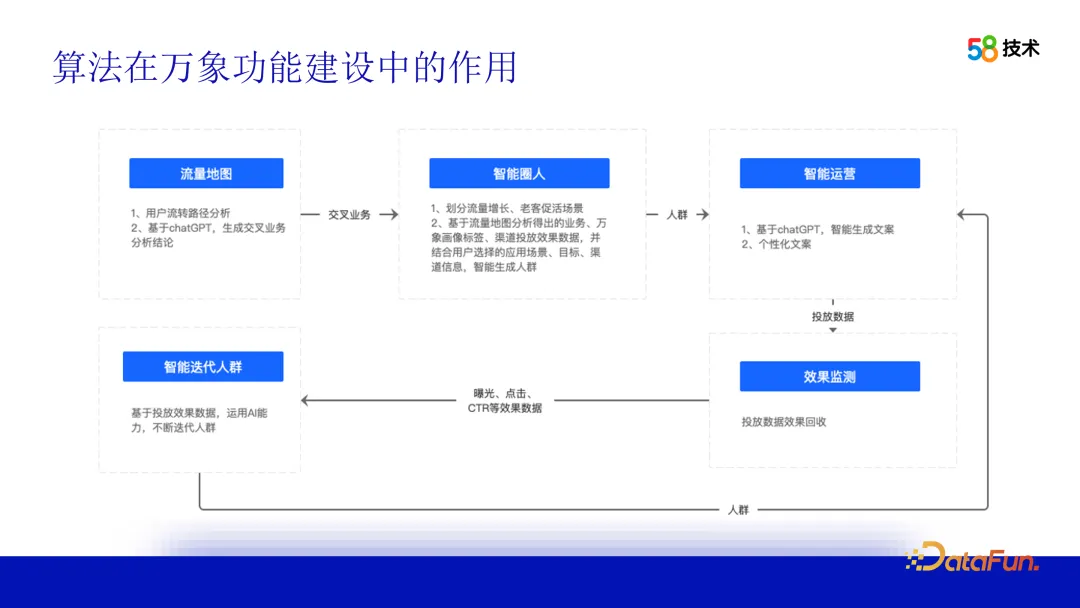
Algorithmen spielen auch eine zentrale Rolle beim funktionalen Aufbau der 58-Städte-Benutzerporträtplattform. Am Beispiel intelligenter Betriebsfunktionen verwenden wir Verkehrskarten, um Korrelationen zwischen verschiedenen Unternehmen zu identifizieren und Betriebsvorschläge oder Schlussfolgerungen für Geschäftsparteien bereitzustellen. Basierend auf diesen Vorschlägen kann die Geschäftsseite über die intelligente Kreisfunktion direkt ein Operator-Crowd-Paket generieren und es mit den entsprechenden Kanälen zur Auslieferung verbinden. Der Liefereffekt kann über die Plattform überwacht und auf Basis der Effektdaten iterativ optimiert werden, um die betrieblichen Effekte kontinuierlich zu verbessern.
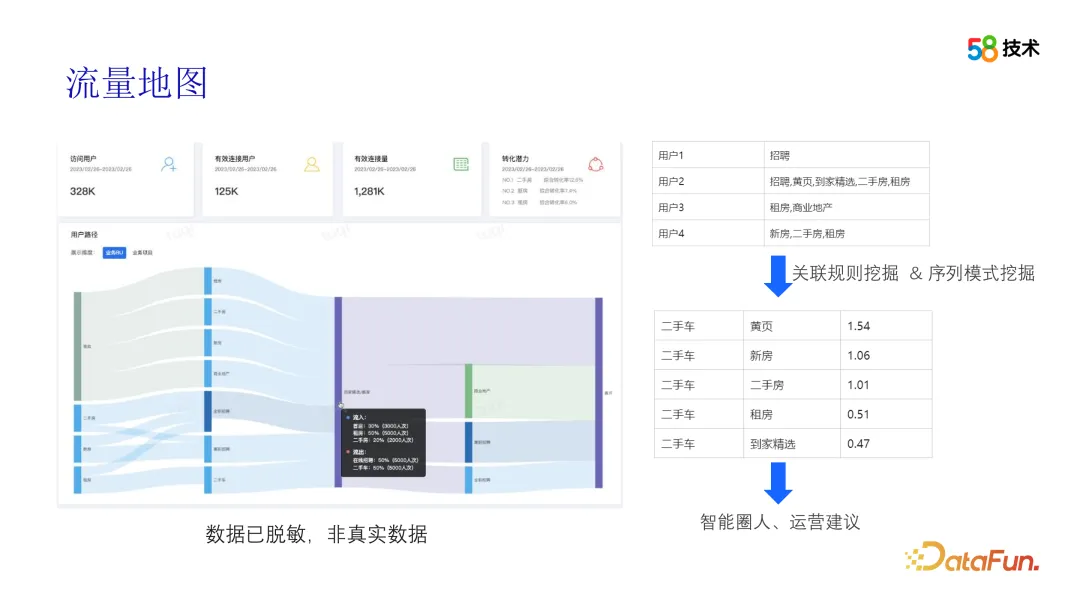
Wie funktioniert der Algorithmus? Als nächstes werden wir es in mehreren Teilen vorstellen. Die erste ist die Verkehrskarte. Wir nutzen die OLAP-Data-Mining- und Datenvisualisierungstechnologie, um eine detaillierte Analyse des Surfverhaltens von 58APP-Benutzern zwischen verschiedenen Unternehmen durchzuführen. Durch die Analyse und Verarbeitung dieser Daten können die Flusspfade der Benutzer zwischen verschiedenen Unternehmen angezeigt werden, wodurch das Betriebsteam einen intuitiven Überblick über das Benutzerverhalten erhält. Dabei können uns Algorithmen nicht nur dabei helfen, Benutzerverhaltensmuster zu erkennen, sondern auch Korrelationen zwischen verschiedenen Unternehmen durch Korrelationsanalysen und andere Technologien zu ermitteln. Diese Zusammenhänge liefern uns wertvolle operative Anregungen und unterstützen das Operations-Team bei übergreifenden Einsätzen.
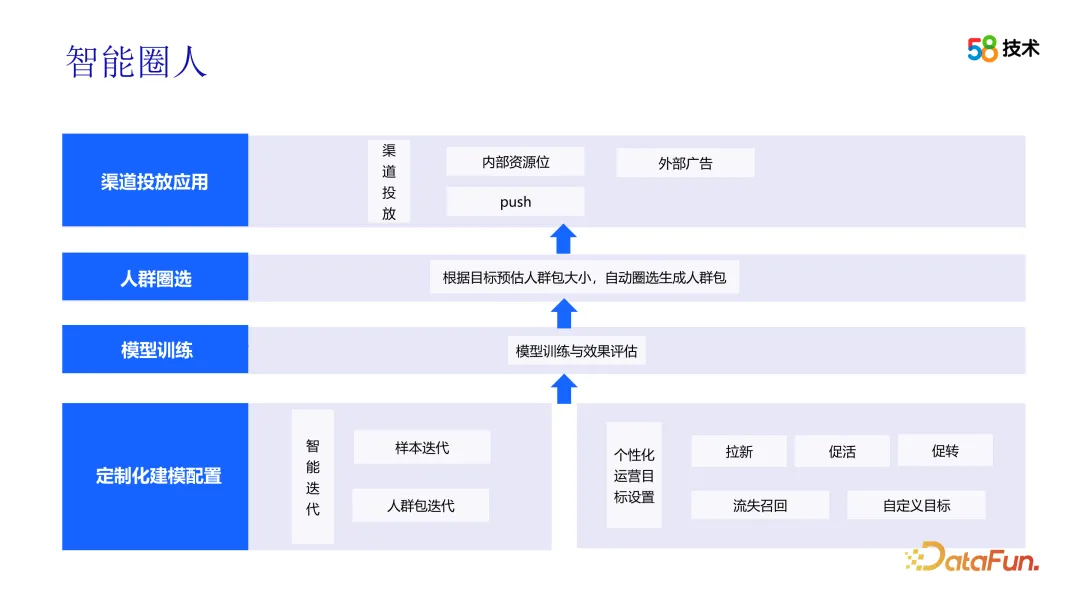
Nach Erhalt der Operationsvorschläge kann das Operationsteam mithilfe der intelligenten Kreisfunktion die Zielgruppe auswählen. Um dieses Ziel zu erreichen, muss das Betriebsteam zunächst personalisierte Betriebsziele konfigurieren und klären, ob das Ziel darin besteht, neue Kunden zu gewinnen, Aktivitäten zu fördern oder Conversions zu fördern usw. Als nächstes müssen Sie den gewünschten Effekt festlegen, einschließlich der Größe des Crowd-Pakets und des erwarteten Liefereffekts. Darüber hinaus muss das Betriebsteam auch geeignete Bereitstellungskanäle auswählen, um sicherzustellen, dass die Zielgruppe relevante Informationen zu den betrieblichen Aktivitäten erhalten kann.
Der Prozess der Generierung von Crowd-Paketen ist eine Blackbox für das Betriebsteam. Um dieses Problem anzugehen, stellen wir weitere Erklärungen und Beschreibungen der Algorithmusprinzipien und -schritte bereit, damit Betriebsteams die Technologie besser verstehen und anwenden können. Gleichzeitig stellen wir mehr visuelle Tools und Schnittstellen bereit, die dem Betriebsteam helfen, die Eigenschaften und Auswirkungen von Crowd-Paketen intuitiv zu erkennen und zu analysieren.
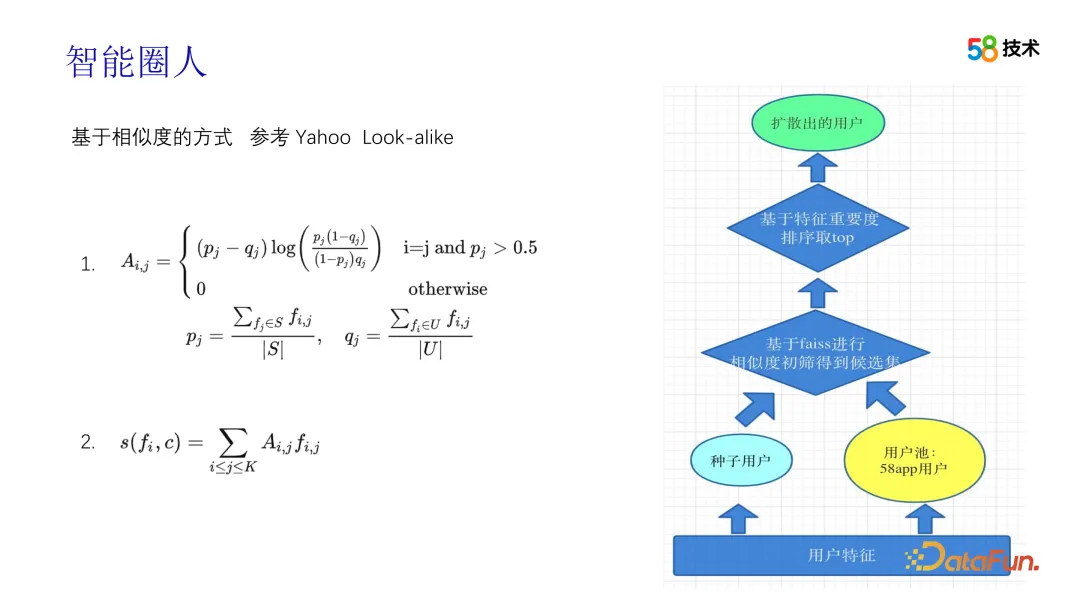
Bei der Generierung von Crowd-Paketen verwenden wir hauptsächlich die Look-alike-Technologie. Wir haben in der Entwicklung dieser Technologie mehrere Phasen durchlaufen. In der Anfangsphase haben wir von der Lösung von Yahoo gelernt und die Ausgabe des Crowd-Pakets in Rückruf- und Sortiermodule unterteilt. Das Rückrufmodul erstellt zunächst die Merkmalsvektoren aller Benutzer, verwendet dann MinHash und die lokal sensible Hashing-Technologie, um die Merkmalsvektoren zu komprimieren, und erreicht durch eine dem Clustering und Bucketing ähnliche Methode einen k-NN-ähnlichen Abruf und berechnet schnell die Beziehung zwischen den Startwerten Benutzer und Basierend auf der paarweisen Ähnlichkeit zwischen den Kandidatengruppen wird topN als Rückrufgruppe für jeden Seed-Benutzer ausgewählt. In der Sortierphase wird der Informationswert zunächst zum Filtern von Merkmalen verwendet, dann werden die Bewertungen basierend auf den gefilterten Merkmalen berechnet und schließlich werden die Bewertungen sortiert, um schließlich ein Crowd-Paket zu erstellen. Während des gesamten Prozesses spielte der Algorithmus eine Schlüsselrolle bei der Sicherstellung der Genauigkeit und Wirksamkeit des Crowd-Pakets.
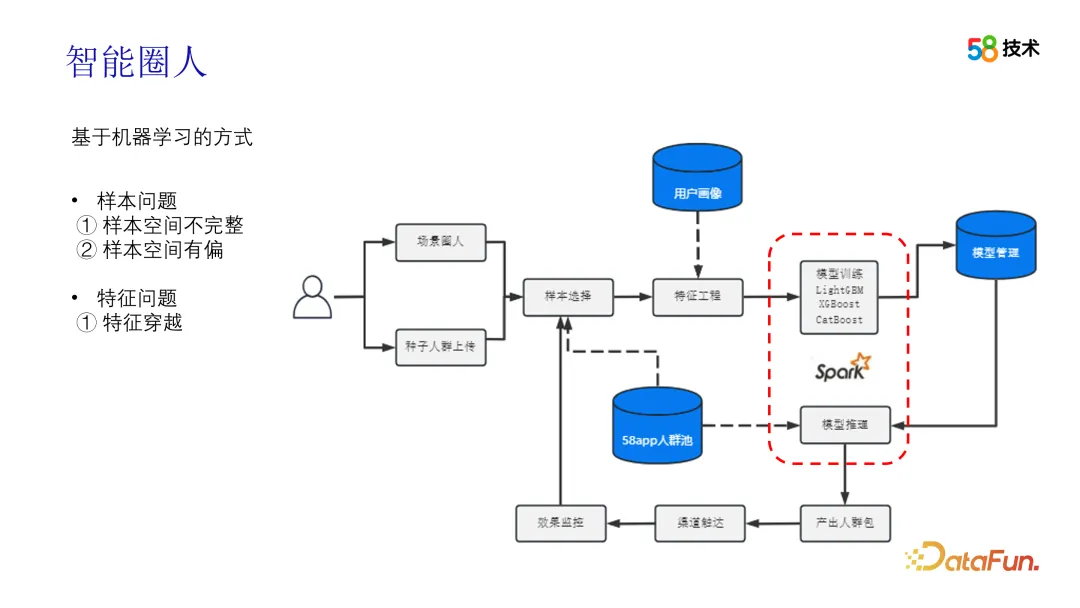
Neben ähnlichkeitsbasierten Lösungen erzielen auch auf maschinellem Lernen basierende Methoden gute Ergebnisse. In praktischen Anwendungen können Benutzer Anfragen über Personen aus Szenenkreisen oder durch Hochladen von Seed-Crowds initiieren. Der Unterschied besteht darin, ob die Seed-Crowd von Benutzern hochgeladen oder automatisch von uns abgebaut wird. Nachdem wir die Samenpopulation, also die positiven Proben, erhalten haben, müssen wir negative Proben auswählen. Wir können eine gewalttätige globale zufällige negative Stichprobe verwenden oder Algorithmen wie PU-Lernen oder TSA verwenden, um die Auswahl negativer Proben abzuschließen. Als nächstes folgt die Feature-Auswahlphase, die in zwei Optionen unterteilt ist: Nach dem Engineering mit festen Features können Modelle wie DeepFM zum Abschließen des Trainings und der CTR-Schätzung verwendet werden, und TopN wird ausgewählt Das auf CTR basierende Crowd-Paket besteht darin, alle Tags als Features zu verwenden, Features automatisch über IV-Werte und Korrelationen auszuwählen und zu eliminieren, dann das AutoML-Framework zu verwenden, um das Feature-Engineering und das Modelltraining abzuschließen und schließlich eine Inferenz auf der 58App durchzuführen Crowd-Pool und Ausgabe basierend auf dem TopN-Crowd-Paket, stellen Sie eine Verbindung zum Kanal her, um Kontakt aufzunehmen, und sammeln Sie schließlich die Liefereffektdaten, um die Iteration der Stichprobenauswahl abzuschließen.
Im obigen Schema gibt es einige Punkte, die Aufmerksamkeit verdienen. Der erste ist die Iteration von Proben. Bei der Wiederherstellung von Effektdaten müssen nicht nur die Belichtungsdaten überprüft werden, sondern auch die unbelichteten Daten debias verarbeitet werden. Gleichzeitig muss der Effekt nach der Iteration offline bewertet und überprüft werden, um den Effekt der Iteration sicherzustellen. Darüber hinaus muss das Durchquerungsproblem auch im Hinblick auf Features berücksichtigt werden, insbesondere in der neuen Szene, wo der Zeitfaktor der Feature-Auswahl berücksichtigt werden muss.
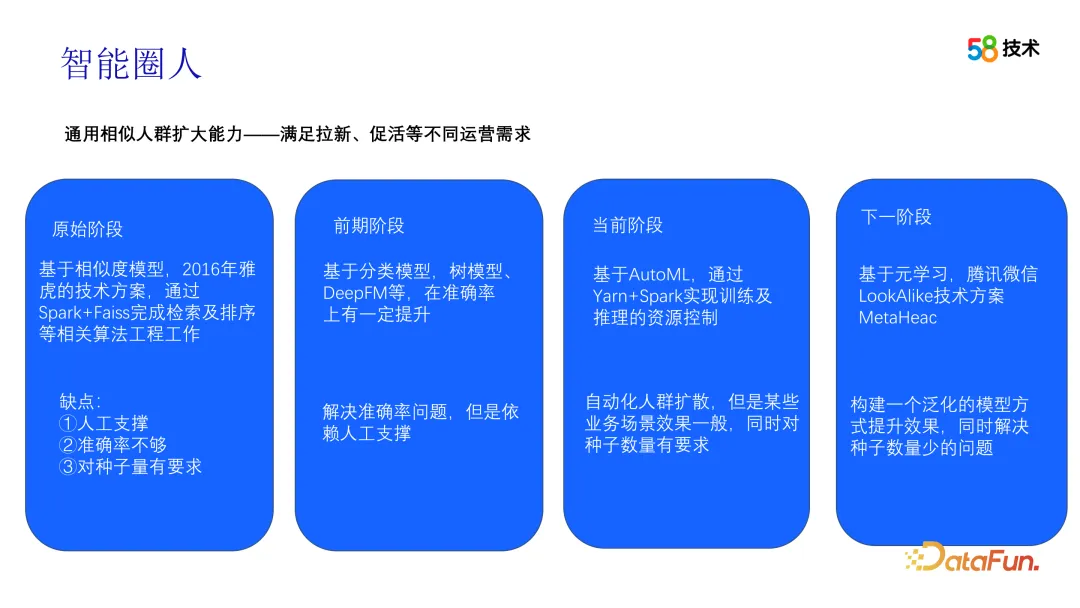
Da in Betriebsszenarien immer mehr Daten anfallen, beginnen wir zu versuchen, diese Daten für die Durchführung von Offline-Experimenten zur Optimierung unseres Iterationsplans zu verwenden. Eine davon ist die auf Tencent WeChat basierende Look-alike-Methode, die eine Meta-Lernmethode anwendet. Konkret erstellt diese Methode ein verallgemeinertes Modell, schließt die Modellkonstruktion in der Offline-Phase ab und verwendet dann eine kleine Menge an Datensätzen, um das angepasste Modell zu trainieren und Inferenzarbeiten in der Online-Phase durchzuführen. Diese Methode kann das Problem der Überanpassung des Modells lösen, wenn die Stichprobengröße relativ klein ist. Multi-Szenario- und Multi-Target-Crowd-Diffusion ist ebenfalls eine unserer nächsten Iterationsrichtungen. 3. Anwendungsfälle für die 58-Portrait-Plattform Alle nutzen die entsprechenden Funktionen der 58-Benutzer-Porträtplattform. Beispielsweise nutzt die Preisoperation die Etikettenauswahlfunktion der Porträtplattform, um Crowd-Pakete zu generieren und spezifische Inhalte für sie zu pushen, wodurch die Verfeinerung von Tausenden von Personen abgeschlossen wird.
2. Personalisierter Push Unsere Porträtplattform ist auch vollständig mit der Push-Plattform von 58 verbunden. Studenten können über die Vientiane-Kreisauswahl oder Lookalike Gruppen erstellen, personalisiertes Copywriting konfigurieren und sie über Push-Benutzer erreichen, um betriebliche Zwecke zu erreichen .
3. Suchempfehlung
Suchempfehlung ist die häufigste Anwendung basierend auf Benutzerporträts. 58 Die beiden Unternehmen für Neuwagen und Gebrauchtwagen verfügen nicht über Algorithmenpersonal, möchten aber auch einige personalisierte Anwendungen erstellen und haben daher auf die oben genannten Inhaltspräferenz-Tags zugegriffen. Der Inhaltspräferenz-TopN-Tag wird in Ressourcenbereichen wie Neuwagenempfehlungen und zugehörigen Empfehlungen auf der Homepage verwendet. In der Suchposition von Gebrauchtwagen wird diese Bezeichnung auch in den Eingabeaufforderungen des Suchfelds und der zugehörigen Autoserie auf der Sucherkennungsseite verwendet. Im Vergleich zur vorherigen Methode zur Verwendung von Regeln hat der Zugriff auf Inhaltspräferenz-Tags als Lösung in der frühen Phase des Projekts ebenfalls gute Ergebnisse erzielt.
4. Ausblick und Zusammenfassung
Die aktuelle Porträtplattform von 58 verfügt bereits über branchenübliche Porträtplattformfunktionen und hat durch den Segen des Algorithmus eine intelligente Bedienung und andere Fähigkeiten erreicht. Es verbessert nicht nur die betrieblichen Auswirkungen auf der Geschäftsseite, sondern bietet den Benutzern auch personalisierte Dienste und sorgt gleichzeitig für ein besseres Benutzererlebnis. Als nächstes werden wir intensiv mit den Geschäftsparteien zusammenarbeiten, um weitere Anwendungsszenarien zu erkunden, den Kooperationsprozess zusammenzufassen und zu verfeinern, zu optimieren und zu innovieren sowie die Technologie zu aktualisieren, um verschiedenen Anforderungen und Herausforderungen gerecht zu werden. Wir freuen uns darauf, bessere Lösungen für Benutzer und Unternehmen zu schaffen. Tolles Preis-Leistungs-Verhältnis.
Das obige ist der detaillierte Inhalt vonAnwendung von Algorithmen beim Aufbau einer 58-Porträt-Plattform. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 So setzen Sie das CGI -Verzeichnis in Apache
Apr 13, 2025 pm 01:18 PM
So setzen Sie das CGI -Verzeichnis in Apache
Apr 13, 2025 pm 01:18 PM
Um ein CGI-Verzeichnis in Apache einzurichten, müssen Sie die folgenden Schritte ausführen: Erstellen Sie ein CGI-Verzeichnis wie "CGI-bin" und geben Sie Apache-Schreibberechtigungen. Fügen Sie den Block "scriptalias" -Richtungsblock in die Apache-Konfigurationsdatei hinzu, um das CGI-Verzeichnis der URL "/cgi-bin" zuzuordnen. Starten Sie Apache neu.
 So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
So starten Sie Apache
Apr 13, 2025 pm 01:06 PM
Die Schritte zum Starten von Apache sind wie folgt: Installieren Sie Apache (Befehl: sudo apt-Get-Get-Installieren Sie Apache2 oder laden Sie ihn von der offiziellen Website herunter). (Optional, Linux: sudo systemctl
 So löschen Sie mehr als Servernamen von Apache
Apr 13, 2025 pm 01:09 PM
So löschen Sie mehr als Servernamen von Apache
Apr 13, 2025 pm 01:09 PM
Um eine zusätzliche Servername -Anweisung von Apache zu löschen, können Sie die folgenden Schritte ausführen: Identifizieren und löschen Sie die zusätzliche Servername -Richtlinie. Starten Sie Apache neu, damit die Änderungen wirksam werden. Überprüfen Sie die Konfigurationsdatei, um Änderungen zu überprüfen. Testen Sie den Server, um sicherzustellen, dass das Problem behoben ist.
 Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Was tun, wenn der Port Apache80 belegt ist
Apr 13, 2025 pm 01:24 PM
Wenn der Port -80 -Port der Apache 80 besetzt ist, lautet die Lösung wie folgt: Finden Sie den Prozess, der den Port einnimmt, und schließen Sie ihn. Überprüfen Sie die Firewall -Einstellungen, um sicherzustellen, dass Apache nicht blockiert ist. Wenn die obige Methode nicht funktioniert, konfigurieren Sie Apache bitte so, dass Sie einen anderen Port verwenden. Starten Sie den Apache -Dienst neu.
 So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
In diesem Artikel wird erläutert, wie die Leistung der Website verbessert wird, indem Apache -Protokolle im Debian -System analysiert werden. 1. Log -Analyse -Basics Apache Protokoll Datensätze Die detaillierten Informationen aller HTTP -Anforderungen, einschließlich IP -Adresse, Zeitstempel, URL, HTTP -Methode und Antwortcode. In Debian -Systemen befinden sich diese Protokolle normalerweise in /var/log/apache2/access.log und /var/log/apache2/error.log verzeichnis. Das Verständnis der Protokollstruktur ist der erste Schritt in der effektiven Analyse. 2. Tool mit Protokollanalyse Mit einer Vielzahl von Tools können Apache -Protokolle analysiert: Befehlszeilen -Tools: GREP, AWK, SED und andere Befehlszeilen -Tools.
 Wie Debian die Hadoop -Datenverarbeitungsgeschwindigkeit verbessert
Apr 13, 2025 am 11:54 AM
Wie Debian die Hadoop -Datenverarbeitungsgeschwindigkeit verbessert
Apr 13, 2025 am 11:54 AM
In diesem Artikel wird erläutert, wie die Effizienz der Hadoop -Datenverarbeitung auf Debian -Systemen verbessert werden kann. Optimierungsstrategien decken Hardware -Upgrades, Parameteranpassungen des Betriebssystems, Änderungen der Hadoop -Konfiguration und die Verwendung effizienter Algorithmen und Tools ab. 1. Hardware -Ressourcenverstärkung stellt sicher, dass alle Knoten konsistente Hardwarekonfigurationen aufweisen, insbesondere die Aufmerksamkeit auf die Leistung von CPU-, Speicher- und Netzwerkgeräten. Die Auswahl von Hochleistungs-Hardwarekomponenten ist wichtig, um die Gesamtverarbeitungsgeschwindigkeit zu verbessern. 2. Betriebssystem -Tunes -Dateideskriptoren und Netzwerkverbindungen: Ändern Sie die Datei /etc/security/limits.conf, um die Obergrenze der Dateideskriptoren und Netzwerkverbindungen zu erhöhen, die gleichzeitig vom System geöffnet werden dürfen. JVM-Parameteranpassung: Einstellen in der Hadoop-env.sh-Datei einstellen
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So sehen Sie Ihre Apache -Version an
Apr 13, 2025 pm 01:15 PM
So sehen Sie Ihre Apache -Version an
Apr 13, 2025 pm 01:15 PM
Es gibt 3 Möglichkeiten, die Version auf dem Apache -Server anzuzeigen: Über die Befehlszeile (apachect -v- oder apache2CTL -v) überprüfen Sie die Seite Serverstatus (http: // & lt; Server -IP- oder Domänenname & GT;/Server -Status) oder die Apache -Konfigurationsdatei (Serversion: Apache/& lt; Versionsnummer & GT;).).
