
 Technologie-Peripheriegeräte
KI
HKUs großes Open-Source-Graph-Grundmodell OpenGraph: starke Generalisierungsfähigkeit, Vorwärtsausbreitung zur Vorhersage neuer Daten
Technologie-Peripheriegeräte
KI
HKUs großes Open-Source-Graph-Grundmodell OpenGraph: starke Generalisierungsfähigkeit, Vorwärtsausbreitung zur Vorhersage neuer Daten
HKUs großes Open-Source-Graph-Grundmodell OpenGraph: starke Generalisierungsfähigkeit, Vorwärtsausbreitung zur Vorhersage neuer Daten

Das Problem des Datenmangels im Bereich des Graphenlernens wurde mit neuen Tricks gelöst!
OpenGraph, ein grundlegendes diagrammbasiertes Modell, das speziell für die Zero-Shot-Vorhersage für eine Vielzahl von Diagrammdatensätzen entwickelt wurde.
Das Team von Chao Huang, Leiter des Hong Kong Big Data Intelligence Laboratory, schlug außerdem Verbesserungs- und Anpassungstechniken für das Modell vor, um die Anpassungsfähigkeit des Modells an neue Aufgaben zu verbessern.
Derzeit wurde diese Arbeit auf GitHub hochgeladen.
Einführung in Techniken zur Datenerweiterung. In dieser Arbeit werden hauptsächlich detaillierte Strategien zur Verbesserung der Generalisierungsfähigkeit grafischer Modelle untersucht (insbesondere, wenn erhebliche Unterschiede zwischen Trainings- und Testdaten bestehen).
OpenGraph ist ein allgemeines Diagrammstrukturmodell, das eine Vorwärtsausbreitung durch Ausbreitungsvorhersage durchführt, um eine Vorhersage neuer Daten ohne Stichprobe zu erreichen.
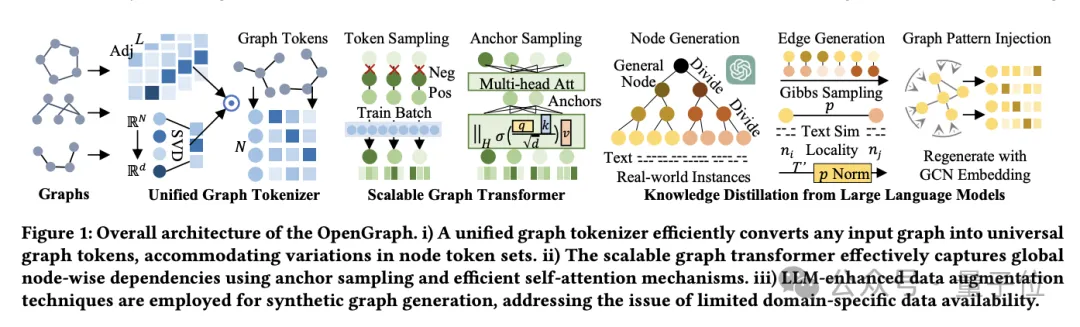
Um das Ziel zu erreichen, hat das Team die folgenden 3 Herausforderungen gelöst:
- Token-Unterschiede zwischen Datensätzen: Unterschiedliche Diagrammdatensätze haben oft unterschiedliche Diagramm-Tokensätze, und wir benötigen das Modell dazu in der Lage sein, über Datensätze hinweg Vorhersagen zu treffen.
- Knotenbeziehungsmodellierung: Beim Erstellen eines allgemeinen Diagrammmodells ist es entscheidend, Knotenbeziehungen effektiv zu modellieren, was mit der Skalierbarkeit und Effizienz des Modells zusammenhängt.
- Datenknappheit: Angesichts des Problems der Datenerfassung führen wir eine Datenverbesserung durch große Sprachmodelle durch, um komplexe Diagrammstrukturbeziehungen zu simulieren und die Qualität des Modelltrainings zu verbessern.
Durch eine Reihe innovativer Methoden, wie zum Beispiel den topologiebewussten BERT Tokenizer und den ankerbasierten Graph Transformer, bewältigt OpenGraph die oben genannten Herausforderungen effektiv. Testergebnisse an mehreren Datensätzen belegen die hervorragende Generalisierungsfähigkeit des Modells und ermöglichen eine effektive Bewertung der Farbgeneralisierungsfähigkeit des Modells.
OpenGraph-Modell
Die OpenGraph-Modellarchitektur besteht hauptsächlich aus drei Kernteilen:
- Unified Graph Tokenizer.
- Erweiterbarer Diagrammtransformator.
- Wissensdestillationstechnologie basierend auf einem großen Sprachmodell.
Lassen Sie uns zunächst über den Unified Graph Tokenizer sprechen.
Um sich an die Unterschiede bei Knoten und Kanten in verschiedenen Datensätzen anzupassen, entwickelte das Team den Unified Graph Tokenizer, der Diagrammdaten in Token-Sequenzen normalisiert.
Dieser Prozess umfasst die Glättung einer Adjazenzmatrix höherer Ordnung und eine topologiebewusste Zuordnung.
Die Adjazenzmatrixglättung hoher Ordnung nutzt die Leistungsfähigkeit der Adjazenzmatrix hoher Ordnung, um das Problem spärlicher Verbindungen zu lösen, während die topologiebewusste Zuordnung die Adjazenzmatrix in eine Knotensequenz umwandelt und zur Minimierung eine schnelle Singularwertzerlegung (SVD) verwendet Informationsverlust, mehr Informationen zur Diagrammstruktur bleiben erhalten.
Der zweite ist der erweiterbare Graph Transformer.
Nach der Tokenisierung verwendet OpenGraph die Transformer-Architektur, um die Abhängigkeiten zwischen Knoten zu simulieren, und verwendet hauptsächlich die folgenden Technologien, um die Leistung und Effizienz des Modells zu optimieren:
Erstens nutzt das Token-Sequenz-Sampling die Sampling-Technologie, um die Anzahl der Beziehungen zu reduzieren, die das Modell benötigt zu verarbeiten, wodurch der Schulungsaufwand und die räumliche Komplexität reduziert werden.
Der zweite ist der Selbstaufmerksamkeitsmechanismus des Ankersamplings. Diese Methode reduziert die Rechenkomplexität weiter und verbessert effektiv die Trainingseffizienz und Stabilität des Modells durch die stufenweise Übertragung von Informationen zwischen Lernknoten.
Der letzte Schritt ist die Wissensdestillation großer Sprachmodelle.
Um die Datenschutz- und Kategoriediversitätsprobleme zu bewältigen, die beim Training allgemeiner Diagrammmodelle auftreten, ließ sich das Team vom Wissen und den Verständnisfähigkeiten großer Sprachmodelle (LLM) inspirieren und nutzte LLM, um verschiedene Diagrammstrukturdaten zu generieren.
Dieser Datenverbesserungsmechanismus verbessert effektiv die Qualität und Praktikabilität von Daten, indem er die Eigenschaften realer Diagramme simuliert.
Das Team generiert außerdem zunächst an spezifische Anwendungen angepasste Knotensätze, wobei jeder Knoten eine Textbeschreibung für die Kantengenerierung hat.
Wenn es um große Knotengruppen wie E-Commerce-Plattformen geht, gehen Forscher damit um, indem sie Knoten in spezifischere Unterkategorien unterteilen.
Zum Beispiel wird dieser Vorgang von „elektronischen Produkten“ bis hin zu bestimmten „Mobiltelefonen“, „Laptops“ usw. wiederholt, bis die Knoten so weit verfeinert sind, dass sie realen Instanzen nahe kommen.
Der Prompt-Tree-Algorithmus unterteilt Knoten entsprechend der Baumstruktur und generiert detailliertere Entitäten.
Beginnen Sie mit einer allgemeinen Kategorie wie „Produkt“, verfeinern Sie sie schrittweise zu bestimmten Unterkategorien und bilden Sie schließlich einen Knotenbaum.
Was die Kantengenerierung betrifft, bilden Forscher mithilfe der Gibbs-Stichprobe Kanten basierend auf dem generierten Knotensatz.
Um den Rechenaufwand zu reduzieren, durchlaufen wir nicht direkt alle möglichen Kanten durch LLM. Stattdessen verwenden wir zunächst LLM, um die Textähnlichkeit zwischen Knoten zu berechnen, und verwenden dann einen einfachen Algorithmus, um die Knotenbeziehung zu bestimmen.
Auf dieser Grundlage führte das Team mehrere technische Anpassungen ein:
- Dynamische Wahrscheinlichkeitsnormalisierung: Ordnen Sie die Ähnlichkeit durch dynamische Anpassung einem Wahrscheinlichkeitsbereich zu, der besser für die Stichprobe geeignet ist.
- Knotenlokalität: Führt das Konzept der Lokalität ein und stellt nur Verbindungen zwischen lokalen Teilmengen von Knoten her, um die Netzwerklokalität in der realen Welt zu simulieren.
- Graph-Topologie-Musterinjektion: Verwenden Sie ein Graph-Faltungsnetzwerk, um die Knotendarstellung zu ändern, um sie besser an die Eigenschaften der Graphstruktur anzupassen und Verteilungsabweichungen zu reduzieren.
Die oben genannten Schritte stellen sicher, dass die generierten Diagrammdaten nicht nur reichhaltig und vielfältig sind, sondern auch den Verbindungsmustern und Strukturmerkmalen der realen Welt nahe kommen.
Experimentelle Verifizierung und Leistungsanalyse
Es ist zu beachten, dass sich dieses Experiment auf das Training des OpenGraph-Modells unter Verwendung eines nur von LLM generierten Datensatzes und das Testen an einem vielfältigen Datensatz aus realen Szenarien konzentriert, der Knotenklassifizierungs- und Verbindungsvorhersageaufgaben abdeckt.
Der Versuchsaufbau ist wie folgt:
Nullprobeneinstellung.
Um die Leistung von OpenGraph anhand unsichtbarer Daten zu bewerten, trainieren wir das Modell anhand des generierten Trainingssatzes und bewerten es dann anhand eines völlig anderen realen Testsatzes. Dadurch wird sichergestellt, dass die Trainings- und Testdaten keine Überlappungen bei Knoten, Kanten und Features aufweisen.
Weniger Beispieleinstellungen.
Angesichts der Tatsache, dass es für viele Methoden schwierig ist, eine Null-Schuss-Vorhersage durchzuführen, führen wir eine Einstellung mit wenigen Schüssen ein. Nachdem das Basismodell anhand von Vortrainingsdaten vorab trainiert wurde, werden K-Schuss-Proben zur Feinabstimmung verwendet .
Ergebnisse zu 2 Aufgaben und 8 Testsätzen zeigen, dass OpenGraph bestehende Methoden bei der Zero-Shot-Vorhersage deutlich übertrifft.
Darüber hinaus schneiden vorhandene vorab trainierte Modelle manchmal schlechter ab als Modelle, die bei datensatzübergreifenden Aufgaben von Grund auf trainiert wurden.
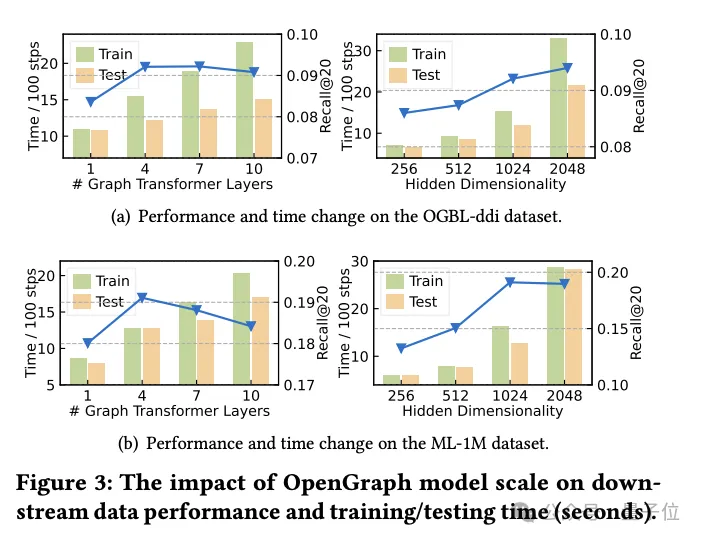
Studie über die Auswirkungen des Graph-Tokenizer-Designs
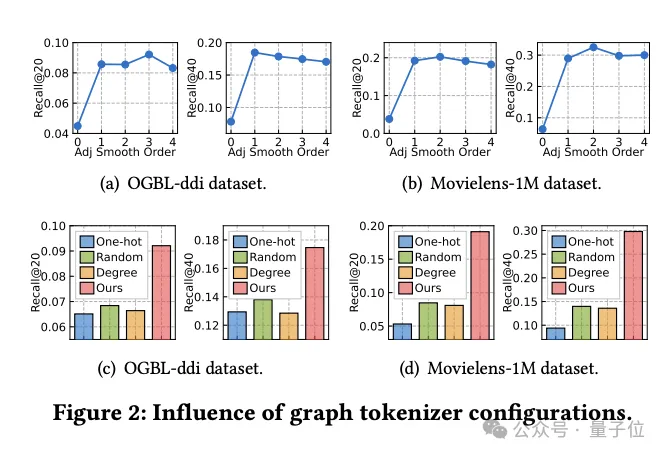
Gleichzeitig untersuchte das Team, wie sich das Graph-Tokenizer-Design auf die Modellleistung auswirkt.
Zunächst wurde durch Experimente festgestellt, dass die Nichtdurchführung einer Adjazenzmatrix-Glättung (Glättungsreihenfolge ist 0) die Leistung erheblich verringert, was auf die Notwendigkeit einer Glättung hinweist.
Die Forscher probierten dann mehrere einfache topologiebewusste Alternativen aus: One-Hot-codierte IDs über Datensätze hinweg, zufällige Zuordnung und knotengradbasierte Darstellungen.
Experimentelle Ergebnisse zeigen, dass die Leistung dieser Alternativen nicht ideal ist.
Insbesondere ist die ID-Darstellung über Datensätze hinweg am schlechtesten, und die gradbasierte Darstellung schneidet ebenfalls schlecht ab, während die zufällige Zuordnung zwar etwas besser ist, aber im Vergleich zur optimierten topologiebewussten Zuordnung einen erheblichen Leistungsunterschied aufweist.
Auswirkungen von Datengenerierungstechniken
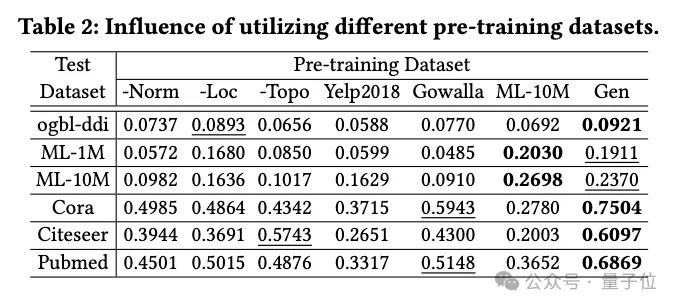
Das Team untersuchte die Auswirkungen verschiedener Datensätze vor dem Training auf die OpenGraph-Leistung, einschließlich Datensätzen, die mit LLM-basierten Wissensdestillationsmethoden generiert wurden, sowie mehrerer Datensätze aus der realen Welt.
Die im Experiment verglichenen Datensätze vor dem Training umfassen den Datensatz nach dem Entfernen einer bestimmten Technologie aus der Teamgenerierungsmethode, 2 echte Datensätze (Yelp2018 und Gowalla) , die nicht mit dem Testdatensatz zusammenhängen, 1 Daten Stellen Sie mit den Testdaten einen ähnlichen realen Datensatz ein (ML-10M) .
Experimentelle Ergebnisse zeigen, dass der generierte Datensatz bei allen Testsätzen eine gute Leistung zeigt; die Entfernung der drei Generierungstechniken wirkt sich erheblich auf die Leistung aus und bestätigt die Wirksamkeit dieser Techniken.
Beim Training mit echten Datensätzen (wie Yelp und Gowalla) , die nicht mit dem Testsatz in Zusammenhang stehen, nimmt die Leistung manchmal ab, was auf Verteilungsunterschiede zwischen verschiedenen Datensätzen zurückzuführen sein kann. Der
ML-10M-Datensatz erzielt die beste Leistung bei ähnlichen Testdatensätzen wie ML-1M und ML-10M , was die Bedeutung der Ähnlichkeit zwischen Trainings- und Testdatensätzen hervorhebt.
Forschung zur Transformer-Sampling-Technologie
In diesem Teil des Experiments untersuchte das Forschungsteam zwei Sampling-Techniken, die im Graph Transformer-Modul verwendet werden:
Token-Sequenz-Sampling (Seq) und Anker-Sampling (Anc).
Sie führten detaillierte Ablationsexperimente mit diesen beiden Probenahmemethoden durch, um deren spezifischen Einfluss auf die Modellleistung zu bewerten.
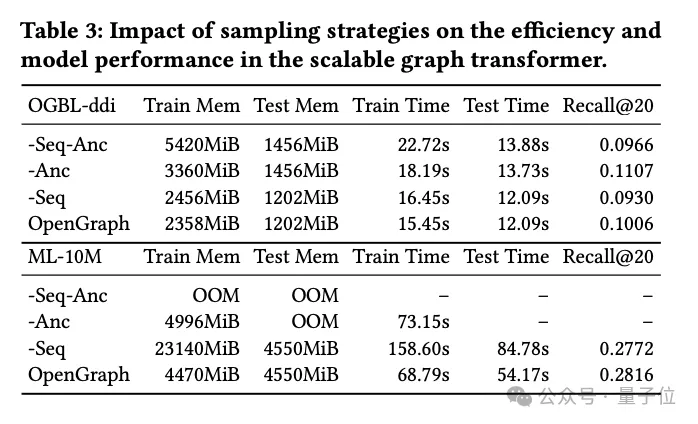
Experimentelle Ergebnisse zeigen, dass beide, unabhängig davon, ob es sich um Token-Sequenz-Sampling oder Ankerpunkt-Sampling handelt, die räumliche und zeitliche Komplexität des Modells während der Trainings- und Testphase effektiv reduzieren können. Dies ist besonders wichtig für die Verarbeitung umfangreicher Diagrammdaten und kann die Effizienz erheblich verbessern.
Aus Sicht der Leistung hat das Token-Sequenz-Sampling einen positiven Einfluss auf die Gesamtleistung des Modells. Diese Stichprobenstrategie optimiert die Darstellung des Diagramms durch Auswahl von Schlüsseltokens und verbessert dadurch die Fähigkeit des Modells, komplexe Diagrammstrukturen zu verarbeiten.
Im Gegensatz dazu zeigen Experimente mit dem DDI-Datensatz, dass Ankerstichproben einen negativen Einfluss auf die Modellleistung haben können. Durch die Ankerstichprobe wird die Diagrammstruktur vereinfacht, indem bestimmte Knoten als Ankerpunkte ausgewählt werden. Bei dieser Methode werden jedoch möglicherweise einige wichtige Informationen zur Diagrammstruktur ignoriert, wodurch die Genauigkeit des Modells beeinträchtigt wird.
Zusammenfassend lässt sich sagen, dass beide Probenahmetechniken zwar ihre Vorteile haben, in praktischen Anwendungen jedoch die geeignete Probenahmestrategie sorgfältig auf der Grundlage spezifischer Datensätze und Aufgabenanforderungen ausgewählt werden muss.
Schlussfolgerung der Forschung
Diese Forschung zielt darauf ab, ein äußerst anpassungsfähiges Framework zu entwickeln, das komplexe topologische Muster verschiedener Graphstrukturen genau identifizieren und analysieren kann.
Das Ziel der Forscher ist es, die Generalisierungsfähigkeit des Modells bei Zero-Shot-Graph-Lernaufgaben, einschließlich einer Vielzahl nachgelagerter Anwendungen, deutlich zu verbessern, indem sie die Fähigkeiten des vorgeschlagenen Modells voll ausschöpfen.
Das Modell wird mit Unterstützung einer skalierbaren Graph-Transformer-Architektur und einem LLM-erweiterten Datenerweiterungsmechanismus erstellt, um die Effizienz und Robustheit von OpenGraph zu verbessern.
Durch umfangreiche Tests an mehreren Standarddatensätzen demonstrierte das Team die hervorragende Generalisierungsleistung des Modells.
Es wird davon ausgegangen, dass sich die Arbeit des Teams in Zukunft als erster Versuch, ein graphbasiertes Modell zu erstellen, auf die Verbesserung der Automatisierungsfähigkeiten des Frameworks konzentrieren wird, einschließlich der automatischen Identifizierung verrauschter Verbindungen und der Durchführung kontrafaktischen Lernens.
Gleichzeitig plant das Team, gemeinsame und übertragbare Muster verschiedener Graphstrukturen zu erlernen und zu extrahieren, um den Anwendungsbereich und die Wirkung des Modells weiter zu fördern.
Referenzlink:
[1] Papier: https://arxiv.org/pdf/2403.01121.pdf.
[2] Quellcode-Bibliothek: https://github.com/HKUDS/OpenGraph.
Das obige ist der detaillierte Inhalt vonHKUs großes Open-Source-Graph-Grundmodell OpenGraph: starke Generalisierungsfähigkeit, Vorwärtsausbreitung zur Vorhersage neuer Daten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
So installieren Sie Deepseek
Feb 19, 2025 pm 05:48 PM
Es gibt viele Möglichkeiten, Deepseek zu installieren, einschließlich: kompilieren Sie von Quelle (für erfahrene Entwickler) mit vorberechtigten Paketen (für Windows -Benutzer) mit Docker -Containern (für bequem am besten, um die Kompatibilität nicht zu sorgen), unabhängig von der Methode, die Sie auswählen, bitte lesen Die offiziellen Dokumente vorbereiten sie sorgfältig und bereiten sie voll und ganz vor, um unnötige Schwierigkeiten zu vermeiden.
 SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
SK Hynix wird am 6. August neue KI-bezogene Produkte vorstellen: 12-Layer-HBM3E, 321-High-NAND usw.
Aug 01, 2024 pm 09:40 PM
Laut Nachrichten dieser Website vom 1. August hat SK Hynix heute (1. August) einen Blogbeitrag veröffentlicht, in dem es ankündigt, dass es am Global Semiconductor Memory Summit FMS2024 teilnehmen wird, der vom 6. bis 8. August in Santa Clara, Kalifornien, USA, stattfindet viele neue Technologien Generation Produkt. Einführung des Future Memory and Storage Summit (FutureMemoryandStorage), früher Flash Memory Summit (FlashMemorySummit), hauptsächlich für NAND-Anbieter, im Zusammenhang mit der zunehmenden Aufmerksamkeit für die Technologie der künstlichen Intelligenz wurde dieses Jahr in Future Memory and Storage Summit (FutureMemoryandStorage) umbenannt Laden Sie DRAM- und Speicheranbieter und viele weitere Akteure ein. Neues Produkt SK Hynix wurde letztes Jahr auf den Markt gebracht
 Zusammenfassung der FAQs für die Verwendung von Deepseek
Feb 19, 2025 pm 03:45 PM
Zusammenfassung der FAQs für die Verwendung von Deepseek
Feb 19, 2025 pm 03:45 PM
Deepseekai Tool User Guide und FAQ Deepseek ist ein leistungsstarkes KI -Intelligent -Tool. FAQ: Der Unterschied zwischen verschiedenen Zugriffsmethoden: Es gibt keinen Unterschied in der Funktion zwischen Webversion, App -Version und API -Aufrufen, und App ist nur ein Wrapper für die Webversion. Die lokale Bereitstellung verwendet ein Destillationsmodell, das der Vollversion von Deepseek-R1 geringfügig unteren ist, das 32-Bit-Modell theoretisch 90% Vollversionsfunktion. Was ist eine Taverne? SillyTervern ist eine Front-End-Oberfläche, die das KI-Modell über API oder Ollama anruft. Was ist Breaking Limit
 Iyo One: Teils Kopfhörer, teils Audiocomputer
Aug 08, 2024 am 01:03 AM
Iyo One: Teils Kopfhörer, teils Audiocomputer
Aug 08, 2024 am 01:03 AM
Konzentration ist zu jeder Zeit eine Tugend. Autor |. Herausgeber Tang Yitao |. Jing Yu Das Wiederaufleben der künstlichen Intelligenz hat zu einer neuen Welle von Hardware-Innovationen geführt. Der beliebteste AIPin hat beispiellose negative Bewertungen erhalten. Marques Brownlee (MKBHD) bezeichnete es als das schlechteste Produkt, das er jemals rezensiert habe; David Pierce, Herausgeber von The Verge, sagte, er würde niemandem empfehlen, dieses Gerät zu kaufen. Sein Konkurrent, der RabbitR1, ist nicht viel besser. Der größte Zweifel an diesem KI-Gerät besteht darin, dass es sich offensichtlich nur um eine App handelt, Rabbit jedoch eine 200-Dollar-Hardware gebaut hat. Viele Menschen sehen KI-Hardware-Innovationen als Chance, das Smartphone-Zeitalter zu untergraben und sich ihm zu widmen.
 Wie registriere ich mich für die LBank Exchange?
Aug 21, 2024 pm 02:20 PM
Wie registriere ich mich für die LBank Exchange?
Aug 21, 2024 pm 02:20 PM
Um sich bei der LBank zu registrieren, besuchen Sie die offizielle Website und klicken Sie auf „Registrieren“. Geben Sie Ihre E-Mail-Adresse und Ihr Passwort ein und bestätigen Sie Ihre E-Mail-Adresse. Laden Sie die LBank-App für iOS herunter: Suchen Sie im AppStore nach „LBank“. Laden Sie die Anwendung „LBank-DigitalAssetExchange“ herunter und installieren Sie sie. Android: Suchen Sie im Google Play Store nach „LBank“. Laden Sie die Anwendung „LBank-DigitalAssetExchange“ herunter und installieren Sie sie.
 Was sind die KI-Tools?
Nov 29, 2024 am 11:11 AM
Was sind die KI-Tools?
Nov 29, 2024 am 11:11 AM
Zu den KI-Tools gehören: Doubao, ChatGPT, Gemini, BlenderBot usw.
 Was sind die Graustufenverschlüsselungsfonds?
Mar 05, 2025 pm 12:33 PM
Was sind die Graustufenverschlüsselungsfonds?
Mar 05, 2025 pm 12:33 PM
Grayscale -Investitionen: Der Kanal für institutionelle Anleger, um den Kryptowährungsmarkt zu betreten. Das Unternehmen hat mehrere Krypto -Trusts auf den Markt gebracht, was die weit verbreitete Marktaufmerksamkeit auf sich gezogen hat, die Auswirkungen dieser Mittel auf die Tokenpreise jedoch erheblich variieren. In diesem Artikel werden einige der wichtigsten Krypto -Vertrauensfonds von Grayscale ausführlich vorgestellt. Grayscale Major Crypto Trust Funds, die auf einer Blick Grayscale-Investition erhältlich sind (gegründet von DigitalCurrencyGroup im Jahr 2013), verwaltet eine Vielzahl von Crypto Asset Trust Funds und bietet institutionelle Anleger und Einzelpersonen mit hohem Nettel mit konformen Investitionskanälen. Zu den Hauptfonds gehören: Zcash (ZEC), Sol,
 Delphi Digital: Wie kann man die neue KI -Wirtschaft verändern, indem sie die neue Elizaos V2 -Architektur analysiert?
Mar 04, 2025 pm 07:00 PM
Delphi Digital: Wie kann man die neue KI -Wirtschaft verändern, indem sie die neue Elizaos V2 -Architektur analysiert?
Mar 04, 2025 pm 07:00 PM
ElizaOSV2: Erleichterung der KI und Führung der neuen Wirtschaft von Web3. Dieser Artikel wird sich mit den wichtigsten Innovationen von Elizaosv2 befassen und wie er eine KI-gesteuerte zukünftige Wirtschaft prägt. KI -Automatisierung: Es war ursprünglich ein KI -Framework, der sich auf Web3 -Automatisierung konzentrierte. Mit der V1 -Version kann AI mit intelligenten Verträgen und Blockchain -Daten interagieren, während die V2 -Version erhebliche Leistungsverbesserungen erzielt. Anstatt nur einfache Anweisungen auszuführen, kann KI Workflows unabhängig verwalten, Geschäft betreiben und finanzielle Strategien entwickeln. Architektur -Upgrade: Verbessert a
