
 Technologie-Peripheriegeräte
KI
HKU überprüft 170 Empfehlungsalgorithmen für „selbstüberwachtes Lernen' und veröffentlicht SSL4Rec: Der Code und die Datenbank sind vollständig Open Source!
Technologie-Peripheriegeräte
KI
HKU überprüft 170 Empfehlungsalgorithmen für „selbstüberwachtes Lernen' und veröffentlicht SSL4Rec: Der Code und die Datenbank sind vollständig Open Source!
HKU überprüft 170 Empfehlungsalgorithmen für „selbstüberwachtes Lernen' und veröffentlicht SSL4Rec: Der Code und die Datenbank sind vollständig Open Source!

Empfehlungssysteme sind wichtig, um der Herausforderung der Informationsüberflutung zu begegnen, da sie maßgeschneiderte Empfehlungen basierend auf den persönlichen Vorlieben der Benutzer bereitstellen. In den letzten Jahren hat die Deep-Learning-Technologie die Entwicklung von Empfehlungssystemen stark vorangetrieben und Einblicke in das Verhalten und die Präferenzen der Nutzer verbessert.
Allerdings stehen herkömmliche Methoden des überwachten Lernens in praktischen Anwendungen vor Herausforderungen, da das Problem der Datenknappheit ihre Fähigkeit einschränkt, die Benutzerleistung effektiv zu erlernen.
Um dieses Problem zu schützen und zu überwinden, wird bei Schülern die Technologie des selbstüberwachten Lernens (SSL) angewendet, die die inhärente Datenstruktur zur Generierung von Überwachungssignalen nutzt und sich nicht ausschließlich auf gekennzeichnete Daten verlässt.
Diese Methode verwendet ein Empfehlungssystem, das aussagekräftige Informationen aus unbeschrifteten Daten extrahieren und genaue Vorhersagen und Empfehlungen treffen kann, selbst wenn die Daten knapp sind.

Artikeladresse: https://arxiv.org/abs/2404.03354
Open-Source-Datenbank: https://github.com/HKUDS/Awesome-SSLRec-Papers
Open Source Code-Bibliothek: https://github.com/HKUDS/SSLRec
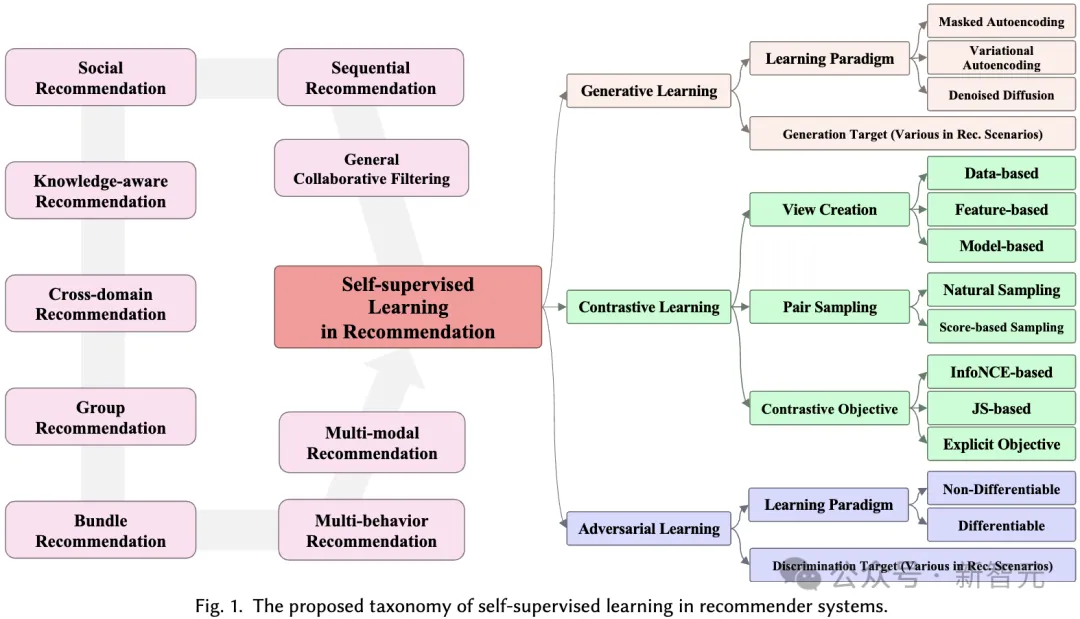
Dieser Artikel bespricht selbstüberwachte Lernrahmen, die für Empfehlungssysteme entwickelt wurden, und führt eine eingehende Analyse von mehr als 170 verwandten Artikeln durch. Wir haben neun verschiedene Anwendungsszenarien untersucht, um ein umfassendes Verständnis dafür zu gewinnen, wie SSL Empfehlungssysteme in verschiedenen Szenarien verbessern kann.
Für jede Domäne diskutieren wir ausführlich verschiedene selbstüberwachte Lernparadigmen, einschließlich kontrastivem Lernen, generativem Lernen und kontradiktorischem Lernen, und zeigen, wie SSL die Leistung von Empfehlungssystemen in verschiedenen Situationen verbessern kann.
1 Empfohlenes System
Die Forschung zu Empfehlungssystemen deckt verschiedene Aufgaben in verschiedenen Szenarien ab, wie z. B. kollaborative Filterung, Sequenzempfehlung, Multiverhaltensempfehlung usw. Diese Aufgaben haben unterschiedliche Datenparadigmen und Ziele. Hier geben wir zunächst eine allgemeine Definition, ohne auf spezifische Variationen für verschiedene Empfehlungsaufgaben einzugehen. In Empfehlungssystemen gibt es zwei Hauptgruppen: Benutzergruppen, bezeichnet als 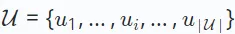 , und Elementgruppen, bezeichnet als
, und Elementgruppen, bezeichnet als 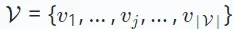 .
.
Verwenden Sie dann eine Interaktionsmatrix 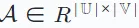 , um die aufgezeichneten Interaktionen zwischen dem Benutzer und dem Artikel darzustellen. In dieser Matrix wird dem Eintrag Ai,j der Matrix der Wert 1 zugewiesen, wenn der Benutzer ui mit dem Element vj interagiert hat, andernfalls ist er 0.
, um die aufgezeichneten Interaktionen zwischen dem Benutzer und dem Artikel darzustellen. In dieser Matrix wird dem Eintrag Ai,j der Matrix der Wert 1 zugewiesen, wenn der Benutzer ui mit dem Element vj interagiert hat, andernfalls ist er 0.
Die Definition von Interaktion kann an verschiedene Kontexte und Datensätze angepasst werden (z. B. Ansehen eines Films, Klicken auf eine E-Commerce-Website oder Tätigen eines Kaufs).
Darüber hinaus gibt es in verschiedenen Empfehlungsaufgaben unterschiedliche Hilfsbeobachtungsdaten, die als entsprechende Beziehungen aufgezeichnet werden.
Und in der sozialen Empfehlung umfasst X Beziehungen auf Benutzerebene, wie zum Beispiel Freundschaft. Basierend auf der obigen Definition optimiert das Empfehlungsmodell eine Vorhersagefunktion f(⋅) mit dem Ziel, den Präferenzwert zwischen jedem Benutzer u und Element v genau zu schätzen:
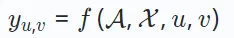
Der Präferenzwert yu,v repräsentiert Benutzer u und Artikel v Möglichkeit der Interaktion.
Basierend auf dieser Bewertung kann das Empfehlungssystem jedem Benutzer nicht interagierte Artikel empfehlen, indem es eine Rangliste der Artikel basierend auf der geschätzten Präferenzbewertung bereitstellt. In der Rezension untersuchen wir weiter die Datenform von (A,X) in verschiedenen Empfehlungsszenarien und die Rolle des selbstüberwachten Lernens darin.
2 Selbstüberwachtes Lernen in Empfehlungssystemen
In den letzten Jahren haben tiefe neuronale Netze beim überwachten Lernen gute Leistungen erbracht, was sich in verschiedenen Bereichen widerspiegelt, darunter Computer Vision, Verarbeitung natürlicher Sprache und Empfehlungssysteme. Aufgrund der starken Abhängigkeit von beschrifteten Daten steht das überwachte Lernen jedoch vor Herausforderungen im Umgang mit der Label-Spärlichkeit, die auch in Empfehlungssystemen ein häufiges Problem darstellt.
Um diese Einschränkung zu beseitigen, hat sich selbstüberwachtes Lernen als vielversprechende Methode herausgestellt, bei der die Daten selbst als gelernte Bezeichnung verwendet werden. Selbstüberwachtes Lernen in Empfehlungssystemen umfasst drei verschiedene Paradigmen: kontrastives Lernen, generatives Lernen und kontradiktorisches Lernen. 2.1 Kontrastives Lernen Beim kontrastiven Lernen des Empfehlungssystems besteht das Ziel darin, die folgende Verlustfunktion zu minimieren:
E∗
∘ω∗ repräsentiert den kontrastiven Ansichtserstellungsvorgang und verschiedene Empfehlungsalgorithmen, die auf kontrastivem Lernen basieren haben unterschiedliche Erstellungsprozesse. Die Konstruktion jeder Ansicht besteht aus einem Datenerweiterungsprozess ω∗ (der Knoten/Kanten im erweiterten Graphen umfassen kann) und einem Einbettungskodierungsprozess E∗. Das Ziel von
minimizing 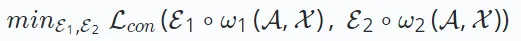
besteht darin, eine robuste Codierungsfunktion zu erhalten, die die Konsistenz zwischen Ansichten maximiert. Diese Konsistenz über Ansichten hinweg kann durch Methoden wie gegenseitige Informationsmaximierung oder Instanzunterscheidung erreicht werden.
2.2 Generatives Lernen
 Das Ziel des generativen Lernens besteht darin, die Struktur und Muster von Daten zu verstehen, um sinnvolle Darstellungen zu lernen. Es optimiert ein tiefes Encoder-Decoder-Modell, das fehlende oder beschädigte Eingabedaten rekonstruiert. Der
Das Ziel des generativen Lernens besteht darin, die Struktur und Muster von Daten zu verstehen, um sinnvolle Darstellungen zu lernen. Es optimiert ein tiefes Encoder-Decoder-Modell, das fehlende oder beschädigte Eingabedaten rekonstruiert. Der
Encoder erstellt eine latente Darstellung aus dem Eingang, während der Decoder
die Originaldaten aus dem Encoder-Ausgang rekonstruiert. Ziel ist es, den Unterschied zwischen den rekonstruierten und den Originaldaten wie folgt zu minimieren:
 Hier steht ω für eine Operation wie Maskierung oder Störung. D∘E repräsentiert den Prozess der Kodierung und Dekodierung zur Rekonstruktion der Ausgabe. Neuere Forschungen haben auch eine reine Decoder-Architektur eingeführt, die Daten ohne Encoder-Decoder-Setup effizient rekonstruiert. Dieser Ansatz verwendet ein einzelnes Modell (z. B. Transformer) zur Rekonstruktion und wird typischerweise auf serialisierte Empfehlungen angewendet, die auf generativem Lernen basieren. Das Format der Verlustfunktion
Hier steht ω für eine Operation wie Maskierung oder Störung. D∘E repräsentiert den Prozess der Kodierung und Dekodierung zur Rekonstruktion der Ausgabe. Neuere Forschungen haben auch eine reine Decoder-Architektur eingeführt, die Daten ohne Encoder-Decoder-Setup effizient rekonstruiert. Dieser Ansatz verwendet ein einzelnes Modell (z. B. Transformer) zur Rekonstruktion und wird typischerweise auf serialisierte Empfehlungen angewendet, die auf generativem Lernen basieren. Das Format der Verlustfunktion 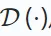 hängt vom Datentyp ab, z. B. mittlerer quadratischer Fehler für kontinuierliche Daten und Kreuzentropieverlust für kategoriale Daten. 2.3 Kontradiktorisches Lernen ist real oder generiert. Im Gegensatz zum generativen Lernen unterscheidet sich das kontradiktorische Lernen dadurch, dass es einen Diskriminator einschließt, der konkurrierende Interaktionen nutzt, um die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Ergebnisse zu erzeugen und so den Diskriminator zu täuschen.
hängt vom Datentyp ab, z. B. mittlerer quadratischer Fehler für kontinuierliche Daten und Kreuzentropieverlust für kategoriale Daten. 2.3 Kontradiktorisches Lernen ist real oder generiert. Im Gegensatz zum generativen Lernen unterscheidet sich das kontradiktorische Lernen dadurch, dass es einen Diskriminator einschließt, der konkurrierende Interaktionen nutzt, um die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Ergebnisse zu erzeugen und so den Diskriminator zu täuschen.
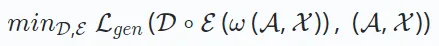 Daher kann das Lernziel des kontradiktorischen Lernens wie folgt definiert werden:
Daher kann das Lernziel des kontradiktorischen Lernens wie folgt definiert werden:
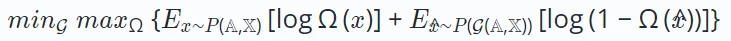
Hier stellt die Variable x die reale Stichprobe dar, die aus der zugrunde liegenden Datenverteilung erhalten wurde, während 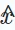 die vom Generator G(⋅) generierte synthetische Stichprobe darstellt. Während des Trainings verbessern sowohl der Generator als auch der Diskriminator ihre Fähigkeiten durch konkurrierende Interaktionen. Letztendlich ist der Generator bestrebt, qualitativ hochwertige Ergebnisse zu erzeugen, die für nachgelagerte Aufgaben von Vorteil sind.
die vom Generator G(⋅) generierte synthetische Stichprobe darstellt. Während des Trainings verbessern sowohl der Generator als auch der Diskriminator ihre Fähigkeiten durch konkurrierende Interaktionen. Letztendlich ist der Generator bestrebt, qualitativ hochwertige Ergebnisse zu erzeugen, die für nachgelagerte Aufgaben von Vorteil sind.
3 Taxonomie
In diesem Abschnitt schlagen wir ein umfassendes Klassifizierungssystem für die Anwendung von selbstüberwachtem Lernen in Empfehlungssystemen vor. Wie bereits erwähnt, können selbstüberwachte Lernparadigmen in drei Kategorien unterteilt werden: kontrastives Lernen, generatives Lernen und kontradiktorisches Lernen. Daher basiert unser Klassifizierungssystem auf diesen drei Kategorien und bietet tiefere Einblicke in jede Kategorie.
3.1 Kontrastives Lernen in Empfehlungssystemen
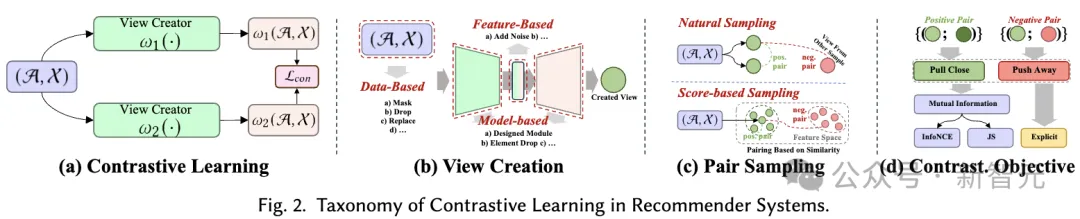
Das Grundprinzip des kontrastiven Lernens (CL) besteht darin, die Konsistenz zwischen verschiedenen Ansichten zu maximieren. Daher schlagen wir eine ansichtszentrierte Taxonomie vor, die aus drei Schlüsselkomponenten besteht, die bei der Anwendung kontrastiven Lernens zu berücksichtigen sind: Ansichten erstellen, Ansichten koppeln, um die Konsistenz zu maximieren, und Konsistenz optimieren.
Erstellung anzeigen. Erstellen Sie Ansichten, die die verschiedenen Datenaspekte hervorheben, auf die sich das Modell konzentriert. Es kann globale kollaborative Informationen kombinieren, um die Fähigkeit des Empfehlungssystems zur Handhabung globaler Beziehungen zu verbessern, oder zufälliges Rauschen einführen, um die Robustheit des Modells zu verbessern.
Wir betrachten die Verbesserung von Eingabedaten (z. B. Diagramme, Sequenzen, Eingabemerkmale) als Ansichtserstellung auf Datenebene, während die Verbesserung latenter Merkmale während der Inferenz als Ansichtserstellung auf Merkmalsebene betrachtet wird. Wir schlagen ein hierarchisches Klassifizierungssystem vor, das Techniken zur Ansichtserstellung von der Basisdatenebene bis zur Ebene des neuronalen Modells umfasst.
- Datenebene Datenbasiert: In einem Empfehlungssystem, das auf kontrastivem Lernen basiert, werden durch die Anreicherung von Eingabedaten vielfältige Ansichten geschaffen. Diese erweiterten Datenpunkte werden dann durch das Modell verarbeitet. Die aus verschiedenen Ansichten erhaltenen Ausgabeeinbettungen werden schließlich gepaart und für vergleichendes Lernen verwendet. Die Erweiterungsmethoden variieren je nach Empfehlungsszenario. Beispielsweise können Diagrammdaten durch das Löschen von Knoten/Kanten verbessert werden, während Sequenzen durch Maskieren, Zuschneiden und Ersetzen verbessert werden können.
- Featurebasiert: Zusätzlich zur Generierung von Ansichten direkt aus Daten erwägen einige Methoden auch die Verbesserung der codierten versteckten Features im Modellweiterleitungsprozess. Zu diesen verborgenen Funktionen können Knoteneinbettungen von Schichten graphischer neuronaler Netzwerke oder Token-Vektoren in Transformers gehören. Durch die mehrfache Anwendung verschiedener Verbesserungstechniken oder die Einführung zufälliger Störungen kann die endgültige Ausgabe des Modells in verschiedenen Ansichten betrachtet werden.
- Modellbasiert: Verbesserungen auf Daten- und Funktionsebene sind nicht adaptiv, da sie nicht parametrisch sind. Es gibt also auch Möglichkeiten, mithilfe von Modellen unterschiedliche Ansichten zu generieren. Diese Ansichten enthalten spezifische Informationen basierend auf dem Modellentwurf. Beispielsweise können absichtsentkoppelte neuronale Module Benutzerabsichten erfassen, während Hypergraph-Module globale Beziehungen erfassen können.
Paar-Sampling. Der Ansichtserstellungsprozess generiert mindestens zwei verschiedene Ansichten für jede Stichprobe in den Daten. Der Kern des kontrastiven Lernens besteht darin, die Ausrichtung bestimmter Ansichten zu maximieren (d. h. sie näher zusammenzubringen), während andere Ansichten verdrängt werden.
Um dies zu erreichen, besteht der Schlüssel darin, die positiven Probenpaare zu identifizieren, die näher gebracht werden sollten, und andere Ansichten zu identifizieren, die negative Probenpaare bilden. Diese Strategie wird als gepaarte Stichprobe bezeichnet und besteht hauptsächlich aus zwei gepaarten Stichprobenmethoden:
- Natürliches Sampling: Eine gängige Methode des gepaarten Samplings ist die direkte und nicht die heuristische Methode, die wir natürliches Sampling nennen. Positive Stichprobenpaare werden aus verschiedenen Ansichten gebildet, die von derselben Datenstichprobe generiert wurden, während negative Stichprobenpaare aus Ansichten unterschiedlicher Datenstichproben gebildet werden. Bei Vorhandensein einer zentralen Ansicht, beispielsweise einer globalen Ansicht, die aus dem gesamten Diagramm abgeleitet wird, können lokal-globale Beziehungen natürlich auch positive Stichprobenpaare bilden. Diese Methode wird in den meisten kontrastiven Lernempfehlungssystemen häufig verwendet.
- Bewertungsbasierte Stichprobenziehung: Eine weitere Methode der paarweisen Stichprobenziehung ist die bewertungsbasierte Stichprobenziehung. Bei diesem Ansatz berechnet ein Modul die Bewertungen von Stichprobenpaaren, um positive oder negative Stichprobenpaare zu bestimmen. Beispielsweise kann der Abstand zwischen zwei Ansichten zur Bestimmung positiver und negativer Probenpaare verwendet werden. Alternativ kann Clustering auf die Ansicht angewendet werden, wobei positive Paare innerhalb desselben Clusters und negative Paare innerhalb verschiedener Cluster liegen. Sobald für eine Ankeransicht ein positives Stichprobenpaar ermittelt wurde, gelten die verbleibenden Ansichten natürlich als negative Ansichten und können mit der gegebenen Ansicht gepaart werden, um negative Stichprobenpaare zu erstellen, was eine Verschiebung ermöglicht.
Kontrastives Objektiv. Das Lernziel beim kontrastiven Lernen besteht darin, die gegenseitige Information zwischen Paaren positiver Stichproben zu maximieren, was wiederum die Leistung des Lernempfehlungsmodells verbessern kann. Da es nicht möglich ist, gegenseitige Informationen direkt zu berechnen, wird beim kontrastiven Lernen normalerweise eine zulässige Untergrenze als Lernziel verwendet. Allerdings gibt es auch explizite Ziele, positive Paare näher zusammenzubringen.
- InfoNCE-basiert: InfoNCE ist eine Variante der lärmkontrastiven Schätzung. Sein Optimierungsprozess zielt darauf ab, positive Probenpaare näher zusammenzubringen und negative Probenpaare zu verdrängen.
- JS-basiert: Zusätzlich zur Verwendung von InfoNCE zur Schätzung der gegenseitigen Information können Sie auch die Jensen-Shannon-Divergenz verwenden, um die Untergrenze zu schätzen. Das abgeleitete Lernziel ähnelt der Kombination von InfoNCE mit dem standardmäßigen binären Kreuzentropieverlust, angewendet auf positive und negative Stichprobenpaare.
- Explizites Ziel: Sowohl InfoNCE-basierte als auch JS-basierte Ziele zielen darauf ab, die geschätzte Untergrenze der gegenseitigen Information zu maximieren, um die gegenseitige Information selbst zu maximieren, was theoretisch garantiert ist. Darüber hinaus gibt es explizite Ziele, wie z. B. die Minimierung des mittleren quadratischen Fehlers oder die Maximierung der Kosinusähnlichkeit innerhalb eines Stichprobenpaars, um Paare positiver Stichproben direkt auszurichten. Diese Ziele werden explizite Ziele genannt.
3.2 Generatives Lernen in Empfehlungssystemen

Beim generativen selbstüberwachten Lernen besteht das Hauptziel darin, die Wahrscheinlichkeitsschätzung der realen Datenverteilung zu maximieren. Dadurch können die erlernten, aussagekräftigen Darstellungen die zugrunde liegende Struktur und Muster in den Daten erfassen, die dann in nachgelagerten Aufgaben verwendet werden können. In unserem Klassifizierungssystem berücksichtigen wir zwei Aspekte, um verschiedene auf generativem Lernen basierende Empfehlungsmethoden zu unterscheiden: generatives Lernparadigma und generatives Ziel.
Generatives Lernparadigma. Im Kontext der Empfehlung können selbstüberwachte Methoden, die generatives Lernen verwenden, in drei Paradigmen eingeteilt werden:
- Maskiertes Autoencoding: Bei maskierten Autoencodern folgt das Lernen einem Maskenrekonstruktionsansatz, bei dem die Das Modell rekonstruiert vollständige Daten aus Teilbeobachtungen.
- Variative Autokodierung: Variational Autoencoder ist eine weitere Generierungsmethode, die die Wahrscheinlichkeitsschätzung maximiert und theoretische Garantien bietet. Typischerweise geht es darum, Eingabedaten auf latente Faktoren abzubilden, die einer Gaußschen Normalverteilung folgen. Das Modell rekonstruiert dann die Eingabedaten basierend auf den abgetasteten latenten Faktoren.
- Entrauschte Diffusion: Entrauschte Diffusion ist ein generatives Modell, das durch Umkehrung des Rauschprozesses neue Datenproben generiert. Im Vorwärtsprozess wird Gaußsches Rauschen zu den Originaldaten hinzugefügt und über mehrere Schritte wird eine Reihe verrauschter Versionen erstellt. Während des umgekehrten Vorgangs lernt das Modell, Rauschen aus der verrauschten Version zu entfernen und stellt so nach und nach die ursprünglichen Daten wieder her.
Generation Target. Beim generativen Lernen ist die Frage, welches Datenmuster als generierte Bezeichnung betrachtet wird, ein weiterer Punkt, der berücksichtigt werden muss, um aussagekräftige selbstüberwachte Hilfssignale zu liefern. Im Allgemeinen variieren die Generierungsziele für verschiedene Methoden und in verschiedenen Empfehlungsszenarien. Beispielsweise können bei einer Sequenzempfehlung die Elemente in der Sequenz das Generierungsziel sein, um die Beziehung zwischen Elementen in der Sequenz zu simulieren. Bei der interaktiven Diagrammempfehlung können die Generierungsziele Knoten/Kanten im Diagramm sein, um topologische Korrelationen auf hoher Ebene im Diagramm zu erfassen.
3.3 Adversarial Learning in empfohlenen Systemen
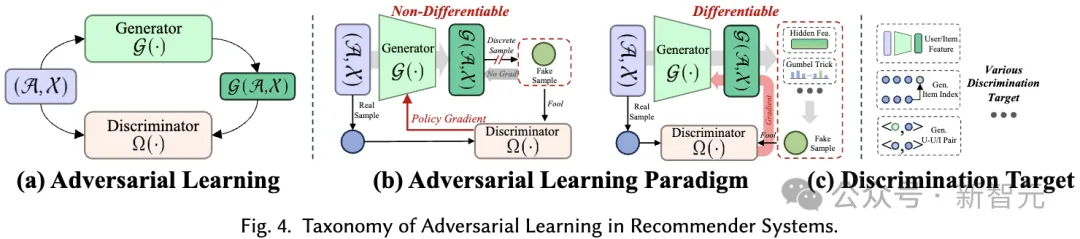
Beim kontradiktorischen Lernen von Empfehlungssystemen spielt der Diskriminator eine entscheidende Rolle bei der Unterscheidung der generierten Fake-Samples von echten Samples. Ähnlich wie beim generativen Lernen deckt das von uns vorgeschlagene Klassifizierungssystem kontroverse Lernmethoden in Empfehlungssystemen aus zwei Perspektiven ab: Lernparadigma und Diskriminierungsziel:
Gegnerisches Lernparadigma. In Empfehlungssystemen besteht kontradiktorisches Lernen aus zwei verschiedenen Paradigmen, je nachdem, ob der diskriminierende Verlust des Diskriminators auf differenzierbare Weise auf den Generator zurückpropagiert werden kann.
- Differenzierbares kontradiktorisches Lernen (Differenzierbares AL): Die erste Methode umfasst Objekte, die in einem kontinuierlichen Raum dargestellt werden, und der Gradient des Diskriminators kann zur Optimierung auf natürliche Weise an den Generator zurückpropagiert werden. Dieser Ansatz wird als differenzierbares kontradiktorisches Lernen bezeichnet.
- Nicht differenzierbares kontradiktorisches Lernen (nicht differenzierbares AL): Eine andere Methode besteht darin, die Ausgabe des Empfehlungssystems zu identifizieren, insbesondere die empfohlenen Produkte. Da die Empfehlungsergebnisse jedoch diskret sind, wird die Rückausbreitung zu einer Herausforderung und führt zu einem nicht differenzierbaren Fall, in dem der Gradient des Diskriminators nicht direkt an den Generator weitergegeben werden kann. Um dieses Problem zu lösen, werden Reinforcement Learning und Policy Gradient eingeführt. In diesem Fall fungiert der Generator als Agent, der mit der Umgebung interagiert, indem er Waren auf der Grundlage früherer Interaktionen vorhersagt. Der Diskriminator fungiert als Belohnungsfunktion und liefert ein Belohnungssignal, um das Lernen des Generators zu steuern. Die Belohnung des Diskriminators ist so definiert, dass sie verschiedene Faktoren hervorhebt, die sich auf die Empfehlungsqualität auswirken, und ist so optimiert, dass realen Stichproben höhere Belohnungen zugewiesen werden als generierten Stichproben, wodurch der Generator dazu angeleitet wird, qualitativ hochwertige Empfehlungen zu erstellen.
Diskriminierungsziel. Unterschiedliche Empfehlungsalgorithmen bewirken, dass der Generator unterschiedliche Eingaben generiert, die dann zur Unterscheidung an den Diskriminator weitergeleitet werden. Dieser Prozess zielt darauf ab, die Fähigkeit des Generators zu verbessern, qualitativ hochwertige Inhalte zu produzieren, die näher an der Realität sind. Auf der Grundlage konkreter Empfehlungsaufgaben werden konkrete Diskriminierungsziele entworfen. 3.4 Verschiedene Empfehlungsszenarien Weitere Informationen finden Sie im Artikel):
Allgemeine kollaborative Filterung (Allgemeine kollaborative Filterung) – Dies ist die grundlegendste Form des Empfehlungssystems, das hauptsächlich auf den Interaktionsdaten zwischen Benutzern und Elementen basiert, um Persönlichkeitsempfehlungen zu generieren.
Sequentielle Empfehlung (Sequentielle Empfehlung) – Berücksichtigen Sie die Zeitreihe der Benutzerinteraktion mit Elementen, um das nächste mögliche interaktive Element des Benutzers vorherzusagen.
Soziale Empfehlung – Kombiniert Benutzerbeziehungsinformationen in sozialen Netzwerken, um personalisiertere Empfehlungen bereitzustellen.
- Wissensbasierte Empfehlung – Nutzen Sie strukturiertes Wissen wie Wissensgraphen, um die Leistung von Empfehlungssystemen zu verbessern.
- Domainübergreifende Empfehlung – Übernehmen Sie Benutzerpräferenzen, die Sie von einer Domain gelernt haben, auf eine andere Domain, um die Empfehlungsergebnisse zu verbessern.
- Gruppenempfehlung – Geben Sie Empfehlungen für Gruppen mit gemeinsamen Merkmalen oder Interessen und nicht für einzelne Benutzer.
- Bundle-Empfehlung – Empfehlen Sie eine Gruppe von Artikeln als Ganzes, normalerweise für Werbeaktionen oder Paketdienste.
- Empfehlung mit mehreren Verhaltensweisen (Empfehlung mit mehreren Verhaltensweisen) – Berücksichtigen Sie die vielfältigen interaktiven Verhaltensweisen des Benutzers bei Elementen, wie z. B. Durchsuchen, Kaufen, Bewerten usw.
- Multimodale Empfehlung – Kombiniert mehrere modale Informationen von Elementen, wie Text, Bilder, Töne usw., um umfassendere Empfehlungen bereitzustellen.
- 4 Fazit
- Dieser Artikel bietet einen umfassenden Überblick über die Anwendung von selbstüberwachtem Lernen (SSL) in Empfehlungssystemen mit einer detaillierten Analyse von mehr als 170 Artikeln. Wir haben ein selbstüberwachtes Klassifizierungssystem vorgeschlagen, das neun Empfehlungsszenarien abdeckt, drei SSL-Paradigmen des kontrastiven Lernens, des generativen Lernens und des kontradiktorischen Lernens im Detail diskutiert und in dem Artikel zukünftige Forschungsrichtungen erörtert.
- Wir betonen die Bedeutung von SSL für den Umgang mit Datenknappheit und die Verbesserung der Leistung von Empfehlungssystemen und weisen auf das Potenzial der Integration großer Sprachmodelle in Empfehlungssysteme, adaptiver dynamischer Empfehlungsumgebungen und der Schaffung einer theoretischen Grundlage für das SSL-Paradigma hin . Forschungsrichtung. Wir hoffen, dass dieser Review wertvolle Ressourcen für Forscher bereitstellen, neue Forschungsideen inspirieren und die Weiterentwicklung von Empfehlungssystemen fördern kann.
Das obige ist der detaillierte Inhalt vonHKU überprüft 170 Empfehlungsalgorithmen für „selbstüberwachtes Lernen' und veröffentlicht SSL4Rec: Der Code und die Datenbank sind vollständig Open Source!. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Das neueste Registrierungsportal für die offizielle Website von Ouyi 2025
Mar 21, 2025 pm 05:57 PM
Das neueste Registrierungsportal für die offizielle Website von Ouyi 2025
Mar 21, 2025 pm 05:57 PM
2025 Ouyi OKX Registrierungseintrittsprognose und Sicherheitsleitfaden: Verstehen Sie den zukünftigen Registrierungsprozess im Voraus und beschlagnahmen Sie die Initiative im Handel mit digitalem Vermögen! Dieser Artikel sagt voraus, dass die Registrierung von Ouyi OKX im Jahr 2025 die KYC-Zertifizierung stärken, regionale Registrierungsverfahren implementieren und Sicherheitsmaßnahmen wie Multi-Faktor-Identitätsüberprüfung und Geräte-Fingerabdruckerkennung stärken wird. Um eine sichere Registrierung zu gewährleisten, greifen Sie auf die Website über offizielle Kanäle zu, legen Sie ein starkes Passwort fest, aktivieren Sie die Zwei-Faktor-Überprüfung und achten Sie auf Phishing-Websites und E-Mails. Nur durch das Verständnis des Registrierungsprozesses im Voraus und zur Verhinderung von Risiken können Sie bei zukünftigen digitalen Asset -Transaktionen einen Vorteil erzielen. Lesen Sie jetzt und beherrschen Sie die Geheimnisse von Ouyi OKX Registrierung im Jahr 2025!
 Top 10 offizielle Handel mit virtuellen Währungshandel -Apps Top 10 offizielle offizielle Handelsplattformen für virtuelle Währung für Mobiltelefone
Mar 19, 2025 pm 05:21 PM
Top 10 offizielle Handel mit virtuellen Währungshandel -Apps Top 10 offizielle offizielle Handelsplattformen für virtuelle Währung für Mobiltelefone
Mar 19, 2025 pm 05:21 PM
Top 10 offizielle Apps für virtuelle Währung Handel: 1. OKX, 2. Binance, 3. Gate.io, 4. Kraken, 5. Huobi, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini. Sicherheit, Liquidität, Handhabungsgebühren, Währungsauswahl, Benutzeroberfläche und Kundenbetreuung sollten bei der Auswahl einer Plattform berücksichtigt werden.
 Die neuesten Ranglisten der Top Ten Ten Virtual Currency App -Austausch im Währungskreis 2025
Mar 27, 2025 pm 07:27 PM
Die neuesten Ranglisten der Top Ten Ten Virtual Currency App -Austausch im Währungskreis 2025
Mar 27, 2025 pm 07:27 PM
Die Top Ten Apps Virtual Currency Trading Apps im Jahr 2025 sind wie folgt: 1. OKX, 2. Binance, 3. Gate.io, 4. Bybit, 5. Kraken, 6. Kucoin, 7. Bitget, 8. Htx, 9. Mexc, 10. Coinbase. Dieses Ranking basiert auf umfassenden Bewertungen wie Sicherheit, Liquidität, Benutzererfahrung und Merkmalsreichtum.
 Wann wurde Bitcoin ausgestellt?
Mar 20, 2025 pm 05:21 PM
Wann wurde Bitcoin ausgestellt?
Mar 20, 2025 pm 05:21 PM
Am 3. Januar 2009 wurde Bitcoin auf einem kleinen Server in Helsinki, Finnland, geboren. Satoshi Nakamoto grub den ersten Block aus - den "Erstellungsblock" und erhielt 50 Bitcoin -Belohnungen. Der Genesis -Block enthält den Text "The Times 03/Jan/2009 Kanzler für Kompromisse der zweiten Rettungsaktion für Banken", was seine Geburtszeit bestätigt und die globale Finanzkrise zu diesem Zeitpunkt impliziert. In diesem Artikel wird der Mainstream -Bitcoin -Austausch im Jahr 2025 wie Ouyi OKX, Binance, Gateio Sesam Open Door und Bitget untersucht.
 Top 10 Digital Currency Exchange Ranking Neueste App Virtual Digital Currency Trading Platform App
Mar 25, 2025 pm 06:21 PM
Top 10 Digital Currency Exchange Ranking Neueste App Virtual Digital Currency Trading Platform App
Mar 25, 2025 pm 06:21 PM
Ranking of the top ten trading platforms digital currency apps: 1. OKX, 2. Binance, 3. Gate.io, 4. Coinbase, 5. Kraken, 6. Huobi, 7. KuCoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, when choosing transactions, you need to consider security, fees, currency selection, user experience, customer support and supervision, and investment should be cautious.
 Eine Zusammenfassung der zehn besten Apps für virtuelle Währung von Virtual Currency Exchange im Jahr 2025
Mar 27, 2025 pm 07:18 PM
Eine Zusammenfassung der zehn besten Apps für virtuelle Währung von Virtual Currency Exchange im Jahr 2025
Mar 27, 2025 pm 07:18 PM
Die zehn Top -Apps für digitale Virtual Currency Trading im Jahr 2025 sind wie folgt: 1. OKX, 2. Binance, 3. Gate.io, 4. Bybit, 5. Kraken, 6. Kucoin, 7. Bitget, 8. Htx, 9. Mexc, 10. Coinbase. Dieses Ranking basiert auf umfassenden Bewertungen wie Sicherheit, Liquidität, Benutzererfahrung und Merkmalsreichtum.
 Top 10 Ranglisten einfach zu bediener virtueller Währungshandelsplattformen im Währungskreis
Mar 20, 2025 pm 04:00 PM
Top 10 Ranglisten einfach zu bediener virtueller Währungshandelsplattformen im Währungskreis
Mar 20, 2025 pm 04:00 PM
Ranking von Apps für virtuelle Währungshandel im Währungskreis: 1. OKX, 2. Binance, 3. Gate.io, 4. Huobi Global, 5. Kraken, 6. Coinbase, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, Bei der Auswahl einer Plattform.
 Top 10 Apps für Währungshandelssoftware 2025 Top 10 Top 10 Apps Ranking Virtual Currency Trading Apps
Mar 25, 2025 pm 05:57 PM
Top 10 Apps für Währungshandelssoftware 2025 Top 10 Top 10 Apps Ranking Virtual Currency Trading Apps
Mar 25, 2025 pm 05:57 PM
Top 10 Apps Rankings von Virtual Currency Trading: 1. OKX, 2. Binance, 3. Gate.io, 4. Coinbase, 5. Kraken, 6. Huobi, 7. Kucoin, 8. Crypto.com, 9. Bitfinex, 10. Gemini, bei der Auswahl von Transaktionen.
