

python实现带验证码网站的自动登陆实现代码

早听说用python做网络爬虫非常方便,正好这几天单位也有这样的需求,需要登陆XX网站下载部分文档,于是自己亲身试验了一番,效果还不错。
本例所登录的某网站需要提供用户名,密码和验证码,在此使用了python的urllib2直接登录网站并处理网站的Cookie。
Cookie的工作原理:
Cookie由服务端生成,然后发送给浏览器,浏览器会将Cookie保存在某个目录下的文本文件中。在下次请求同一网站时,会发送该Cookie给服务器,这样服务器就知道该用户是否合法以及是否需要重新登录。
Python提供了基本的cookielib库,在首次访问某页面时,cookie便会自动保存下来,之后访问其它页面便都会带有正常登录的Cookie了。
原理:
(1)激活cookie功能
(2)反“反盗链”,伪装成浏览器访问
(3)访问验证码链接,并将验证码图片下载到本地
(4)验证码的识别方案网上较多,python也有自己的图像处理库,此例调用了火车头采集器的OCR识别接口。
(5)表单的处理,可用fiddler等抓包工具获取需要提交的参数
(6)生成需要提交的数据,生成http请求并发送
(7)根据返回的js页面判断是否登陆成功
(8)登陆成功后下载其它页面
此例中使用多个账号轮询登陆,每个账号下载3个页面。
下载网址因为某些问题,就不透露了。
以下是部分代码:
#!usr/bin/env python
#-*- coding: utf-8 -*-
import os
import urllib2
import urllib
import cookielib
import xml.etree.ElementTree as ET
#-----------------------------------------------------------------------------
# Login in www.***.com.cn
def ChinaBiddingLogin(url, username, password):
# Enable cookie support for urllib2
cookiejar=cookielib.CookieJar()
urlopener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cookiejar))
urllib2.install_opener(urlopener)
urlopener.addheaders.append(('Referer', 'http://www.chinabidding.com.cn/zbw/login/login.jsp'))
urlopener.addheaders.append(('Accept-Language', 'zh-CN'))
urlopener.addheaders.append(('Host', 'www.chinabidding.com.cn'))
urlopener.addheaders.append(('User-Agent', 'Mozilla/5.0 (compatible; MISE 9.0; Windows NT 6.1); Trident/5.0'))
urlopener.addheaders.append(('Connection', 'Keep-Alive'))
print 'XXX Login......'
imgurl=r'http://www.*****.com.cn/zbw/login/image.jsp'
DownloadFile(imgurl, urlopener)
authcode=raw_input('Please enter the authcode:')
#authcode=VerifyingCodeRecognization(r"http://192.168.0.106/images/code.jpg")
# Send login/password to the site and get the session cookie
values={'login_id':username, 'opl':'op_login', 'login_passwd':password, 'login_check':authcode}
urlcontent=urlopener.open(urllib2.Request(url, urllib.urlencode(values)))
page=urlcontent.read(500000)
# Make sure we are logged in, check the returned page content
if page.find('login.jsp')!=-1:
print 'Login failed with username=%s, password=%s and authcode=%s' \
% (username, password, authcode)
return False
else:
print 'Login succeeded!'
return True
#-----------------------------------------------------------------------------
# Download from fileUrl then save to fileToSave
# Note: the fileUrl must be a valid file
def DownloadFile(fileUrl, urlopener):
isDownOk=False
try:
if fileUrl:
outfile=open(r'/var/www/images/code.jpg', 'w')
outfile.write(urlopener.open(urllib2.Request(fileUrl)).read())
outfile.close()
isDownOK=True
else:
print 'ERROR: fileUrl is NULL!'
except:
isDownOK=False
return isDownOK
#------------------------------------------------------------------------------
# Verifying code recoginization
def VerifyingCodeRecognization(imgurl):
url=r'http://192.168.0.119:800/api?'
user='admin'
pwd='admin'
model='ocr'
ocrfile='cbi'
values={'user':user, 'pwd':pwd, 'model':model, 'ocrfile':ocrfile, 'imgurl':imgurl}
data=urllib.urlencode(values)
try:
url+=data
urlcontent=urllib2.urlopen(url)
except IOError:
print '***ERROR: invalid URL (%s)' % url
page=urlcontent.read(500000)
# Parse the xml data and get the verifying code
root=ET.fromstring(page)
node_find=root.find('AddField')
authcode=node_find.attrib['data']
return authcode
#------------------------------------------------------------------------------
# Read users from configure file
def ReadUsersFromFile(filename):
users={}
for eachLine in open(filename, 'r'):
info=[w for w in eachLine.strip().split()]
if len(info)==2:
users[info[0]]=info[1]
return users
#------------------------------------------------------------------------------
def main():
login_page=r'http://www.***.com.cnlogin/login.jsp'
download_page=r'http://www.***.com.cn***/***?record_id='
start_id=8593330
end_id=8595000
now_id=start_id
Users=ReadUsersFromFile('users.conf')
while True:
for key in Users:
if ChinaBiddingLogin(login_page, key, Users[key]):
for i in range(3):
pageUrl=download_page+'%d' % now_id
urlcontent=urllib2.urlopen(pageUrl)
filepath='./download/%s.html' % now_id
f=open(filepath, 'w')
f.write(urlcontent.read(500000))
f.close()
now_id+=1
else:
continue
#------------------------------------------------------------------------------
if __name__=='__main__':
main()
Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

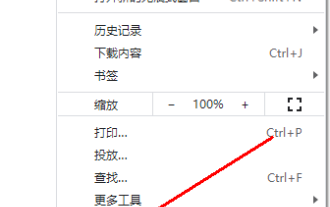 Was soll ich tun, wenn Google Chrome das Bild des Bestätigungscodes nicht anzeigt? Der Chrome-Browser zeigt den Bestätigungscode nicht an?
Mar 13, 2024 pm 08:55 PM
Was soll ich tun, wenn Google Chrome das Bild des Bestätigungscodes nicht anzeigt? Der Chrome-Browser zeigt den Bestätigungscode nicht an?
Mar 13, 2024 pm 08:55 PM
Was soll ich tun, wenn Google Chrome das Bild des Bestätigungscodes nicht anzeigt? Manchmal benötigen Sie einen Bestätigungscode, um sich mit Google Chrome auf einer Webseite anzumelden. Einige Nutzer stellen fest, dass Google Chrome den Inhalt des Bildes bei Verwendung von Bildbestätigungscodes nicht richtig anzeigen kann. Was soll getan werden? Der folgende Editor erklärt, wie man damit umgeht, dass der Google Chrome-Bestätigungscode nicht angezeigt wird. Ich hoffe, dass er für alle hilfreich ist. Einführung in die Methode: 1. Rufen Sie die Software auf, klicken Sie oben rechts auf die Schaltfläche „Mehr“ und wählen Sie zum Aufrufen in der Optionsliste unten „Einstellungen“ aus. 2. Nachdem Sie die neue Benutzeroberfläche aufgerufen haben, klicken Sie links auf die Option „Datenschutzeinstellungen und Sicherheit“. 3. Klicken Sie dann rechts auf „Website-Einstellungen“.
 Warum kann ich den Bestätigungscode nicht auf meinem Telefon empfangen?
Aug 17, 2023 pm 02:49 PM
Warum kann ich den Bestätigungscode nicht auf meinem Telefon empfangen?
Aug 17, 2023 pm 02:49 PM
Wenn Sie den Bestätigungscode nicht auf Ihrem Mobiltelefon erhalten, kann dies auf Netzwerkprobleme, Probleme mit den Mobiltelefoneinstellungen, Probleme mit dem Mobilfunkbetreiber und Probleme mit den persönlichen Einstellungen zurückzuführen sein. Detaillierte Einführung: 1. Die Netzwerkumgebung, in der sich das Mobiltelefon befindet, ist instabil oder das Signal ist schwach, was dazu führen kann, dass der Bestätigungscode nicht rechtzeitig übermittelt werden kann. 2. Probleme mit der Mobiltelefoneinstellung oder die Sprachfunktion des Mobiltelefons wurde versehentlich ausgeschaltet oder die Sendenummer des Bestätigungscodes wurde zur schwarzen Liste hinzugefügt, was dazu führte, dass der Bestätigungscode nicht normal empfangen wurde. 3. Möglicherweise hat der Mobilfunkanbieter Probleme Fehlfunktionen oder Wartungsarbeiten, die dazu führen, dass der Verifizierungscode nicht rechtzeitig geliefert wird usw.
 Können virtuelle Nummern Verifizierungscodes erhalten?
Jan 02, 2024 am 10:22 AM
Können virtuelle Nummern Verifizierungscodes erhalten?
Jan 02, 2024 am 10:22 AM
Die virtuelle Nummer kann den Bestätigungscode empfangen. Solange die bei der Registrierung eingegebene Mobiltelefonnummer den Vorschriften entspricht und die Mobiltelefonnummer normal verbunden werden kann, können Sie den SMS-Verifizierungscode erhalten. Allerdings müssen Sie bei der Verwendung virtueller Mobiltelefonnummern vorsichtig sein. Einige Websites unterstützen die Registrierung virtueller Mobiltelefonnummern nicht, daher müssen Sie einen regulären Anbieter für virtuelle Mobiltelefonnummern wählen.
 Fall der PHP-Bildverarbeitung: So implementieren Sie die Verifizierungscodefunktion von Bildern
Aug 17, 2023 pm 12:09 PM
Fall der PHP-Bildverarbeitung: So implementieren Sie die Verifizierungscodefunktion von Bildern
Aug 17, 2023 pm 12:09 PM
Fall der PHP-Bildverarbeitung: So implementieren Sie die Verifizierungscodefunktion von Bildern Mit der rasanten Entwicklung des Internets sind Verifizierungscodes zu einem wichtigen Mittel zum Schutz der Website-Sicherheit geworden. Der Verifizierungscode ist eine Verifizierungsmethode, die mithilfe der Bilderkennungstechnologie ermittelt, ob der Benutzer ein echter Benutzer ist. In diesem Artikel wird erläutert, wie Sie mit PHP die Verifizierungscodefunktion von Bildern implementieren, und es werden Codebeispiele bereitgestellt. Einleitung Ein Verifizierungscode ist ein Bild mit zufälligen Zeichen. Der Benutzer muss die Zeichen im Bild eingeben, um die Verifizierung zu bestehen. Der Hauptprozess der Implementierung des Verifizierungscodes umfasst die Generierung zufälliger Zeichen und das Zeichnen von Zeichen in Bilder.
 PHP-Entwicklungshandbuch: Implementierung des Verifizierungscode-Logins
Jul 01, 2023 am 09:27 AM
PHP-Entwicklungshandbuch: Implementierung des Verifizierungscode-Logins
Jul 01, 2023 am 09:27 AM
Mit der Entwicklung des Internets und der Popularität von Smartphones wird die Anmeldefunktion mit Bestätigungscode von immer mehr Websites und Anwendungen übernommen. Bei der Anmeldung mit Bestätigungscode handelt es sich um eine Anmeldemethode, die die Identität des Benutzers durch Eingabe des richtigen Bestätigungscodes überprüft, um die Sicherheit zu verbessern und böswillige Angriffe zu verhindern. In der PHP-Entwicklung ist die Implementierung einer einfachen Anmeldefunktion mit Bestätigungscode nicht kompliziert und kann durch die folgenden Schritte abgeschlossen werden. Erstellen Sie eine Datenbanktabelle. Zuerst müssen wir eine Tabelle in der Datenbank erstellen, um Informationen zum Bestätigungscode zu speichern. Die Tabellenstruktur kann die folgenden Felder enthalten: id: automatisch inkrementierender Primärschlüssel phon
 Verifizierungscodes können Roboter nicht aufhalten! Google AI kann verschwommenen Text genau identifizieren, während GPT-4 vorgibt, blind zu sein und um Hilfe bittet
Apr 12, 2023 am 09:46 AM
Verifizierungscodes können Roboter nicht aufhalten! Google AI kann verschwommenen Text genau identifizieren, während GPT-4 vorgibt, blind zu sein und um Hilfe bittet
Apr 12, 2023 am 09:46 AM
„Das Ärgerlichste sind alle möglichen seltsamen (oder sogar perversen) Bestätigungscodes, wenn man sich auf einer Website anmeldet.“ Nun gibt es gute und schlechte Nachrichten. Die gute Nachricht ist: KI kann das für Sie erledigen. Wenn Sie mir nicht glauben, hier sind drei reale Fälle von zunehmenden Erkennungsschwierigkeiten: Und das sind die Antworten, die ein Modell namens „Pix2Struct“ gibt: Sind sie alle korrekt und Wort für Wort? Einige Internetnutzer beklagten: Sicher, die Genauigkeit ist besser als meine. Kann es also in ein Browser-Plug-in umgewandelt werden? ? Ja, einige Leute sagten: Auch wenn diese Fälle relativ einfach sind, kann ich mir nicht vorstellen, wie stark der Effekt sein wird, wenn man sie nur verfeinert. Die schlechte Nachricht ist also: Der Bestätigungscode wird die Roboter bald nicht mehr stoppen können! (Gefahr Gefahr Gefahr...) Wie geht das? Pix2St
 Wie erstelle ich ein Verifizierungscode-Bild mit PHP?
Sep 13, 2023 am 11:40 AM
Wie erstelle ich ein Verifizierungscode-Bild mit PHP?
Sep 13, 2023 am 11:40 AM
Wie erstelle ich ein Verifizierungscode-Bild mit PHP? CAPTCHA ist eine häufig verwendete Methode, um zu überprüfen, ob der Benutzer ein Mensch und keine Maschine ist. Auf Websites sehen wir häufig Bilder von Verifizierungscodes, bei denen Benutzer zufällige Zeichen oder Zahlen eingeben müssen, die auf dem Bild angezeigt werden, um Vorgänge wie Anmeldung, Registrierung und Kommentieren abzuschließen. In diesem Artikel wird erläutert, wie Sie mit PHP ein Verifizierungscodebild erstellen, und es werden spezifische Codebeispiele bereitgestellt. 1. PHPGD-Bibliothek Um ein Verifizierungscode-Bild zu erstellen, müssen wir die GD-Bibliothek von PHP verwenden. Die GD-Bibliothek ist eine Erweiterung zur Bildverarbeitung.
 Was passiert, wenn ich Verifizierungscodes von verschiedenen Plattformen auf meinem Mobiltelefon erhalte?
Sep 21, 2023 pm 03:31 PM
Was passiert, wenn ich Verifizierungscodes von verschiedenen Plattformen auf meinem Mobiltelefon erhalte?
Sep 21, 2023 pm 03:31 PM
Der Empfang von Bestätigungscodes von verschiedenen Plattformen auf Ihrem Mobiltelefon kann darauf zurückzuführen sein, dass Ihre persönlichen Daten gestohlen wurden, Ihre Mobiltelefonnummer missbraucht wurde oder Ihre Mobiltelefonnummer falsch eingegeben oder missbraucht wurde. Ausführliche Einführung: 1. Persönliche Daten wurden gestohlen und können über verschiedene Kanäle an Ihre persönlichen Daten gelangen und diese Informationen dann verwenden, um Konten auf verschiedenen Plattformen zu registrieren. 2. Mobiltelefonnummern wurden missbraucht, und einige Kriminelle verwenden A Eine große Anzahl von Mobiltelefonnummern wird auf verschiedene Weise erlangt und dann werden diese Mobiltelefonnummern für verschiedene betrügerische Aktivitäten verwendet. 3. Mobiltelefonnummern werden falsch eingegeben oder missbraucht usw.
