

你写过的最好的 Python 脚本是什么?

源自:Python (programming language): What are the best Python scripts you've ever written?
想看到更多的更酷的东西 :- |
回复内容:
我们公司办公环境是window,开发环境是unix(可以近似认为所有人工作在同一台机器上,大部分人的目录权限都是755。。。),为了防止开发代码流出到外网,windows与unix之间没有网络连接,我们只能远程登陆到一个跳转服务器再远程登陆到unix上,如果有unix网内的文件需要传出到windows网中,需要领导严格审批(反方向没问题,有专用ftp服务器)。对于通信专业毕业的我,最不能忍受的场景就是没有建立起双向通信。于是,为了可以将unix网内的数据传出来,我用python将二进制数据转化为图像,每个像素点可以表示3个字节,再将图像外围增加宽度为1的黑色边框,外面再增加宽度为1像素的白色边框,作为图像边界的标识符。这样,我在windows下截图,用python进行逆操作,数据就完好的解出来了!这样一次至少可以传1MB多的文件(屏幕越大传的越多),7z压缩一下,可以传很多文本了。如果需要传更多,还可以搞成动画。。。脚本一共只有几十行,却大大提高了我后来工作的效率。python好爽,我爱python! 说两个和知乎相关的。因为我本人并不认可“问题是大家的”的观点,对每个人都可以编辑问题这个设定表示接受但不认同。所以每次看到有好事者把问题原题改得面目全非的时候,感觉就像吃了死苍蝇一样恶心。(虽然有问题日志,但是大多数群众不会去看。)
终于有一天,我被某人恶心得受不了了,就用python写了一个脚本:对于某个问题,每10秒刷新一次,当发现有人把问题改动得和设想的不一样,那就再自动改回来——这不是什么过激手段,也只不过利用规则而已。这个脚本至今用过两次,看日志,着实恶心到了几个所谓“公共编辑计划”的同学——想象下,偷偷摸摸凌晨两三点修改问题,不到10秒就被改回原样,那种抓狂的表情。
另一个例子,我本人喜欢关注妹子,所以关注的人很多,这样带来几个问题:一个是tl太杂,一个是逼格不够高。所以需要定时清理一下。于是写脚本抓取了所以关注人的性别、问题数、赞同数、近期活跃时间等等特征,然后提取一百个作为训练数据,人工标注是否需要取关,再使用线性模型训练,判断哪些关注的价值比较低,好定期清理。(目前还没有清理过,因为还在对关注者价值机器学习的结果进行评估。)
作为程序员,自娱自乐还是有些意思的,python干这些很顺手。 想起以前和沈游侠聊天的一个笑话
代码开始 True, False = False, True
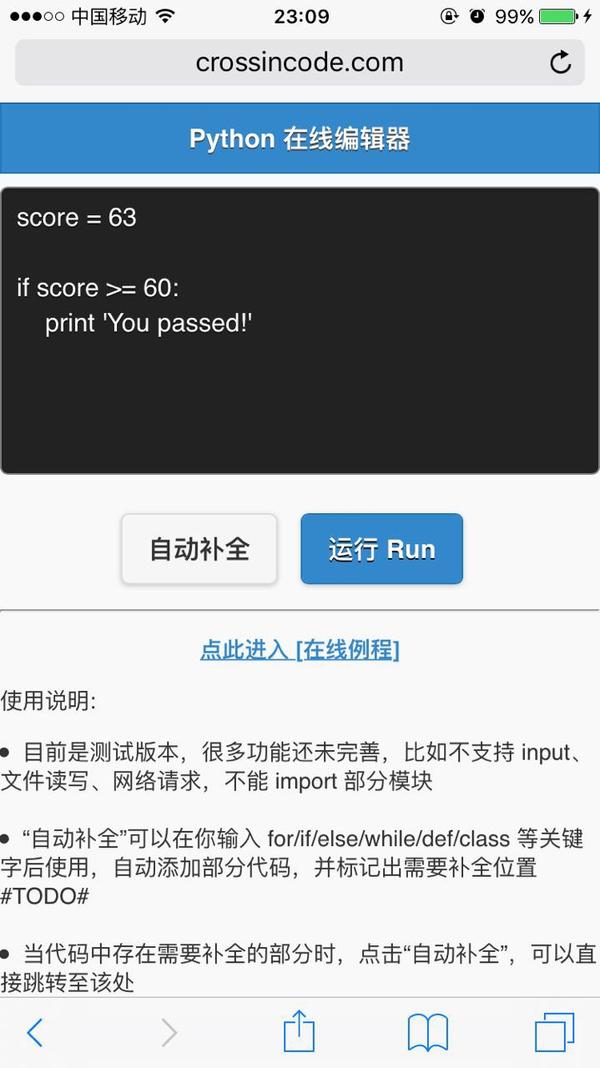
然后开始写 Python 程序 谢邀。当年玩 http://projecteuler.net/ 的时候写过一些很鸡贼的小脚本,有兴趣可以看看 https://github.com/riobard/project-euler/blob/master/euler.py Python 在线编辑器
这是我用 python 写的一个可以在网页上编写并执行 python 代码的编辑器。支持基本的语法和模块。但出于安全考虑(当然也因为没怎么去完善),功能还比较受限。
写代码的时候可以自动补全,不过这是js的事情,跟python无关。
两年多前写的,最近又稍微优化了一下,增加了几个语法和模块的支持。另外增加了几十个教学例程。做这个的目的是想方便公众号读者在微信里面直接试验代码。
 不到两百行代码实现goagent
GitHub - larva-lang/larva-lang: The larva programming Language
确认安装好urllib2和webscraping库,然后粘贴此代码到pythonIDE里运行,过一会儿打开d盘的f.txt 你懂的!
不到两百行代码实现goagent
GitHub - larva-lang/larva-lang: The larva programming Language
确认安装好urllib2和webscraping库,然后粘贴此代码到pythonIDE里运行,过一会儿打开d盘的f.txt 你懂的!<span class="c"># -*- coding: UTF-8 -*-</span>
<span class="n">__author__</span> <span class="o">=</span> <span class="s">'ftium4.com'</span>
<span class="c">#导入urllib2库,用于获取网页</span>
<span class="kn">import</span> <span class="nn">urllib2</span>
<span class="c">#使用开源库webscraping库的xpath模块</span>
<span class="kn">from</span> <span class="nn">webscraping</span> <span class="kn">import</span> <span class="n">xpath</span><span class="p">,</span><span class="n">common</span>
<span class="k">def</span> <span class="nf">get_data</span><span class="p">(</span><span class="n">url</span><span class="p">):</span>
<span class="n">req</span> <span class="o">=</span> <span class="n">urllib2</span><span class="o">.</span><span class="n">Request</span><span class="p">(</span><span class="n">url</span><span class="p">)</span>
<span class="n">req</span><span class="o">.</span><span class="n">add_header</span><span class="p">(</span><span class="s">'User-Agent'</span><span class="p">,</span> <span class="s">'Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.14) Gecko/20080404 (FoxPlus) Firefox/2.0.0.14'</span><span class="p">)</span>
<span class="c">#获得响应</span>
<span class="n">reponse</span> <span class="o">=</span> <span class="n">urllib2</span><span class="o">.</span><span class="n">urlopen</span><span class="p">(</span><span class="n">req</span><span class="p">)</span>
<span class="c">#将响应的内容存入html变量</span>
<span class="n">html</span> <span class="o">=</span> <span class="n">reponse</span><span class="o">.</span><span class="n">read</span><span class="p">()</span>
<span class="c">#以下抓取页面的番号和片名</span>
<span class="n">title</span> <span class="o">=</span> <span class="n">xpath</span><span class="o">.</span><span class="n">search</span><span class="p">(</span><span class="n">html</span><span class="p">,</span> <span class="s">'//div[@class="av style1"]/a[1]/@title'</span><span class="p">)</span>
<span class="k">return</span> <span class="n">title</span>
<span class="c">#创建文本用于保存采集结果</span>
<span class="n">f</span><span class="o">=</span><span class="nb">open</span><span class="p">(</span><span class="s">r'D:\f.txt'</span><span class="p">,</span><span class="s">'w'</span><span class="p">)</span>
<span class="k">for</span> <span class="n">p</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="mi">1</span><span class="p">,</span><span class="mi">494</span><span class="p">):</span>
<span class="n">url</span> <span class="o">=</span> <span class="s">r'http://dmm18.net/index.php?pageno_b=</span><span class="si">%s</span><span class="s">'</span><span class="o">%</span><span class="n">p</span>
<span class="k">print</span> <span class="n">url</span>
<span class="n">title</span> <span class="o">=</span> <span class="n">get_data</span><span class="p">(</span><span class="n">url</span><span class="p">)</span>
<span class="k">for</span> <span class="n">item1</span> <span class="ow">in</span> <span class="n">title</span><span class="p">:</span>
<span class="c">#将采集结果写入文本中</span>
<span class="n">f</span><span class="o">.</span><span class="n">write</span><span class="p">(</span><span class="nb">str</span><span class="p">(</span><span class="n">item1</span><span class="p">)</span><span class="o">+</span><span class="s">'</span><span class="se">\n</span><span class="s">'</span><span class="p">)</span>
<span class="k">print</span> <span class="n">item1</span>
<span class="n">f</span><span class="o">.</span><span class="n">close</span><span class="p">()</span>
脚本地址
https://gist.github.com/zhu327/987f3fc288ca55939e73
xbmc是在树莓派上用的,一般720p+外挂字幕毫无压力,另外附上树莓派用xbmc心得一篇
http://bozpy.sinaapp.com/blog/13 输入动漫名(模糊匹配)和集数,直接获取到下载URL,贴到迅雷马上使用
http://www.kylen314.com/archives/5729

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Eine Anwendung, die XML direkt in PDF konvertiert, kann nicht gefunden werden, da es sich um zwei grundlegend unterschiedliche Formate handelt. XML wird zum Speichern von Daten verwendet, während PDF zur Anzeige von Dokumenten verwendet wird. Um die Transformation abzuschließen, können Sie Programmiersprachen und Bibliotheken wie Python und ReportLab verwenden, um XML -Daten zu analysieren und PDF -Dokumente zu generieren.
 Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Wie konvertiere ich XML -Dateien in PDF auf Ihrem Telefon?
Apr 02, 2025 pm 10:12 PM
Mit einer einzigen Anwendung ist es unmöglich, XML -zu -PDF -Konvertierung direkt auf Ihrem Telefon zu vervollständigen. Es ist erforderlich, Cloud -Dienste zu verwenden, die in zwei Schritten erreicht werden können: 1. XML in PDF in der Cloud, 2. Zugriff auf die konvertierte PDF -Datei auf dem Mobiltelefon konvertieren oder herunterladen.
 Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Die Geschwindigkeit der mobilen XML zu PDF hängt von den folgenden Faktoren ab: der Komplexität der XML -Struktur. Konvertierungsmethode für mobile Hardware-Konfiguration (Bibliothek, Algorithmus) -Codierungsoptimierungsmethoden (effiziente Bibliotheken, Optimierung von Algorithmen, Cache-Daten und Nutzung von Multi-Threading). Insgesamt gibt es keine absolute Antwort und es muss gemäß der spezifischen Situation optimiert werden.
 Wie steuert ich die Größe von XML, die in Bilder konvertiert sind?
Apr 02, 2025 pm 07:24 PM
Wie steuert ich die Größe von XML, die in Bilder konvertiert sind?
Apr 02, 2025 pm 07:24 PM
Um Bilder über XML zu generieren, müssen Sie Grafikbibliotheken (z. B. Kissen und Jfreechart) als Brücken verwenden, um Bilder basierend auf Metadaten (Größe, Farbe) in XML zu generieren. Der Schlüssel zur Steuerung der Bildgröße besteht darin, die Werte der & lt; width & gt; und & lt; Höhe & gt; Tags in XML. In praktischen Anwendungen haben jedoch die Komplexität der XML -Struktur, die Feinheit der Graphenzeichnung, die Geschwindigkeit der Bilderzeugung und des Speicherverbrauchs und die Auswahl der Bildformate einen Einfluss auf die generierte Bildgröße. Daher ist es notwendig, ein tiefes Verständnis der XML -Struktur zu haben, die in der Grafikbibliothek kompetent ist, und Faktoren wie Optimierungsalgorithmen und Bildformatauswahl zu berücksichtigen.
 Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
Empfohlenes XML -Formatierungswerkzeug
Apr 02, 2025 pm 09:03 PM
XML -Formatierungs -Tools können Code nach Regeln eingeben, um die Lesbarkeit und das Verständnis zu verbessern. Achten Sie bei der Auswahl eines Tools auf die Anpassungsfunktionen, den Umgang mit besonderen Umständen, die Leistung und die Benutzerfreundlichkeit. Zu den häufig verwendeten Werkzeugtypen gehören Online-Tools, IDE-Plug-Ins und Befehlszeilen-Tools.
 Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Was ist die Funktion der C -Sprachsumme?
Apr 03, 2025 pm 02:21 PM
Es gibt keine integrierte Summenfunktion in der C-Sprache, daher muss sie selbst geschrieben werden. Die Summe kann erreicht werden, indem das Array durchquert und Elemente akkumulieren: Schleifenversion: Die Summe wird für die Schleifen- und Arraylänge berechnet. Zeigerversion: Verwenden Sie Zeiger, um auf Array-Elemente zu verweisen, und eine effiziente Summierung wird durch Selbststillstandszeiger erzielt. Dynamisch Array -Array -Version zuweisen: Zuordnen Sie Arrays dynamisch und verwalten Sie selbst den Speicher selbst, um sicherzustellen, dass der zugewiesene Speicher befreit wird, um Speicherlecks zu verhindern.
 So öffnen Sie das XML -Format
Apr 02, 2025 pm 09:00 PM
So öffnen Sie das XML -Format
Apr 02, 2025 pm 09:00 PM
Verwenden Sie die meisten Texteditoren, um XML -Dateien zu öffnen. Wenn Sie eine intuitivere Baumanzeige benötigen, können Sie einen XML -Editor verwenden, z. B. Sauerstoff XML -Editor oder XMLSPY. Wenn Sie XML -Daten in einem Programm verarbeiten, müssen Sie eine Programmiersprache (wie Python) und XML -Bibliotheken (z. B. XML.etree.elementtree) verwenden, um zu analysieren.
 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 09:45 PM
Es gibt keine App, die alle XML -Dateien in PDFs umwandeln kann, da die XML -Struktur flexibel und vielfältig ist. Der Kern von XML zu PDF besteht darin, die Datenstruktur in ein Seitenlayout umzuwandeln, für das XML analysiert und PDF generiert werden muss. Zu den allgemeinen Methoden gehören das Parsen von XML mithilfe von Python -Bibliotheken wie ElementTree und das Generieren von PDFs unter Verwendung der ReportLab -Bibliothek. Für komplexe XML kann es erforderlich sein, XSLT -Transformationsstrukturen zu verwenden. Wenn Sie die Leistung optimieren, sollten Sie Multithread- oder Multiprozesse verwenden und die entsprechende Bibliothek auswählen.
