

如何用 Python 中的 NLTK 对中文进行分析和处理?

用nltk对自己的日记进行分析。得到以下结果(节选)
'\xb8\xb0', '\xe5\xbc\xba\xe8\xba', '\xe5\xbd\xbc\xe5', '\xb8\xb4', '\xb8\x8a', '\xb8\x8b', '\xb8\x88', '\xb8\x89', '\xb8\x8e', '\xb8\x8f', '\xb8\x8d', '\xb8\x82', '\xb8\x83', '\xb8\x80', '\xb8\x81', '\xb8\x87', 'tend', '\xb8\x9a',
请问对于中文的自然语言分析,有哪些方法和工具可以推荐?
回复内容:
最近正在用nltk 对中文网络商品评论进行褒贬情感分类,计算评论的信息熵(entropy)、互信息(point mutual information)和困惑值(perplexity)等(不过这些概念我其实也还理解不深...只是nltk 提供了相应方法)。
我感觉用nltk 处理中文是完全可用的。其重点在于中文分词和文本表达的形式。
中文和英文主要的不同之处是中文需要分词。因为nltk 的处理粒度一般是词,所以必须要先对文本进行分词然后再用nltk 来处理(不需要用nltk 来做分词,直接用分词包就可以了。严重推荐结巴分词,非常好用)。
中文分词之后,文本就是一个由每个词组成的长数组:[word1, word2, word3…… wordn]。之后就可以使用nltk 里面的各种方法来处理这个文本了。比如用FreqDist 统计文本词频,用bigrams 把文本变成双词组的形式:[(word1, word2), (word2, word3), (word3, word4)……(wordn-1, wordn)]。
再之后就可以用这些来计算文本词语的信息熵、互信息等。
再之后可以用这些来选择机器学习的特征,构建分类器,对文本进行分类(商品评论是由多个独立评论组成的多维数组,网上有很多情感分类的实现例子用的就是nltk 中的商品评论语料库,不过是英文的。但整个思想是可以一致的)。
另外还有一个困扰很多人的Python 中文编码问题。多次失败后我总结出一些经验。
Python 解决中文编码问题基本可以用以下逻辑:
utf8(输入) ——> unicode(处理) ——> (输出)utf8
Python 里面处理的字符都是都是unicode 编码,因此解决编码问题的方法是把输入的文本(无论是什么编码)解码为(decode)unicode编码,然后输出时再编码(encode)成所需编码。
由于处理的一般为txt 文档,所以最简单的方法,是把txt 文档另存为utf-8 编码,然后使用Python 处理的时候解码为unicode(sometexts.decode('utf8')),输出结果回txt 的时候再编码成utf8(直接用str() 函数就可以了)。
楼主遇到的只是编码的问题…
有很多好用的中文处理包:
Jieba:可以用来做分词,词性标注,TextRank
HanLP:分词,命名实体识别,依存句法分析,还有FudanNLP,NLPIR
个人觉得都比NLTK好用~
中文分词用结巴就好了,我做了个小例子 nltk-比较中文文档相似度你说这个跟NLTK无关,换Python3,就没有这些鬼了!中文还得UTF8!
大爱NLTK!其它包,除了固定任务的,java就算了,
使用:text.decode('gbk')
分词:你找相应的中文分词包 https://github.com/fxsjy/jieba因为nltk不能对中文进行分词的原因吧,最近也在学习这方面的东西,推荐一个工具中文處理工具,可以研究一下
我遇到同样的问题,在看《Python自然语言处理》一书,成功加载自己的文档后,却看到里面的中文如你所示,应该是编码设置的问题,但是不知道该设置哪里。这方面的资料太少了

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1371
1371
 52
52

![GeForce Now-Fehlercode 0x0000012E [BEHOBEN]](https://img.php.cn/upload/article/000/000/164/170834836989999.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) GeForce Now-Fehlercode 0x0000012E [BEHOBEN]
Feb 19, 2024 pm 09:12 PM
GeForce Now-Fehlercode 0x0000012E [BEHOBEN]
Feb 19, 2024 pm 09:12 PM
Wenn bei NVIDIA GeForceNOW der Fehlercode 0x0000012E auftritt, teilen wir Ihnen die Lösung mit. Wir sind auf das gleiche Problem gestoßen und haben es wie folgt behoben, damit Sie das Spielen auf GeForce reibungslos genießen können. Beheben Sie den GeForce Now-Fehlercode 0x0000012E jetzt. Um den GeForceNow-Fehlercode 0x0000012E auf einem Windows-Computer zu beheben, befolgen Sie diese Lösungen: Überprüfen Sie die Internetverbindungsanforderungen. Überprüfen Sie die Hardwareanforderungen. Als Administrator ausführen. Zusätzliche Vorschläge. Bevor Sie beginnen, empfehlen wir Ihnen, eine Weile geduldig zu warten, da viele Benutzer keine Maßnahmen ergriffen haben, um das Problem zu beheben. Manchmal kann dies durch eine Fehlfunktion verursacht werden
 Was bedeutet der Fehler 0x0000004e?
Feb 18, 2024 pm 01:54 PM
Was bedeutet der Fehler 0x0000004e?
Feb 18, 2024 pm 01:54 PM
Was ist ein 0x0000004e-Fehler? Ein Fehler ist ein häufiges Problem in Computersystemen. Wenn ein Computer auf einen Fehler stößt, fährt das System normalerweise herunter, stürzt ab oder zeigt Fehlermeldungen an, weil es nicht ordnungsgemäß ausgeführt werden kann. In Windows-Systemen gibt es einen spezifischen Fehlercode 0x0000004e, bei dem es sich um einen Bluescreen-Fehlercode handelt, der darauf hinweist, dass im System ein schwerwiegender Fehler aufgetreten ist. Der Bluescreen-Fehler 0x0000004e wird durch Systemkernel- oder Treiberprobleme verursacht. Dieser Fehler führt normalerweise dazu, dass das Computersystem
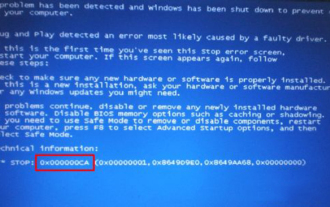 Umgang mit dem Bluescreen-Code 0x000003b in Win7 Ultimate Edition
Jul 23, 2023 pm 09:21 PM
Umgang mit dem Bluescreen-Code 0x000003b in Win7 Ultimate Edition
Jul 23, 2023 pm 09:21 PM
Das Bluescreen-Problem entsteht, wenn das Betriebssystem den Fehler nicht beheben kann und die Anzeige eines Bildschirmbilds erzwingt, um die Datendateien des Computers zu schützen. Und stellen Sie dem Benutzer den Fehlercode zur einfacheren Untersuchung zur Verfügung. Was ist der Grund für den Win7-Bluescreen-Code 0x万万3b? Wie kann man das Problem beheben? Zu diesem Thema stellt die folgende kleine Serie die Reparaturmethode des Bluescreen-Codes 0x million million 3b in der ultimativen Win7-Version vor. Details siehe unten. Was tun mit dem Bluescreen-Code 0x000003b in Win7 Ultimate Edition? 1. Wenn das Win7-System die Fehlermeldung 0x000003B stoppt, müssen Sie normalerweise manuell einen Patch herunterladen, um das Problem zu beheben. Allein dem Bluescreen-Code nach zu urteilen, wird der Code 0x000003B durch einen unerwarteten Netzwerkfehler verursacht. 2. Daher ist es notwendig, den Systembrowser-Cache rechtzeitig zu leeren
 Erfahren Sie, wie Sie den Bluescreen-Code 0x00008e lösen
Jul 10, 2023 pm 02:37 PM
Erfahren Sie, wie Sie den Bluescreen-Code 0x00008e lösen
Jul 10, 2023 pm 02:37 PM
Internetnutzer, die häufig Computerspiele spielen, stoßen manchmal auf Computer-Bluescreens, wissen jedoch nicht, was die Ursache ist, da die Umstände unterschiedlich und die Gründe unklar sind. Was ist also der Bluescreen-Code 0xWanwan8e? Wie kann man es lösen? Um diese Benutzer besser nutzen zu können, wird Xiaobian Ihnen die Gründe und Lösungen für den Bluescreen-Code 0x1008e nennen. Ich glaube, dass viele Internetnutzer durch den falschen Code verwirrt sind, wenn ihr Computer ausfällt. Was bedeutet der Bluescreen-Code 0x1008e, um die durch den Code verursachten Verwirrungen und Probleme schnell zu lösen und Fehler zu beseitigen? Wir erklären Ihnen, wie Sie das Problem des Bluescreen-Codes 0x万万8e lösen können. Bild und Text zur Lösung des Bluescreen-Codes 0x00008e. Bluescreen-Code am Fehlerpunkt gefunden (Abbildung 1) Code: 0x000008e Grund: Das System kann JOI derzeit nicht ausführen
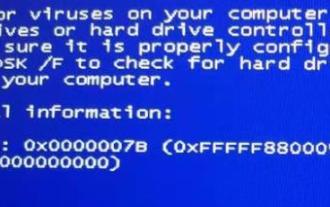 So beheben Sie den Fehler 0x0000007b
Dec 25, 2023 pm 03:35 PM
So beheben Sie den Fehler 0x0000007b
Dec 25, 2023 pm 03:35 PM
Viele Freunde sind bei der Verwendung von Computern auf den Fehlercode 0x0000007b gestoßen. Wie kann man eine solche Situation lösen? Wir können dieses Problem lösen, indem wir den Festplattenmodus ändern oder die Einstellungen zurücksetzen. Werfen wir einen Blick auf die folgenden Lösungen. Was tun, wenn 0x0000007b angezeigt wird: Methode 1: 1. Es ist wahrscheinlich, dass der falsche Grafikkartentreiber aktualisiert wurde. Starten Sie den Computer neu, nachdem der Fehlercode angezeigt wird. 2. Drücken Sie dann „F8“, um die Auswahloberfläche für den abgesicherten Modus aufzurufen, und wählen Sie „Letzte als funktionierend bekannte Konfiguration“ aus, um das System aufzurufen. 3. Dadurch kann das Anwendungskonfliktproblem gelöst werden. Wenn es nicht gelöst werden kann, können Sie versuchen, den Startmodus der Festplatte zu ändern. Methode 2: 1. Starten Sie zuerst den Computer neu und geben Sie dann mit dem Hotkey b ein
 Was soll ich tun, wenn der freigegebene Drucker nicht mit dem Win7-Computer 0x0000011b verbunden werden kann?
Jul 12, 2023 pm 07:01 PM
Was soll ich tun, wenn der freigegebene Drucker nicht mit dem Win7-Computer 0x0000011b verbunden werden kann?
Jul 12, 2023 pm 07:01 PM
Ich glaube, dass viele Benutzer bei der Verwendung von Computern häufig Fotokopiergeräte verwenden. In letzter Zeit haben viele Verbraucher jedoch die Eingabeaufforderung 0x0000011b erhalten, wenn sie die Win7-Computer ihres Unternehmens zum Herstellen einer Verbindung zu freigegebenen Druckern verwendet haben. Der Herausgeber wird jeden dazu bringen, einen Blick nach unten zu werfen! Originalentwurf von System Home www.xitongzhijia.net, beim Nachdruck muss die Quelle angegeben werden. Methode 1: Kennen Sie die Patch-Nummer, verwenden Sie ein Tool eines Drittanbieters, um den Patch zu deinstallieren. Dieses Tool ist ein offiziell von Lenovo hergestelltes Patch-Deinstallationstool. Es ist für jeden Computer geeignet. Die Daten müssen nur nach der Aktualisierung des KB eingegeben werden des Patches einfach deinstallieren. Download-Link: http://www.xito
 So beheben Sie den Bluescreen-Fehler 0x0000004e
Feb 18, 2024 pm 07:59 PM
So beheben Sie den Bluescreen-Fehler 0x0000004e
Feb 18, 2024 pm 07:59 PM
0x0000004e Bluescreen-Lösung Wenn wir den Computer verwenden, kann es gelegentlich zu einem Bluescreen kommen. Ein Bluescreen bedeutet, dass das Windows-Betriebssystem auf einen nicht behebbaren Fehler stößt, der dazu führt, dass der Computer nicht normal funktionieren kann und eine Fehlermeldung in Form eines Bluescreens angezeigt wird. Einer der häufigsten Bluescreen-Fehlercodes ist 0x0000004e. In diesem Artikel werden einige Methoden zur Lösung dieses Problems vorgestellt. Zuerst müssen wir die Ursache des 0x0000004e-Bluescreens verstehen. Dieser Fehler wird normalerweise durch ein Problem mit dem Systemtreiber verursacht.
![Xbox.com/ErrorHelp 0x87e50007 [BEHOBEN]](https://img.php.cn/upload/article/000/887/227/170831504115537.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) Xbox.com/ErrorHelp 0x87e50007 [BEHOBEN]
Feb 19, 2024 am 11:57 AM
Xbox.com/ErrorHelp 0x87e50007 [BEHOBEN]
Feb 19, 2024 am 11:57 AM
In diesem Artikel erfahren Sie, wie Sie den Xbox-Fehlercode 0x87e50007 beheben, der durch Serverprobleme, Netzwerkinstabilität oder fehlende Updates verursacht werden kann. Bevor Sie mit der weiteren Fehlerbehebung fortfahren, überprüfen Sie unbedingt den Status des XboxLive-Dienstes. Wenn ein Problem mit dem Xbox-Dienst vorliegt, kann es an einem Serverausfall liegen. Warten Sie in diesem Fall bitte geduldig, bis das Problem behoben ist, und überprüfen Sie regelmäßig die Xbox-Statusseite auf die neuesten Informationen. So beheben Sie den Xbox-Fehlercode 0x87e50007. Verwenden Sie die folgenden Korrekturen, um Xbox.com/ErrorHelp0x87e50007 zu beheben: Überprüfen Sie Ihre Internetverbindung. Aktualisieren Sie Spiele. Deinstallieren Sie Spiele oder Apps. Setzen Sie Ihre Konsole zurück. Beginnen wir. 1]Überprüfen Sie Ihr Internet
