

正则表达式如何匹配网页里面的汉字?

python做的爬虫,需要提取html中Apple iPhone 5s (A1530) 16GB 金色 移动联通4G手机 这里面的手机名,因为初学怎么都不能匹配完全, 其中用.*只能匹配到Apple iPhone 5s (A1 请各位指点一下!已经困住两天了!回复内容:
谢邀。
我又来安利xpath了,放弃正则表达式吧少年。//span[@class="pro-title"]/text()
(?<=>).*?(?=<)
如果实际情况中有许多不同的“<>”对,就请自行填充前后向断言的内容
你应该看看汉字编码,网页的编码很可能是GBK,然而python是用的utf8,所以绝对匹配不了


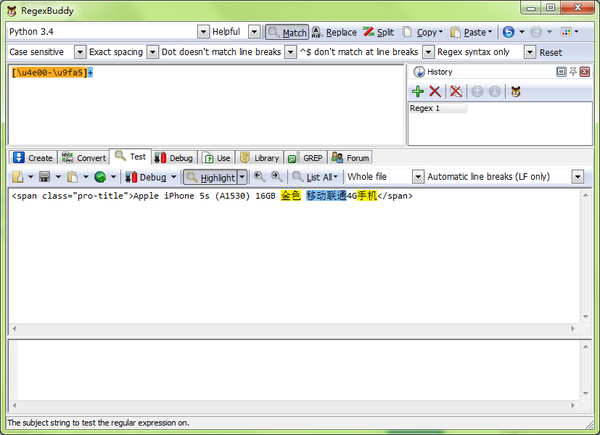
怒答,看到不懂正则的还瞎BB,为你感到悲哀!上图!---------------代码区----------------
# coding:utf-8
import re
x='<span class="pro-title">Apple iPhone 5s (A1530) 16GB 金色 移动联通4G手机</span> <span class="pro-price">'
xre=r'(<span class="pro-title">)(.+)(</span> <span class="pro-price">)'
z=re.search(xre,x).group(2)
print z
----------输出区-----------------------
C:\Python27\python.exe D:/PycharmProjects/爬虫/test.py
Apple iPhone 5s (A1530) 16GB 金色 移动联通4G手机
进程已结束,退出代码0
先用靓汤或正则找到这个节点,再用上面的字符组匹配。
假设这个节点只有一个,用法如下:<span class="kn">import</span> <span class="nn">re</span>
<span class="kn">import</span> <span class="nn">requests</span> <span class="k">as</span> <span class="nn">req</span>
<span class="kn">from</span> <span class="nn">bs4</span> <span class="k">import</span> <span class="n">BeautifulSoup</span>
<span class="n">url</span> <span class="o">=</span> <span class="s">'xxx'</span>
<span class="n">html</span> <span class="o">=</span> <span class="n">req</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">url</span><span class="p">)</span><span class="o">.</span><span class="n">text</span>
<span class="n">bs</span> <span class="o">=</span> <span class="n">BeautifulSoup</span><span class="p">(</span><span class="n">html</span><span class="p">)</span>
<span class="n">span</span> <span class="o">=</span> <span class="n">bs</span><span class="o">.</span><span class="n">find_all</span><span class="p">(</span><span class="s">'span'</span><span class="p">,</span> <span class="s">'pro-title'</span><span class="p">)</span>
<span class="sd">'''</span>
<span class="sd">span = re.findall('<span\sclass="pro-title">[^<]+</span>', html)</span>
<span class="sd">s = span[0]</span>
<span class="sd">m = re.findall('[\u4e00-\u9fa5]+', s)</span>
<span class="sd">'''</span>
<span class="n">s</span> <span class="o">=</span> <span class="nb">str</span><span class="p">(</span><span class="n">span</span><span class="p">)</span>
<span class="n">m</span> <span class="o">=</span> <span class="n">re</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="s">'[</span><span class="se">\u4e00</span><span class="s">-</span><span class="se">\u9fa5</span><span class="s">]+'</span><span class="p">,</span> <span class="n">s</span><span class="p">)</span>
<span class="nb">print</span><span class="p">(</span><span class="n">m</span><span class="p">)</span>

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Apples „HomeAccessory'-Gerät soll unter anderem über einen A18-Chipsatz verfügen
Sep 27, 2024 am 09:02 AM
Apples „HomeAccessory'-Gerät soll unter anderem über einen A18-Chipsatz verfügen
Sep 27, 2024 am 09:02 AM
Apples „HomeAccessory'-Gerät soll unter anderem über einen A18-Chipsatz verfügen
 Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 14, 2024 am 06:29 AM
Aktivierungssperre für iPhone-Teile in iOS 18 RC entdeckt – möglicherweise Apples jüngster Schlag gegen das Recht auf Reparatur, das unter dem Deckmantel des Benutzerschutzes verkauft wird
 Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
Sep 13, 2024 pm 06:17 PM
Die Aktivierungssperre für iPhone-Teile könnte Apples jüngster Schlag gegen das Recht auf Reparatur sein, das unter dem Deckmantel des Benutzerschutzes verkauft wird
 Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
Feb 13, 2025 pm 07:33 PM
Gate.io Trading Platform Offizielle App -Download- und Installationsadresse
 ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
Mar 04, 2025 pm 01:06 PM
ANBI App Offizieller Download V2.96.2 Neueste Version Installation Anbi Offizielle Android -Version
 Wie installiere und registriere ich eine App zum Kauf virtueller Münzen?
Feb 21, 2025 pm 06:00 PM
Wie installiere und registriere ich eine App zum Kauf virtueller Münzen?
Feb 21, 2025 pm 06:00 PM
Wie installiere und registriere ich eine App zum Kauf virtueller Münzen?
 Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
Sep 23, 2024 pm 06:18 PM
Mehrere iPhone 16 Pro-Benutzer berichten von Problemen mit dem Einfrieren des Touchscreens, die möglicherweise mit der Empfindlichkeit bei der Ablehnung der Handfläche zusammenhängen
 Laden Sie den Link des OUYI IOS -Versionsinstallationspakets herunter
Feb 21, 2025 pm 07:42 PM
Laden Sie den Link des OUYI IOS -Versionsinstallationspakets herunter
Feb 21, 2025 pm 07:42 PM
Laden Sie den Link des OUYI IOS -Versionsinstallationspakets herunter
