首先你们说的正则匹配一般是指partial match,或叫search。js里应该就是exec,但是我没查过。这个策略是独立于正则表达式本身的。一旦用了这个策略,正则引擎将寻找起点最靠左的可行解。
非贪婪是满足条件即返回结果。
a * = 0
a. * = 1
a.. * = 2
a... * = 3
… …
Nach dem Login kopieren
因为无论你的正则表达式怎么写,第一个字符在元字符串的位置出现的越早,这个答案的优先级就更高。
根本和贪婪非贪婪没关系好么!!@Tim Shen 巨巨已经说了!!
有个很重要的前提是正则表达式得成功啊,就是说要找到一个可行解!
<span class="sr">/(.*?)d/</span>
Nach dem Login kopieren
因为正则是从前往后逐字符扫描的
a yes
b yes
c yes
d bingo
第一个 a..d 对应过去就是abcd 两个点分别匹配到bc
第二个 a 后面的(.*?)看都不用看
第三个 ...d 对应过去就是abcd 三个点分别匹配到abc
因为这个匹配的实际效果是先找到第一个符合“.”的内容(就是随便什么都行),然后向后找到第一个“d”为止
其实跟贪婪不贪婪没什么区别,原因只是因为正则是从前往后匹配而不是从后往前匹配
正则表达式多用才是王道!
看到了一个非常棒的帖子,从NFA引擎机制上解释了这一问题 引用过来供大家参考 本题相关关键内容已加粗并下划线 (其中有两张图大家看完一定就明白了) 对于贪婪与非贪婪模式,可以从应用和原理两个角度进行理解,但如果想真正掌握,还是要从匹配原理来理解的。 2.1 从应用角度分析贪婪与非贪婪模式 test1
bbtest2
cc .*
test1
bbtest2
.*?
test1
(这里指的是一次匹配结果,所以没包括test2
)
”时已经可以使整个表达式匹配成功,但是由于采用的是贪婪模式,所以仍然要向右尝试匹配,查看是否还有更长的可以成功匹配的子串,匹配到第二个“”后,向右再没有可以成功匹配的子串,匹配结束,匹配结果为“
test1
bb
test2
”。当然,实际的匹配过程并不是这样的,后面的匹配原理会详细介绍。
仅从应用角度分析,可以这样认为,
贪婪模式,就是在整个表达式匹配成功的前提下,尽可能多的匹配, 也就是所谓的“贪婪”,通俗点讲,就是看到想要的,有多少就捡多少,除非再也没有想要的了。
正则表达式二采用的是非贪婪模式,在匹配到第一个“”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“
test1
”。
仅从应用角度分析,可以这样认为,
非贪婪模式,就是在整个表达式匹配成功的前提下,尽可能少的匹配, 也就是所谓的“非贪婪”,通俗点讲,就是找到一个想要的捡起来就行了,至于还有没有没捡的就不管了。
2.1.2 关于前提条件的说明
在上面从应用角度分析贪婪与非贪婪模式时,一直提到的一个前提条件就是
“整个表达式匹配成功” ,为什么要强调这个前提,我们看下下面的例子。
正则表达式三:
.*
bb
匹配结果三:
test1
bb
修饰“.”的仍然是匹配优先量词“*”,所以这里还是贪婪模式,前面的“
.*
”仍然可以匹配到“
test1
bb
test2
”,但是由于后面的“bb”无法匹配成功,这时“
.*
”必须让出已匹配的“bb
test2
”,以使整个表达式匹配成功。这时整个表达式匹配的结果为“
test1
bb”,“
.*
”匹配的内容为“
test1
”。可以看到,在“整个表达式匹配成功”的前提下,贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,贪婪模式只会影响匹配过程,对匹配结果的影响无从谈起。
非贪婪模式也存在同样的问题,来看下面的例子。
正则表达式四:
.*?
cc
匹配结果四:
test1
bb
test2
cc
这里采用的是非贪婪模式,前面的“
.*?
”仍然是匹配到“
test1
”为止,此时后面的“cc”无法匹配成功,要求“
.*?
”必须继续向右尝试匹配,直到匹配内容为“
test1
bb
test2
”时,后面的“cc”才能匹配成功,整个表达式匹配成功,匹配的内容为“
test1
bb
test2
cc”,其中“
.*?
”匹配的内容为“
test1
bb
test2
”。可以看到,在“整个表达式匹配成功”的前提下,非贪婪模式才真正的影响着子表达式的匹配行为,如果整个表达式匹配失败,非贪婪模式无法影响子表达式的匹配行为。
2.1.3 贪婪还是非贪婪——应用的抉择
通过应用角度的分析,已基本了解了贪婪与非贪婪模式的特性,那么在实际应用中,究竟是选择贪婪模式,还是非贪婪模式呢,这要根据需求来确定。
对于一些简单的需求,比如源字符为“aa
test1
bb”,那么取得div标签,使用贪婪与非贪婪模式都可以取得想要的结果,使用哪一种或许关系不大。
但是就2.1.1中的例子来说,实际应用中,一般一次只需要取得一个配对出现的div标签,也就是非贪婪模式匹配到的内容,贪婪模式所匹配到的内容通常并不是我们所需要的。
那为什么还要有贪婪模式的存在呢,从应用角度很难给出满意的解答了,这就需要从匹配原理的角度去分析贪婪与非贪婪模式。
2.2 从匹配原理角度分析贪婪与非贪婪模式 如果想真正了解什么是贪婪模式,什么是非贪婪模式,分别在什么情况下使用,各自的效率如何,那就不能仅仅从应用角度分析,而要充分了解贪婪与非贪婪模式的匹配原理。
2.2.1 从基本匹配原理谈起
NFA引擎基本匹配原理参考:正则基础之——NFA引擎匹配原理。
这里主要针对贪婪与非贪婪模式涉及到的匹配原理进行介绍。先看一下贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*"
图2-1
注:为了能够看清晰匹配过程,上面的空隙留得较大,实际源字符串为“”Regex””,下同。
来看一下匹配过程。
首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*”。
“.*”取得控制权后,由于“*”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到结尾的“””,匹配成功,由于此时已匹配到字符串的结尾,所以“.*”结束匹配,将控制权交给正则表达式最后的“"”。
“"”取得控制权后,由于已经在字符串结束位置,匹配失败,向前查找可供回溯的状态,控制权交给“.*”,由“.*”让出一个字符,也就是字符串结尾处的“””,再把控制权交给正则表达式最后的“"”,由“"”匹配字符串结尾处的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*”匹配的内容为“Regex”,匹配过程中进行了一次回溯。
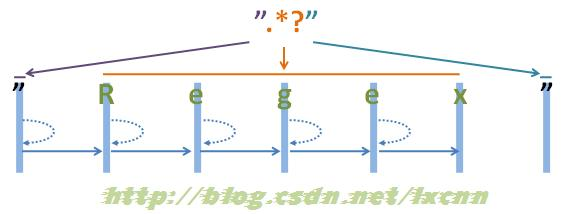
接下来看一下非贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*?"
图2-2
看一下非贪婪模式的匹配过程。
首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*?”。 此时整个正则表达式匹配成功,其中“.*?”匹配的内容为“Regex”,匹配过程中进行了五次回溯。
全文链接:
正则基础之—
感谢原作者




 关于"?"元字符
关于"?"元字符 /*知乎首问*/
/*知乎首问*/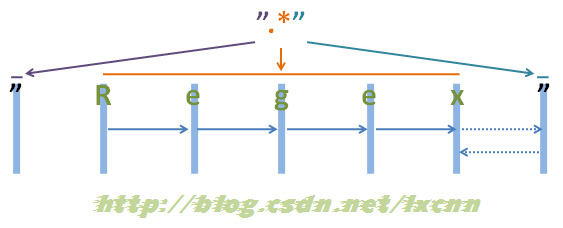

 So öffnen Sie eine PHP-Datei
So öffnen Sie eine PHP-Datei
 So entfernen Sie die ersten paar Elemente eines Arrays in PHP
So entfernen Sie die ersten paar Elemente eines Arrays in PHP
 Was tun, wenn die PHP-Deserialisierung fehlschlägt?
Was tun, wenn die PHP-Deserialisierung fehlschlägt?
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So verbinden Sie PHP mit der MSSQL-Datenbank
So verbinden Sie PHP mit der MSSQL-Datenbank
 So laden Sie HTML hoch
So laden Sie HTML hoch
 So lösen Sie verstümmelte Zeichen in PHP
So lösen Sie verstümmelte Zeichen in PHP
 So öffnen Sie PHP-Dateien auf einem Mobiltelefon
So öffnen Sie PHP-Dateien auf einem Mobiltelefon








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



