

Der gesamte Prozess der Erstellung eines Crawlers mit NodeJS_node.js

Lassen Sie uns heute das Crawler-Tutorial von alsotang lernen und dann dem einfachen Crawlen von CNode folgen.
Projekt craelr-demo erstellen
Wir erstellen zunächst ein Express-Projekt und löschen dann den gesamten Inhalt der Datei app.js, da wir den Inhalt vorerst nicht im Web anzeigen müssen. Natürlich können wir auch direkt npm install express in einem leeren Ordner die von uns benötigten Express-Funktionen nutzen.
Gezielte Website-Analyse
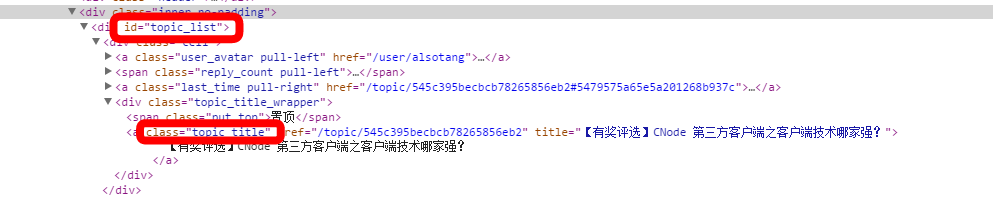
Wie im Bild gezeigt, ist dies ein Teil des div-Tags auf der CNode-Homepage. Wir verwenden diese Reihe von IDs und Klassen, um die benötigten Informationen zu finden.
Verwenden Sie Superagent, um Quelldaten zu erhalten
Superagent ist eine HTTP-Bibliothek, die von der Ajax-API verwendet wird. Seine Verwendung ähnelt der von jQuery. Wir initiieren darüber eine Get-Anfrage und geben das Ergebnis in der Callback-Funktion aus.
var express = require('express');
var url = require('url'); //Operations-URL analysieren
var superagent = require('superagent'); // Vergessen Sie nicht, npm install
für diese drei externen Abhängigkeiten durchzuführen var cheerio = require('cheerio');
var eventproxy = require('eventproxy');
var targetUrl = 'https://cnodejs.org/';
superagent.get(targetUrl)
.end(function (err, res) {
console.log(res);
});
Sein Res-Ergebnis ist ein Objekt, das Ziel-URL-Informationen enthält, und der Website-Inhalt besteht hauptsächlich aus seinem Text (String).
Verwenden Sie Cheerio zum Parsen
cheerio fungiert als serverseitige jQuery-Funktion. Zuerst verwenden wir .load(), um HTML zu laden, und filtern dann Elemente über den CSS-Selektor.
var $ = cheerio.load(res.text);
//Daten über den CSS-Selektor filtern
$('#topic_list .topic_title').each(function (idx, element) {
console.log(element);
});
Das Ergebnis ist ein Objekt. Rufen Sie die Funktion .each(function(index, element)) auf, um jedes Objekt zu durchlaufen und HTML-DOM-Elemente zurückzugeben.

Das Ergebnis der Ausgabe von console.log($element.attr('title')); ist 广州 2014年12月06日 NodeParty 之 UC 场
Titel wie console.log($element.attr('href')); werden als URLs wie /topic/545c395becbcb78265856eb2 ausgegeben. Verwenden Sie dann die Funktion url.resolve() von NodeJS1, um die vollständige URL zu vervollständigen.
superagent.get(tUrl)
.end(function (err, res) {
Wenn (irrt) {
return console.error(err);
}
var topicUrls = [];
var $ = cheerio.load(res.text);
//Alle Links auf der Homepage erhalten
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
var href = url.resolve(tUrl, $element.attr('href'));
console.log(href);
//topicUrls.push(href);
});
});
Verwenden Sie Eventproxy, um den Inhalt jedes Themas gleichzeitig zu crawlen
Das Tutorial zeigt Beispiele für tief verschachtelte (serielle) Methoden und Zählermethoden. Eventproxy verwendet Ereignismethoden (parallele Methoden), um dieses Problem zu lösen. Wenn das gesamte Crawling abgeschlossen ist, empfängt eventproxy die Ereignisnachricht und ruft automatisch die Verarbeitungsfunktion für Sie auf.
//Schritt eins: Holen Sie sich eine Instanz von eventproxy
var ep = new eventproxy();
//Schritt 2: Definieren Sie die Rückruffunktion für Abhörereignisse.
//Die After-Methode ist eine wiederholte Überwachung
//params: eventname(String) Ereignisname, times(Number) Anzahl der Abhörzeiten, Callback-Callback-Funktion
ep.after('topic_html', topicUrls.length, function(topics){
// topic ist ein Array, das die 40 Paare
in ep.emit('topic_html', pair) 40 Mal enthält //.map
themen = themen.map(function(topicPair){
//verwende Cheerio
var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = cheerio.load(topicHtml);
zurück ({
Titel: $('.topic_full_title').text().trim(),
href: topicUrl,
comment1: $('.reply_content').eq(0).text().trim()
});
});
//Ergebnis
console.log('outcome:');
console.log(topics);
});
//Schritt 3: Bestimmen Sie das
, das die Ereignismeldung auslöst topicUrls.forEach(function (topicUrl) {
Superagent.get(topicUrl)
.end(function (err, res) {
console.log('fetch ' topicUrl ' erfolgreich');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
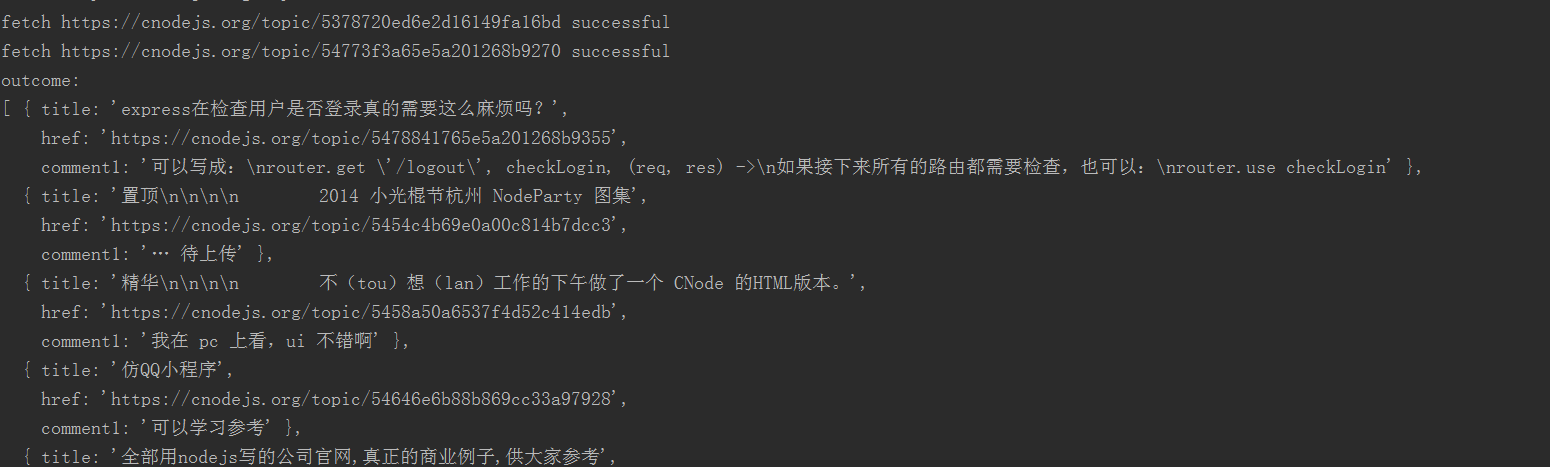
Die Ergebnisse sind wie folgt
Erweiterte Übung (Challenge)
Benutzernamen und Punkte per Nachricht erhalten
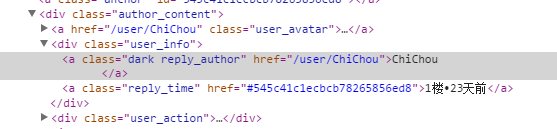
Suchen Sie den Klassennamen des Benutzers, der im Quellcode der Artikelseite einen Kommentar abgegeben hat. Der Klassenname lautet „reply_author“. Wie Sie dem ersten Element von console.log $('.reply_author').get(0) entnehmen können, ist alles, was wir brauchen, hier.
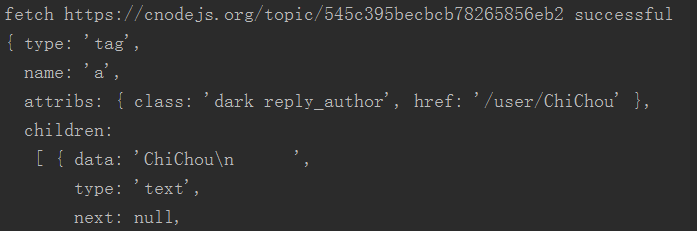
Lassen Sie uns zunächst einen Artikel crawlen und alles, was wir brauchen, auf einmal erhalten.
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
console.log($('.reply_author').get(0).children[0].data);
Wir können Punktinformationen über https://cnodejs.org/user/username
$('.reply_author').each(function (idx, element) {
var $element = $(element);
console.log($element.attr('href'));
});
Auf der Benutzerinformationsseite $('.big').text().trim() finden Sie die Punkteinformationen.
Verwenden Sie die Funktion .get(0) von Cheerio, um das erste Element abzurufen.
var userHref = url.resolve(tUrl, $('.reply_author').get(0).attribs.href);
console.log(userHref);
Dies ist nur eine Aufnahme eines einzelnen Artikels, es gibt noch 40, die geändert werden müssen.

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Der Unterschied zwischen NodeJS und VueJS
Apr 21, 2024 am 04:17 AM
Der Unterschied zwischen NodeJS und VueJS
Apr 21, 2024 am 04:17 AM
Node.js ist eine serverseitige JavaScript-Laufzeitumgebung, während Vue.js ein clientseitiges JavaScript-Framework zum Erstellen interaktiver Benutzeroberflächen ist. Node.js wird für die serverseitige Entwicklung verwendet, beispielsweise für die Entwicklung von Back-End-Service-APIs und die Datenverarbeitung, während Vue.js für die clientseitige Entwicklung verwendet wird, beispielsweise für Single-Page-Anwendungen und reaktionsfähige Benutzeroberflächen.
 Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Ist NodeJS ein Backend-Framework?
Apr 21, 2024 am 05:09 AM
Node.js kann als Backend-Framework verwendet werden, da es Funktionen wie hohe Leistung, Skalierbarkeit, plattformübergreifende Unterstützung, ein umfangreiches Ökosystem und einfache Entwicklung bietet.
 So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
So verbinden Sie NodeJS mit der MySQL-Datenbank
Apr 21, 2024 am 06:13 AM
Um eine Verbindung zu einer MySQL-Datenbank herzustellen, müssen Sie die folgenden Schritte ausführen: Installieren Sie den MySQL2-Treiber. Verwenden Sie mysql2.createConnection(), um ein Verbindungsobjekt zu erstellen, das die Hostadresse, den Port, den Benutzernamen, das Passwort und den Datenbanknamen enthält. Verwenden Sie „connection.query()“, um Abfragen durchzuführen. Verwenden Sie abschließend Connection.end(), um die Verbindung zu beenden.
 Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Was sind die globalen Variablen in NodeJS?
Apr 21, 2024 am 04:54 AM
Die folgenden globalen Variablen sind in Node.js vorhanden: Globales Objekt: global Kernmodul: Prozess, Konsole, erforderlich Laufzeitumgebungsvariablen: __dirname, __filename, __line, __column Konstanten: undefiniert, null, NaN, Infinity, -Infinity
 Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Was ist der Unterschied zwischen den Dateien npm und npm.cmd im Installationsverzeichnis von nodejs?
Apr 21, 2024 am 05:18 AM
Es gibt zwei npm-bezogene Dateien im Node.js-Installationsverzeichnis: npm und npm.cmd. Die Unterschiede sind wie folgt: unterschiedliche Erweiterungen: npm ist eine ausführbare Datei und npm.cmd ist eine Befehlsfensterverknüpfung. Windows-Benutzer: npm.cmd kann über die Eingabeaufforderung verwendet werden, npm kann nur über die Befehlszeile ausgeführt werden. Kompatibilität: npm.cmd ist spezifisch für Windows-Systeme, npm ist plattformübergreifend verfügbar. Nutzungsempfehlungen: Windows-Benutzer verwenden npm.cmd, andere Betriebssysteme verwenden npm.
 Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Gibt es einen großen Unterschied zwischen NodeJS und Java?
Apr 21, 2024 am 06:12 AM
Die Hauptunterschiede zwischen Node.js und Java sind Design und Funktionen: Ereignisgesteuert vs. Thread-gesteuert: Node.js ist ereignisgesteuert und Java ist Thread-gesteuert. Single-Threaded vs. Multi-Threaded: Node.js verwendet eine Single-Threaded-Ereignisschleife und Java verwendet eine Multithread-Architektur. Laufzeitumgebung: Node.js läuft auf der V8-JavaScript-Engine, während Java auf der JVM läuft. Syntax: Node.js verwendet JavaScript-Syntax, während Java Java-Syntax verwendet. Zweck: Node.js eignet sich für I/O-intensive Aufgaben, während Java für große Unternehmensanwendungen geeignet ist.
 Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ist NodeJS eine Back-End-Entwicklungssprache?
Apr 21, 2024 am 05:09 AM
Ja, Node.js ist eine Backend-Entwicklungssprache. Es wird für die Back-End-Entwicklung verwendet, einschließlich der Handhabung serverseitiger Geschäftslogik, der Verwaltung von Datenbankverbindungen und der Bereitstellung von APIs.
 So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
So stellen Sie das NodeJS-Projekt auf dem Server bereit
Apr 21, 2024 am 04:40 AM
Serverbereitstellungsschritte für ein Node.js-Projekt: Bereiten Sie die Bereitstellungsumgebung vor: Erhalten Sie Serverzugriff, installieren Sie Node.js, richten Sie ein Git-Repository ein. Erstellen Sie die Anwendung: Verwenden Sie npm run build, um bereitstellbaren Code und Abhängigkeiten zu generieren. Code auf den Server hochladen: über Git oder File Transfer Protocol. Abhängigkeiten installieren: Stellen Sie eine SSH-Verbindung zum Server her und installieren Sie Anwendungsabhängigkeiten mit npm install. Starten Sie die Anwendung: Verwenden Sie einen Befehl wie node index.js, um die Anwendung zu starten, oder verwenden Sie einen Prozessmanager wie pm2. Konfigurieren Sie einen Reverse-Proxy (optional): Verwenden Sie einen Reverse-Proxy wie Nginx oder Apache, um den Datenverkehr an Ihre Anwendung weiterzuleiten
