Insgesamt10000 bezogener Inhalt gefunden

Die Community der intelligenten Hausmüll-Sortierroboter stellt ihre „Talente' zur Schau und bittet die Bewohner um Meinungen
Artikeleinführung:Beijing Daily Client |. Reporter Cheng Gong Am 17. Juli schloss sich die Datun Street im Bezirk Chaoyang mit der Beijing Tianyi Oasis Environmental Protection Technology Co., Ltd. und der „Green Care“-Gruppe der School of Mechanical and Materials Engineering der North China University zusammen Technologie soll den Bewohnern der Gemeinde Xiuya in Anhui Beili die leistungsstarken Funktionen des intelligenten Sortierroboters für Hausmüll demonstrieren. Dieser Roboter wurde von der „Green Care“-Gruppe der Technischen Universität Peking unabhängig entwickelt und innovativ entwickelt. Er kann den eingegebenen Hausmüll gemäß den vier Klassifizierungsstandards „Recyclingstoffe, Küchenabfälle, gefährliche Abfälle und andere Abfälle“ intelligent identifizieren und klassifizieren. , und legen Sie es in die entsprechenden Mülleimer. Die Müllkomprimierung und die intelligente Klassifizierung des Mülls werden automatisch und ohne menschliches Eingreifen durchgeführt. Der helle Bildschirm zeigt klassifizierte Daten in Echtzeit an. Wenn die Müllmenge überlastet ist, wird ein Vollalarm ausgegeben. Im Standby-Modus werden selbst entworfene und produzierte Videos abgespielt.
2023-07-19
Kommentar 0
1781

Die Bedeutung der Müllklassifizierung
Artikeleinführung:Die Bedeutung der Müllklassifizierung: 1. Reduzierung der Umweltverschmutzung; 3. Verbesserung des öffentlichen Bewusstseins für den Umweltschutz; 6. Förderung des Aufbaus einer ökologischen Zivilisation; . Das Niveau der sozialen Governance verbessern. Ausführliche Einführung: 1. Mit der Beschleunigung der Urbanisierung nimmt die Menge des erzeugten Mülls von Jahr zu Jahr zu, was schwerwiegende Auswirkungen auf die Umwelt hat. Durch die Müllklassifizierung kann die Verschmutzung des Bodens, der Wasserquellen usw. verringert werden 2. Die effektive Nutzung von Ressourcen enthält viele wiederverwertbare Ressourcen.
2024-01-19
Kommentar 0
61408

Graphisches neuronales Netzwerk zur Multi-Label-Klassifizierung
Artikeleinführung:Ein graphisches neuronales Netzwerk ist eine Art neuronales Netzwerkmodell, das für die Aufgaben der Graphdatenanalyse und des Graph-Data-Mining entwickelt wurde. Es kann für Klassifizierungsaufgaben mit mehreren Etiketten verwendet werden. In grafischen neuronalen Netzen können Knoten und Kanten als Vektoren oder Tensoren dargestellt werden, und die Beziehungen zwischen Knoten und Kanten werden durch den Rechenprozess des neuronalen Netzes gelernt. Um die Genauigkeit der Ausgabeergebnisse des Netzwerks zu verbessern, kann der Backpropagation-Algorithmus zur Optimierung verwendet werden. Bei der Multi-Label-Klassifizierung handelt es sich um eine Methode zur Aufteilung von Daten in verschiedene Kategorien, wobei jeder Datenpunkt zu mehr als einer Kategorie gehören kann. Bei der Analyse von Diagrammdaten kann die Multi-Label-Klassifizierung verwendet werden, um Beschriftungen von Knoten oder Untergraphen zu identifizieren, z. B. die Interessen und Hobbys von Benutzern in sozialen Netzwerken, die Eigenschaften chemischer Moleküle usw. Die Anwendung graphischer neuronaler Netze bei Klassifizierungsaufgaben mit mehreren Etiketten bietet breite Anwendungsaussichten. 1. Der Gott der Bilder
2024-01-22
Kommentar 0
872

Coreldraw-Primär-Tutorial
Artikeleinführung:CorelDRAW-Basis-Tutorial CorelDRAW ist eine leistungsstarke Software zur Bearbeitung von Vektorgrafiken, die häufig in den Bereichen Grafikdesign, Illustrationsproduktion, kommerzielles Logodesign und anderen Bereichen eingesetzt wird. In diesem Artikel stellen wir die Grundkenntnisse und Bedienfähigkeiten von CorelDRAW vor, um Anfängern den schnellen Einstieg zu erleichtern. Einführung in die Benutzeroberfläche Nach dem Öffnen der CorelDRAW-Software sehen wir als Erstes die Softwareoberfläche. Es ist hauptsächlich in vier Teile unterteilt: Menüleiste, Symbolleiste, Funktionsfeld und Seitenansicht. Menüleiste: einschließlich Datei, Bearbeiten, Anzeigen, Paaren
2024-02-21
Kommentar 0
731
Entdecken Sie die dynamische Welt von Python und Jython
Artikeleinführung:Dynamische Typisierung: Variablen werden basierend auf ihren Werten zur Laufzeit typisiert. Interpreter: Python-Code wird Zeile für Zeile interpretiert und ausgeführt. Umfangreiche Bibliotheken: Python verfügt über eine riesige Standardbibliothek und Bibliotheken von Drittanbietern für verschiedene Aufgaben. JythonJython ist eine Implementierung von Python, die für die Ausführung auf der Java Virtual Machine (JVM) entwickelt wurde. Es erbt viele Funktionen von Python, bietet aber auch einige einzigartige Vorteile: Interoperabilität mit Java: Jython-Code kann nahtlos mit Java-Code interagieren und auf Java-Klassen und -Bibliotheken zugreifen. JVM-Optimierung: Jython läuft auf der JVM und nutzt die Garbage Collection und JIT-Kompilierung von Java sowie andere Optimierungen. Plattformübergreifend: Jython kann auf jedem Server bereitgestellt werden, der Java unterstützt
2024-03-19
Kommentar 0
645

Der Unterschied zwischen Naive Bayes und Entscheidungsbäumen
Artikeleinführung:Naive Bayes und Entscheidungsbäume sind gängige Algorithmen für maschinelles Lernen, die für Klassifizierungs- und Regressionsprobleme verwendet werden. Bei beiden handelt es sich um Klassifikatoren, die auf probabilistischen Modellen basieren, ihre Implementierung und Ziele unterscheiden sich jedoch geringfügig. Naive Bayes basiert auf dem Bayes-Theorem, bei dem davon ausgegangen wird, dass Merkmale unabhängig voneinander sind, und bei der Klassifizierung durch Berechnung der A-posteriori-Wahrscheinlichkeit erfolgt. Der Entscheidungsbaum klassifiziert basierend auf der bedingten Beziehung zwischen Features durch den Aufbau einer Baumstruktur. Naive Bayes eignet sich für Probleme wie Textklassifizierung und Spam-Filterung, während Entscheidungsbäume für Probleme geeignet sind, bei denen eine offensichtliche Beziehung zwischen Merkmalen besteht. Kurz gesagt, Naive Bayes eignet sich besser für hochdimensionale Merkmale und kleine Stichprobendaten. 1. Verschiedene Grundprinzipien: Naive Bayes und Entscheidungsbäume sind Klassifikatoren, die auf der Wahrscheinlichkeitstheorie basieren. Naive Bayes verwendet den Satz von Bayes, um die Wahrscheinlichkeit einer Klasse angesichts der Merkmale zu berechnen. Entscheidungsbaum
2024-01-22
Kommentar 0
1161

Der Unterschied zwischen Golang und Python
Artikeleinführung:Golang und Python sind zwei sehr beliebte Programmiersprachen, jede mit ihren eigenen Vorteilen und anwendbaren Szenarien. In diesem Artikel werden die Unterschiede zwischen Golang und Python anhand der folgenden vier Aspekte vorgestellt. 1. Sprachfunktionen Golang ist eine statisch typisierte Programmiersprache. Ihre Hauptziele sind Parallelität und parallele Programmierung. Sie bietet native Unterstützung für Goroutinen und Kanäle, was die gleichzeitige Programmierung erleichtert. Golang unterstützt Garbage Collection und automatische Speicherzuweisung, was das Schreiben von Programmen erleichtert
2023-05-13
Kommentar 0
1734

Eine überraschende Methode der zeitlichen Redundanz: eine neue Möglichkeit, den Rechenaufwand visueller Transformer zu reduzieren
Artikeleinführung:Transformer wurde ursprünglich für die Verarbeitung natürlicher Sprache entwickelt, wird aber mittlerweile häufig für Bildverarbeitungsaufgaben eingesetzt. Visual Transformer hat bei mehreren visuellen Erkennungsaufgaben eine hervorragende Genauigkeit bewiesen und bei Aufgaben wie der Bildklassifizierung, der Videoklassifizierung und der Objekterkennung eine erstklassige Leistung erzielt. Ein großer Nachteil von Visual Transformer ist der hohe Rechenaufwand. Ein typisches Faltungsnetzwerk (CNN) benötigt für die Verarbeitung mehrere zehn GFlops pro Bild, während ein visueller Transformer oft eine Größenordnung mehr benötigt und Hunderte von GFlops pro Bild erreicht. Bei der Verarbeitung von Videos ist dieses Problem aufgrund der großen Datenmenge noch gravierender. Der hohe Rechenaufwand macht den visuellen Transformer aus
2023-10-06
Kommentar 0
1626

So verwenden Sie die Go-Sprache, um die Funktionseffizienz zu verbessern
Artikeleinführung:Titel: Methoden zur Verwendung der Go-Sprache zur Verbesserung der Funktionseffizienz. Bei der Go-Sprachprogrammierung ist die Optimierung der Funktionseffizienz ein wichtiger Aspekt zur Verbesserung der Programmleistung. Durch vernünftiges Design und Optimierung können wir dafür sorgen, dass Funktionen effizienter laufen. In diesem Artikel werden einige Methoden zur Verwendung der Go-Sprache zur Verbesserung der Funktionseffizienz vorgestellt und spezifische Codebeispiele gegeben. 1. Vermeiden Sie die häufige Erstellung temporärer Variablen. In der Go-Sprache erhöht die häufige Erstellung temporärer Variablen die Belastung durch die Speicherzuweisung und die Speicherbereinigung und beeinträchtigt somit die Programmleistung. Um dies zu vermeiden, können Sie die Variable außerhalb der Funktion und definieren
2024-03-28
Kommentar 0
871

Entwerfen einer RESTful-API mit NodeJS und Restify
Artikeleinführung:RESTfulAPI enthält zwei Hauptkonzepte: Ressourcen und Darstellung. Eine Ressource kann ein beliebiges Objekt sein, das mit Daten verknüpft ist oder durch einen URI identifiziert wird (mehrere URIs können auf dieselbe Ressource verweisen) und kann mithilfe von HTTP-Methoden manipuliert werden. Darstellung ist die Art und Weise, wie eine Ressource angezeigt wird. In diesem Tutorial behandeln wir einige theoretische Informationen zum RESTful-API-Design und implementieren eine Beispiel-API für eine Bloganwendung mit NodeJS. Ressourcen Die Auswahl der richtigen Ressourcen für eine RESTful-API ist ein wichtiger Teil des Designs. Zunächst müssen Sie Ihr Geschäftsfeld analysieren und dann über die Menge und Art der zu verwendenden Ressourcen entscheiden, die für Ihre Geschäftsanforderungen relevant sind. Wenn Sie eine Blogging-API entwerfen, arbeiten Sie möglicherweise mit Beiträgen, Benutzern und Kommentaren. diese sind
2023-09-03
Kommentar 0
1621

Was ist Hedera Coin? Wie funktioniert die Hedera-Münze?
Artikeleinführung:HederaHashgraph: Innovation in der Distributed-Ledger-Technologie HederaHashgraph ist eine Distributed-Ledger-Technologie (DLT) mit hohem Durchsatz, geringer Latenz und starker Sicherheit. Ziel ist es, eine schnelle, sichere und skalierbare Plattform für verschiedene Arten von Anwendungen bereitzustellen. HederaHashgraph verwendet einen einzigartigen Konsensmechanismus namens Gossip Protocol, der sich von der herkömmlichen Blockchain-Technologie unterscheidet. Dieses Protokoll ermöglicht es Knoten, durch zufällige Kommunikation schnell und zuverlässig einen Konsens zu erreichen, wobei jeder Knoten nur mit wenigen anderen Knoten Informationen austauschen muss. Auf diese Weise können sich Transaktionen schnell ausbreiten und Forks effektiv verhindern. Das Design des Gossip-Protokolls ermöglicht es dem Netzwerk, einen effizienten Konsens zu erzielen und gleichzeitig Sicherheit und Zuverlässigkeit zu gewährleisten.
2024-03-15
Kommentar 0
372

Die Zukunft intelligenter Städte: ein neues Kapitel unabhängigen Denkens
Artikeleinführung:Stellen Sie sich eine Stadt vor, die mitdenkt, dafür sorgt, dass Güter so schnell wie möglich ankommen, indem sie den Verkehr „umleitet“, damit Einsatzfahrzeuge ihre Ziele reibungslos erreichen können, und sogar Menschen mit ihren verlorenen Haustieren wieder zusammenbringt. Die Aussicht, eine „kognitive Stadt“ genannt zu werden, ist Die neu formulierte Richtung für die nächste Generation intelligenter Städte lautet wie folgt: Die ersten intelligenten Städte können wahrnehmen, aber nicht handeln, kognitive Städte hingegen werden wahrnehmen und reagieren. Der Schlüssel zur Erreichung dieses Ziels sind auf den Straßen verteilte Sensoren und Edge Computing. Viele der Smart Cities der Zukunft werden „auf der grünen Wiese“ sein: völlig neue Städte, die von Grund auf neu gebaut und mit Intelligenz ausgestattet sind, wobei Edge Computing in alles integriert ist, von Straßenlaternen bis hin zu Mülleimern. Für die Menschen, die in diesen Städten leben, wird Edge Computing echte, messbare Verbesserungen in ihrem Leben bringen – angefangen bei
2023-09-04
Kommentar 0
1282

So fragen Sie Groß- und Kleinbuchstaben in MySQL ab
Artikeleinführung:Fallprobleme in MySQL Fallprobleme in MySQL können auf das Design der Datenbank zurückgeführt werden. In MySQL wird bei Bezeichnern (z. B. Tabellennamen, Spaltennamen, Variablennamen usw.) die Groß-/Kleinschreibung beachtet. Dies kann uns in manchen Fällen große Probleme bereiten. Wenn wir beispielsweise eine Tabelle erstellen, geben wir den Tabellennamen student an. Wenn wir später die SELECT-Anweisung zum Abfragen der Tabelle verwenden, können wir Student oder STUDENT und andere ähnliche Fallformen nicht verwenden, da die MySQL-Datenbank sonst eine Fehlermeldung zurückgibt . So verwenden Sie das Schlüsselwort BINARY für Groß-/Kleinschreibungsabfragen in MySQL. Verwenden Sie bei Abfragen das Schlüsselwort BINARY, um die Groß-/Kleinschreibung in MySQL zu ignorieren. Zum Beispiel,
2023-06-03
Kommentar 0
1500

Bildrauschen mithilfe von Faltungs-Neuronalen Netzen
Artikeleinführung:Faltungs-Neuronale Netze eignen sich gut für Aufgaben zur Bildrauschunterdrückung. Es nutzt die erlernten Filter, um das Rauschen zu filtern und so das Originalbild wiederherzustellen. In diesem Artikel wird die Methode zur Bildentrauschung basierend auf einem Faltungs-Neuronalen Netzwerk ausführlich vorgestellt. 1. Überblick über das Convolutional Neural Network Das Convolutional Neural Network ist ein Deep-Learning-Algorithmus, der eine Kombination aus mehreren Faltungsschichten, Pooling-Schichten und vollständig verbundenen Schichten verwendet, um Bildmerkmale zu lernen und zu klassifizieren. In der Faltungsschicht werden die lokalen Merkmale des Bildes durch Faltungsoperationen extrahiert und so die räumliche Korrelation im Bild erfasst. Die Pooling-Schicht reduziert den Rechenaufwand durch Reduzierung der Feature-Dimension und behält die Hauptfeatures bei. Die vollständig verbundene Schicht ist für die Zuordnung erlernter Merkmale und Beschriftungen zur Implementierung der Bildklassifizierung oder anderer Aufgaben verantwortlich. Das Design dieser Netzwerkstruktur macht das Faltungs-Neuronale Netzwerk für die Bildverarbeitung und -erkennung nützlich.
2024-01-23
Kommentar 0
1309
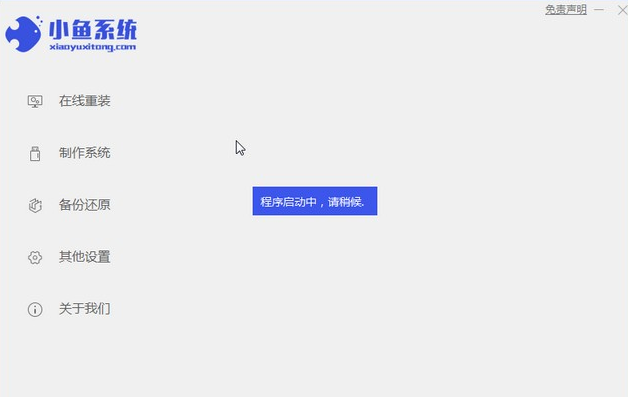
So installieren Sie das Win7-Betriebssystem auf dem Computer
Artikeleinführung:Unter den Computer-Betriebssystemen ist das WIN7-System ein sehr klassisches Computer-Betriebssystem. Wie installiert man also das Win7-System? Der folgende Editor stellt detailliert vor, wie Sie das Win7-System auf Ihrem Computer installieren. 1. Laden Sie zunächst das Xiaoyu-System herunter und installieren Sie die Systemsoftware erneut auf Ihrem Desktop-Computer. 2. Wählen Sie das Win7-System aus und klicken Sie auf „Dieses System installieren“. 3. Beginnen Sie dann mit dem Herunterladen des Image des Win7-Systems. 4. Stellen Sie nach dem Herunterladen die Umgebung bereit und klicken Sie nach Abschluss auf Jetzt neu starten. 5. Nach dem Neustart des Computers erscheint die Windows-Manager-Seite. Wir wählen die zweite. 6. Kehren Sie zur Pe-Schnittstelle des Computers zurück, um die Installation fortzusetzen. 7. Starten Sie nach Abschluss den Computer neu. 8. Kommen Sie schließlich zum Desktop und die Systeminstallation ist abgeschlossen. Ein-Klick-Installation des Win7-Systems
2023-07-16
Kommentar 0
1217
PHP-Einfügesortierung
Artikeleinführung::Dieser Artikel stellt hauptsächlich die PHP-Einfügesortierung vor. Studenten, die sich für PHP-Tutorials interessieren, können darauf zurückgreifen.
2016-08-08
Kommentar 0
1073
图解找出PHP配置文件php.ini的路径的方法,_PHP教程
Artikeleinführung:图解找出PHP配置文件php.ini的路径的方法,。图解找出PHP配置文件php.ini的路径的方法, 近来,有不博友问php.ini存在哪个目录下?或者修改php.ini以后为何没有生效?基于以上两个问题,
2016-07-13
Kommentar 0
822

Huawei bringt zwei neue kommerzielle KI-Speicherprodukte großer Modelle auf den Markt, die eine Leistung von 12 Millionen IOPS unterstützen
Artikeleinführung:IT House berichtete am 14. Juli, dass Huawei kürzlich neue kommerzielle KI-Speicherprodukte „OceanStorA310 Deep Learning Data Lake Storage“ und „FusionCubeA3000 Training/Pushing Hyper-Converged All-in-One Machine“ herausgebracht habe. Beamte sagten, dass „diese beiden Produkte grundlegendes Training ermöglichen“. KI-Modelle, Branchenmodelltraining, segmentiertes Szenariomodelltraining und Inferenz sorgen für neuen Schwung.“ ▲ Bildquelle Huawei IT Home fasst zusammen: OceanStorA310 Deep Learning Data Lake Storage ist hauptsächlich auf einfache/industrielle große Modell-Data-Lake-Szenarien ausgerichtet, um eine Datenregression zu erreichen . Umfangreiches Datenmanagement im gesamten KI-Prozess von der Erfassung und Vorverarbeitung bis hin zum Modelltraining und der Inferenzanwendung. Offiziell erklärt, dass OceanStorA310 Single Frame 5U die branchenweit höchsten 400 GB/s unterstützt
2023-07-16
Kommentar 0
1551

