Insgesamt10000 bezogener Inhalt gefunden

Golangs Anwendung für maschinelles Lernen beim Reinforcement Learning
Artikeleinführung:Einführung in die maschinelle Lernanwendung von Golang beim Reinforcement Learning. Reinforcement Learning ist eine Methode des maschinellen Lernens, die optimales Verhalten durch Interaktion mit der Umgebung und basierend auf Belohnungsfeedback lernt. Die Go-Sprache verfügt über Funktionen wie Parallelität, Parallelität und Speichersicherheit, was ihr einen Vorteil beim verstärkenden Lernen verschafft. Praktischer Fall: Go Reinforcement Learning In diesem Tutorial verwenden wir die Go-Sprache und den AlphaZero-Algorithmus, um ein Go Reinforcement Learning-Modell zu implementieren. Schritt 1: Abhängigkeiten installieren gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
Kommentar 0
512

Probleme bei der Algorithmenauswahl beim Reinforcement Learning
Artikeleinführung:Das Problem der Algorithmenauswahl beim Reinforcement Learning erfordert spezifische Codebeispiele. Reinforcement Learning ist ein Bereich des maschinellen Lernens, das durch die Interaktion zwischen dem Agenten und der Umgebung optimale Strategien lernt. Beim Reinforcement Learning ist die Wahl eines geeigneten Algorithmus entscheidend für den Lerneffekt. In diesem Artikel untersuchen wir Probleme bei der Algorithmusauswahl beim Reinforcement Learning und stellen konkrete Codebeispiele bereit. Beim Reinforcement Learning stehen viele Algorithmen zur Auswahl, z. B. Q-Learning, DeepQNetwork (DQN), Actor-Critic usw. Wählen Sie den richtigen Algorithmus
2023-10-08
Kommentar 0
1203

So erstellen Sie einen Reinforcement-Learning-Algorithmus mit PHP
Artikeleinführung:So erstellen Sie einen Reinforcement-Learning-Algorithmus mit PHP. Einführung: Reinforcement Learning ist eine maschinelle Lernmethode, die lernt, durch Interaktion mit der Umgebung optimale Entscheidungen zu treffen. In diesem Artikel stellen wir vor, wie man Reinforcement-Learning-Algorithmen mithilfe der Programmiersprache PHP erstellt, und stellen Codebeispiele bereit, um den Lesern ein besseres Verständnis zu erleichtern. 1. Was ist ein Reinforcement-Learning-Algorithmus? Der Reinforcement-Learning-Algorithmus ist eine maschinelle Lernmethode, die lernt, Entscheidungen zu treffen, indem sie das Feedback aus der Umgebung beobachtet. Im Gegensatz zu anderen Algorithmen für maschinelles Lernen basieren Reinforcement-Learning-Algorithmen nicht nur auf vorhandenen Daten
2023-07-31
Kommentar 0
712

Probleme beim Belohnungsdesign beim verstärkenden Lernen
Artikeleinführung:Das Problem des Belohnungsdesigns beim Reinforcement Learning erfordert spezifische Codebeispiele. Reinforcement Learning ist eine Methode des maschinellen Lernens, deren Ziel darin besteht, zu lernen, wie man Aktionen durchführt, die die kumulativen Belohnungen durch Interaktion mit der Umgebung maximieren. Beim verstärkenden Lernen spielt die Belohnung eine entscheidende Rolle. Sie ist ein Signal im Lernprozess des Agenten und wird zur Steuerung seines Verhaltens verwendet. Das Belohnungsdesign ist jedoch ein herausforderndes Problem, und ein angemessenes Belohnungsdesign kann die Leistung von Verstärkungslernalgorithmen stark beeinträchtigen. Beim verstärkenden Lernen können Belohnungen als der Agent gegenüber der Umgebung betrachtet werden
2023-10-08
Kommentar 0
1452

Deep-Reinforcement-Learning-Technologie in C++
Artikeleinführung:Die Deep-Reinforcement-Learning-Technologie ist ein Zweig der künstlichen Intelligenz, der viel Aufmerksamkeit erregt hat. Sie hat mehrere internationale Wettbewerbe gewonnen und wird auch häufig in persönlichen Assistenten, autonomem Fahren, Spielintelligenz und anderen Bereichen eingesetzt. Bei der Umsetzung von Deep Reinforcement Learning ist C++ als effiziente und hervorragende Programmiersprache besonders wichtig, wenn die Hardwareressourcen begrenzt sind. Deep Reinforcement Learning kombiniert, wie der Name schon sagt, Technologien aus den beiden Bereichen Deep Learning und Reinforcement Learning. Um es einfach zu verstehen: Deep Learning bezieht sich auf das Lernen von Funktionen aus Daten und das Treffen von Entscheidungen durch den Aufbau eines mehrschichtigen neuronalen Netzwerks.
2023-08-21
Kommentar 0
1145

Definition, Klassifizierung und Algorithmusrahmen des Reinforcement Learning
Artikeleinführung:Reinforcement Learning (RL) ist ein maschineller Lernalgorithmus zwischen überwachtem Lernen und unüberwachtem Lernen. Es löst Probleme durch Versuch und Irrtum und Lernen. Während des Trainings trifft das verstärkende Lernen eine Reihe von Entscheidungen und wird basierend auf den durchgeführten Aktionen belohnt oder bestraft. Das Ziel besteht darin, die Gesamtbelohnung zu maximieren. Reinforcement Learning hat die Fähigkeit, autonom zu lernen und sich anzupassen und in dynamischen Umgebungen optimierte Entscheidungen zu treffen. Im Vergleich zum herkömmlichen überwachten Lernen eignet sich Verstärkungslernen besser für Probleme ohne klare Bezeichnungen und kann bei langfristigen Entscheidungsproblemen gute Ergebnisse erzielen. Im Kern geht es beim Reinforcement Learning um die Durchsetzung von Aktionen auf der Grundlage von Aktionen eines Agenten, der auf der Grundlage der positiven Auswirkungen seiner Aktionen auf ein Gesamtziel belohnt wird. Es gibt zwei Haupttypen von Reinforcement-Learning-Algorithmen: modellbasierte und modellfreie Lernalgorithmen
2024-01-24
Kommentar 0
711

Probleme beim Design von Belohnungsfunktionen beim verstärkenden Lernen
Artikeleinführung:Probleme beim Design von Belohnungsfunktionen beim Reinforcement Learning Einführung Reinforcement Learning ist eine Methode, die optimale Strategien durch die Interaktion zwischen einem Agenten und der Umgebung lernt. Beim verstärkenden Lernen ist die Gestaltung der Belohnungsfunktion entscheidend für den Lerneffekt des Agenten. In diesem Artikel werden Probleme beim Design von Belohnungsfunktionen beim Reinforcement Learning untersucht und spezifische Codebeispiele bereitgestellt. Die Rolle der Belohnungsfunktion und der Zielbelohnungsfunktion sind ein wichtiger Teil des Verstärkungslernens und werden zur Bewertung des Belohnungswerts verwendet, den der Agent in einem bestimmten Zustand erhält. Sein Design hilft dem Agenten dabei, die langfristige Ermüdung durch die Auswahl optimaler Maßnahmen zu maximieren.
2023-10-09
Kommentar 0
1746

Hierarchisches Verstärkungslernen
Artikeleinführung:Hierarchical Reinforcement Learning (HRL) ist eine Reinforcement-Learning-Methode, die Verhaltensweisen und Entscheidungen auf hoher Ebene auf hierarchische Weise lernt. Im Gegensatz zu herkömmlichen Methoden des Verstärkungslernens zerlegt HRL die Aufgabe in mehrere Unteraufgaben, lernt in jeder Unteraufgabe eine lokale Strategie und kombiniert diese lokalen Strategien dann zu einer globalen Strategie. Diese hierarchische Lernmethode kann die durch hochdimensionale Umgebungen und komplexe Aufgaben verursachten Lernschwierigkeiten verringern und die Lerneffizienz und -leistung verbessern. Durch hierarchische Strategien kann HRL Entscheidungen auf verschiedenen Ebenen treffen, um intelligentere Verhaltensweisen auf höherer Ebene zu erreichen. Dieser Ansatz findet in vielen Bereichen Anwendung, beispielsweise in der Robotersteuerung, beim Gameplay und beim autonomen Fahren.
2024-01-22
Kommentar 0
1421

Maschinelles Lernen: Top 19 Reinforcement Learning (RL)-Projekte auf Github
Artikeleinführung:Reinforcement Learning (RL) ist eine Methode des maschinellen Lernens, bei der Agenten durch Versuch und Irrtum lernen. Reinforcement-Learning-Algorithmen werden in vielen Bereichen eingesetzt, beispielsweise in der Gaming-, Robotik- und Finanzbranche. Das Ziel von RL besteht darin, eine Strategie zu finden, die die erwarteten langfristigen Renditen maximiert. Reinforcement-Learning-Algorithmen werden im Allgemeinen in zwei Kategorien unterteilt: modellbasiert und modellfrei. Modellbasierte Algorithmen nutzen Umgebungsmodelle, um optimale Handlungspfade zu planen. Dieser Ansatz basiert auf einer genauen Modellierung der Umgebung und der anschließenden Verwendung des Modells, um die Ergebnisse verschiedener Aktionen vorherzusagen. Im Gegensatz dazu lernen modellfreie Algorithmen direkt aus Interaktionen mit der Umgebung, ohne die Umgebung explizit zu modellieren. Diese Methode eignet sich besser für Situationen, in denen das Umgebungsmodell schwer zu erhalten oder ungenau ist. Im tatsächlichen Vergleich ist dies bei modellfreien Reinforcement-Learning-Algorithmen nicht der Fall
2024-03-19
Kommentar 0
939
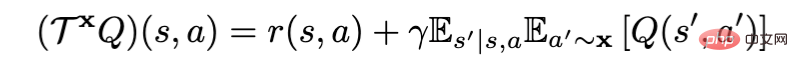
Ein neues Paradigma für Offline-Lernen zur Verstärkung! JD.com und die Tsinghua University schlagen einen entkoppelten Lernalgorithmus vor
Artikeleinführung:Der Offline-Lernalgorithmus für Verstärkung (Offline RL) ist eine der beliebtesten Unterrichtungen des Lernens für Verstärkung. Offline-Lernen zur Verstärkung interagiert nicht mit der Umgebung und zielt darauf ab, Zielrichtlinien aus zuvor aufgezeichneten Daten zu lernen. Offline-Bestärkendes Lernen ist im Vergleich zu Online-Bestärkendes Lernen (Online RL) besonders attraktiv in Bereichen, in denen die Datenerfassung teuer oder gefährlich ist, in denen jedoch möglicherweise große Datenmengen vorhanden sind (z. B. Robotik, industrielle Steuerung, autonomes Fahren). Bei Verwendung des Bellman-Richtlinienbewertungsoperators für die Richtlinienbewertung kann der aktuelle Offline-Lernalgorithmus zur Verstärkung entsprechend der Differenz in X in RL-basiert (x = π) und imitationsbasiert (x = μ) unterteilt werden, wobei π das Ziel ist Politik, μ ist die Verhaltensstrategie
2023-04-11
Kommentar 0
1017

Verstehen Sie Reinforcement Learning und seine Anwendungsszenarien
Artikeleinführung:Der beste Weg, einen Hund zu erziehen, besteht darin, ein Belohnungssystem zu verwenden, um ihn für gutes Verhalten zu belohnen und ihn für schlechtes Verhalten zu bestrafen. Die gleiche Strategie kann für maschinelles Lernen verwendet werden, das sogenannte Reinforcement Learning. Reinforcement Learning ist ein Zweig des maschinellen Lernens, der Modelle durch Entscheidungsfindung trainiert, um die beste Lösung für ein Problem zu finden. Um die Modellgenauigkeit zu verbessern, können positive Belohnungen verwendet werden, um den Algorithmus zu ermutigen, der richtigen Antwort näher zu kommen, während negative Belohnungen vergeben werden können, um Abweichungen vom Ziel zu bestrafen. Sie müssen nur die Ziele klären und dann die Daten modellieren. Das Modell beginnt, mit den Daten zu interagieren und ohne manuellen Eingriff Lösungen vorzuschlagen. Beispiel für Verstärkungslernen Nehmen wir als Beispiel das Hundetraining. Wir stellen Belohnungen wie Hundekekse zur Verfügung, um den Hund zu verschiedenen Aktionen zu bewegen. Der Hund verfolgt Belohnungen nach einer bestimmten Strategie, befolgt also Befehle und lernt neue Handlungen, wie zum Beispiel Betteln
2024-01-22
Kommentar 0
1409

Eine Methode zur Optimierung von AB mithilfe des Lernens zur Verstärkung des Richtliniengradienten
Artikeleinführung:AB-Tests sind eine Technik, die in Online-Experimenten weit verbreitet ist. Sein Hauptzweck besteht darin, zwei oder mehr Versionen einer Seite oder Anwendung zu vergleichen, um festzustellen, welche Version bessere Geschäftsziele erreicht. Diese Ziele können Klickraten, Konversionsraten usw. sein. Im Gegensatz dazu handelt es sich beim Reinforcement Learning um eine Methode des maschinellen Lernens, die mithilfe von Trial-and-Error-Lernen Entscheidungsstrategien optimiert. Policy Gradient Reinforcement Learning ist eine spezielle Reinforcement-Learning-Methode, die darauf abzielt, die kumulativen Belohnungen durch das Erlernen optimaler Richtlinien zu maximieren. Beide haben unterschiedliche Anwendungen bei der Optimierung von Geschäftszielen. Beim AB-Testen betrachten wir unterschiedliche Seitenversionen als unterschiedliche Aktionen und Geschäftsziele können als wichtige Indikatoren für Belohnungssignale betrachtet werden. Um maximale Geschäftsziele zu erreichen, müssen wir eine Strategie entwerfen, die wählbar ist
2024-01-24
Kommentar 0
1001

Xishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen
Artikeleinführung:Vom 6. bis 7. August 2022 findet wie geplant die AISummit Global Artificial Intelligence Technology Conference statt. Auf dem Unterforum „Artificial Intelligence Frontier Exploration“, das am Nachmittag des 7. stattfand, brachte Huang Hongbo, technischer Experte für künstliche Intelligenz in Xishanju, einen Themenvortrag zum Thema „Praktische Kombination von Verstärkungslernen und Verhaltensbäumen in Spielen“ und erläuterte dabei ausführlich die Auswirkungen der Verstärkung Lernen im Spielbereich. Huang Hongbo sagte, dass die Implementierung der Reinforcement-Learning-Technologie nicht darin besteht, den Algorithmus zu ändern, um ihn leistungsfähiger zu machen, sondern darin, Reinforcement-Learning-Technologie mit Deep Learning und Spielplanung zu kombinieren, um einen vollständigen Satz von Lösungen zu bilden und diese umzusetzen. Reinforcement Learning macht Spiele intelligenter. Die Implementierung von Reinforcement Learning in Spielen kann Spiele intelligenter und spielbarer machen.
2023-04-09
Kommentar 0
1836


Verstärkungslernmethode für die Vue-Komponentenkommunikation
Artikeleinführung:Verstärkungslernmethode für die Vue-Komponentenkommunikation In der Vue-Entwicklung ist die Komponentenkommunikation ein sehr wichtiges Thema. Es geht darum, wie man Daten zwischen mehreren Komponenten teilt, Ereignisse auslöst usw. Ein gängiger Ansatz besteht darin, Requisiten und $emit-Methoden für die Kommunikation zwischen übergeordneten und untergeordneten Komponenten zu verwenden. Diese einfache Kommunikationsmethode kann jedoch umständlich und schwierig zu warten sein, wenn Anwendungen größer werden und die Beziehungen zwischen Komponenten komplex werden. Reinforcement Learning ist ein Algorithmus, der Versuch-und-Irrtum- und Belohnungsmechanismen nutzt, um die Problemlösung zu optimieren. In der Komponentenkommunikation I
2023-07-17
Kommentar 0
1294

Merkmalsauswahl durch verstärkende Lernstrategien
Artikeleinführung:Die Funktionsauswahl ist ein entscheidender Schritt im Prozess der Erstellung eines Modells für maschinelles Lernen. Die Auswahl guter Funktionen für das Modell und die Aufgabe, die wir ausführen möchten, kann die Leistung verbessern. Wenn es sich um hochdimensionale Datensätze handelt, ist die Auswahl der Merkmale besonders wichtig. Dadurch kann das Modell schneller und besser lernen. Die Idee besteht darin, die optimale Anzahl an Funktionen und die aussagekräftigsten Funktionen zu finden. In diesem Artikel werden wir eine neue Funktionsauswahl über eine Strategie des verstärkenden Lernens vorstellen und implementieren. Wir beginnen mit der Diskussion des verstärkenden Lernens, insbesondere der Markov-Entscheidungsprozesse. Es handelt sich um eine sehr neue Methode im Bereich der Datenwissenschaft, die sich besonders für die Merkmalsauswahl eignet. Anschließend werden die Implementierung und die Installation und Verwendung der Python-Bibliothek (FSRLearning) vorgestellt. Abschließend soll dies anhand eines einfachen Beispiels demonstriert werden
2024-06-05
Kommentar 0
497

Die Wertfunktion beim Reinforcement Learning und die Bedeutung ihrer Bellman-Gleichung
Artikeleinführung:Reinforcement Learning ist ein Zweig des maschinellen Lernens, der darauf abzielt, durch Versuch und Irrtum optimale Aktionen in einer bestimmten Umgebung zu erlernen. Unter ihnen sind die Wertfunktion und die Bellman-Gleichung Schlüsselkonzepte beim Reinforcement Learning und helfen uns, die Grundprinzipien dieses Bereichs zu verstehen. Die Wertfunktion ist die erwartete langfristige Rendite, die von einem bestimmten Zustand erwartet wird. Beim verstärkenden Lernen verwenden wir häufig Belohnungen, um den Wert einer Aktion zu bewerten. Belohnungen können sofort oder verzögert erfolgen, wobei die Auswirkungen in zukünftigen Zeitschritten eintreten. Daher können wir Wertfunktionen in zwei Kategorien einteilen: Zustandswertfunktionen und Aktionswertfunktionen. Zustandswertfunktionen bewerten den Wert der Durchführung einer Aktion in einem bestimmten Zustand, während Aktionswertfunktionen den Wert der Durchführung einer bestimmten Aktion in einem bestimmten Zustand bewerten. Verstärken Sie Lernalgorithmen durch Berechnen und Aktualisieren von Wertfunktionen
2024-01-22
Kommentar 0
940

Wie weit hat sich Transformer im Bereich Reinforcement Learning entwickelt? Die Tsinghua-Universität, die Peking-Universität und andere haben gemeinsam eine Rezension von TransformRL veröffentlicht
Artikeleinführung:Reinforcement Learning (RL) bietet eine mathematische Form für die sequentielle Entscheidungsfindung, und auch Deep Reinforcement Learning (DRL) hat in den letzten Jahren große Fortschritte gemacht. Probleme mit der Stichprobeneffizienz behindern jedoch die weitverbreitete Anwendung von Deep-Reinforcement-Learning-Methoden in der realen Welt. Um dieses Problem zu lösen, besteht ein wirksamer Mechanismus darin, eine induktive Vorspannung in das DRL-Framework einzuführen. Beim Deep Reinforcement Learning sind Funktionsnäherungen sehr wichtig. Im Vergleich zum Architekturdesign beim überwachten Lernen (Supervised Learning, SL) werden die Fragen des Architekturdesigns beim DRL jedoch immer noch selten untersucht. Die meisten bestehenden Arbeiten zu RL-Architekturen wurden von der betreuten/halbüberwachten Lerngemeinschaft vorangetrieben. Um beispielsweise Eingaben basierend auf hochdimensionalen Bildern in DRL zu verarbeiten, besteht ein gängiger Ansatz in der Einführung von Convolutional Neural Networks (CNN) [
2023-04-13
Kommentar 0
784

Wird Verstärkungslernen überbewertet?
Artikeleinführung:Übersetzer |. Rezensiert von Li Rui |. Sie können sich vorstellen, dass Sie sich darauf vorbereiten, mit Ihren Freunden Schach zu spielen, aber er ist kein Mensch, sondern ein Computerprogramm, das die Spielregeln nicht versteht. Aber diese App versteht, dass sie auf ein Ziel hinarbeitet: das Spiel zu gewinnen. Da das Computerprogramm die Regeln nicht kennt, sind die Züge, die es ausführt, zufällig. Einige dieser Tricks machen überhaupt keinen Sinn und Sie können leicht gewinnen. Nehmen wir an, es macht Ihnen so viel Spaß, mit diesem Freund Schach zu spielen, dass Sie süchtig nach dem Spiel werden. Aber das Computerprogramm wird irgendwann gewinnen, weil es nach und nach Wege und Tricks lernt, um Sie zu besiegen. Obwohl dieses hypothetische Szenario weit hergeholt erscheinen mag, sollte es Ihnen eine Vorstellung von Reinforcement Learning vermitteln, einem Bereich des maschinellen Lernens.
2023-04-13
Kommentar 0
1149

Gradientenalgorithmus für Reinforcement-Learning-Richtlinien
Artikeleinführung:Der Policy-Gradient-Algorithmus ist ein wichtiger Reinforcement-Learning-Algorithmus. Seine Kernidee besteht darin, durch direkte Optimierung der Policy-Funktion nach der besten Strategie zu suchen. Im Vergleich zur Methode der indirekten Optimierung der Wertfunktion weist der Richtliniengradientenalgorithmus eine bessere Konvergenz und Stabilität auf und kann Probleme im kontinuierlichen Aktionsraum bewältigen, weshalb er weit verbreitet ist. Der Vorteil dieses Algorithmus besteht darin, dass er die Richtlinienparameter direkt lernen kann, ohne dass eine Schätzwertfunktion erforderlich ist. Dadurch kann der Richtliniengradientenalgorithmus die komplexen Probleme des hochdimensionalen Zustandsraums und des kontinuierlichen Aktionsraums bewältigen. Darüber hinaus kann der Richtliniengradientenalgorithmus den Gradienten auch durch Stichproben annähern, wodurch die Recheneffizienz verbessert wird. Kurz gesagt, der Richtliniengradientenalgorithmus ist eine leistungsstarke und flexible Methode. Im Richtliniengradientenalgorithmus müssen wir eine Richtlinienfunktion\pi(a|s) definieren
2024-01-22
Kommentar 0
1237
