Insgesamt10000 bezogener Inhalt gefunden

Welche Möglichkeiten gibt es, Daten mit PHP zu erfassen?
Artikeleinführung:Zu den PHP-Datenerfassungsmethoden gehören die Verwendung der cURL-Bibliothek, die Verwendung der Funktion file_get_contents, die Verwendung der Simple HTML DOM-Bibliothek, die Verwendung von Bibliotheken von Drittanbietern usw. Detaillierte Einführung: 1. Mithilfe der cURL-Bibliothek stellt PHP die cURL-Erweiterung bereit, mit der Sie problemlos Anforderungsheader festlegen, POST- oder GET-Anforderungen senden und vom Server zurückgegebene Daten abrufen können. 2. Verwenden Sie die Funktionsmethode file_get_contents usw.
2023-08-15
Kommentar 0
1295

Scrape but Validate: Daten-Scraping mit Pydantic Validation
Artikeleinführung:Hinweis: Keine Ausgabe von chatGPT/LLM
Unter Data Scraping versteht man das Sammeln von Daten aus öffentlichen Webquellen und erfolgt meist mithilfe von Skripten auf automatisierte Weise. Aufgrund der Automatisierung weisen die erfassten Daten häufig Fehler auf und müssen herausgefiltert und bereinigt werden
2024-11-22
Kommentar 0
857

So verwenden Sie BeautifulSoup zum Scrapen von Webseitendaten
Artikeleinführung:So verwenden Sie BeautifulSoup zum Crawlen von Webseitendaten. Einführung: Im Informationszeitalter des Internets sind Webseitendaten eine der Hauptquellen für uns, um Informationen zu erhalten. Um nützliche Informationen aus Webseiten zu extrahieren, müssen wir einige Tools zum Parsen und Crawlen von Webseitendaten verwenden. Unter diesen ist BeautifulSoup eine beliebte Python-Bibliothek, mit der sich problemlos Daten aus Webseiten extrahieren lassen. In diesem Artikel wird erläutert, wie Sie BeautifulSoup zum Crawlen von Webseitendaten verwenden, und es wird ein Beispielcode mitgeliefert. 1. Installieren Sie Beau
2023-08-03
Kommentar 0
2162

PHP- und Apache Nutch-Integration zur Erzielung von Web-Scraping und Data-Scraping
Artikeleinführung:Mit dem Aufkommen des Internetzeitalters haben wir es täglich mit riesigen Mengen an Informationen und Daten zu tun. In diesem Prozess ist die Erfassung und Sammlung von Daten zu einem sehr wichtigen Bestandteil geworden. Für Entwickler ist die Suche nach einem hervorragenden Tool zum effizienten Web-Crawling und Daten-Crawling zu einem Problem geworden, das sie lösen müssen. Unter den vielen Crawling-Tools ist ApacheNutch aufgrund seiner leistungsstarken Funktionen und hervorragenden Leistung zu einer sehr beliebten Wahl bei Entwicklern geworden. Gleichzeitig ist PHP auch eine ausgereifte Back-End-Programmiersprache
2023-06-25
Kommentar 0
1107
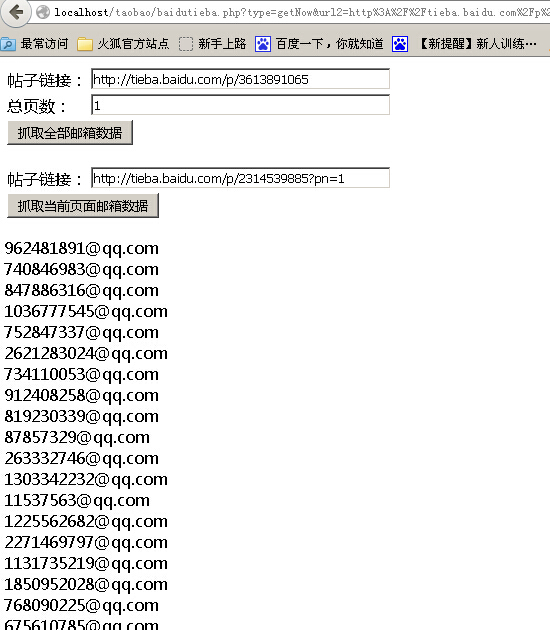
PHP网页抓取之抓取百度贴吧邮箱数据代码分享
Artikeleinführung:本文给大家介绍PHP网页抓取之抓取百度贴吧邮箱数据代码分享,程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,感兴趣的朋友一起学习吧
2016-06-10
Kommentar 0
1100

Wie kann ich den PHP-Crawler zum Crawlen von API-Schnittstellendaten verwenden?
Artikeleinführung:Wie kann ich den PHP-Crawler zum Crawlen von API-Schnittstellendaten verwenden? Als effizientes Daten-Scraping-Tool werden Crawler häufig verwendet, um wertvolle Daten aus Webseiten zu extrahieren. In der tatsächlichen Entwicklung müssen wir häufig API-Schnittstellendaten über Crawler für die anschließende Datenanalyse und -verarbeitung abrufen. In diesem Artikel wird erläutert, wie PHP-Crawler-Klassen zum Crawlen von API-Schnittstellendaten verwendet werden, und es werden entsprechende Codebeispiele angehängt. Bestimmen Sie die Ziel-API-Schnittstelle. Bevor wir beginnen, müssen wir zunächst die API-Schnittstelle bestimmen, die wir crawlen möchten, einschließlich der URL der Schnittstelle.
2023-08-07
Kommentar 0
1453

Wie man PHP verwendet, um Daten-Scraping- und Webseiten-Parsing-Funktionen zu implementieren
Artikeleinführung:So verwenden Sie PHP zur Implementierung von Datenerfassungs- und Webseiten-Analysefunktionen. Im modernen Internetzeitalter sind Daten eine sehr wertvolle Ressource. Die Möglichkeit, schnell und genau die erforderlichen Daten zu erhalten, ist unser Grundbedürfnis für Datenanalyse, Data Mining oder Webentwicklung . Mit der Programmiersprache PHP können wir problemlos Datenerfassungs- und Webseiten-Parsing-Funktionen implementieren. In diesem Artikel wird die Verwendung von PHP zur Implementierung von Datenerfassungs- und Webseiten-Analysefunktionen vorgestellt und entsprechende Codebeispiele bereitgestellt. 1. Die Datenerfassung verwendet die cURL-Bibliothek zur Datenerfassung
2023-09-05
Kommentar 0
1118

So scrapen Sie Webdaten in Python
Artikeleinführung:So führen Sie Web Scraping in Python durch Web Scraping bezieht sich auf den Prozess des Abrufens von Informationen aus dem Internet. In Python gibt es viele leistungsstarke Bibliotheken, die uns dabei helfen können, dieses Ziel zu erreichen. In diesem Artikel wird die Verwendung von Python zum Crawlen von Netzwerkdaten vorgestellt und spezifische Codebeispiele bereitgestellt. Notwendige Bibliotheken installieren Bevor wir beginnen, müssen wir einige notwendige Bibliotheken installieren. Unter diesen werden die folgenden drei Bibliotheken am häufigsten verwendet: urllib: Wird zum Abrufen von Daten aus URL-Anfragen verwendet: fortgeschrittenere und prägnantere Netzwerkanfragen
2023-10-20
Kommentar 0
862
phpQuery 数据抓取疑点
Artikeleinführung:
phpQuery 数据抓取疑问我想使用phpQuery 抓取某东产品的名字和价格,能取到产品名称,不能取到价格,因为源代码的价格是使用JS输出的,如果用Chrome浏览器审查元素是有价格的,应该怎样取得审查元素里的价格?------解决方案--------------------是ajax的吧?那就得多一次请求了如果是js代码,那就要用正则去匹
2016-06-13
Kommentar 0
886

Scrapy ist eine Daten-Scraping-Anwendung, die Crawler-Vorlagen enthält
Artikeleinführung:Mit der kontinuierlichen Weiterentwicklung der Internet-Technologie wurde auch die Crawler-Technologie weit verbreitet. Die Crawler-Technologie kann Daten im Internet automatisch crawlen und in einer Datenbank speichern, was die Datenanalyse und das Data Mining erleichtert. Als sehr bekanntes Crawler-Framework in Python verfügt Scrapy über einige gängige Crawler-Vorlagen, mit denen Daten auf der Zielwebsite schnell gecrawlt und automatisch in einer lokalen oder Cloud-Datenbank gespeichert werden können. In diesem Artikel wird erläutert, wie Sie Scrapys eigene Crawler-Vorlage zum Crawlen von Daten verwenden und wie Sie sie nach dem Crawlen verwenden.
2023-06-22
Kommentar 0
802

So optimieren Sie Web-Crawling und Data Scraping mit PHP und REDIS
Artikeleinführung:So nutzen Sie PHP und REDIS zur Optimierung von Webcrawlern und Datenerfassung. Einführung: Im Zeitalter von Big Data ist der Wert von Daten immer wichtiger geworden. Daher sind Webcrawler und Data Scraping zu Hotspots in Forschung und Entwicklung geworden. Allerdings verbraucht das Crawlen großer Datenmengen enorme Serverressourcen, und es müssen auch Zeitüberschreitungen und Duplizierungsprobleme während des Crawling-Vorgangs gelöst werden. In diesem Artikel stellen wir kurz vor, wie Sie mithilfe der PHP- und REDIS-Technologie den Web-Crawling- und Data-Scraping-Prozess optimieren und so die Effizienz und Leistung verbessern können. 1. Was ist REDISREDIS?
2023-07-22
Kommentar 0
1356


Lernen Sie Web-Crawling und Data Scraping mit der Go-Sprache
Artikeleinführung:Learn Go Language Webcrawler und Datenerfassung Ein Webcrawler ist ein automatisiertes Programm, das Webseiten durchsuchen und Daten gemäß bestimmten Regeln im Internet erfassen kann. Mit der rasanten Entwicklung des Internets und dem Aufkommen des Big-Data-Zeitalters ist die Datenerfassung für viele Unternehmen und Einzelpersonen zu einer unverzichtbaren Aufgabe geworden. Als schnelle und effiziente Programmiersprache hat die Go-Sprache das Potenzial, im Bereich Webcrawler und Datenerfassung weit verbreitet eingesetzt zu werden. Die Parallelität der Go-Sprache macht sie zu einer sehr geeigneten Sprache für die Implementierung von Webcrawlern. In der Go-Sprache können Sie verwenden
2023-11-30
Kommentar 0
517

python抓取安居客小区数据的程序代码
Artikeleinführung:抓取数据不管用什么编程语言几乎都是可以实现了,今天我们需要采集安居客的小区数据,下面我们来看一个python抓取安居客小区数据的程序代码了,希望下文能够对大家有帮助。
2016-06-08
Kommentar 0
1991
php使用curl和正则表达式抓取网页数据示例_PHP
Artikeleinführung:这篇文章主要介绍了php使用curl和正则表达式抓取网页数据示例,这里是抓取某网站的小说,需要的朋友可以修改一下抓取其它数据
2016-06-01
Kommentar 0
960

Scrapy-Framework-Praxis: Crawlen von Jianshu-Website-Daten
Artikeleinführung:Scrapy-Framework-Praxis: Crawlen von Jianshu-Website-Daten Scrapy ist ein Open-Source-Python-Crawler-Framework, mit dem Daten aus dem World Wide Web extrahiert werden können. In diesem Artikel stellen wir das Scrapy-Framework vor und verwenden es zum Crawlen von Daten von Jianshu-Websites. Scrapy installierenScrapy kann mit Paketmanagern wie pip oder conda installiert werden. Hier verwenden wir pip, um Scrapy zu installieren. Geben Sie den folgenden Befehl in die Befehlszeile ein: pipinstallscrapy Nachdem die Installation abgeschlossen ist
2023-06-22
Kommentar 0
1304

Web-Scraping- und Datenextraktionstechniken in Python
Artikeleinführung:Python hat sich für eine Vielzahl von Anwendungen zur Programmiersprache der Wahl entwickelt und seine Vielseitigkeit erstreckt sich auch auf die Welt des Web-Scrapings. Mit seinem umfangreichen Ökosystem an Bibliotheken und Frameworks bietet Python ein leistungsstarkes Toolkit zum Extrahieren von Daten aus Websites und zum Erschließen wertvoller Erkenntnisse. Unabhängig davon, ob Sie ein Datenbegeisterter, Forscher oder Branchenprofi sind, kann Web Scraping in Python eine wertvolle Fähigkeit sein, die riesigen Mengen an online verfügbaren Informationen zu nutzen. In diesem Tutorial tauchen wir in die Welt des Web Scraping ein und erkunden die verschiedenen Techniken und Tools in Python, die zum Extrahieren von Daten aus Websites verwendet werden können. Wir erläutern die Grundlagen des Web Scraping, verstehen die rechtlichen und ethischen Aspekte dieser Praxis und befassen uns mit den praktischen Aspekten der Datenextraktion. Im nächsten Teil dieses Artikels
2023-09-16
Kommentar 0
1260

Java-Crawler-Kenntnisse: Bewältigung des Daten-Crawlings von verschiedenen Webseiten
Artikeleinführung:Verbesserung der Crawler-Fähigkeiten: Wie Java-Crawler mit dem Crawlen von Daten von verschiedenen Webseiten umgehen, erfordert spezifische Codebeispiele. Zusammenfassung: Mit der rasanten Entwicklung des Internets und dem Aufkommen des Big-Data-Zeitalters ist das Crawlen von Daten immer wichtiger geworden. Als leistungsstarke Programmiersprache hat auch die Crawler-Technologie von Java große Aufmerksamkeit erregt. In diesem Artikel werden die Techniken des Java-Crawlers beim Crawlen verschiedener Webseitendaten vorgestellt und spezifische Codebeispiele bereitgestellt, um den Lesern dabei zu helfen, ihre Crawler-Fähigkeiten zu verbessern. Einführung Mit der Popularität des Internets können wir problemlos riesige Datenmengen beschaffen. Allerdings sind diese Zahlen
2024-01-09
Kommentar 0
901


