Insgesamt10000 bezogener Inhalt gefunden

Fähigkeiten zur Entwicklung asynchroner Coroutinen: Erzielen einer effizienten Datenerfassung und -analyse
Artikeleinführung:Fähigkeiten zur asynchronen Coroutine-Entwicklung: Um eine effiziente Datenerfassung und -analyse zu erreichen, sind spezifische Codebeispiele erforderlich. Mit der rasanten Entwicklung des Internets sind Daten immer wichtiger geworden, und das Abrufen und Analysieren von Daten daraus ist zu einer Kernanforderung vieler Anwendungen geworden . Bei der Datenerfassung und -analyse ist die Verbesserung der Effizienz eine der wichtigsten Herausforderungen für Entwickler. Um dieses Problem zu lösen, können wir Fähigkeiten zur asynchronen Coroutine-Entwicklung nutzen, um eine effiziente Datenerfassung und -analyse zu erreichen. Asynchrone Coroutinen sind eine gleichzeitige Programmiertechnologie, die eine gleichzeitige Ausführung in einem einzelnen Thread erreichen und Threadwechsel vermeiden kann.
2023-12-02
Kommentar 0
615

So optimieren Sie Web-Crawling und Data Scraping mit PHP und REDIS
Artikeleinführung:So nutzen Sie PHP und REDIS zur Optimierung von Webcrawlern und Datenerfassung. Einführung: Im Zeitalter von Big Data ist der Wert von Daten immer wichtiger geworden. Daher sind Webcrawler und Data Scraping zu Hotspots in Forschung und Entwicklung geworden. Allerdings verbraucht das Crawlen großer Datenmengen enorme Serverressourcen, und es müssen auch Zeitüberschreitungen und Duplizierungsprobleme während des Crawling-Vorgangs gelöst werden. In diesem Artikel stellen wir kurz vor, wie Sie mithilfe der PHP- und REDIS-Technologie den Web-Crawling- und Data-Scraping-Prozess optimieren und so die Effizienz und Leistung verbessern können. 1. Was ist REDISREDIS?
2023-07-22
Kommentar 0
1410


Web Scraping-Tutorial: Extrahieren Sie Daten von Websites mit Python
Artikeleinführung:Dieses Tutorial zeigt, wie Sie mithilfe von Python, einem leistungsstarken Tool zur Web-Scraping-Automatisierung, effizient Daten aus Websites extrahieren. Wir erstellen ein Python-Skript zum Scrapen von Produktinformationen, das wesentliche Schritte, potenzielle Schwierigkeiten und effektive Datenverwaltungstechniken abdeckt. Unter
2025-01-10
Kommentar 0
406

PHP- und Apache Nutch-Integration zur Erzielung von Web-Scraping und Data-Scraping
Artikeleinführung:Mit dem Aufkommen des Internetzeitalters haben wir es täglich mit riesigen Mengen an Informationen und Daten zu tun. In diesem Prozess ist die Erfassung und Sammlung von Daten zu einem sehr wichtigen Bestandteil geworden. Für Entwickler ist die Suche nach einem hervorragenden Tool zum effizienten Web-Crawling und Daten-Crawling zu einem Problem geworden, das sie lösen müssen. Unter den vielen Crawling-Tools ist ApacheNutch aufgrund seiner leistungsstarken Funktionen und hervorragenden Leistung zu einer sehr beliebten Wahl bei Entwicklern geworden. Gleichzeitig ist PHP auch eine ausgereifte Back-End-Programmiersprache
2023-06-25
Kommentar 0
1162


Wie kann ich den PHP-Crawler zum Crawlen von API-Schnittstellendaten verwenden?
Artikeleinführung:Wie kann ich den PHP-Crawler zum Crawlen von API-Schnittstellendaten verwenden? Als effizientes Daten-Scraping-Tool werden Crawler häufig verwendet, um wertvolle Daten aus Webseiten zu extrahieren. In der tatsächlichen Entwicklung müssen wir häufig API-Schnittstellendaten über Crawler für die anschließende Datenanalyse und -verarbeitung abrufen. In diesem Artikel wird erläutert, wie PHP-Crawler-Klassen zum Crawlen von API-Schnittstellendaten verwendet werden, und es werden entsprechende Codebeispiele angehängt. Bestimmen Sie die Ziel-API-Schnittstelle. Bevor wir beginnen, müssen wir zunächst die API-Schnittstelle bestimmen, die wir crawlen möchten, einschließlich der URL der Schnittstelle.
2023-08-07
Kommentar 0
1521

Erstellen eines Webcrawlers mit Node.js und Redis: So scrapen Sie Daten effizient
Artikeleinführung:Erstellen eines Webcrawlers mit Node.js und Redis: So crawlen Sie Daten effizient. Im heutigen Zeitalter der Informationsexplosion müssen wir oft große Datenmengen aus dem Internet abrufen. Die Aufgabe eines Webcrawlers besteht darin, automatisch Daten von Webseiten zu crawlen. In diesem Artikel stellen wir anhand von Codebeispielen vor, wie Sie mit Node.js und Redis einen effizienten Webcrawler erstellen. 1. Einführung in Node.js Node.js ist eine JavaScript-Operation, die auf der ChromeV8-Engine basiert.
2023-07-29
Kommentar 0
1062

Beherrschen Sie die Prinzipien von MySQL MVCC und verbessern Sie die Effizienz beim Lesen von Daten
Artikeleinführung:Beherrschen Sie die Prinzipien von MySQL MVCC und verbessern Sie die Effizienz beim Lesen von Daten. Einführung: MySQL ist ein häufig verwendetes relationales Datenbankverwaltungssystem, und MVCC (Multi-VersionConcurrencyControl) ist ein häufig verwendeter Parallelitätskontrollmechanismus in MySQL. Die Beherrschung des MVCC-Prinzips kann uns helfen, die internen Arbeitsprinzipien von MySQL besser zu verstehen und die Effizienz des Datenlesens zu verbessern. In diesem Artikel wird das Prinzip von MVCC vorgestellt und erläutert, wie dieses Prinzip zur Verbesserung der Effizienz beim Lesen von Daten genutzt werden kann.
2023-09-10
Kommentar 0
1008

Lernen Sie Web-Crawling und Data Scraping mit der Go-Sprache
Artikeleinführung:Learn Go Language Webcrawler und Datenerfassung Ein Webcrawler ist ein automatisiertes Programm, das Webseiten durchsuchen und Daten gemäß bestimmten Regeln im Internet erfassen kann. Mit der rasanten Entwicklung des Internets und dem Aufkommen des Big-Data-Zeitalters ist die Datenerfassung für viele Unternehmen und Einzelpersonen zu einer unverzichtbaren Aufgabe geworden. Als schnelle und effiziente Programmiersprache hat die Go-Sprache das Potenzial, im Bereich Webcrawler und Datenerfassung weit verbreitet eingesetzt zu werden. Die Parallelität der Go-Sprache macht sie zu einer sehr geeigneten Sprache für die Implementierung von Webcrawlern. In der Go-Sprache können Sie verwenden
2023-11-30
Kommentar 0
574

Welche Möglichkeiten gibt es, Daten mit PHP zu erfassen?
Artikeleinführung:Zu den PHP-Datenerfassungsmethoden gehören die Verwendung der cURL-Bibliothek, die Verwendung der Funktion file_get_contents, die Verwendung der Simple HTML DOM-Bibliothek, die Verwendung von Bibliotheken von Drittanbietern usw. Detaillierte Einführung: 1. Mithilfe der cURL-Bibliothek stellt PHP die cURL-Erweiterung bereit, mit der Sie problemlos Anforderungsheader festlegen, POST- oder GET-Anforderungen senden und vom Server zurückgegebene Daten abrufen können. 2. Verwenden Sie die Funktionsmethode file_get_contents usw.
2023-08-15
Kommentar 0
1369

Entwickeln Sie effiziente Webcrawler und Daten-Scraping-Tools mit den Sprachen Vue.js und Perl
Artikeleinführung:Verwenden Sie die Sprachen Vue.js und Perl, um effiziente Webcrawler und Daten-Scraping-Tools zu entwickeln. Mit der rasanten Entwicklung des Internets und der zunehmenden Bedeutung von Daten ist auch die Nachfrage nach Web-Crawlern und Daten-Scraping-Tools gestiegen. In diesem Zusammenhang ist es eine gute Wahl, Vue.js und die Perl-Sprache zu kombinieren, um effiziente Webcrawler und Daten-Scraping-Tools zu entwickeln. In diesem Artikel wird vorgestellt, wie man ein solches Tool mit Vue.js und der Perl-Sprache entwickelt, und es werden entsprechende Codebeispiele beigefügt. 1. Einführung in Vue.js und die Perl-Sprache
2023-07-31
Kommentar 0
1502

Scrape but Validate: Daten-Scraping mit Pydantic Validation
Artikeleinführung:Hinweis: Keine Ausgabe von chatGPT/LLM
Unter Data Scraping versteht man das Sammeln von Daten aus öffentlichen Webquellen und erfolgt meist mithilfe von Skripten auf automatisierte Weise. Aufgrund der Automatisierung weisen die erfassten Daten häufig Fehler auf und müssen herausgefiltert und bereinigt werden
2024-11-22
Kommentar 0
939

Wie Scrapy die Crawling-Stabilität und Crawling-Effizienz verbessert
Artikeleinführung:Scrapy ist ein leistungsstarkes, in Python geschriebenes Webcrawler-Framework, mit dem Benutzer schnell und effizient die erforderlichen Informationen aus dem Internet crawlen können. Bei der Verwendung von Scrapy zum Crawlen treten jedoch häufig Probleme auf, z. B. Crawling-Fehler, unvollständige Daten oder langsame Crawling-Geschwindigkeit. Diese Probleme beeinträchtigen die Effizienz und Stabilität des Crawlers. Daher wird in diesem Artikel untersucht, wie Scrapy die Crawling-Stabilität und Crawling-Effizienz verbessert. Legen Sie beim Crawlen des Webs Anforderungsheader und User-Agent fest.
2023-06-23
Kommentar 0
1935

Leitfaden zum React-Daten-Caching: So optimieren Sie die Front-End-Datenerfassung und die Aktualisierungseffizienz
Artikeleinführung:React Data Caching Guide: So optimieren Sie die Front-End-Datenerfassung und die Aktualisierungseffizienz. Einführung: Bei der Entwicklung von Webanwendungen müssen wir häufig Daten vom Back-End abrufen und diese im Front-End anzeigen. Allerdings müssen Sie jedes Mal, wenn Sie Daten abrufen, eine Anfrage an den Server senden, was zu einer gewissen Verzögerung führt und die Benutzererfahrung beeinträchtigt. Um die Effizienz beim Abrufen und Aktualisieren von Front-End-Daten zu verbessern, können wir die Daten-Caching-Technologie verwenden. In diesem Artikel wird erläutert, wie das Datencaching in React-Anwendungen zur Optimierung der Datenerfassung und Aktualisierungseffizienz verwendet wird, und es werden spezifische Codebeispiele bereitgestellt. verwenden
2023-09-29
Kommentar 0
1445


So verwenden Sie BeautifulSoup zum Scrapen von Webseitendaten
Artikeleinführung:So verwenden Sie BeautifulSoup zum Crawlen von Webseitendaten. Einführung: Im Informationszeitalter des Internets sind Webseitendaten eine der Hauptquellen für uns, um Informationen zu erhalten. Um nützliche Informationen aus Webseiten zu extrahieren, müssen wir einige Tools zum Parsen und Crawlen von Webseitendaten verwenden. Unter diesen ist BeautifulSoup eine beliebte Python-Bibliothek, mit der sich problemlos Daten aus Webseiten extrahieren lassen. In diesem Artikel wird erläutert, wie Sie BeautifulSoup zum Crawlen von Webseitendaten verwenden, und es wird ein Beispielcode mitgeliefert. 1. Installieren Sie Beau
2023-08-03
Kommentar 0
2217
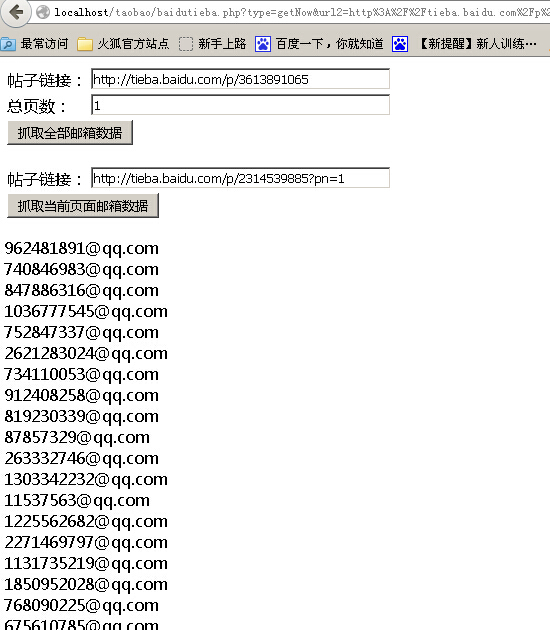
PHP网页抓取之抓取百度贴吧邮箱数据代码分享
Artikeleinführung:本文给大家介绍PHP网页抓取之抓取百度贴吧邮箱数据代码分享,程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,感兴趣的朋友一起学习吧
2016-06-10
Kommentar 0
1141
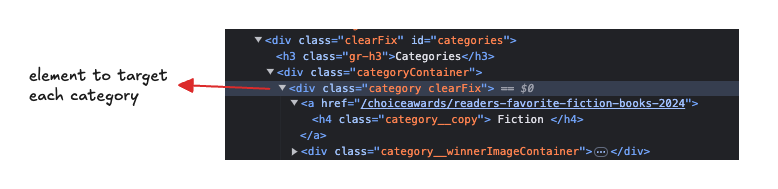
So extrahieren Sie Daten aus Goodreads mit Python und BeautifulSoup
Artikeleinführung:Web Scraping ist ein leistungsstarkes Tool zum Sammeln von Daten von Websites. Ganz gleich, ob Sie Produktbewertungen sammeln, Preise verfolgen oder, wie in unserem Fall, Goodreads-Bücher durchsuchen, Web Scraping bietet endlose Möglichkeiten für datengesteuerte Anwendungen.
In diesem
2024-12-10
Kommentar 0
283

