

Artikeleinführung:<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title>System Error</title> <meta name="robots" content="noindex,nofollow" /> <meta name="viewport" content="width=device-width, initial-scale=1, user-scalable=no"> <style> /* Base */ body { color: #333; font: 14px Verdana, "Helvetica Neue", helvetica, Arial, 'Microsoft YaHei', sans-serif; margin: 0; padding: 0 20px 20px; word-break: break-word; } h1{ margin: 10px 0 0; font-size: 28px; font-weight: 500; line-height: 32px; } h2{ color: #4288ce; font-weight: 400; padding: 6px 0; margin: 6px 0 0; font-size: 18px; border-bottom: 1px solid #eee; } h3.subheading { color: #4288ce; margin: 6px 0 0; font-weight: 400; } h3{ margin: 12px; font-size: 16px; font-weight: bold; } abbr{ cursor: help; text-decoration: underline; text-decoration-style: dotted; } a{ color: #868686; cursor: pointer; } a:hover{ text-decoration: underline; } .line-error{ background: #f8cbcb; } .echo table { width: 100%; } .echo pre { padding: 16px; overflow: auto; font-size: 85%; line-height: 1.45; background-color: #f7f7f7; border: 0; border-radius: 3px; font-family: Consolas, "Liberation Mono", Menlo, Courier, monospace; } .echo pre > pre { padding: 0; margin: 0; } /* Layout */ .col-md-3 { width: 25%; } .col-md-9 { width: 75%; } [class^="col-md-"] { float: left; } .clearfix { clear:both; } @media only screen and (min-device-width : 375px) and (max-device-width : 667px) { .col-md-3, .col-md-9 { width: 100%; } } /* Exception Info */ .exception { margin-top: 20px; } .exception .message{ padding: 12px; border: 1px solid #ddd; border-bottom: 0 none; line-height: 18px; font-size:16px; border-top-left-radius: 4px; border-top-right-radius: 4px; font-family: Consolas,"Liberation Mono",Courier,Verdana,"微软雅黑"; } .exception .code{ float: left; text-align: center; color: #fff; margin-right: 12px; padding: 16px; border-radius: 4px; background: #999; } .exception .source-code{ padding: 6px; border: 1px solid #ddd; background: #f9f9f9; overflow-x: auto; } .exception .source-code pre{ margin: 0; } .exception .source-code pre ol{ margin: 0; color: #4288ce; display: inline-block; min-width: 100%; box-sizing: border-box; font-size:14px; font-family: "Century Gothic",Consolas,"Liberation Mono",Courier,Verdana; padding-left: 48px; } .exception .source-code pre li{ border-left: 1px solid #ddd; height: 18px; line-height: 18px; } .exception .source-code pre code{ color: #333; height: 100%; display: inline-block; border-left: 1px solid #fff; font-size:14px; font-family: Consolas,"Liberation Mono",Courier,Verdana,"微软雅黑"; } .exception .trace{ padding: 6px; border: 1px solid #ddd; border-top: 0 none; line-height: 16px; font-size:14px; font-family: Consolas,"Liberation Mono",Courier,Verdana,"微软雅黑"; } .exception .trace ol{ margin: 12px; } .exception .trace ol li{ padding: 2px 4px; } .exception div:last-child{ border-bottom-left-radius: 4px; border-bottom-right-radius: 4px; } /* Exception Variables */ .exception-var table{ width: 100%; margin: 12px 0; box-sizing: border-box; table-layout:fixed; word-wrap:break-word; } .exception-var table caption{ text-align: left; font-size: 16px; font-weight: bold; padding: 6px 0; } .exception-var table caption small{ font-weight: 300; display: inline-block; margin-left: 10px; color: #ccc; } .exception-var table tbody{ font-size: 13px; font-family: Consolas,"Liberation Mono",Courier,"微软雅黑"; } .exception-var table td{ padding: 0 6px; vertical-align: top; word-break: break-all; } .exception-var table td:first-child{ width: 28%; font-weight: bold; white-space: nowrap; } .exception-var table td pre{ margin: 0; } /* Copyright Info */ .copyright{ margin-top: 24px; padding: 12px 0; border-top: 1px solid #eee; } /* SPAN elements with the classes below are added by prettyprint. */ pre.prettyprint .pln { color: #000 } /* plain text */ pre.prettyprint .str { color: #080 } /* string content */ pre.prettyprint .kwd { color: #008 } /* a keyword */ pre.prettyprint .com { color: #800 } /* a comment */ pre.prettyprint .typ { color: #606 } /* a type name */ pre.prettyprint .lit { color: #066 } /* a literal value */ /* punctuation, lisp open bracket, lisp close bracket */ pre.prettyprint .pun, pre.prettyprint .opn, pre.prettyprint .clo { color: #660 } pre.prettyprint .tag { color: #008 } /* a markup tag name */ pre.prettyprint .atn { color: #606 } /* a markup attribute name */ pre.prettyprint .atv { color: #080 } /* a markup attribute value */ pre.prettyprint .dec, pre.prettyprint .var { color: #606 } /* a declaration; a variable name */ pre.prettyprint .fun { color: red } /* a function name */ </style> </head> <body> <div class="echo"> </div> <div class="exception"> <div class="message"> <div class="info"> <div> <h2>[2] <abbr title="think\exception\ErrorException">ErrorException</abbr> in <a class="toggle" title="/data/wwwroot/td.880772.xyz/application/api/controller/Index.php line 81">Index.php line 81</a></h2> </div> <div><h1>preg_match_all(): Unknown modifier '�'</h1></div> </div> </div> <div class="source-code"> <pre class="prettyprint lang-php"><ol start="72"><li class="line-72"><code> // 处理每一行数据 </code></li><li class="line-73"><code> $download_list[] = str_replace(['/',"'",')','('],['\/',"\'",'\)','\('],addslashes($row['name'])); </code></li><li class="line-74"><code> } </code></li><li class="line-75"><code> </code></li><li class="line-76"><code> if(!empty($download_list)) </code></li><li class="line-77"><code> { </code></li><li class="line-78"><code> </code></li><li class="line-79"><code> $download_reg = preg_quote(implode('|',$download_list)); </code></li><li class="line-80"><code> </code></li><li class="line-81"><code> preg_match_all('/'.$download_reg.'/is', $content, $matches); </code></li><li class="line-82"><code> if (!empty($matches[0])) { </code></li><li class="line-83"><code> $games = $matches[0]; </code></li><li class="line-84"><code> </code></li><li class="line-85"><code> </code></li><li class="line-86"><code> foreach ($matches[0] as $key => $match) { </code></li><li class="line-87"><code> $tempTag = "<🎜>"; </code></li><li class="line-88"><code> $tempTags[] = $match; </code></li><li class="line-89"><code> $content = str_replace($match, $tempTag, $content); </code></li><li class="line-90"><code> } </code></li></ol></pre> </div> <div class="trace"> <h2>Call Stack</h2> <ol> <li>in <a class="toggle" title="/data/wwwroot/td.880772.xyz/application/api/controller/Index.php line 81">Index.php line 81</a></li> <li> at <abbr title="think\Error">Error</abbr>::appError() </li> <li> at preg_match_all() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/application/api/controller/Index.php line 81">Index.php line 81</a> </li> <li> at <abbr title="app\api\controller\Index">Index</abbr>->fanyi_article_title() </li> <li> at <abbr title="ReflectionMethod">ReflectionMethod</abbr>->invokeArgs() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/library/think/App.php line 343">App.php line 343</a> </li> <li> at <abbr title="think\App">App</abbr>::invokeMethod() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/library/think/App.php line 611">App.php line 611</a> </li> <li> at <abbr title="think\App">App</abbr>::module() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/library/think/App.php line 456">App.php line 456</a> </li> <li> at <abbr title="think\App">App</abbr>::exec() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/library/think/App.php line 139">App.php line 139</a> </li> <li> at <abbr title="think\App">App</abbr>::run() in <a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/start.php line 19">start.php line 19</a> </li> <li> at require('<a class="toggle" title="/data/wwwroot/td.880772.xyz/thinkphp/start.php">/data/wwwroot/td.880...</a>') in <a class="toggle" title="/data/wwwroot/td.880772.xyz/public/index.php line 23">index.php line 23</a> </li> </ol> </div> </div> <div class="exception-var"> <h2>Environment Variables</h2> <div> <h3 class="subheading">GET Data</h3> <div> <div class="clearfix"> <div class="col-md-3"><strong>content</strong></div> <div class="col-md-9"><small> Drova Forsaken Kin是一部取材于经典暗黑元素与凯尔特神话神秘气质的像素风格动作角色扮演游戏,客户可依据个人喜好及需求选购。 Drova Forsaken Kin价格介绍 答:Drova Forsaken Kin售价为92元。 关于售价说明 国内Steam平台上,该款游戏现售价为82.8元(原价92元)。 此价格为首发优惠时期折扣价,错过将无法在近期内享受类似优惠。 购入游戏的推荐 如果您对《Drova Forsaken Kin》感兴趣,并计划以优惠价格购入,建议在首发优惠阶段 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>to</strong></div> <div class="col-md-9"><small> de </small></div> </div> </div> </div> <div> <div class="clearfix"> <div class="col-md-3"><strong>POST Data</strong></div> <div class="col-md-9"><small>empty</small></div> </div> </div> <div> <div class="clearfix"> <div class="col-md-3"><strong>Files</strong></div> <div class="col-md-9"><small>empty</small></div> </div> </div> <div> <h3 class="subheading">Cookies</h3> <div> <div class="clearfix"> <div class="col-md-3"><strong>myip</strong></div> <div class="col-md-9"><small> 65.21.47.162 </small></div> </div> </div> </div> <div> <div class="clearfix"> <div class="col-md-3"><strong>Session</strong></div> <div class="col-md-9"><small>empty</small></div> </div> </div> <div> <h3 class="subheading">Server/Request Data</h3> <div> <div class="clearfix"> <div class="col-md-3"><strong>TEMP</strong></div> <div class="col-md-9"><small> /tmp </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>TMPDIR</strong></div> <div class="col-md-9"><small> /tmp </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>TMP</strong></div> <div class="col-md-9"><small> /tmp </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>PATH</strong></div> <div class="col-md-9"><small> /usr/local/bin:/usr/bin:/bin </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>USER</strong></div> <div class="col-md-9"><small> www </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HOME</strong></div> <div class="col-md-9"><small> /home/www </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_CONTENT_TYPE</strong></div> <div class="col-md-9"><small> application/x-www-form-urlencoded;charset=UTF-8 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_CONNECTION</strong></div> <div class="col-md-9"><small> Keep-Alive </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_COOKIE</strong></div> <div class="col-md-9"><small> myip=65.21.47.162 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_ACCEPT_ENCODING</strong></div> <div class="col-md-9"><small> gzip </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_ACCEPT</strong></div> <div class="col-md-9"><small> */* </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_USER_AGENT</strong></div> <div class="col-md-9"><small> Mozilla/5.0 (Linux; Android 6.0.1; OPPO A57 Build/MMB29M; wv) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/63.0.3239.83 Mobile Safari/537.36 T7/10.13 baiduboxapp/10.13.0.10 (Baidu; P1 6.0.1) </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTP_HOST</strong></div> <div class="col-md-9"><small> td.880772.xyz </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>PATH_INFO</strong></div> <div class="col-md-9"><small> /api/index/fanyi_article_title </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REDIRECT_STATUS</strong></div> <div class="col-md-9"><small> 200 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SERVER_NAME</strong></div> <div class="col-md-9"><small> td.880772.xyz </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SERVER_PORT</strong></div> <div class="col-md-9"><small> 443 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SERVER_ADDR</strong></div> <div class="col-md-9"><small> 188.165.242.95 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REMOTE_PORT</strong></div> <div class="col-md-9"><small> 16504 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REMOTE_ADDR</strong></div> <div class="col-md-9"><small> 65.21.47.162 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SERVER_SOFTWARE</strong></div> <div class="col-md-9"><small> nginx/1.20.2 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>GATEWAY_INTERFACE</strong></div> <div class="col-md-9"><small> CGI/1.1 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>HTTPS</strong></div> <div class="col-md-9"><small> on </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REQUEST_SCHEME</strong></div> <div class="col-md-9"><small> https </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SERVER_PROTOCOL</strong></div> <div class="col-md-9"><small> HTTP/1.1 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>DOCUMENT_ROOT</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/public </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>DOCUMENT_URI</strong></div> <div class="col-md-9"><small> /index.php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REQUEST_URI</strong></div> <div class="col-md-9"><small> /api/index/fanyi_article_title?content=Drova+Forsaken+Kin%E6%98%AF%E4%B8%80%E9%83%A8%E5%8F%96%E6%9D%90%E4%BA%8E%E7%BB%8F%E5%85%B8%E6%9A%97%E9%BB%91%E5%85%83%E7%B4%A0%E4%B8%8E%E5%87%AF%E5%B0%94%E7%89%B9%E7%A5%9E%E8%AF%9D%E7%A5%9E%E7%A7%98%E6%B0%94%E8%B4%A8%E7%9A%84%E5%83%8F%E7%B4%A0%E9%A3%8E%E6%A0%BC%E5%8A%A8%E4%BD%9C%E8%A7%92%E8%89%B2%E6%89%AE%E6%BC%94%E6%B8%B8%E6%88%8F%EF%BC%8C%E5%AE%A2%E6%88%B7%E5%8F%AF%E4%BE%9D%E6%8D%AE%E4%B8%AA%E4%BA%BA%E5%96%9C%E5%A5%BD%E5%8F%8A%E9%9C%80%E6%B1%82%E9%80%89%E8%B4%AD%E3%80%82%09Drova+Forsaken+Kin%E4%BB%B7%E6%A0%BC%E4%BB%8B%E7%BB%8D%09%E7%AD%94%EF%BC%9ADrova+Forsaken+Kin%E5%94%AE%E4%BB%B7%E4%B8%BA92%E5%85%83%E3%80%82%09%E5%85%B3%E4%BA%8E%E5%94%AE%E4%BB%B7%E8%AF%B4%E6%98%8E%09%E5%9B%BD%E5%86%85Steam%E5%B9%B3%E5%8F%B0%E4%B8%8A%EF%BC%8C%E8%AF%A5%E6%AC%BE%E6%B8%B8%E6%88%8F%E7%8E%B0%E5%94%AE%E4%BB%B7%E4%B8%BA82.8%E5%85%83%EF%BC%88%E5%8E%9F%E4%BB%B792%E5%85%83%EF%BC%89%E3%80%82%09%E6%AD%A4%E4%BB%B7%E6%A0%BC%E4%B8%BA%E9%A6%96%E5%8F%91%E4%BC%98%E6%83%A0%E6%97%B6%E6%9C%9F%E6%8A%98%E6%89%A3%E4%BB%B7%EF%BC%8C%E9%94%99%E8%BF%87%E5%B0%86%E6%97%A0%E6%B3%95%E5%9C%A8%E8%BF%91%E6%9C%9F%E5%86%85%E4%BA%AB%E5%8F%97%E7%B1%BB%E4%BC%BC%E4%BC%98%E6%83%A0%E3%80%82%09+%09%E8%B4%AD%E5%85%A5%E6%B8%B8%E6%88%8F%E7%9A%84%E6%8E%A8%E8%8D%90%09%E5%A6%82%E6%9E%9C%E6%82%A8%E5%AF%B9%E3%80%8ADrova+Forsaken+Kin%E3%80%8B%E6%84%9F%E5%85%B4%E8%B6%A3%EF%BC%8C%E5%B9%B6%E8%AE%A1%E5%88%92%E4%BB%A5%E4%BC%98%E6%83%A0%E4%BB%B7%E6%A0%BC%E8%B4%AD%E5%85%A5%EF%BC%8C%E5%BB%BA%E8%AE%AE%E5%9C%A8%E9%A6%96%E5%8F%91%E4%BC%98%E6%83%A0%E9%98%B6%E6%AE%B5&to=de </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SCRIPT_NAME</strong></div> <div class="col-md-9"><small> /index.php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CONTENT_LENGTH</strong></div> <div class="col-md-9"><small> </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CONTENT_TYPE</strong></div> <div class="col-md-9"><small> application/x-www-form-urlencoded;charset=UTF-8 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REQUEST_METHOD</strong></div> <div class="col-md-9"><small> GET </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>QUERY_STRING</strong></div> <div class="col-md-9"><small> s=/api/index/fanyi_article_title&content=Drova+Forsaken+Kin%E6%98%AF%E4%B8%80%E9%83%A8%E5%8F%96%E6%9D%90%E4%BA%8E%E7%BB%8F%E5%85%B8%E6%9A%97%E9%BB%91%E5%85%83%E7%B4%A0%E4%B8%8E%E5%87%AF%E5%B0%94%E7%89%B9%E7%A5%9E%E8%AF%9D%E7%A5%9E%E7%A7%98%E6%B0%94%E8%B4%A8%E7%9A%84%E5%83%8F%E7%B4%A0%E9%A3%8E%E6%A0%BC%E5%8A%A8%E4%BD%9C%E8%A7%92%E8%89%B2%E6%89%AE%E6%BC%94%E6%B8%B8%E6%88%8F%EF%BC%8C%E5%AE%A2%E6%88%B7%E5%8F%AF%E4%BE%9D%E6%8D%AE%E4%B8%AA%E4%BA%BA%E5%96%9C%E5%A5%BD%E5%8F%8A%E9%9C%80%E6%B1%82%E9%80%89%E8%B4%AD%E3%80%82%09Drova+Forsaken+Kin%E4%BB%B7%E6%A0%BC%E4%BB%8B%E7%BB%8D%09%E7%AD%94%EF%BC%9ADrova+Forsaken+Kin%E5%94%AE%E4%BB%B7%E4%B8%BA92%E5%85%83%E3%80%82%09%E5%85%B3%E4%BA%8E%E5%94%AE%E4%BB%B7%E8%AF%B4%E6%98%8E%09%E5%9B%BD%E5%86%85Steam%E5%B9%B3%E5%8F%B0%E4%B8%8A%EF%BC%8C%E8%AF%A5%E6%AC%BE%E6%B8%B8%E6%88%8F%E7%8E%B0%E5%94%AE%E4%BB%B7%E4%B8%BA82.8%E5%85%83%EF%BC%88%E5%8E%9F%E4%BB%B792%E5%85%83%EF%BC%89%E3%80%82%09%E6%AD%A4%E4%BB%B7%E6%A0%BC%E4%B8%BA%E9%A6%96%E5%8F%91%E4%BC%98%E6%83%A0%E6%97%B6%E6%9C%9F%E6%8A%98%E6%89%A3%E4%BB%B7%EF%BC%8C%E9%94%99%E8%BF%87%E5%B0%86%E6%97%A0%E6%B3%95%E5%9C%A8%E8%BF%91%E6%9C%9F%E5%86%85%E4%BA%AB%E5%8F%97%E7%B1%BB%E4%BC%BC%E4%BC%98%E6%83%A0%E3%80%82%09+%09%E8%B4%AD%E5%85%A5%E6%B8%B8%E6%88%8F%E7%9A%84%E6%8E%A8%E8%8D%90%09%E5%A6%82%E6%9E%9C%E6%82%A8%E5%AF%B9%E3%80%8ADrova+Forsaken+Kin%E3%80%8B%E6%84%9F%E5%85%B4%E8%B6%A3%EF%BC%8C%E5%B9%B6%E8%AE%A1%E5%88%92%E4%BB%A5%E4%BC%98%E6%83%A0%E4%BB%B7%E6%A0%BC%E8%B4%AD%E5%85%A5%EF%BC%8C%E5%BB%BA%E8%AE%AE%E5%9C%A8%E9%A6%96%E5%8F%91%E4%BC%98%E6%83%A0%E9%98%B6%E6%AE%B5&to=de </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>SCRIPT_FILENAME</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/public/index.php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>PHP_VALUE</strong></div> <div class="col-md-9"><small> open_basedir=/data/wwwroot/td.880772.xyz/public:/tmp/:/proc/:/data/wwwroot/td.880772.xyz/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>FCGI_ROLE</strong></div> <div class="col-md-9"><small> RESPONDER </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>PHP_SELF</strong></div> <div class="col-md-9"><small> /index.php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REQUEST_TIME_FLOAT</strong></div> <div class="col-md-9"><small> 1729593378.3352 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>REQUEST_TIME</strong></div> <div class="col-md-9"><small> 1729593378 </small></div> </div> </div> </div> <div> <div class="clearfix"> <div class="col-md-3"><strong>Environment Variables</strong></div> <div class="col-md-9"><small>empty</small></div> </div> </div> <div> <h3 class="subheading">ThinkPHP Constants</h3> <div> <div class="clearfix"> <div class="col-md-3"><strong>PUBLIC_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/public/../public/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>APP_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/public/../application/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>THINK_VERSION</strong></div> <div class="col-md-9"><small> 5.0.24 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>THINK_START_TIME</strong></div> <div class="col-md-9"><small> 1729593378.3356 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>THINK_START_MEM</strong></div> <div class="col-md-9"><small> 411280 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>EXT</strong></div> <div class="col-md-9"><small> .php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>DS</strong></div> <div class="col-md-9"><small> / </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>THINK_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/thinkphp/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>LIB_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/thinkphp/library/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CORE_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/thinkphp/library/think/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>TRAIT_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/thinkphp/library/traits/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>ROOT_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>EXTEND_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/extend/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>VENDOR_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/vendor/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>RUNTIME_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/runtime/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>LOG_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/runtime/log/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CACHE_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/runtime/cache/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>TEMP_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/runtime/temp/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CONF_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/public/../application/ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>CONF_EXT</strong></div> <div class="col-md-9"><small> .php </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>ENV_PREFIX</strong></div> <div class="col-md-9"><small> PHP_ </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>IS_CLI</strong></div> <div class="col-md-9"><small> false </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>IS_WIN</strong></div> <div class="col-md-9"><small> false </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>FILTER_VALIDATE_BOOL</strong></div> <div class="col-md-9"><small> 258 </small></div> </div> <div class="clearfix"> <div class="col-md-3"><strong>ADDON_PATH</strong></div> <div class="col-md-9"><small> /data/wwwroot/td.880772.xyz/addons/ </small></div> </div> </div> </div> </div> <div class="copyright"> <a title="官方网站" href="http://www.thinkphp.cn">ThinkPHP</a> <span>V5.0.24</span> <span>{ 十年磨一剑-为API开发设计的高性能框架 }</span> </div> <script> var LINE = 81; function $(selector, node){ var elements; node = node || document; if(document.querySelectorAll){ elements = node.querySelectorAll(selector); } else { switch(selector.substr(0, 1)){ case '#': elements = [node.getElementById(selector.substr(1))]; break; case '.': if(document.getElementsByClassName){ elements = node.getElementsByClassName(selector.substr(1)); } else { elements = get_elements_by_class(selector.substr(1), node); } break; default: elements = node.getElementsByTagName(); } } return elements; function get_elements_by_class(search_class, node, tag) { var elements = [], eles, pattern = new RegExp('(^|\\s)' + search_class + '(\\s|$)'); node = node || document; tag = tag || '*'; eles = node.getElementsByTagName(tag); for(var i = 0; i < eles.length; i++) { if(pattern.test(eles[i].className)) { elements.push(eles[i]) } } return elements; } } $.getScript = function(src, func){ var script = document.createElement('script'); script.async = 'async'; script.src = src; script.onload = func || function(){}; $('head')[0].appendChild(script); } ;(function(){ var files = $('.toggle'); var ol = $('ol', $('.prettyprint')[0]); var li = $('li', ol[0]); // 短路径和长路径变换 for(var i = 0; i < files.length; i++){ files[i].ondblclick = function(){ var title = this.title; this.title = this.innerHTML; this.innerHTML = title; } } // 设置出错行 var err_line = $('.line-' + LINE, ol[0])[0]; err_line.className = err_line.className + ' line-error'; $.getScript('//cdn.bootcss.com/prettify/r298/prettify.min.js', function(){ prettyPrint(); // 解决Firefox浏览器一个很诡异的问题 // 当代码高亮后,ol的行号莫名其妙的错位 // 但是只要刷新li里面的html重新渲染就没有问题了 if(window.navigator.userAgent.indexOf('Firefox') >= 0){ ol[0].innerHTML = ol[0].innerHTML; } }); })(); </script> </body> </html>
2024-10-22 Kommentar 0 1113

Artikeleinführung:Suchen von Autos, die alle Tests in einer Liste bestanden haben. Die vorliegende Aufgabe besteht darin, Autos aus einer „Autos“-Tabelle zu identifizieren, die alle Tests erfolgreich bestanden haben ...
2025-01-14 Kommentar 0 1101

Artikeleinführung:Den Kontrollfluss in .NET mit Yield und Await verstehen: Yield und Await, eingeführt in .NET, bieten syntaktischen Zucker für die Steuerungsverwaltung ...
2025-01-14 Kommentar 0 514

Artikeleinführung:System.Text.Json: Wie gebe ich einen benutzerdefinierten Namen für einen Enumerationswert an? Diese Funktion ist in .NET Core 3.0, .NET 5, .NET ... nicht sofort verfügbar.
2025-01-14 Kommentar 0 483

Artikeleinführung:Spaltenaliase und SELECT-AusdrückeIn SQL werden Spaltenaliase verwendet, um temporäre Namen für Ergebnisspalten bereitzustellen und so deren Referenzierung zu ermöglichen ...
2025-01-14 Kommentar 0 379

Artikeleinführung:Wählen Sie eine Gruppe von Zeilen aus, die allen Elementen in einer Liste entsprechen. Betrachten Sie zwei Tabellen:cars: Listet Autos mit ihren entsprechenden Modellnummern auf.passedtest: Zeichnet auf...
2025-01-14 Kommentar 0 1017

Artikeleinführung:Pivotieren mehrerer Spalten mit TablefuncFrage: Wie kann Tablefunc genutzt werden, um Daten auf mehreren Variablen zu plotten, anstatt nur die ... zu verwenden?
2025-01-14 Kommentar 0 1077

Artikeleinführung:Integration von C-Code in C#: Ein umfassender Leitfaden durch C /CLIDie nahtlose Integration von C-Code in C# ist seit langem ein gefragter...
2025-01-14 Kommentar 0 1028

Artikeleinführung:Aufrufen von C-Code aus C#In einem typischen Szenario kann die Verbindung mit externen Bibliotheken und Code, der in verschiedenen Programmiersprachen geschrieben ist, eine Herausforderung darstellen.
2025-01-14 Kommentar 0 945

Artikeleinführung:Während ich TypeScript lernte, wollte ich auch meine Fähigkeiten in React verbessern. React hatte mir bereits eine solide Grundlage für die Erstellung interaktiver Benutzeroberflächen gegeben, aber ich hatte das Gefühl, dass es noch mehr zu entdecken gab. Da machte mich mein Lehrer mit Next.js bekannt.
2025-01-14 Kommentar 0 585

Artikeleinführung:Behandeln nicht behandelter Ausnahmen in WinForms-AnwendungenIn WinForms-Anwendungen kann die standardmäßige Ausnahmebehandlung im Debug-Modus von der in... abweichen.
2025-01-14 Kommentar 0 709

Artikeleinführung:Dieses Tutorial führt Sie durch die Erstellung einer grundlegenden RESTful-API mit Go, dem Gin-Framework und den Open-Source-Bibliotheken Ginvalidator und Validatorgo. Diese Bibliotheken vereinfachen die Eingabevalidierung und machen Ihre API robuster. Wir erstellen eine API zur Verwaltung des Produktinventars. Die API unterstützt Sie
2025-01-14 Kommentar 0 735

Artikeleinführung:Überwindung schlüsselwortbasierter Spaltennamenkonflikte bei PostgreSQL-EinfügungenBeim Umgang mit PostgreSQL-Tabellen kann es zu Fehlern kommen, wenn...
2025-01-14 Kommentar 0 392
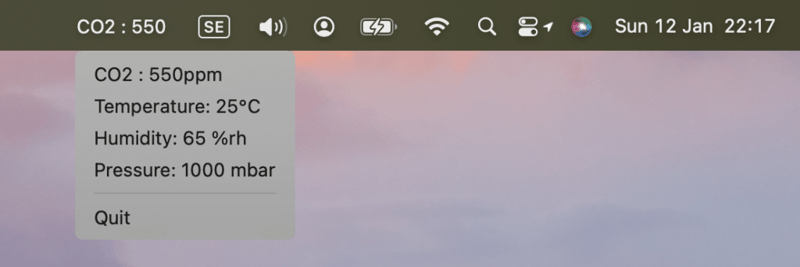
Artikeleinführung:Dieses Tutorial demonstriert den Aufbau einer Echtzeit-MacOS-Menüanwendung mithilfe eines BleuIOUSBBLE-Dongles zur Anzeige von Umgebungsdaten. BleuIO vereinfacht die BLE-Entwicklung (Bluetooth Low Energy) und eignet sich daher ideal für die Erstellung innovativer Projekte. MacOS-Menüleisten-Apps bieten eine diskrete Möglichkeit zur Überwachung
2025-01-14 Kommentar 0 740

Artikeleinführung:Auswirkungen des SQL Server-Upgrades auf die Zeilenreihenfolge in SELECT-Abfragen SQL Server 2012 führt eine wesentliche Änderung in der Handhabung der Zeilenreihenfolge für SELECT ein...
2025-01-14 Kommentar 0 1083

Artikeleinführung:Einführung Haben Sie schon einmal eine Website besucht, deren Laden ewig gedauert hat? Frustrierend, nicht wahr? Schnelle Ladezeiten und ein reibungsloses Benutzererlebnis sind nicht nur „nice-to-have“ – sie sind unerlässlich, um Besucher in der Nähe zu halten und in den Suchmaschinen weit oben zu ranken
2025-01-14 Kommentar 0 839


Artikeleinführung:C#-Reflexion: Klassenreferenzen aus Strings abrufenIm Bereich der C#-Programmierung besteht die Notwendigkeit, dynamisch auf Klassen basierend auf ihrer... zuzugreifen.
2025-01-14 Kommentar 0 337

Artikeleinführung:Der Assertionsmechanismus zur Kompilierungszeit der Go-Sprache wird verwendet, um bestimmte Bedingungen oder Einschränkungen in der Kompilierungsphase und nicht zur Laufzeit durchzusetzen. Wenn die Bedingungen nicht erfüllt sind, schlägt der Kompilierungsprozess fehl und meldet einen Fehler. Dies hilft, Fehler so früh wie möglich zu erkennen und sicherzustellen, dass das Programm vor der Ausführung bestimmte Invarianten oder Annahmen erfüllt. Assertionen zur Kompilierungszeit werden häufig verwendet, um sicherzustellen, dass Datenstrukturen die erwartete Größe haben. Stellen Sie sicher, dass der Wert einer Konstante oder eines Ausdrucks wie erwartet ist. Erzwingen Sie Typeinschränkungen oder andere Prüfungen zur Kompilierungszeit. Zusicherungen zur Kompilierungszeit in Go Die Go-Sprache selbst unterstützt Zusicherungen zur Kompilierungszeit nicht direkt wie einige andere Sprachen. Mit einigen cleveren Techniken können wir jedoch eine ähnliche Funktionalität erreichen. Hier sind einige gängige Methoden: Stellen Sie sicher, dass ein konstanter boolescher Ausdruck zur Kompilierungszeit wahr (oder falsch) ist: Wir können die folgenden Funktionen nutzen: Die Go-Sprachspezifikation ist klar
2025-01-14 Kommentar 0 779
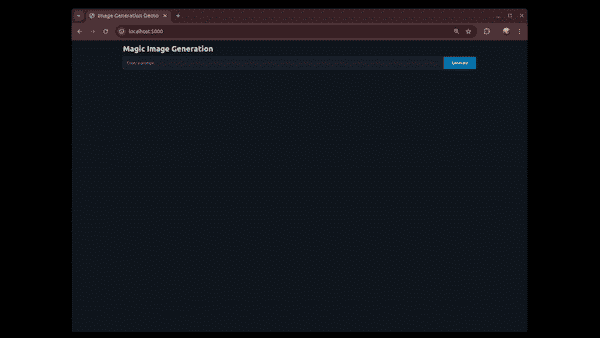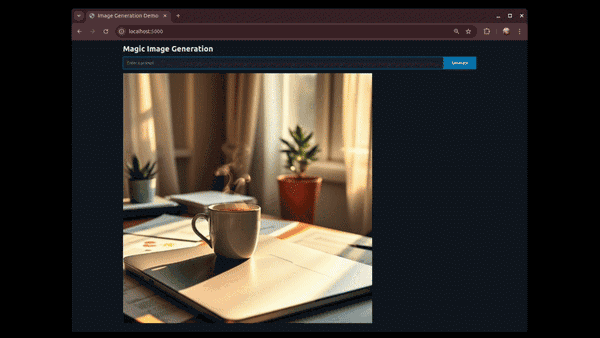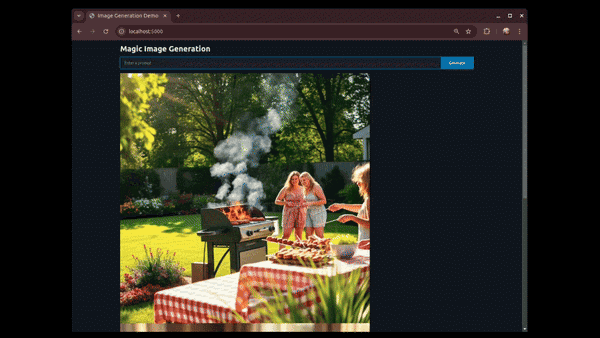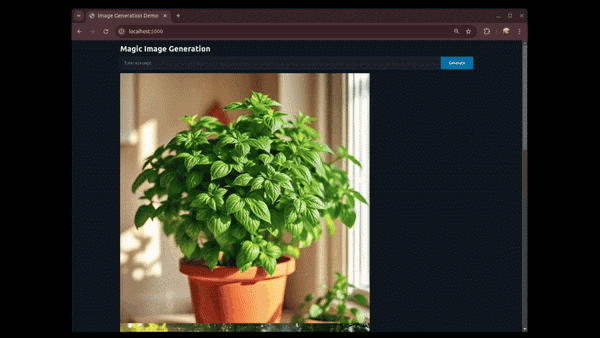
Artikeleinführung:FastHTML: Ein schneller Pfad zur Web-App-Entwicklung mit Python. Die Entwicklung neuer Anwendungen erfordert häufig die Beherrschung zahlreicher Tools und Frameworks. Für Python-Entwickler kann der Einstieg in HTML, CSS und JavaScript eine erhebliche Hürde darstellen. Umgekehrt können Webentwickler auf Python-Backend-Tools stoßen
2025-01-14 Kommentar 0 582