Insgesamt10000 bezogener Inhalt gefunden

Durch die Änderung einer Codezeile ist das PyTorch-Training dreimal schneller. Diese „fortschrittlichen Technologien' sind der Schlüssel
Artikeleinführung:Kürzlich hielt Sebastian Raschka, ein bekannter Forscher auf dem Gebiet des Deep Learning und Chefpädagoge für künstliche Intelligenz von LightningAI, auf der CVPR2023 eine Keynote-Rede mit dem Titel „ScalingPyTorchModelTrainingWithMinimalCodeChanges“. Um die Forschungsergebnisse mit mehr Menschen zu teilen, hat Sebastian Raschka die Rede in einem Artikel zusammengefasst. Der Artikel untersucht, wie das PyTorch-Modelltraining mit minimalen Codeänderungen skaliert werden kann, und zeigt, dass der Schwerpunkt auf der Nutzung von Mixed-Precision-Methoden und Multi-GPU-Trainingsmodi statt auf Maschinenoptimierungen auf niedriger Ebene liegt. Artikelverwendungsansicht
2023-08-14
Kommentar 0
956

Forschung zu Vorurteilen und Selbstkorrekturmethoden von Sprachmodellen
Artikeleinführung:Die Voreingenommenheit eines Sprachmodells besteht darin, dass es bei der Generierung von Text auf bestimmte Personengruppen, Themen oder Themen ausgerichtet sein kann, was dazu führt, dass der Text unvoreingenommen, neutral oder diskriminierend ist. Diese Verzerrung kann auf Faktoren wie die Auswahl der Trainingsdaten, das Design des Trainingsalgorithmus oder die Modellstruktur zurückzuführen sein. Um dieses Problem zu lösen, müssen wir uns auf die Datenvielfalt konzentrieren und sicherstellen, dass Trainingsdaten unterschiedliche Hintergründe und Perspektiven umfassen. Darüber hinaus sollten wir Trainingsalgorithmen und Modellstrukturen überprüfen, um ihre Fairness und Neutralität sicherzustellen und so die Qualität und Inklusivität des generierten Textes zu verbessern. Beispielsweise kann es zu einer übermäßigen Ausrichtung auf bestimmte Kategorien in den Trainingsdaten kommen, was dazu führt, dass das Modell diese Kategorien bei der Textgenerierung bevorzugt. Diese Verzerrung kann dazu führen, dass das Modell bei der Verarbeitung anderer Kategorien eine schlechte Leistung erbringt, was sich auf die Leistung des Modells auswirkt. Darüber hinaus kann es zu Abweichungen im Design des Modells kommen.
2024-01-22
Kommentar 0
454

Python implementiert die SVM-Klassifizierung (Support Vector Machine): Detaillierte Erläuterung der Algorithmusprinzipien
Artikeleinführung:Beim maschinellen Lernen werden Support Vector Machines (SVM) häufig zur Datenklassifizierung und Regressionsanalyse verwendet und sind diskriminante Algorithmusmodelle, die auf Trennungshyperebenen basieren. Mit anderen Worten: Bei gegebenen beschrifteten Trainingsdaten gibt der Algorithmus eine optimale Hyperebene zum Klassifizieren neuer Beispiele aus. Das SVM-Algorithmusmodell (Support Vector Machine) stellt Beispiele als Punkte im Raum dar. Nach der Zuordnung werden Beispiele verschiedener Kategorien so weit wie möglich unterteilt. Zusätzlich zur Durchführung einer linearen Klassifizierung können Support-Vektor-Maschinen (SVMs) effizient eine nichtlineare Klassifizierung durchführen, indem sie ihre Eingaben implizit in einen hochdimensionalen Merkmalsraum abbilden. Was macht eine Support-Vektor-Maschine? Bei einer Reihe von Trainingsbeispielen wird jedes Trainingsbeispiel mit einer Kategorie entsprechend zwei Kategorien markiert, und dann wird mithilfe des Support Vector Machine (SVM)-Trainingsalgorithmus ein Modell erstellt, um die neuen Beispiele zu klassifizieren
2024-01-24
Kommentar 0
1180

X-Dreamer durchbricht die dimensionale Wand und bringt hochwertigen Text in die 3D-Generierung, indem es die Bereiche der 2D- und 3D-Generierung integriert.
Artikeleinführung:In den letzten Jahren wurden erhebliche Fortschritte bei der automatischen Umwandlung von Text in 3D-Inhalte erzielt, angetrieben durch die Entwicklung vorab trainierter Diffusionsmodelle [1, 2, 3]. Unter anderem führte DreamFusion[4] eine effiziente Methode ein, die ein vorab trainiertes 2D-Diffusionsmodell[5] nutzt, um automatisch 3D-Assets aus Text zu generieren, ohne dass ein spezieller 3D-Asset-Datensatz erforderlich ist. Eine wichtige von DreamFusion eingeführte Innovation ist die fraktionierte Destillation (SDS)-Algorithmus. Der Algorithmus nutzt ein vorab trainiertes 2D-Diffusionsmodell, um eine einzelne 3D-Darstellung wie NeRF [6] auszuwerten und sie dadurch zu optimieren, um sicherzustellen, dass das gerenderte Bild aus jeder Kameraperspektive eine hohe Konsistenz mit dem gegebenen Text beibehält. Inspiriert durch den bahnbrechenden SDS-Algorithmus, mehrere
2023-12-15
Kommentar 0
595

ConvNeXt V2 verwendet hier nur die einfachste Faltungsarchitektur und ist hinsichtlich der Leistung Transformer nicht unterlegen
Artikeleinführung:Nach Jahrzehnten der Grundlagenforschung hat das Gebiet der visuellen Erkennung eine neue Ära des groß angelegten Lernens visueller Darstellungen eingeläutet. Vorab trainierte großformatige Vision-Modelle sind zu einem unverzichtbaren Werkzeug für Feature-Learning und Vision-Anwendungen geworden. Die Leistung eines Lernsystems für visuelle Darstellung wird stark von drei Hauptfaktoren beeinflusst: der neuronalen Netzwerkarchitektur des Modells, der zum Trainieren des Netzwerks verwendeten Methode und den Trainingsdaten. Verbesserungen bei jedem Faktor tragen zu einer Verbesserung der Gesamtleistung des Modells bei. Innovationen im Design neuronaler Netzwerkarchitekturen haben im Bereich des Repräsentationslernens schon immer eine wichtige Rolle gespielt. Die Convolutional Neural Network Architecture (ConvNet) hatte einen erheblichen Einfluss auf die Computer-Vision-Forschung und ermöglichte den Einsatz universeller Feature-Learning-Methoden bei verschiedenen visuellen Erkennungsaufgaben, ohne auf künstliche Intelligenz angewiesen zu sein.
2023-04-11
Kommentar 0
1480

Grundprinzipien und Beispiele der KNN-Algorithmusklassifizierung
Artikeleinführung:Der KNN-Algorithmus ist ein einfacher und benutzerfreundlicher Klassifizierungsalgorithmus, der für kleine Datensätze und niedrigdimensionale Merkmalsräume geeignet ist. Es schneidet in Bereichen wie der Bildklassifizierung und der Textklassifizierung gut ab und ist wegen seiner einfachen Implementierung und leichten Verständlichkeit beliebt. Die Grundidee des KNN-Algorithmus besteht darin, die nächsten K Nachbarn zu finden, indem die Merkmale der zu klassifizierenden Stichprobe mit den Merkmalen der Trainingsstichprobe verglichen werden, und anhand dieser Kategorien die Kategorie der zu klassifizierenden Stichprobe zu bestimmen K Nachbarn. Der KNN-Algorithmus verwendet einen Trainingssatz mit beschrifteten Kategorien und einen zu klassifizierenden Testsatz. Der Klassifizierungsprozess des KNN-Algorithmus umfasst die folgenden Schritte: Berechnen Sie zunächst den Abstand zwischen der zu klassifizierenden Stichprobe und allen Trainingsstichproben. Wählen Sie dann die K nächsten Nachbarn aus, um die zu erhalten Klassifizierungsbeispielkategorie;
2024-01-23
Kommentar 0
773

Symbolischer Algorithmus zur Rückkehr zum Ursprung
Artikeleinführung:Der symbolische Regressionsalgorithmus ist ein maschineller Lernalgorithmus, der automatisch mathematische Modelle erstellt. Sein Hauptziel besteht darin, den Wert der Ausgabevariablen vorherzusagen, indem die funktionale Beziehung zwischen den Variablen in den Eingabedaten analysiert wird. Dieser Algorithmus kombiniert die Ideen genetischer Algorithmen und evolutionärer Strategien, um die Genauigkeit des Modells durch zufälliges Generieren und Kombinieren mathematischer Ausdrücke schrittweise zu verbessern. Durch die kontinuierliche Optimierung des Modells können symbolische Regressionsalgorithmen uns helfen, komplexe Datenbeziehungen besser zu verstehen und vorherzusagen. Der Prozess des symbolischen Regressionsalgorithmus ist wie folgt: 1. Definieren Sie das Problem: Bestimmen Sie die Eingabevariablen und Ausgabevariablen. 2. Initialisieren Sie die Population: Generieren Sie zufällig eine Reihe mathematischer Ausdrücke als Population. Fitness bewerten: Verwenden Sie den mathematischen Ausdruck jedes Einzelnen, um die Daten im Trainingssatz vorherzusagen, und berechnen Sie den Fehler zwischen dem vorhergesagten Wert und dem tatsächlichen Wert als Anpassung
2024-01-23
Kommentar 0
1443

Einführung in das Gameplay des gemeinsamen Trainingsgeländes „White Wattle Corridor'.
Artikeleinführung:Wie spielt man auf dem Baijing Corridor Joint Training Ground? Der Joint Training Ground ist einer der Spielmodi von White Wattle Corridor. Spieler können sich den Artikelinhalt ansehen, um mehr über das Gameplay des Joint Training Ground zu erfahren Ich glaube, dass die Einführung in das Gameplay des White Wattle Corridor Joint Training Ground für Sie hilfreich sein wird. Werfen wir einen Blick darauf. Gameplay-Einführung zum gemeinsamen Trainingsgelände „Baijing Corridor“: 1. Zuerst müssen die Spieler vier Verteidigungszonen A, B, C und D in der Reihenfolge der Zeit erobern. Es gibt 3 Abschnitte unter A, B, C und D. 2. Der Spieler platziert jeweils einen Charakter in der quadratischen Lagerecke und dem Rhombus-Beruf zum Kämpfen und wird hier stationiert. 3. Schließlich basiert die Punktzahl auf den Kampfergebnissen. Bewertungsregeln: 1. Alle 1.000 Punkte erhöht die Anzahl der Abzugssitze um 5 %, und der Abzugsfortschritt gibt das Maximum an
2024-01-12
Kommentar 0
1227

Funktionen und Methoden zur Optimierung von Hyperparametern
Artikeleinführung:Hyperparameter sind Parameter, die vor dem Training des Modells festgelegt werden müssen. Sie können nicht aus Trainingsdaten gelernt werden und müssen manuell angepasst oder durch automatische Suche ermittelt werden. Zu den gängigen Hyperparametern gehören Lernrate, Regularisierungskoeffizient, Anzahl der Iterationen, Stapelgröße usw. Hyperparameter-Tuning ist der Prozess zur Optimierung der Algorithmusleistung und ist sehr wichtig, um die Genauigkeit und Leistung des Algorithmus zu verbessern. Der Zweck der Hyperparameter-Optimierung besteht darin, die beste Kombination von Hyperparametern zu finden, um die Leistung und Genauigkeit des Algorithmus zu verbessern. Wenn die Abstimmung unzureichend ist, kann dies zu einer schlechten Algorithmusleistung und Problemen wie Über- oder Unteranpassung führen. Durch Optimierung kann die Generalisierungsfähigkeit des Modells verbessert und seine Leistung bei neuen Daten verbessert werden. Daher ist es wichtig, die Hyperparameter vollständig abzustimmen. Es gibt viele Methoden zur Hyperparameter-Optimierung. Zu den gängigen Methoden gehören die Rastersuche, die Zufallssuche und die Bayes'sche Optimierung.
2024-01-22
Kommentar 0
796

Automatische Lernmaschine (AutoML)
Artikeleinführung:Automatisches maschinelles Lernen (AutoML) ist ein Game-Changer im Bereich des maschinellen Lernens. Es kann Algorithmen automatisch auswählen und optimieren, wodurch der Prozess des Trainierens von Modellen für maschinelles Lernen einfacher und effizienter wird. Selbst wenn Sie keine Erfahrung mit maschinellem Lernen haben, können Sie mithilfe von AutoML problemlos ein Modell mit hervorragender Leistung trainieren. AutoML bietet einen erklärbaren KI-Ansatz zur Verbesserung der Modellinterpretierbarkeit. Auf diese Weise können Datenwissenschaftler Einblicke in den Vorhersageprozess des Modells gewinnen. Dies ist besonders nützlich in den Bereichen Gesundheitswesen, Finanzen und autonome Systeme. Es kann dabei helfen, Verzerrungen in Daten zu erkennen und falsche Vorhersagen zu verhindern. AutoML nutzt maschinelles Lernen, um reale Probleme zu lösen, einschließlich Aufgaben wie Algorithmusauswahl, Hyperparameteroptimierung und Feature-Engineering. Hier sind einige häufig verwendete Methoden: Gott
2024-01-22
Kommentar 0
953

Kann Menschen ohne RLHF ausrichten, Leistung vergleichbar mit ChatGPT! Chinesisches Team schlägt Wombat-Modell vor
Artikeleinführung:ChatGPT von OpenAI ist in der Lage, eine Vielzahl menschlicher Anweisungen zu verstehen und verschiedene Sprachaufgaben gut zu bewältigen. Dies ist dank einer neuartigen Methode zur Feinabstimmung groß angelegter Sprachmodelle namens RLHF (Aligned Human Feedback via Reinforcement Learning) möglich. Die RLHF-Methode erschließt die Fähigkeit von Sprachmodellen, menschlichen Anweisungen zu folgen, wodurch die Fähigkeiten von Sprachmodellen mit menschlichen Bedürfnissen und Werten in Einklang gebracht werden. Derzeit verwendet die Forschungsarbeit von RLHF hauptsächlich den PPO-Algorithmus zur Optimierung von Sprachmodellen. Der PPO-Algorithmus enthält jedoch viele Hyperparameter und erfordert die Zusammenarbeit mehrerer unabhängiger Modelle während des Iterationsprozesses des Algorithmus, sodass falsche Implementierungsdetails zu schlechten Trainingsergebnissen führen können. Gleichzeitig sind Reinforcement-Learning-Algorithmen aus Sicht der menschlichen Ausrichtung nicht erforderlich. Argument
2023-05-03
Kommentar 0
1355

Deep Thinking | Wo liegt die Leistungsgrenze großer Modelle?
Artikeleinführung:Wenn wir über unendliche Ressourcen wie unendliche Daten, unendliche Rechenleistung, unendliche Modelle, perfekte Optimierungsalgorithmen und Generalisierungsleistung verfügen, kann das resultierende vorab trainierte Modell dann zur Lösung aller Probleme verwendet werden? Dies ist eine Frage, die allen große Sorgen bereitet, aber bestehende Theorien des maschinellen Lernens können sie nicht beantworten. Es hat nichts mit der Ausdrucksfähigkeitstheorie zu tun, da das Modell unendlich ist und die Ausdrucksfähigkeit von Natur aus unendlich ist. Es hat auch nichts mit der Optimierungs- und Generalisierungstheorie zu tun, da wir davon ausgehen, dass die Optimierungs- und Generalisierungsleistung des Algorithmus perfekt ist. Mit anderen Worten: Die Probleme der bisherigen theoretischen Forschung bestehen hier nicht mehr! Heute möchte ich Ihnen das Papier OnthePowerofFoundationModels vorstellen, das ich auf der ICML'2023 veröffentlicht habe. Aus der Perspektive der Kategorientheorie.
2023-09-08
Kommentar 0
1318

Überanpassungsproblem bei maschinellen Lernalgorithmen
Artikeleinführung:Das Problem der Überanpassung bei Algorithmen für maschinelles Lernen erfordert spezifische Codebeispiele. Im Bereich des maschinellen Lernens ist das Problem der Überanpassung von Modellen eine der häufigsten Herausforderungen. Wenn ein Modell die Trainingsdaten übermäßig anpasst, wird es übermäßig empfindlich gegenüber Rauschen und Ausreißern, was dazu führt, dass das Modell bei neuen Daten eine schlechte Leistung erbringt. Um das Problem der Überanpassung zu lösen, müssen wir während des Modelltrainingsprozesses einige wirksame Methoden anwenden. Ein gängiger Ansatz besteht darin, Regularisierungstechniken wie L1-Regularisierung und L2-Regularisierung zu verwenden. Diese Techniken begrenzen die Komplexität des Modells, indem sie einen Strafterm hinzufügen, um zu verhindern, dass das Modell es übertreibt
2023-10-09
Kommentar 0
1024

Wie beeinflussen Merkmale die Wahl des Modelltyps?
Artikeleinführung:Funktionen spielen beim maschinellen Lernen eine wichtige Rolle. Beim Erstellen eines Modells müssen wir die zu trainierenden Funktionen sorgfältig auswählen. Die Auswahl der Funktionen wirkt sich direkt auf die Leistung und den Typ des Modells aus. In diesem Artikel wird untersucht, wie sich Features auf den Modelltyp auswirken. 1. Anzahl der Features Die Anzahl der Features ist einer der wichtigen Faktoren, die den Modelltyp beeinflussen. Wenn die Anzahl der Merkmale gering ist, werden normalerweise herkömmliche Algorithmen für maschinelles Lernen wie lineare Regression, Entscheidungsbäume usw. verwendet. Diese Algorithmen eignen sich für die Verarbeitung einer kleinen Anzahl von Merkmalen und die Berechnungsgeschwindigkeit ist relativ hoch. Wenn jedoch die Anzahl der Merkmale sehr groß wird, nimmt die Leistung dieser Algorithmen normalerweise ab, da sie Schwierigkeiten bei der Verarbeitung hochdimensionaler Daten haben. Daher müssen wir in diesem Fall fortschrittlichere Algorithmen wie Support-Vektor-Maschinen, neuronale Netze usw. verwenden. Diese Algorithmen sind in der Lage, hochdimensionale Daten zu verarbeiten
2024-01-24
Kommentar 0
1023

Tipps zur Modellbewertung für maschinelles Lernen in Python
Artikeleinführung:Maschinelles Lernen ist ein komplexes Feld, das zahlreiche Techniken und Methoden umfasst, die bei der Lösung realer Probleme häufige Tests und Bewertungen der Modellleistung erfordern. Modellbewertungstechniken für maschinelles Lernen sind sehr wichtige Fähigkeiten in Python, da sie Entwicklern dabei helfen, festzustellen, wann ein Modell zuverlässig ist und wie es bei einem bestimmten Datensatz funktioniert. Hier sind einige gängige Techniken zur Modellbewertung für maschinelles Lernen in Python: Kreuzvalidierung Kreuzvalidierung ist eine statistische Technik, die häufig zur Bewertung der Leistung von Algorithmen für maschinelles Lernen verwendet wird. Der Datensatz ist in Training unterteilt
2023-06-10
Kommentar 0
1695
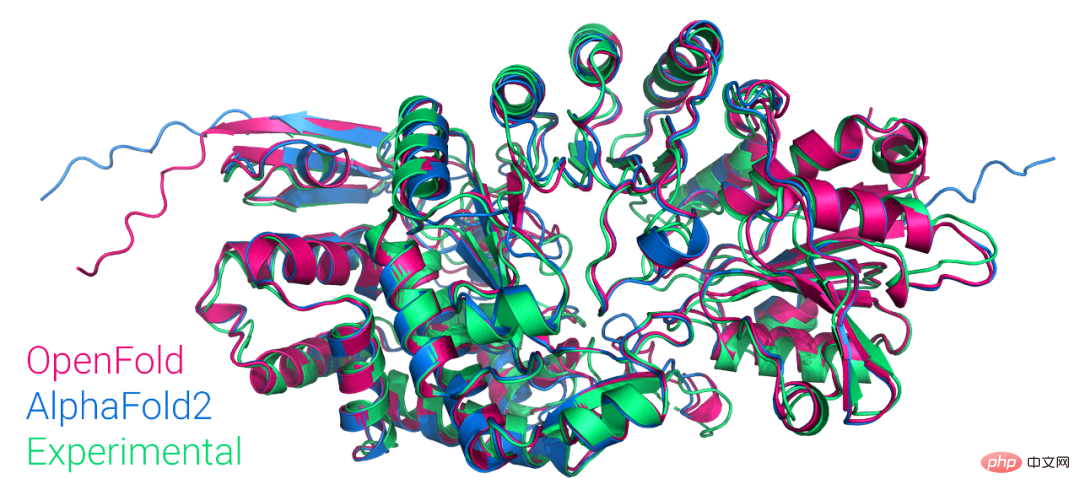
Die erste öffentlich verfügbare PyTorch-Version von AlphaFold2 wird reproduziert, ist Open Source von der Columbia University und hat mehr als 1.000 Sterne
Artikeleinführung:Gerade erst gab Mohammed AlQuraishi, Assistenzprofessor für Systembiologie an der Columbia University, auf Twitter bekannt, dass sie ein Modell namens OpenFold von Grund auf trainiert haben, bei dem es sich um eine trainierbare PyTorch-Wiederaufführung von AlphaFold2 handelt. Mohammed AlQuraishi erklärte außerdem, dass dies die erste öffentlich zugängliche Reproduktion von AlphaFold2 sei. AlphaFold2 kann Proteinstrukturen in regelmäßigen Abständen mit atomarer Präzision vorhersagen. Dabei kommt eine Technologie zum Einsatz, die Multi-Sequenz-Alignment und Deep-Learning-Algorithmen nutzt, kombiniert mit physikalischem und biologischem Wissen über Proteinstrukturen, um die Vorhersagen zu verbessern. Es erzielt hervorragende Ergebnisse bei der Vorhersage von 2/3 Proteinstrukturen.
2023-04-13
Kommentar 0
1252

Das erste LLM, das die 4-Bit-Gleitkomma-Quantisierung unterstützt, ist da und löst die Bereitstellungsprobleme von LLaMA, BERT usw.
Artikeleinführung:Die Komprimierung großer Sprachmodelle (LLM) hat schon immer große Aufmerksamkeit auf sich gezogen, und die Post-Training-Quantisierung ist einer der am häufigsten verwendeten Algorithmen. Die meisten vorhandenen PTQ-Methoden sind jedoch Ganzzahlquantisierung und die Anzahl der Bits kleiner als 8 ist, wird die Genauigkeit des Modells nach der Quantisierung erheblich sinken. Im Vergleich zur Integer-Quantifizierung (INT) kann die FloatingPoint-Quantifizierung (FP) die Long-Tail-Verteilung besser darstellen, sodass immer mehr Hardwareplattformen die FP-Quantifizierung unterstützen. Dieser Artikel bietet eine Lösung für die FP-Quantifizierung großer Modelle. Der Artikel wurde auf EMNLP2023 veröffentlicht. Papieradresse: https://arxiv.org/abs/2310.16
2023-11-18
Kommentar 0
1161

Die Nachtaufnahmeleistung des Redmi K70 Pro wurde dank des Xiaomi Night Owl-Algorithmus erheblich verbessert
Artikeleinführung:Laut Nachrichten vom 27. November hat Redmi kürzlich sein neuestes Mobiltelefon K70Pro herausgebracht. Dieses Telefon ist nicht nur mit der optischen Anti-Shake-Technologie OIS ausgestattet, sondern führt auch erstmals den von Xiaomi entwickelten Night Owl-Algorithmus ein, der Benutzern ein beispielloses Nachtaufnahmeerlebnis bietet. Nach dem Verständnis des Herausgebers wurde der Night Owl-Algorithmus ursprünglich eingeführt auf Xiaomi 11 Ultra. Dieser Algorithmus konzentriert sich auf die Lösung häufiger Lärmprobleme bei der Nachtfotografie. Durch das unabhängig entwickelte System zur Kalibrierung von Nachtszenenlärm führt er eine genaue mathematische Modellierung der Verteilung und Form des Nachtszenenrauschens durch. Um die Wirkung des Night Owl-Algorithmus zu verbessern, hat das Ingenieurteam von Xiaomi eine innovative Methode eingeführt, um die Vielfalt der simulierten Geräuschdaten zu erhöhen, indem der Simulation Rauschen hinzugefügt wird, wodurch die Trainingsdaten des Algorithmus angereichert und der Entrauschungsprozess durchgeführt wird
2023-11-27
Kommentar 0
1697

Verstehen Sie Reinforcement Learning und seine Anwendungsszenarien
Artikeleinführung:Der beste Weg, einen Hund zu erziehen, besteht darin, ein Belohnungssystem zu verwenden, um ihn für gutes Verhalten zu belohnen und ihn für schlechtes Verhalten zu bestrafen. Die gleiche Strategie kann für maschinelles Lernen verwendet werden, das sogenannte Reinforcement Learning. Reinforcement Learning ist ein Zweig des maschinellen Lernens, der Modelle durch Entscheidungsfindung trainiert, um die beste Lösung für ein Problem zu finden. Um die Modellgenauigkeit zu verbessern, können positive Belohnungen verwendet werden, um den Algorithmus zu ermutigen, der richtigen Antwort näher zu kommen, während negative Belohnungen vergeben werden können, um Abweichungen vom Ziel zu bestrafen. Sie müssen nur die Ziele klären und dann die Daten modellieren. Das Modell beginnt, mit den Daten zu interagieren und ohne manuellen Eingriff Lösungen vorzuschlagen. Beispiel für Verstärkungslernen Nehmen wir als Beispiel das Hundetraining. Wir stellen Belohnungen wie Hundekekse zur Verfügung, um den Hund zu verschiedenen Aktionen zu bewegen. Der Hund verfolgt Belohnungen nach einer bestimmten Strategie, befolgt also Befehle und lernt neue Handlungen, wie zum Beispiel Betteln
2024-01-22
Kommentar 0
1407

China Unicom veröffentlicht ein KI-Modell für große Bilder und Texte, das Bilder und Videoclips aus Text generieren kann
Artikeleinführung:Driving China News am 28. Juni 2023, heute während des Mobile World Congress in Shanghai, veröffentlichte China Unicom das Grafikmodell „Honghu Graphic Model 1.0“. China Unicom sagte, dass das Honghu-Grafikmodell das erste große Modell für Mehrwertdienste von Betreibern sei. Ein Reporter von China Business News erfuhr, dass das Grafikmodell von Honghu derzeit über zwei Versionen von 800 Millionen Trainingsparametern und 2 Milliarden Trainingsparametern verfügt, mit denen Funktionen wie textbasierte Bilder, Videobearbeitung und bildbasierte Bilder realisiert werden können. Darüber hinaus sagte Liu Liehong, Vorsitzender von China Unicom, in seiner heutigen Grundsatzrede, dass generative KI eine einzigartige Entwicklung einleitet und 50 % der Arbeitsplätze in den nächsten zwei Jahren stark von künstlicher Intelligenz betroffen sein werden.
2023-06-29
Kommentar 0
1511
