Insgesamt10000 bezogener Inhalt gefunden
Quantifizierung, Beschneidung, Destillation, was genau sagen diese großen Modell-Slangs aus?
Artikeleinführung:Quantifizierung, Beschneidung, Destillation: Wenn Sie häufig auf große Sprachmodelle achten, werden Sie diese Wörter auf jeden Fall sehen. Es ist für uns schwierig zu verstehen, was sie bewirken, aber diese Wörter sind für die Entwicklung besonders wichtig großer Sprachmodelle in dieser Phase. Dieser Artikel wird Ihnen helfen, sie kennenzulernen und ihre Prinzipien zu verstehen. Modellkomprimierungsquantisierung, -bereinigung und -destillation sind eigentlich allgemeine Modellkomprimierungstechnologien für neuronale Netzwerke und nicht ausschließlich auf große Sprachmodelle anwendbar. Die Bedeutung der Modellkomprimierung: Nach der Komprimierung wird die Modelldatei kleiner, der verwendete Festplattenspeicher wird ebenfalls kleiner, der Cache-Speicherplatz, der beim Laden in den Speicher oder bei der Anzeige verwendet wird, wird ebenfalls kleiner und die Laufgeschwindigkeit des Modells kann ebenfalls kleiner werden verbessert werden. Durch die Komprimierung verbraucht die Verwendung des Modells weniger Rechenressourcen und kann stark skaliert werden
2024-04-26
Kommentar 0
800

Detaillierte Erläuterung der Beispiele für PS-Ebenen-Mischmodi
Artikeleinführung:Viele Konzepte in PS ähneln denen in Core Graphics, wie z. B. Masken, Pfade, Beschneidung, Mischmodi usw. Wenn Sie den Mischmodus in Core Graphics nicht ganz verstehen, kann Ihnen die Lektüre dieses Artikels ein rationaleres Verständnis und Verständnis für das Konzept des Mischmodus in Core Graphics vermitteln. In diesem Artikel werden keine Mischmodi in iOS behandelt. Ich hoffe, dieser Artikel ist hilfreich für Sie.
2017-02-14
Kommentar 0
3914

10 empfohlene Artikel über PS-Ebenen-Mischmodi
Artikeleinführung:Viele Konzepte in PS ähneln denen in Core Graphics, wie z. B. Masken, Pfade, Beschneidung, Mischmodi usw. Wenn Sie den Mischmodus in Core Graphics nicht ganz verstehen, kann Ihnen die Lektüre dieses Artikels ein rationaleres Verständnis und Verständnis für das Konzept des Mischmodus in Core Graphics vermitteln. In diesem Artikel werden keine Mischmodi in iOS behandelt. Ich hoffe, dieser Artikel ist hilfreich für Sie. Der Ebenenüberblendungsmodus bestimmt das aktuelle Bild ...
2017-06-15
Kommentar 0
1882

Mithilfe von maschinellem Lernen Gesichter in Videos rekonstruieren
Artikeleinführung:Übersetzer |. Rezensiert von Cui Hao |. Diese Technologie kann die Gesichtsstruktur mit hoher Konsistenz und ohne Spuren künstlicher Beschneidung vergrößern und verkleinern. Typischerweise wird diese Transformation der Gesichtsstruktur durch traditionelle CGI-Methoden erreicht, die auf detaillierten und teuren Verfahren zur Bewegungsbegrenzung, Rigging und Texturierung basieren, um das Gesicht vollständig zu rekonstruieren. Im Gegensatz zu herkömmlichen Methoden wird CGI in der neuen Technologie als Parameter für 3D-Gesichtsinformationen in die neuronale Pipeline integriert und dient als Grundlage für den maschinellen Lernworkflow. Der Autor betont: „Unser Ziel ist es, Gesichtskonturen basierend auf natürlichen Gesichtern in der realen Welt zu verfeinern.“
2023-04-08
Kommentar 0
1093

Huawei P70-Serie vorgestellt: einzigartige 1-Zoll-Hauptkamera + neues Linsendesign für ein hervorragendes Bilderlebnis
Artikeleinführung:Laut Nachrichten von Digital Chat Station verfügen Huaweis kommende Flaggschiff-Handys der P70-Serie über große Verbesserungen bei den Kameras. Es wird berichtet, dass die Top-Version den Sony IMX989-Sensor verwenden wird, eine Hauptkamera mit einer supergroßen 1-Zoll-Basis ohne jegliche Beschneidung. Diese Konfiguration macht die Huawei P70-Serie zum bisher leistungsstärksten Flaggschiff der Marke in Bezug auf die Bildqualität. Diese Nachricht ist zweifellos eine gute Nachricht für Huawei-Fans. Sony IMX989 nutzt die Quad-Bayer-Color-Array-Technologie, die den Dynamikbereich der Kamera erheblich verbessern kann und dadurch klarere Fotos mit weniger Rauschen in Umgebungen mit wenig Licht aufnimmt. Darüber hinaus erfuhr die Redaktion, dass auch die Huawei P70-Serie mit Innovationen ausgestattet ist
2024-01-09
Kommentar 0
873

Das Team von Chen Danqi bringt Ihnen Schritt für Schritt bei, wie man „Alpaka' schert, und schlägt die LLM-Shearing-Methode zum Beschneiden großer Modelle vor
Artikeleinführung:Welchen Effekt hat das Schneiden der Haare des großen Modells Llama2 (Alpaka)? Heute hat das Chen Danqi-Team der Princeton University eine Methode zur Beschneidung großer Modelle namens LLM-Shearing vorgeschlagen, mit der mit geringem Rechen- und Kostenaufwand eine bessere Leistung als Modelle gleicher Größe erzielt werden kann. Seit dem Aufkommen großer Sprachmodelle (LLMs) haben sie bei verschiedenen Aufgaben der natürlichen Sprache bemerkenswerte Ergebnisse erzielt. Für das Training großer Sprachmodelle sind jedoch enorme Rechenressourcen erforderlich. Daher ist die Branche mit dem Aufkommen von LLaMA, MPT und Falcon zunehmend daran interessiert, gleichermaßen leistungsstarke Modelle mittlerer Größe zu bauen, die eine effiziente Inferenz und Feinabstimmung ermöglichen. Diese LLMs unterschiedlicher Größe eignen sich für unterschiedliche Anwendungsfälle, aber jedes einzelne Modell wird von Grund auf trainiert (sogar).
2023-10-12
Kommentar 0
1349

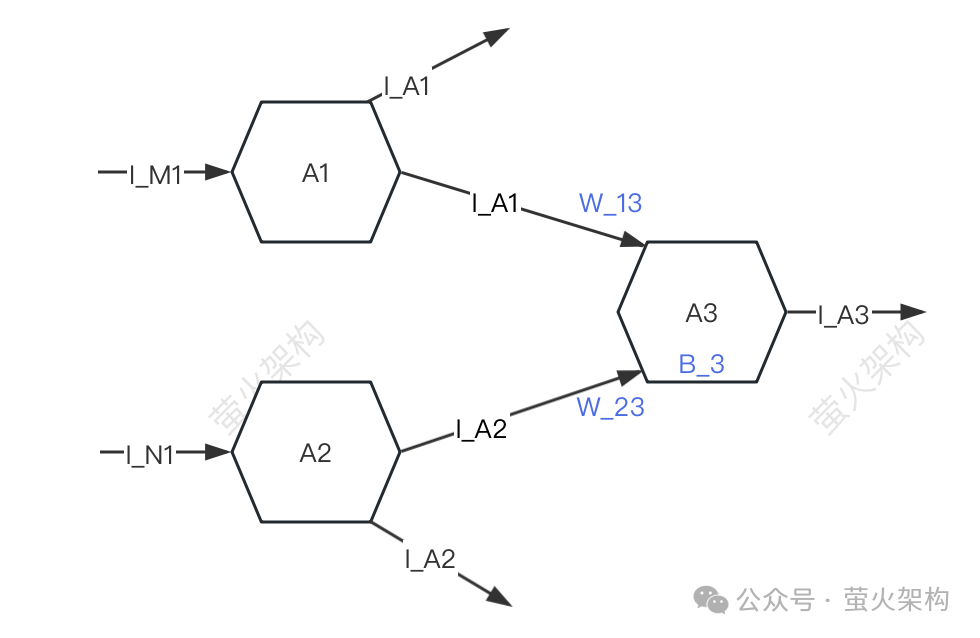
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Artikeleinführung:Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Modellreihe Llama3.1, zu der das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit Parameterbeträgen von 70 Milliarden bzw. 8 Milliarden gehören. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher hat sich in der Branche ein weiterer Trend herausgebildet, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
2024-08-16
Kommentar 0
416
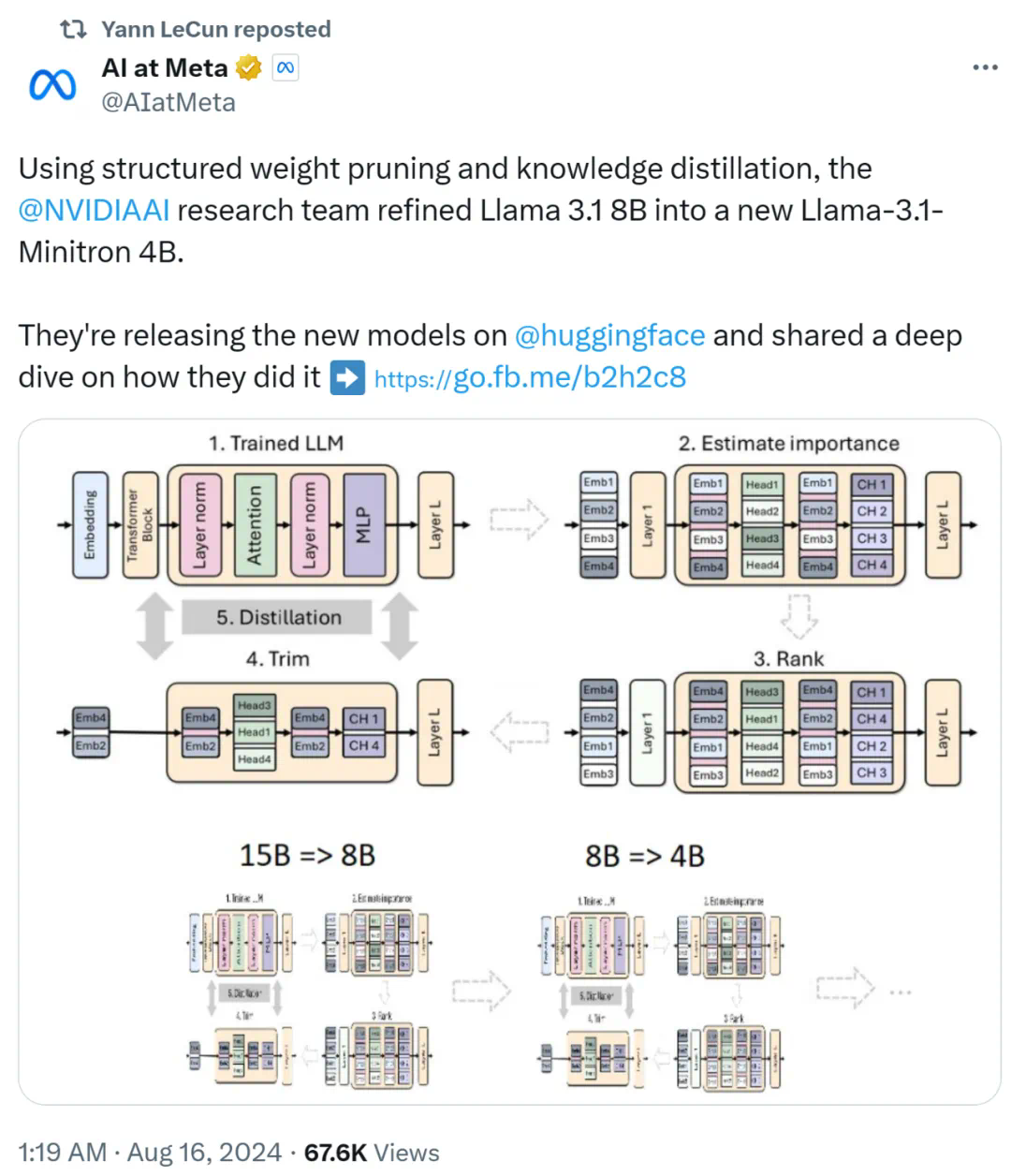
Nvidia spielt mit Beschneidung und Destillation: Halbierung der Llama 3.1 8B-Parameter, um bei gleicher Größe eine bessere Leistung zu erzielen
Artikeleinführung:Der Aufstieg kleiner Modelle. Letzten Monat veröffentlichte Meta die Llama3.1-Modellreihe, die das bisher größte Modell von Meta, das 405B-Modell, und zwei kleinere Modelle mit 70 Milliarden bzw. 8 Milliarden Parametern umfasst. Llama3.1 gilt als der Beginn einer neuen Ära von Open Source. Obwohl die Modelle der neuen Generation leistungsstark sind, erfordern sie bei der Bereitstellung immer noch große Mengen an Rechenressourcen. Daher ist in der Branche ein weiterer Trend entstanden, der darin besteht, kleine Sprachmodelle (SLM) zu entwickeln, die bei vielen Sprachaufgaben eine ausreichende Leistung erbringen und zudem sehr kostengünstig in der Bereitstellung sind. Kürzlich haben Untersuchungen von NVIDIA gezeigt, dass durch strukturierte Gewichtsbereinigung in Kombination mit Wissensdestillation nach und nach kleinere Sprachmodelle aus einem zunächst größeren Modell gewonnen werden können. Turing-Preisträger, Meta Chief A
2024-08-16
Kommentar 0
1054

Machen Sie große Modelle um 90 % „schlank'! Die Tsinghua-Universität und das Harbin Institute of Technology schlugen eine extreme Komprimierungslösung vor: 1-Bit-Quantisierung unter Beibehaltung von 83 % der Kapazität.
Artikeleinführung:Quantisierungs-, Bereinigungs- und andere Komprimierungsvorgänge an großen Modellen sind die häufigsten Bestandteile der Bereitstellung. Doch wie hoch ist diese Grenze? Eine gemeinsame Studie der Tsinghua-Universität und des Harbin Institute of Technology ergab die Antwort: 90 %. Sie schlugen OneBit vor, ein 1-Bit-Framework zur extremen Komprimierung großer Modelle, das erstmals eine Gewichtskomprimierung großer Modelle von über 90 % erreichte und gleichzeitig die meisten Funktionen (83 %) beibehielt. Man kann sagen, dass es beim Spielen um „sowohl Wollen als auch Wollen“ geht ~ Werfen wir einen Blick darauf. Die 1-Bit-Quantisierungsmethode für große Modelle reicht von der Beschneidung und Quantisierung bis hin zur Wissensdestillation und der Zerlegung niedriger Ränge. Große Modelle können bereits ein Viertel des Gewichts fast ohne Verlust komprimieren. Die Gewichtsquantifizierung wandelt typischerweise die Parameter eines großen Modells in eine Darstellung mit geringer Bitbreite um. Dies kann durch Konvertieren eines vollständig trainierten Modells erreicht werden (
2024-03-11
Kommentar 0
1027
So installieren Sie das Win7-Betriebssystem auf dem Computer
Artikeleinführung:Unter den Computer-Betriebssystemen ist das WIN7-System ein sehr klassisches Computer-Betriebssystem. Wie installiert man also das Win7-System? Der folgende Editor stellt detailliert vor, wie Sie das Win7-System auf Ihrem Computer installieren. 1. Laden Sie zunächst das Xiaoyu-System herunter und installieren Sie die Systemsoftware erneut auf Ihrem Desktop-Computer. 2. Wählen Sie das Win7-System aus und klicken Sie auf „Dieses System installieren“. 3. Beginnen Sie dann mit dem Herunterladen des Image des Win7-Systems. 4. Stellen Sie nach dem Herunterladen die Umgebung bereit und klicken Sie nach Abschluss auf Jetzt neu starten. 5. Nach dem Neustart des Computers erscheint die Windows-Manager-Seite. Wir wählen die zweite. 6. Kehren Sie zur Pe-Schnittstelle des Computers zurück, um die Installation fortzusetzen. 7. Starten Sie nach Abschluss den Computer neu. 8. Kommen Sie schließlich zum Desktop und die Systeminstallation ist abgeschlossen. Ein-Klick-Installation des Win7-Systems
2023-07-16
Kommentar 0
1254
PHP-Einfügesortierung
Artikeleinführung::Dieser Artikel stellt hauptsächlich die PHP-Einfügesortierung vor. Studenten, die sich für PHP-Tutorials interessieren, können darauf zurückgreifen.
2016-08-08
Kommentar 0
1114
图解找出PHP配置文件php.ini的路径的方法,_PHP教程
Artikeleinführung:图解找出PHP配置文件php.ini的路径的方法,。图解找出PHP配置文件php.ini的路径的方法, 近来,有不博友问php.ini存在哪个目录下?或者修改php.ini以后为何没有生效?基于以上两个问题,
2016-07-13
Kommentar 0
855

Huawei bringt zwei neue kommerzielle KI-Speicherprodukte großer Modelle auf den Markt, die eine Leistung von 12 Millionen IOPS unterstützen
Artikeleinführung:IT House berichtete am 14. Juli, dass Huawei kürzlich neue kommerzielle KI-Speicherprodukte „OceanStorA310 Deep Learning Data Lake Storage“ und „FusionCubeA3000 Training/Pushing Hyper-Converged All-in-One Machine“ herausgebracht habe. Beamte sagten, dass „diese beiden Produkte grundlegendes Training ermöglichen“. KI-Modelle, Branchenmodelltraining, segmentiertes Szenariomodelltraining und Inferenz sorgen für neuen Schwung.“ ▲ Bildquelle Huawei IT Home fasst zusammen: OceanStorA310 Deep Learning Data Lake Storage ist hauptsächlich auf einfache/industrielle große Modell-Data-Lake-Szenarien ausgerichtet, um eine Datenregression zu erreichen . Umfangreiches Datenmanagement im gesamten KI-Prozess von der Erfassung und Vorverarbeitung bis hin zum Modelltraining und der Inferenzanwendung. Offiziell erklärt, dass OceanStorA310 Single Frame 5U die branchenweit höchsten 400 GB/s unterstützt
2023-07-16
Kommentar 0
1608
PHP-Funktionscontainering...
Artikeleinführung::In diesem Artikel wird hauptsächlich der PHP-Funktionscontainer vorgestellt ... Studenten, die sich für PHP-Tutorials interessieren, können darauf verweisen.
2016-08-08
Kommentar 0
1144
PHP面向对象程序设计之接口用法,php面向对象程序设计_PHP教程
Artikeleinführung:PHP面向对象程序设计之接口用法,php面向对象程序设计。PHP面向对象程序设计之接口用法,php面向对象程序设计 接口是PHP面向对象程序设计中非常重要的一个概念。本文以实例形式较为详细的讲述
2016-07-13
Kommentar 0
1013
PHP面向对象程序设计之类常量用法实例,sed用法实例_PHP教程
Artikeleinführung:PHP面向对象程序设计之类常量用法实例,sed用法实例。PHP面向对象程序设计之类常量用法实例,sed用法实例 类常量是PHP面向对象程序设计中非常重要的一个概念,牢固掌握类常量有助于进一步提
2016-07-13
Kommentar 0
1049



