Insgesamt10000 bezogener Inhalt gefunden
Welche Algorithmen sind für maschinelles Lernen der Einstiegsklasse erforderlich?
Artikeleinführung:K-Nearest-Neighbor-Algorithmus Was ist der K-Nearest-Neighbor-Algorithmus? Es geht darum, Ihr Kategoriekonzept basierend auf Ihren Nachbarn abzuleiten: Der KNearestNeighbor-Algorithmus wird auch als KNN-Algorithmus bezeichnet. Dieser Algorithmus ist ein relativ klassischer Algorithmus im maschinellen Lernen. Definition: Wenn eine Stichprobe zu einer bestimmten Kategorie unter den k ähnlichsten (dh dem nächsten Nachbarn im Merkmalsraum) Stichproben im Merkmalsraum gehört, gehört die Stichprobe ebenfalls zu dieser Kategorie. Quelle: Der KNN-Algorithmus wurde erstmals von Cover und Hart als Klassifizierungsalgorithmus vorgeschlagen. Der Abstand zwischen zwei Stichproben kann mit der folgenden Formel berechnet werden, die auch als euklidische Distanz bezeichnet wird. Das Anwendungsszenario der linearen Regression wird weiter unten erläutert ist: Immobilienpreisvorhersage
2023-05-02
Kommentar 0
835

Grundprinzipien und Beispiele der KNN-Algorithmusklassifizierung
Artikeleinführung:Der KNN-Algorithmus ist ein einfacher und benutzerfreundlicher Klassifizierungsalgorithmus, der für kleine Datensätze und niedrigdimensionale Merkmalsräume geeignet ist. Es schneidet in Bereichen wie der Bildklassifizierung und der Textklassifizierung gut ab und ist wegen seiner einfachen Implementierung und leichten Verständlichkeit beliebt. Die Grundidee des KNN-Algorithmus besteht darin, die nächsten K Nachbarn zu finden, indem die Merkmale der zu klassifizierenden Stichprobe mit den Merkmalen der Trainingsstichprobe verglichen werden, und anhand dieser Kategorien die Kategorie der zu klassifizierenden Stichprobe zu bestimmen K Nachbarn. Der KNN-Algorithmus verwendet einen Trainingssatz mit beschrifteten Kategorien und einen zu klassifizierenden Testsatz. Der Klassifizierungsprozess des KNN-Algorithmus umfasst die folgenden Schritte: Berechnen Sie zunächst den Abstand zwischen der zu klassifizierenden Stichprobe und allen Trainingsstichproben. Wählen Sie dann die K nächsten Nachbarn aus, um die zu erhalten Klassifizierungsbeispielkategorie;
2024-01-23
Kommentar 0
759

So implementieren Sie den K-Nächste-Nachbarn-Algorithmus in PHP
Artikeleinführung:So implementieren Sie den K-Nearest-Neighbor-Algorithmus in PHP. Der K-Nearest-Neighbor-Algorithmus ist ein einfacher und häufig verwendeter Algorithmus für maschinelles Lernen, der häufig bei Klassifizierungs- und Regressionsproblemen eingesetzt wird. Sein Grundprinzip besteht darin, die zu klassifizierende Probe in die Kategorie zu klassifizieren, zu der die nächsten K bekannten Proben gehören, indem der Abstand zwischen der zu klassifizierenden Probe und den bekannten Proben berechnet wird. In diesem Artikel stellen wir die Implementierung des K-Nearest-Neighbor-Algorithmus in PHP vor und stellen Codebeispiele bereit. Datenvorbereitung Zunächst müssen wir bekannte und zu klassifizierende Probendaten vorbereiten. Es ist bekannt, dass die Probendaten Kategorien und Merkmalswerte enthalten und die Anzahl der zu klassifizierenden Proben beträgt
2023-07-07
Kommentar 0
1129

Wie löse ich das Problem des nächstgelegenen Punktpaars in PHP mithilfe der Divide-and-Conquer-Methode und erhalte die optimale Lösung?
Artikeleinführung:Wie löse ich das Problem des nächstgelegenen Punktpaars in PHP mithilfe der Divide-and-Conquer-Methode und erhalte die optimale Lösung? Das Problem des nächsten Paares bezieht sich auf das Finden der zwei nächsten Punktpaare auf einer gegebenen Ebene. Dieses Problem kommt in der Computergeometrie sehr häufig vor und hat viele Lösungen. Eine der am häufigsten verwendeten Methoden ist Teilen und Herrschen. Teilen und Erobern ist eine Methode, ein Problem in kleinere Teilprobleme aufzuteilen und das ursprüngliche Problem durch rekursives Lösen der Teilprobleme zu lösen.
2023-09-20
Kommentar 0
1476
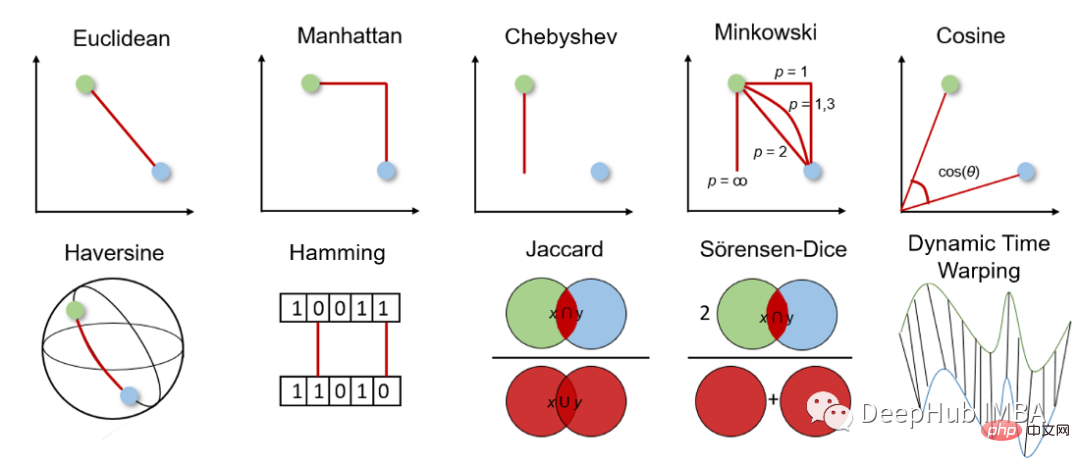
Zehn häufig verwendete Entfernungsmessmethoden beim maschinellen Lernen
Artikeleinführung:Entfernungsmessungen sind die Grundlage überwachter und unbeaufsichtigter Lernalgorithmen, einschließlich k-Nearest Neighbor, Support Vector Machine und K-Means-Clustering. Die Wahl der Distanzmetrik wirkt sich auf unsere Ergebnisse des maschinellen Lernens aus. Daher ist es wichtig zu überlegen, welche Metrik für das Problem am besten geeignet ist. Daher sollten wir bei der Entscheidung, welche Messmethode wir verwenden, vorsichtig sein. Doch bevor wir eine Entscheidung treffen, müssen wir verstehen, wie die Entfernungsmessung funktioniert und aus welchen Messungen wir wählen können. In diesem Artikel werden häufig verwendete Abstandsmaße kurz vorgestellt, wie sie funktionieren, wie sie in Python berechnet werden und wann sie verwendet werden. Dies führt zu tieferem Wissen und Verständnis sowie zu verbesserten Algorithmen und Ergebnissen für maschinelles Lernen. Bevor wir tiefer auf die verschiedenen Distanzmessungen eingehen, verschaffen wir uns zunächst einen Überblick über deren Funktionsweise und Funktionsweise
2023-04-16
Kommentar 0
1513
Detailliertes Beispiel für die Einbettung von Wortvektoren
Artikeleinführung:Die Einbettung von Wortvektoren erfordert eine effiziente Verarbeitung umfangreicher Textkorpora. word2vec. Auf einfache Weise wird das Wort an das One-Hot-Codierungs-Lernsystem gesendet, die Länge ist ein Vektor der Länge des Vokabulars, das entsprechende Positionselement des Wortes ist 1 und die anderen Elemente sind 0. Die Vektordimension ist sehr hoch und kann die semantische Assoziation verschiedener Wörter nicht beschreiben. Kookkurrenz stellt Wörter dar, löst semantische Assoziationen auf, durchläuft einen großen Textkorpus, zählt die umgebenden Wörter innerhalb eines bestimmten Abstands zu jedem Wort und stellt jedes Wort mit der normalisierten Anzahl benachbarter Wörter dar. ähnliche Wörter im Kontext
2017-06-21
Kommentar 0
3116

Anwendung von ortsabhängigem Hashing bei der Suche nach ungefähren nächsten Nachbarn
Artikeleinführung:Locality Sensitive Hashing (LSH) ist eine Methode zur ungefähren Suche nach nächsten Nachbarn, die sich besonders für Daten in hochdimensionalen Räumen eignet. In vielen praktischen Anwendungen wie Text- und Bilddaten kann die Dimensionalität von Datenpunkten sehr hoch sein. Im hochdimensionalen Raum sind herkömmliche Entfernungsmessmethoden wie die euklidische Entfernung nicht mehr effektiv und herkömmliche lineare Suchmethoden sind ineffizient. Daher benötigen wir einige effiziente Algorithmen, um dieses Problem zu lösen. Die Grundidee von LSH besteht darin, ähnliche Datenpunkte über eine Hash-Funktion ähnlichen Hash-Buckets zuzuordnen. Auf diese Weise müssen wir nur in ähnlichen Hash-Buckets suchen, anstatt den gesamten Datensatz zu durchsuchen, wodurch die Sucheffizienz erheblich verbessert wird. Der Kern des LSH-Algorithmus besteht darin, eine geeignete Hash-Funktion zu entwerfen. Die Hash-Funktion sollte zwei Merkmale aufweisen: erstens Ähnlichkeit
2024-01-23
Kommentar 0
550
So installieren Sie das Win7-Betriebssystem auf dem Computer
Artikeleinführung:Unter den Computer-Betriebssystemen ist das WIN7-System ein sehr klassisches Computer-Betriebssystem. Wie installiert man also das Win7-System? Der folgende Editor stellt detailliert vor, wie Sie das Win7-System auf Ihrem Computer installieren. 1. Laden Sie zunächst das Xiaoyu-System herunter und installieren Sie die Systemsoftware erneut auf Ihrem Desktop-Computer. 2. Wählen Sie das Win7-System aus und klicken Sie auf „Dieses System installieren“. 3. Beginnen Sie dann mit dem Herunterladen des Image des Win7-Systems. 4. Stellen Sie nach dem Herunterladen die Umgebung bereit und klicken Sie nach Abschluss auf Jetzt neu starten. 5. Nach dem Neustart des Computers erscheint die Windows-Manager-Seite. Wir wählen die zweite. 6. Kehren Sie zur Pe-Schnittstelle des Computers zurück, um die Installation fortzusetzen. 7. Starten Sie nach Abschluss den Computer neu. 8. Kommen Sie schließlich zum Desktop und die Systeminstallation ist abgeschlossen. Ein-Klick-Installation des Win7-Systems
2023-07-16
Kommentar 0
1202
PHP-Einfügesortierung
Artikeleinführung::Dieser Artikel stellt hauptsächlich die PHP-Einfügesortierung vor. Studenten, die sich für PHP-Tutorials interessieren, können darauf zurückgreifen.
2016-08-08
Kommentar 0
1057
图解找出PHP配置文件php.ini的路径的方法,_PHP教程
Artikeleinführung:图解找出PHP配置文件php.ini的路径的方法,。图解找出PHP配置文件php.ini的路径的方法, 近来,有不博友问php.ini存在哪个目录下?或者修改php.ini以后为何没有生效?基于以上两个问题,
2016-07-13
Kommentar 0
804

Huawei bringt zwei neue kommerzielle KI-Speicherprodukte großer Modelle auf den Markt, die eine Leistung von 12 Millionen IOPS unterstützen
Artikeleinführung:IT House berichtete am 14. Juli, dass Huawei kürzlich neue kommerzielle KI-Speicherprodukte „OceanStorA310 Deep Learning Data Lake Storage“ und „FusionCubeA3000 Training/Pushing Hyper-Converged All-in-One Machine“ herausgebracht habe. Beamte sagten, dass „diese beiden Produkte grundlegendes Training ermöglichen“. KI-Modelle, Branchenmodelltraining, segmentiertes Szenariomodelltraining und Inferenz sorgen für neuen Schwung.“ ▲ Bildquelle Huawei IT Home fasst zusammen: OceanStorA310 Deep Learning Data Lake Storage ist hauptsächlich auf einfache/industrielle große Modell-Data-Lake-Szenarien ausgerichtet, um eine Datenregression zu erreichen . Umfangreiches Datenmanagement im gesamten KI-Prozess von der Erfassung und Vorverarbeitung bis hin zum Modelltraining und der Inferenzanwendung. Offiziell erklärt, dass OceanStorA310 Single Frame 5U die branchenweit höchsten 400 GB/s unterstützt
2023-07-16
Kommentar 0
1533
PHP-Funktionscontainering...
Artikeleinführung::In diesem Artikel wird hauptsächlich der PHP-Funktionscontainer vorgestellt ... Studenten, die sich für PHP-Tutorials interessieren, können darauf verweisen.
2016-08-08
Kommentar 0
1097
PHP面向对象程序设计之接口用法,php面向对象程序设计_PHP教程
Artikeleinführung:PHP面向对象程序设计之接口用法,php面向对象程序设计。PHP面向对象程序设计之接口用法,php面向对象程序设计 接口是PHP面向对象程序设计中非常重要的一个概念。本文以实例形式较为详细的讲述
2016-07-13
Kommentar 0
982
PHP面向对象程序设计之类常量用法实例,sed用法实例_PHP教程
Artikeleinführung:PHP面向对象程序设计之类常量用法实例,sed用法实例。PHP面向对象程序设计之类常量用法实例,sed用法实例 类常量是PHP面向对象程序设计中非常重要的一个概念,牢固掌握类常量有助于进一步提
2016-07-13
Kommentar 0
1017





