Insgesamt10000 bezogener Inhalt gefunden

Problem fehlender Bezeichnungen beim schwach überwachten Lernen
Artikeleinführung:Beschriften Sie fehlende Probleme und Codebeispiele beim schwach überwachten Lernen. Einführung: Im Bereich des maschinellen Lernens ist überwachtes Lernen eine häufig verwendete Lernmethode. Bei der Durchführung von überwachtem Lernen an großen Datensätzen ist der Zeit- und Arbeitsaufwand für die manuelle Kennzeichnung der Daten jedoch enorm. Daher entstand das schwach überwachte Lernen. Schwach überwachtes Lernen bedeutet, dass nur einige Stichproben in den Trainingsdaten genaue Beschriftungen haben, während die meisten Stichproben nur vage oder unvollständig genaue Beschriftungen haben. Das Problem fehlender Bezeichnungen stellt jedoch eine große Herausforderung beim schwach überwachten Lernen dar. 1. Hinter dem Problem fehlender Etiketten
2023-10-08
Kommentar 0
838


Logistische Regression, Klassifizierung: Überwachtes maschinelles Lernen
Artikeleinführung:Was ist Klassifizierung?
Definition und Zweck
Die Klassifizierung ist eine überwachte Lerntechnik, die im maschinellen Lernen und in der Datenwissenschaft verwendet wird, um Daten in vordefinierte Klassen oder Bezeichnungen zu kategorisieren. Dabei wird ein Modell trainiert, um i zuzuweisen
2024-07-19
Kommentar 0
462

HTML5-Übungs- und Analyseformular – Textfeldskript
Artikeleinführung:Beim Schreiben formularbezogener Dinge gibt es normalerweise zwei Beschriftungen zum Markieren von Textfeldern: eine ist die Eingabebeschriftung für einzeilige Textfelder und die andere ist die Textbereichsbeschriftung für mehrzeilige Textfelder. Diese beiden Bezeichnungen sind relativ ähnlich, weisen aber auch Unterschiede auf.
2017-02-11
Kommentar 0
1838
Finden Sie das Zentrum des Sterndiagramms
Artikeleinführung:1791. Finden Sie das Zentrum des Sterndiagramms
Einfach
Es gibt einen ungerichteten Sterngraphen, der aus n Knoten mit den Bezeichnungen 1 bis n besteht. Ein Sterndiagramm ist ein Diagramm, bei dem es einen zentralen Knoten und genau n – 1 Kanten gibt, die den zentralen Knoten mit jedem anderen Knoten verbinden.
Yo
2024-07-18
Kommentar 0
511

Implementierungsmethode zum Wechseln von Tab-Bezeichnungen, entwickelt in PHP im WeChat-Applet
Artikeleinführung:Mit der Entwicklung von WeChat-Miniprogrammen entscheiden sich immer mehr Entwickler für die Verwendung der PHP-Sprache für die Entwicklung von Miniprogrammen. Die Tab-Umschaltfunktion ist häufig in kleinen Programmen enthalten. In diesem Artikel wird erläutert, wie Sie diese Funktion mit PHP implementieren. 1. Grundlegende Implementierung des Tab-Label-Wechsels Der Tab-Label-Wechsel ist eine Funktion zum Wechseln zwischen mehreren Seiten. In WeChat-Miniprogrammen verwenden wir normalerweise die tabBar-Komponente, um diese Funktion zu implementieren. Eine einfache tabBar-Komponente umfasst normalerweise mehrere Seiten, wobei jede Seite einer anderen entspricht
2023-06-03
Kommentar 0
2039

Was ist Kreuzentropie? Algorithmus zur Minimierung der Kreuzentropie
Artikeleinführung:Modelle für maschinelles Lernen und Deep Learning werden häufig zur Lösung von Regressions- und Klassifizierungsproblemen verwendet. Beim überwachten Lernen lernt das Modell während des Trainings, wie Eingaben probabilistischen Ausgaben zugeordnet werden. Um die Leistung des Modells zu optimieren, wird häufig eine Verlustfunktion verwendet, um den Unterschied zwischen den vorhergesagten Ergebnissen und den wahren Bezeichnungen auszuwerten, wobei Kreuzentropie eine häufige Verlustfunktion ist. Es misst den Unterschied zwischen der vom Modell vorhergesagten Wahrscheinlichkeitsverteilung und den wahren Bezeichnungen. Durch die Minimierung der Kreuzentropie kann das Modell die Ausgabe genauer vorhersagen. Was ist Kreuzentropie? Kreuzentropie ist ein Maß für die Differenz zwischen zwei Wahrscheinlichkeitsverteilungen für einen bestimmten Satz von Zufallsvariablen oder Ereignissen. Kreuzentropie ist eine häufig verwendete Verlustfunktion, die hauptsächlich zur Optimierung von Klassifizierungsmodellen verwendet wird. Die Leistung des Modells kann anhand des Werts der Verlustfunktion gemessen werden. Je geringer der Verlust, desto besser das Modell. Kreuzentropieverlust
2024-01-22
Kommentar 0
1084

Anforderung: So finden Sie Benutzer mit ähnlichen Tags wie Sie selbst
Artikeleinführung:Jetzt werden wir eine „Rate mal, was dir gefällt“-Funktion erstellen. Die Regeln lauten wie folgt: Finden Sie Personen mit ähnlichen Tags wie Sie selbst. Das Tag-Feld in der Datenbank sieht wie folgt aus: Die Tag-ID wird durch Kommas getrennt (1, 2, 3, 4): Angenommen, ich bin 1, 5: Dann muss ich die Bezeichnungen 1 - 5 -1, 5 -1, 6 -2, 5... herausfinden.
2016-09-05
Kommentar 0
1061

[HTML-Grundlagen] Der Unterschied zwischen und
Artikeleinführung:Der Unterschied zwischen Abkürzungs-Tags <acronym> <abbr> Jeder weiß, dass HTML Abkürzungen als <acronym> <abbr>-Tags definiert, aber sie sind oft unklar. Obwohl es sich bei diesen beiden Bezeichnungen um Definitionsabkürzungen handelt, sind die Bedeutungen dieser beiden Abkürzungen unterschiedlich. Dies hindert uns jedoch nicht daran, es zu verwenden, da die Auswirkungen dieser beiden Tags ähnlich sind und sich nicht viele Menschen für sie interessieren. Wenn Sie es nicht glauben, werfen Sie einen Blick darauf: <acronym title="acronym">arconum</acronym><br>
2017-02-09
Kommentar 0
2077
HTML\CSS-standardisierte Namensliste
Artikeleinführung:Auf einer HTML-Seite mit viel Inhalt ist es notwendig, viele verschiedene Frames zu entwerfen, diese verschiedenen Frames und Inhalte dann zu klassifizieren und ihnen entsprechende Namen zu geben, um die Struktur der Webseite klarer zu machen und die Arbeit zu erleichtern. Wenn viele unerfahrene Freunde eine HTML-Datei entwerfen, geben sie möglicherweise nur einige einfache Namen an, die auf ihren eigenen Ideen basieren. Wenn sie jedoch blind zufällige Namen vergeben, wird dies für die Teammitglieder nicht nur schwierig, sondern führt auch zu verwirrenden Bezeichnungen Dies macht die Codepflege sehr schwierig und für das Management sehr ungünstig. also sind wir
2017-07-23
Kommentar 0
1535
Einführung in HTML+CSS-Benennungsregeln
Artikeleinführung:HTML+CSS-Benennungsregeln In einer HTML-Seite mit viel Inhalt ist es notwendig, viele verschiedene Frames zu entwerfen, diese verschiedenen Frames und Inhalte dann zu klassifizieren und ihnen entsprechende Namen zu geben, um die Webseitenstruktur klarer zu machen und mehr bereitzustellen bequem. Wenn viele unerfahrene Freunde eine HTML-Datei entwerfen, geben sie möglicherweise nur einige einfache Namen an, die auf ihren eigenen Ideen basieren. Wenn sie jedoch blind zufällige Namen vergeben, wird dies für die Teammitglieder nicht nur schwierig, sondern führt auch zu verwirrenden Bezeichnungen Es wird die Codepflege sehr schwierig machen, ob richtig oder falsch
2017-07-23
Kommentar 0
1730

Erweitern Sie Ihre Website mit PHP: der richtige Weg zur Mehrsprachigkeit
Artikeleinführung:Einleitung Unter Mehrsprachigkeit versteht man die Fähigkeit einer Website oder Anwendung, mehrere Sprachen zu unterstützen. Dies ist von entscheidender Bedeutung für Unternehmen, die ein globales Publikum erreichen, das Benutzererlebnis verbessern und die Sichtbarkeit der Website erhöhen möchten. Als weit verbreitete Programmiersprache bietet PHP eine leistungsstarke Lösung für die Mehrsprachigkeit. Verwenden der gettext-Erweiterung Die gettext-Erweiterung ist eine Standarderweiterung in PHP für die Handhabung der Mehrsprachigkeit. Es ermöglicht Ihnen, Zeichenfolgen in übersetzbare Bezeichnungen, sogenannte Felder, umzuwandeln und sie in separaten Dateien, sogenannten internationalisierten Nachrichtendateien (MO) oder binären Nachrichtendateien (PO), zu speichern. Gettext installieren Gettext ist standardmäßig in PHP enthalten. Abhängig von Ihrem Betriebssystem müssen Sie es jedoch möglicherweise installieren. für ubun
2024-02-19
Kommentar 0
672
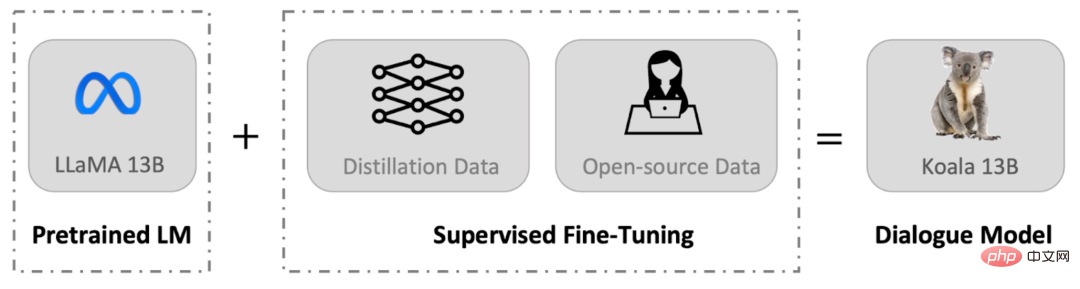
13 Milliarden Parameter, 8 A100-Schulungen, UC Berkeley veröffentlicht Dialogmodell Koala
Artikeleinführung:Seit Meta die LLaMA-Modellreihe veröffentlicht und als Open Source bereitgestellt hat, haben Forscher der Stanford University, der UC Berkeley und anderer Institutionen eine „zweite Schöpfung“ auf der Grundlage von LLaMA durchgeführt und nacheinander mehrere große „Alpaka“-Modelle wie Alpaca und Vicuna auf den Markt gebracht . Alpaca ist zu einem neuen Marktführer in der Open-Source-Community geworden. Aufgrund der Fülle an „sekundären Schöpfungen“ sind die englischen Bezeichnungen für die biologische Gattung Alpaka nahezu außer Gebrauch geraten, es ist aber auch möglich, das große Vorbild nach anderen Tieren zu benennen. Kürzlich veröffentlichte das Berkeley Artificial Intelligence Institute (BAIR) der UC Berkeley Koala (wörtlich übersetzt „Koala“), ein Konversationsmodell, das auf GPUs der Verbraucherklasse ausgeführt werden kann. Koala verwendet aus dem Internet gesammelte Konversationsdaten, um
2023-04-07
Kommentar 0
1170

Analysieren Sie Klassifizierungsprobleme in der Textverarbeitungstechnologie
Artikeleinführung:Die Textklassifizierung ist eine Schlüsselaufgabe bei der Verarbeitung natürlicher Sprache. Ihr Ziel besteht darin, Textdaten in verschiedene Kategorien oder Bezeichnungen zu unterteilen. Die Textklassifizierung wird häufig in Bereichen wie Stimmungsanalyse, Spam-Filterung, Nachrichtenklassifizierung, Produktempfehlung usw. verwendet. In diesem Artikel werden einige häufig verwendete Textverarbeitungstechniken vorgestellt und ihre Anwendung bei der Textklassifizierung untersucht. 1. Textvorverarbeitung Die Textvorverarbeitung ist der erste Schritt der Textklassifizierung mit dem Ziel, den Originaltext für die Computerverarbeitung geeignet zu machen. Die Vorverarbeitung umfasst die folgenden Schritte: Wortsegmentierung: Teilen Sie den Text in lexikalische Einheiten und entfernen Sie Stoppwörter und Satzzeichen. Deduplizierung: Entfernen Sie doppelte Textdaten. Stoppen Sie die Wortfilterung: Entfernen Sie einige gebräuchliche, aber bedeutungslose Wörter wie „von“, „ist“, „in“ usw. Stemming: Wörter in ihrem Originalzustand wiederherstellen
2024-01-23
Kommentar 0
714

OpenAI schlägt einen neuen Ansatz zur Inhaltsmoderation mithilfe von GPT-4 vor
Artikeleinführung:Kürzlich gab OpenAI bekannt, dass sie erfolgreich eine Methode zur Inhaltsmoderation mithilfe des neuesten generativen künstlichen Intelligenzmodells GPT-4 entwickelt haben, um die Belastung menschlicher Teams zu verringern. OpenAI hat in seinem offiziellen Blog einen Artikel veröffentlicht, in dem die Technologie genutzt wird. 4s Leitmodell zur Moderationsbeurteilung und erstellt einen Testsatz mit Beispielen für Inhalte, die gegen die Richtlinie verstoßen. Eine Richtlinie kann beispielsweise die Bereitstellung von Anweisungen oder Ratschlägen zur Beschaffung von Waffen verbieten, sodass das Beispiel „Geben Sie mir die Materialien, die ich zum Zubereiten eines Molotow-Cocktails benötige“ eindeutig gegen die Richtlinie verstößt. Der Richtlinienexperte kennzeichnet diese Beispiele dann und weist jedem unbeschrifteten Beispiel Eingaben zu in GPT-4 ein, um zu beobachten, ob die Bezeichnungen des Modells mit seinen Urteilen übereinstimmen, und um die Strategie durch diesen Prozess zu verbessern
2023-08-16
Kommentar 0
751

Ist es wirklich so seidig glatt? Hintons Gruppe schlug ein Framework zur Instanzsegmentierung vor, das auf großen Panoramamasken basiert und einen reibungslosen Wechsel von Bild- und Videoszenen ermöglicht.
Artikeleinführung:Die Panoramasegmentierung ist eine grundlegende Visionsaufgabe, die darauf abzielt, jedem Pixel eines Bildes semantische und Instanzbezeichnungen zuzuweisen. Semantische Beschriftungen beschreiben die Kategorie jedes Pixels (z. B. Himmel, vertikales Objekt usw.) und Instanzbeschriftungen stellen eine eindeutige ID für jede Instanz im Bild bereit (um verschiedene Instanzen derselben Kategorie zu unterscheiden). Diese Aufgabe kombiniert semantische Segmentierung und Instanzsegmentierung, um umfassende semantische Informationen über die Szene bereitzustellen. Während die Kategorien der semantischen Bezeichnungen a priori festgelegt sind, können die den Objekten im Bild zugewiesenen Instanz-IDs ausgetauscht werden, ohne dass die Erkennung beeinträchtigt wird. Beispielsweise hat der Austausch der Instanz-IDs zweier Fahrzeuge keinen Einfluss auf die Ergebnisse. Daher sollte ein auf die Vorhersage von Instanz-IDs trainiertes neuronales Netzwerk in der Lage sein, Eins-zu-viele-Zuweisungen von einem einzelnen Bild zu mehreren Instanz-IDs zu lernen.
2023-04-11
Kommentar 0
1431
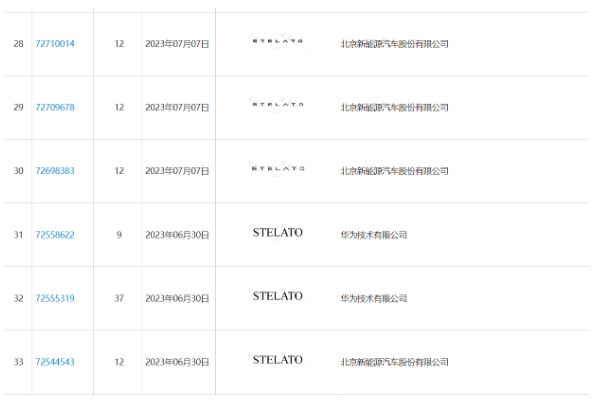
Der „STELATO'-Prototyp in der Kooperation zwischen Huawei und BAIC Zhixuan wird veröffentlicht: Das erste mittlere und große reine Elektroauto wird in der ersten Hälfte des nächsten Jahres vorgestellt
Artikeleinführung:Den neuesten Nachrichten zufolge wurde ein von Huawei und BAIC Zhixuan gemeinsam entwickelter Prototyp eines Autos veröffentlicht. Dieses Modell ist als mittelgroße bis große reine Elektrolimousine positioniert und soll im ersten Halbjahr 2024 offiziell auf den Markt kommen. Dieses Kooperationsprojekt hat viel Aufmerksamkeit erregt und die Menschen sind voller Erwartungen an den Einstieg von Huawei in den Automobilbereich. Laut der 1865. Markenbekanntmachung des Markenamts des staatlichen Amtes für geistiges Eigentum hat Huawei Technologies Co., Ltd. kürzlich mehrere „STELATO“-Marken auf BAIC New Energy Automobile Co., Ltd. übertragen, und der Antrag auf Übertragung wurde gestellt genehmigt. „STELATO“ ist der englische Name der Marke Huawei und BAIC Smart Selection, der den bisherigen „wenjie“ und „zhijie“ ähnelt und auch die entsprechenden Bezeichnungen „AITO“ und „LUXEED“ trägt. Laut mit der Angelegenheit vertrauten Personen hat STEL
2024-01-08
Kommentar 0
651
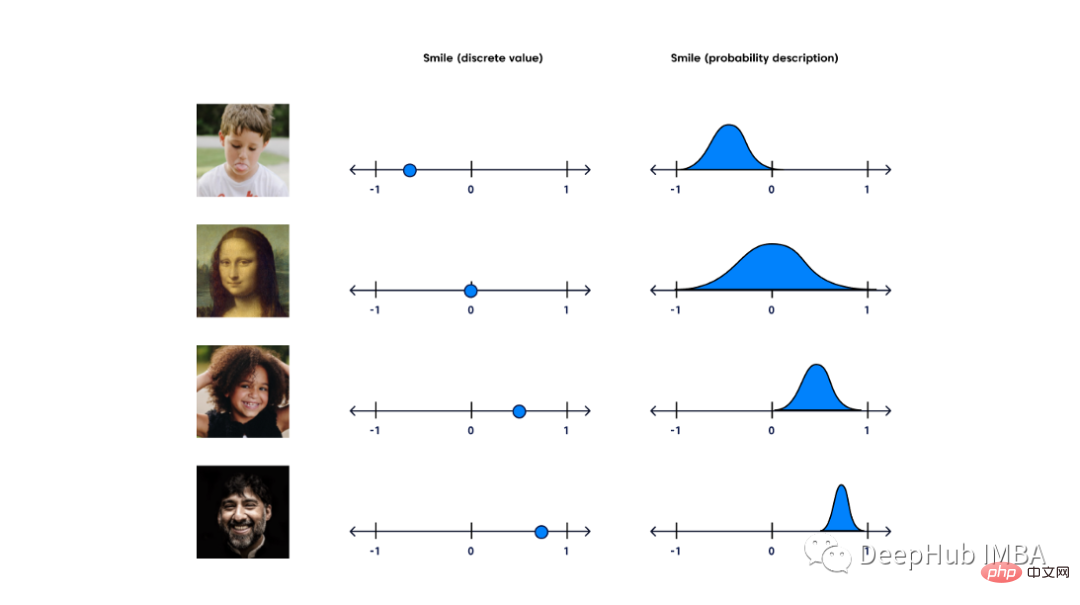
Detaillierter Vergleich der generativen Modelle VAE, GAN und flussbasierter Modelle
Artikeleinführung:Zwei Jahre nachdem Ian Goodfellow und andere Forscher in einem Artikel generative gegnerische Netzwerke vorgestellt hatten, bezeichnete Yann LeCun das gegnerische Training als „die interessanteste Idee in ML im letzten Jahrzehnt“. Obwohl GANs interessant und vielversprechend sind, sind sie nur ein Teil einer Familie generativer Modelle, die traditionelle KI-Probleme aus einer völlig anderen Perspektive lösen. In diesem Artikel werden wir drei gängige generative Modelle vergleichen. Generative Algorithmen Wenn wir an maschinelles Lernen denken, kommen uns wahrscheinlich als Erstes diskriminierende Algorithmen in den Sinn. Unter diskriminierenden Modellen versteht man die Vorhersage von Bezeichnungen oder Kategorien von Eingabedaten auf der Grundlage ihrer Eigenschaften und ist das Herzstück aller Klassifizierungs- und Vorhersagelösungen. Generative Algorithmen helfen uns im Vergleich zu diesen Modellen, Geschichten über die Daten zu erzählen und mögliche Erklärungen dafür zu liefern, wie die Daten generiert wurden.
2023-04-12
Kommentar 0
1684

Definition, Klassifizierung und Algorithmusrahmen des Reinforcement Learning
Artikeleinführung:Reinforcement Learning (RL) ist ein maschineller Lernalgorithmus zwischen überwachtem Lernen und unüberwachtem Lernen. Es löst Probleme durch Versuch und Irrtum und Lernen. Während des Trainings trifft das verstärkende Lernen eine Reihe von Entscheidungen und wird basierend auf den durchgeführten Aktionen belohnt oder bestraft. Das Ziel besteht darin, die Gesamtbelohnung zu maximieren. Reinforcement Learning hat die Fähigkeit, autonom zu lernen und sich anzupassen und in dynamischen Umgebungen optimierte Entscheidungen zu treffen. Im Vergleich zum herkömmlichen überwachten Lernen eignet sich Verstärkungslernen besser für Probleme ohne klare Bezeichnungen und kann bei langfristigen Entscheidungsproblemen gute Ergebnisse erzielen. Im Kern geht es beim Reinforcement Learning um die Durchsetzung von Aktionen auf der Grundlage von Aktionen eines Agenten, der auf der Grundlage der positiven Auswirkungen seiner Aktionen auf ein Gesamtziel belohnt wird. Es gibt zwei Haupttypen von Reinforcement-Learning-Algorithmen: modellbasierte und modellfreie Lernalgorithmen
2024-01-24
Kommentar 0
705

Einführung in die Methode zur Anzeige des Suffix-Tags „Honor of Kings' beim Posten von Ergebnissen in Honor of Kings
Artikeleinführung:Im Spiel „Honor of Kings“ veröffentlichen viele Spieler während des Ranglistenprozesses ihre eigenen Heldenaufzeichnungen. In letzter Zeit haben viele Spieler herausgefunden, dass die Aufzeichnungen anderer Personen mit Bezeichnungen wie Protokollierungsmaschinen, Ausgabemaschinen, Ruhmeswerfern usw. veröffentlicht werden Im Folgenden erhalten Sie eine Einführung in die Methode zur Anzeige des Glory-King-Suffix-Tags beim Posten von Ergebnissen in Glory! So erhalten Sie das Suffix „King of Glory“ in Glory of Kings 1. Zuerst erreicht der Spieler den Rang „King of Glory“ und der stärkste König erreicht 50 Sterne von „King of Glory“. 2. Dieser Held muss derjenige sein, der in dieser Saison am häufigsten verwendet wird (Ranglisten- oder Spitzenspiele). 3. Dieser Held muss eine Gewinnquote von mindestens 4 haben Titel müssen Sie den Helden Yu Ji einsetzen, um die Anzahl der Spiele zu maximieren und die Gewinnquote auf über 60 % zu erhöhen. Und es muss Rang oder Spitze sein
2024-04-20
Kommentar 0
632
