Insgesamt10000 bezogener Inhalt gefunden

Schaffung von Kafka -Verbrauchern mit Reaktor Kafka
Artikeleinführung:In diesem Artikel wird beschrieben, dass skalierbare und belastbare Kafka -Verbraucher mit Reaktor Kafka im Spring Boot erstellt werden. Es deckt Konfiguration, Nachrichtenverarbeitung, Backdruckverwaltung (mit Buffer, OnbackPressuredrop usw.), robuster Fehlerbehandlung (Wiederholungen, D.
2025-03-07
Kommentar 0
569




Kafka Keys verstehen: Ein umfassender Leitfaden
Artikeleinführung:Apache Kafka ist eine leistungsstarke Plattform für verteilte Ereignisstreams, die häufig zum Erstellen realer Zeitpipelines und -anwendungen verwendet wird. Eine seiner Kernfunktionen ist der Kafka -Nachrichtenschlüssel, der eine wichtige Rolle bei Nachrichtenpartitionen, Sortieren und Routing spielt. In diesem Artikel wird das Konzept, die Wichtigkeit und die tatsächlichen Beispiele des Kafka -Schlüssels untersucht.
Was ist der Kafka -Schlüssel?
In Kafka enthält jede Nachricht zwei Hauptkomponenten:
Schlüssel: Bestimmen Sie die Partition, dass die Nachricht gesendet wird.
Wert: Die tatsächlichen Daten der Nachricht sind effektiv.
Kafka -Produzenten verwenden Schlüssel, um den Hash -Wert zu berechnen, der die spezifische Partition der Nachricht bestimmt. Wenn der Schlüssel nicht bereitgestellt wird, wird die Nachricht in jedem von jedem verteilt
2025-01-29
Kommentar 0
1051

Arbeiten mit reaktivem Kafka -Stream und Spring WebFlux
Artikeleinführung:In diesem Artikel werden reaktionsschnelle, skalierbare ereignisgesteuerte Apps mit reaktiven Kafka-Streams und Spring WebFlux erstellt. Es betont die effiziente Backpressure -Handhabung über Kafka -Verbrauchereinstellungen und Projektreaktorbetreiber und befürwortet das Verständnis
2025-03-07
Kommentar 0
842
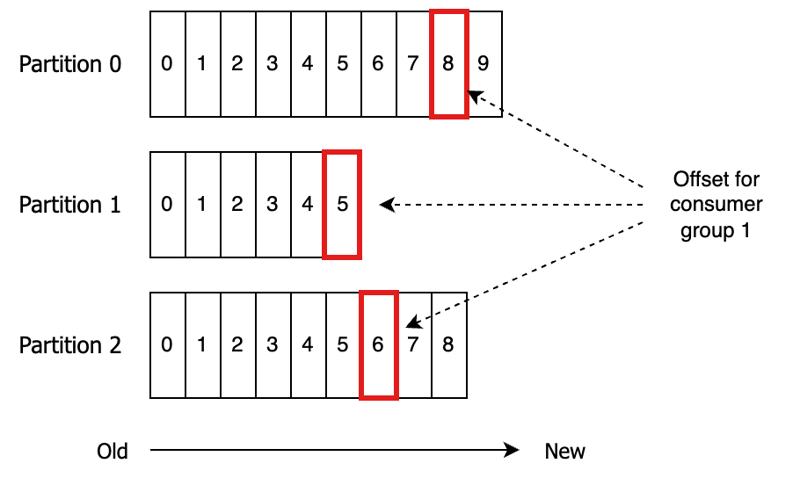
Kafka Consumer - Verschiebung der Verbrauchergruppe begehen
Artikeleinführung:Kafka Consumer Group Offsets verstehen: Ein umfassender Leitfaden
In diesem Leitfaden werden Kafka-Verbrauchergruppen-Offsets untersucht, die für die Verfolgung des Nachrichtenverbrauchsfortschritts von entscheidender Bedeutung sind. Jede Verbrauchergruppe verwaltet einen Offset für jede von ihr genutzte Partition, was darauf hinweist
2025-01-26
Kommentar 0
1022

Aufbau eines Kafka-Produzenten und -Konsumenten in Go
Artikeleinführung:Apache Kafka ist eine leistungsstarke verteilte Streaming-Plattform, die zum Aufbau von Echtzeit-Datenpipelines und Streaming-Anwendungen verwendet wird. In diesem Blogbeitrag gehen wir Schritt für Schritt durch die Einrichtung eines Kafka-Produzenten und -Konsumenten mit Golang.
Voraussetzungen
Sei
2025-01-03
Kommentar 0
890

KAFKA -Nachrichtenbestätigungsoptionen
Artikeleinführung:In diesem Artikel werden die Optionen zur Bestätigung der KAFKA untersucht: automatisch, manuell synchron, manuell asynchron und manuell mit bestimmten Offsets. Es analysiert ihre Leistungsverkäufe zwischen Durchsatz und Zuverlässigkeit und führt die Leser in SELE an
2025-03-07
Kommentar 0
553

Beschleunigen Sie GenAI: Streamen Sie Daten von MySQL nach Kafka
Artikeleinführung:Im Zeitalter der KI wird Apache Kafka aufgrund seiner hohen Leistung beim Echtzeit-Datenstreaming und -verarbeitung zu einer zentralen Kraft. Viele Unternehmen möchten Daten in Kafka integrieren, um die Effizienz und Geschäftsflexibilität zu steigern. In diesem Fall
2024-11-03
Kommentar 0
273

RabbitMQ vs. Kafka: Auswahl des richtigen Nachrichtenbrokers für Ihre Java-Anwendung
Artikeleinführung:Vergleich von RabbitMQ und Kafka:
Wenn Sie sich für Ihre Message-Brokering-Anforderungen zwischen RabbitMQ und Kafka entscheiden, ist es wichtig, deren einzigartige Stärken und besten Anwendungsfälle zu verstehen.
RabbitMQ ist ein traditioneller Nachrichtenbroker, der ein Push-Modell für Deli verwendet
2024-11-12
Kommentar 0
587

Belay the Metamorphosis: Analyse des Kafka-Projekts
Artikeleinführung:Haben Sie sich jemals gefragt, welche Fehler im Projektquellcode globaler Unternehmen lauern könnten? Verpassen Sie nicht die Gelegenheit, interessante Fehler zu entdecken, die vom statischen Analysator PVS-Studio im Open-Source-Projekt Apache Kafka entdeckt wurden.
Vorstellen
2024-10-16
Kommentar 0
678

Datenpipelines mit Apache Kafka im Jahr 2025 revolutionieren
Artikeleinführung:In diesem Artikel werden die Rolle von Apache Kafka in der Datenpipeline-Architektur bis 2025 untersucht. Er geht von Herausforderungen wie explodiertem Datenvolumen, Echtzeitanalyseanforderungen und komplexen Datenquellen vor. Der Artikel zeigt Kafkas Skalierbarkeit, Echtzeit Capab
2025-03-07
Kommentar 0
353

Kafka-Grundlagen mit einem praktischen Beispiel
Artikeleinführung:In den letzten Wochen habe ich mich intensiv mit Kafka beschäftigt und mir dabei Notizen gemacht. Ich habe beschlossen, daraus einen Blog-Beitrag zu organisieren und zu strukturieren. Neben Konzepten und Tipps gibt es auch ein praktisches Beispiel, das mit NestJS und KafkaJs erstellt wurde .
2024-12-28
Kommentar 0
450
Praktischer Leitfaden zum Kafka-Protokoll
Artikeleinführung:Ich habe ziemlich viel mit dem Apache Kafka-Protokoll auf der unteren Ebene gearbeitet. Es war nicht einfach, damit anzufangen, indem ich nur der offiziellen Anleitung folgte, und ich habe den Code oft gelesen. Mit diesem Beitrag möchte ich Ihnen einen Vorsprung verschaffen, indem ich Sie von Anfang an Schritt für Schritt anleite
2024-12-28
Kommentar 0
492




