Insgesamt10000 bezogener Inhalt gefunden

Wie kann man die Go-Sprache verwenden, um tiefgreifende Forschung zum verstärkten Lernen durchzuführen?
Artikeleinführung:Deep Reinforcement Learning (DeepReinforcementLearning) ist eine fortschrittliche Technologie, die Deep Learning und Reinforcement Learning kombiniert. Sie wird häufig in der Spracherkennung, Bilderkennung, Verarbeitung natürlicher Sprache und anderen Bereichen eingesetzt. Als schnelle, effiziente und zuverlässige Programmiersprache kann die Go-Sprache bei der tiefgreifenden Forschung zum Reinforcement Learning hilfreich sein. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache tiefgreifende Forschung zum verstärkten Lernen durchführen können. 1. Installieren Sie die Go-Sprache und die zugehörigen Bibliotheken und beginnen Sie mit der Verwendung der Go-Sprache für tiefgreifendes, verstärkendes Lernen.
2023-06-10
Kommentar 0
1226
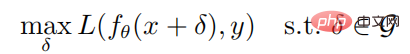
Gegnerische Angriffe und Abwehrmaßnahmen beim Deep Reinforcement Learning
Artikeleinführung:01 Einleitung In diesem Artikel geht es um die Arbeit des Deep Reinforcement Learning gegen Angriffe. In diesem Artikel untersucht der Autor die Robustheit von Deep-Reinforcement-Learning-Strategien gegenüber gegnerischen Angriffen aus der Perspektive einer robusten Optimierung. Im Rahmen der robusten Optimierung wird der optimale gegnerische Angriff durch die Minimierung der erwarteten Rendite der Strategie erreicht, und dementsprechend wird ein guter Abwehrmechanismus durch die Verbesserung der Leistung der Strategie bei der Bewältigung des Worst-Case-Szenarios erreicht. Da Angreifer in der Regel nicht in der Lage sind, in der Trainingsumgebung anzugreifen, schlägt der Autor einen gierigen Angriffsalgorithmus vor, der versucht, die erwartete Rendite der Strategie zu minimieren, ohne mit der Umgebung zu interagieren. Darüber hinaus schlägt der Autor auch einen Verteidigungsalgorithmus vor, der das gegnerische Training ermöglicht Deep Reinforcement Learning-Algorithmen unter Verwendung von Max-Min-Spielen. Experimentelle Ergebnisse in der Atari-Spielumgebung zeigen das
2023-04-08
Kommentar 0
1333
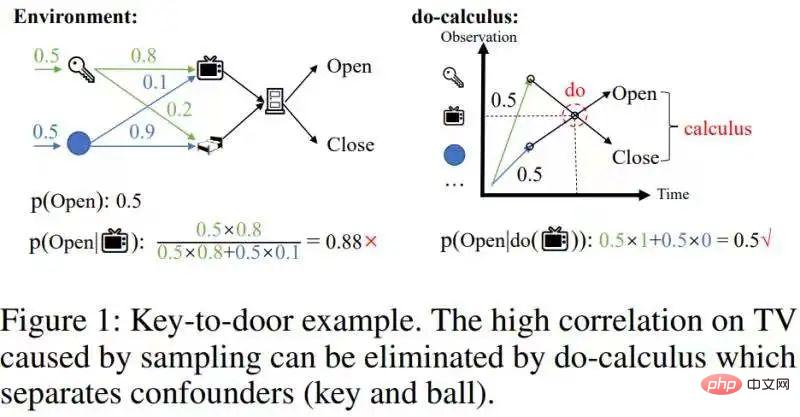
Zum ersten Mal vorgestellt! Verwendung kausaler Schlussfolgerungen, um teilweise beobachtbares Verstärkungslernen durchzuführen
Artikeleinführung:In diesem Artikel „Schnelle kontrafaktische Inferenz für geschichtsbasiertes Verstärkungslernen“ wird ein schneller Kausalinferenzalgorithmus vorgeschlagen, der die rechnerische Komplexität der Kausalinferenz erheblich reduziert – auf ein Niveau, das mit Online-Verstärkungslernen kombiniert werden kann. Die theoretischen Beiträge dieses Artikels umfassen hauptsächlich zwei Punkte: 1. Vorschlag des Konzepts der zeitlich gemittelten kausalen Effekte 2. Erweiterung des berühmten Backdoor-Kriteriums von der Schätzung des univariaten Interventionseffekts zur Schätzung des multivariablen Interventionseffekts, das als Step-Backdoor-Kriterium bezeichnet wird. Der Hintergrund erfordert die Vorbereitung von Grundkenntnissen über teilweise beobachtbares Verstärkungslernen und kausale Schlussfolgerungen. Ohne hier zu sehr auf die Einführung einzugehen, nennen wir ein paar Portale: Teilweise beobachtbare Verbesserung
2023-04-15
Kommentar 0
1083

Inverses Verstärkungslernen: Definition, Prinzipien und Anwendungen
Artikeleinführung:Inverse Reinforcement Learning (IRL) ist eine Technik des maschinellen Lernens, die beobachtetes Verhalten nutzt, um auf die zugrunde liegende Motivation zu schließen. Im Gegensatz zum traditionellen Verstärkungslernen erfordert IRL keine expliziten Belohnungssignale, sondern leitet stattdessen potenzielle Belohnungsfunktionen durch Verhalten ab. Diese Methode bietet eine effektive Möglichkeit, menschliches Verhalten zu verstehen und zu simulieren. Das Arbeitsprinzip von IRL basiert auf dem Rahmenwerk des Markov Decision Process (MDP). Bei MDP interagiert der Agent mit der Umgebung, indem er verschiedene Aktionen auswählt. Die Umgebung gibt basierend auf den Aktionen des Agenten ein Belohnungssignal aus. Das Ziel von IRL besteht darin, aus dem beobachteten Agentenverhalten eine unbekannte Belohnungsfunktion abzuleiten, um das Verhalten des Agenten zu erklären. Durch die Analyse der von einem Agenten in verschiedenen Staaten gewählten Aktionen kann IRL die Aktionen eines Agenten modellieren
2024-01-22
Kommentar 0
887

Eine Methode zur Optimierung von AB mithilfe des Lernens zur Verstärkung des Richtliniengradienten
Artikeleinführung:AB-Tests sind eine Technik, die in Online-Experimenten weit verbreitet ist. Sein Hauptzweck besteht darin, zwei oder mehr Versionen einer Seite oder Anwendung zu vergleichen, um festzustellen, welche Version bessere Geschäftsziele erreicht. Diese Ziele können Klickraten, Konversionsraten usw. sein. Im Gegensatz dazu handelt es sich beim Reinforcement Learning um eine Methode des maschinellen Lernens, die mithilfe von Trial-and-Error-Lernen Entscheidungsstrategien optimiert. Policy Gradient Reinforcement Learning ist eine spezielle Reinforcement-Learning-Methode, die darauf abzielt, die kumulativen Belohnungen durch das Erlernen optimaler Richtlinien zu maximieren. Beide haben unterschiedliche Anwendungen bei der Optimierung von Geschäftszielen. Beim AB-Testen betrachten wir unterschiedliche Seitenversionen als unterschiedliche Aktionen und Geschäftsziele können als wichtige Indikatoren für Belohnungssignale betrachtet werden. Um maximale Geschäftsziele zu erreichen, müssen wir eine Strategie entwerfen, die wählbar ist
2024-01-24
Kommentar 0
996

Hierarchisches Verstärkungslernen
Artikeleinführung:Hierarchical Reinforcement Learning (HRL) ist eine Reinforcement-Learning-Methode, die Verhaltensweisen und Entscheidungen auf hoher Ebene auf hierarchische Weise lernt. Im Gegensatz zu herkömmlichen Methoden des Verstärkungslernens zerlegt HRL die Aufgabe in mehrere Unteraufgaben, lernt in jeder Unteraufgabe eine lokale Strategie und kombiniert diese lokalen Strategien dann zu einer globalen Strategie. Diese hierarchische Lernmethode kann die durch hochdimensionale Umgebungen und komplexe Aufgaben verursachten Lernschwierigkeiten verringern und die Lerneffizienz und -leistung verbessern. Durch hierarchische Strategien kann HRL Entscheidungen auf verschiedenen Ebenen treffen, um intelligentere Verhaltensweisen auf höherer Ebene zu erreichen. Dieser Ansatz findet in vielen Bereichen Anwendung, beispielsweise in der Robotersteuerung, beim Gameplay und beim autonomen Fahren.
2024-01-22
Kommentar 0
1415

Probleme beim Design von Belohnungsfunktionen beim verstärkenden Lernen
Artikeleinführung:Probleme beim Design von Belohnungsfunktionen beim Reinforcement Learning Einführung Reinforcement Learning ist eine Methode, die optimale Strategien durch die Interaktion zwischen einem Agenten und der Umgebung lernt. Beim verstärkenden Lernen ist die Gestaltung der Belohnungsfunktion entscheidend für den Lerneffekt des Agenten. In diesem Artikel werden Probleme beim Design von Belohnungsfunktionen beim Reinforcement Learning untersucht und spezifische Codebeispiele bereitgestellt. Die Rolle der Belohnungsfunktion und der Zielbelohnungsfunktion sind ein wichtiger Teil des Verstärkungslernens und werden zur Bewertung des Belohnungswerts verwendet, den der Agent in einem bestimmten Zustand erhält. Sein Design hilft dem Agenten dabei, die langfristige Ermüdung durch die Auswahl optimaler Maßnahmen zu maximieren.
2023-10-09
Kommentar 0
1727

Probleme bei der Algorithmenauswahl beim Reinforcement Learning
Artikeleinführung:Das Problem der Algorithmenauswahl beim Reinforcement Learning erfordert spezifische Codebeispiele. Reinforcement Learning ist ein Bereich des maschinellen Lernens, das durch die Interaktion zwischen dem Agenten und der Umgebung optimale Strategien lernt. Beim Reinforcement Learning ist die Wahl eines geeigneten Algorithmus entscheidend für den Lerneffekt. In diesem Artikel untersuchen wir Probleme bei der Algorithmusauswahl beim Reinforcement Learning und stellen konkrete Codebeispiele bereit. Beim Reinforcement Learning stehen viele Algorithmen zur Auswahl, z. B. Q-Learning, DeepQNetwork (DQN), Actor-Critic usw. Wählen Sie den richtigen Algorithmus
2023-10-08
Kommentar 0
1197

Wie führt man tiefgreifendes Reinforcement Learning und natürliche Sprachübersetzung in PHP durch?
Artikeleinführung:Bei der Entwicklung moderner Technologie sind Deep Reinforcement Learning und natürliche Sprachübersetzung die beiden repräsentativsten Anwendungsbereiche. PHP als einfache und leicht zu erlernende Programmiersprache kann auch in diesen beiden Bereichen mitwirken und mehr Möglichkeiten für die weit verbreitete Anwendung der KI-Technologie bieten. 1. Deep Reinforcement Learning Deep Reinforcement Learning ist eine beliebte Forschungsrichtung im Bereich der künstlichen Intelligenz und wird in vielen Bereichen eingesetzt, darunter Spiele, autonomes Fahren, Robotersteuerung usw. Die Kernidee besteht darin, ein tiefes neuronales Netzwerk mit einer gegebenen Eingabe und Zielausgabe zu trainieren
2023-05-22
Kommentar 0
724

Wie führt man tiefgreifendes Reinforcement Learning und Benutzerverhaltensanalysen in PHP durch?
Artikeleinführung:Mit der kontinuierlichen Weiterentwicklung der Deep-Learning-Technologie wird künstliche Intelligenz zunehmend in verschiedenen Branchen eingesetzt. Neben verschiedenen Programmiersprachen kann PHP als beliebte serverseitige Sprache auch die Deep-Reinforcement-Learning-Technologie zur Analyse des Benutzerverhaltens nutzen. Deep Learning ist eine maschinelle Lerntechnologie, die durch Training mit großen Datenmengen Muster und Regelmäßigkeiten entdeckt. Deep Reinforcement Learning ist eine Methode, die Deep Learning und Reinforcement Learning kombiniert und zur Lösung komplexer Entscheidungsprobleme eingesetzt wird. Um Deep Reinforcement Learning in PHP zu implementieren, müssen Sie relevante PHP-Bibliotheken und -Boxen verwenden
2023-05-26
Kommentar 0
1004


Von Mäusen, die durch das Labyrinth laufen, bis hin zu AlphaGo, das Menschen besiegt, die Entwicklung des verstärkenden Lernens
Artikeleinführung:Wenn es um Reinforcement Learning geht, steigt bei vielen Forschern der Adrenalinspiegel unkontrolliert an! Es spielt eine sehr wichtige Rolle in Spiel-KI-Systemen, modernen Robotern, Chip-Design-Systemen und anderen Anwendungen. Es gibt viele verschiedene Arten von Reinforcement-Learning-Algorithmen, sie werden jedoch hauptsächlich in zwei Kategorien unterteilt: „modellbasiert“ und „modellfrei“. In einem Gespräch mit TechTalks diskutierte der Neurowissenschaftler und Autor von „The Birth of Intelligence“ Daeyeol Lee verschiedene Modelle des verstärkenden Lernens bei Menschen und Tieren, künstliche Intelligenz und natürliche Intelligenz sowie zukünftige Forschungsrichtungen. Modellfreies verstärkendes Lernen Im späten 19. Jahrhundert wurde das vom Psychologen Edward Thorndike vorgeschlagene „Gesetz der Wirkung“ zur Grundlage des modellfreien verstärkenden Lernens. Th
2023-05-09
Kommentar 0
877

Xishanju-KI-Technikexperte Huang Hongbo: Praktische Integration von Verstärkungslernen und Verhaltensbäumen in Spielen
Artikeleinführung:Vom 6. bis 7. August 2022 findet wie geplant die AISummit Global Artificial Intelligence Technology Conference statt. Auf dem Unterforum „Artificial Intelligence Frontier Exploration“, das am Nachmittag des 7. stattfand, brachte Huang Hongbo, technischer Experte für künstliche Intelligenz in Xishanju, einen Themenvortrag zum Thema „Praktische Kombination von Verstärkungslernen und Verhaltensbäumen in Spielen“ und erläuterte dabei ausführlich die Auswirkungen der Verstärkung Lernen im Spielbereich. Huang Hongbo sagte, dass die Implementierung der Reinforcement-Learning-Technologie nicht darin besteht, den Algorithmus zu ändern, um ihn leistungsfähiger zu machen, sondern darin, Reinforcement-Learning-Technologie mit Deep Learning und Spielplanung zu kombinieren, um einen vollständigen Satz von Lösungen zu bilden und diese umzusetzen. Reinforcement Learning macht Spiele intelligenter. Die Implementierung von Reinforcement Learning in Spielen kann Spiele intelligenter und spielbarer machen.
2023-04-09
Kommentar 0
1829

PromptPG: Wenn verstärkendes Lernen auf groß angelegte Sprachmodelle trifft
Artikeleinführung:Mathematische Argumentation ist eine Kernfähigkeit der menschlichen Intelligenz, aber abstraktes Denken und logisches Denken stellen immer noch eine große Herausforderung für Maschinen dar. Große vorab trainierte Sprachmodelle wie GPT-3 und GPT-4 haben erhebliche Fortschritte beim textbasierten mathematischen Denken (z. B. mathematische Wortprobleme) erzielt. Derzeit ist jedoch unklar, ob diese Modelle komplexere Probleme mit heterogenen Informationen wie Tabellendaten bewältigen können. Um diese Lücke zu schließen, führen Forscher der UCLA und des Allen Institute for Artificial Intelligence (AI2) Tabular Math Word Problems (TabMWP) ein, einen Datensatz mit 38.431 Open-Domain-Problemen, die erforderlich sind
2023-04-07
Kommentar 0
1232

Wie weit hat sich Transformer im Bereich Reinforcement Learning entwickelt? Die Tsinghua-Universität, die Peking-Universität und andere haben gemeinsam eine Rezension von TransformRL veröffentlicht
Artikeleinführung:Reinforcement Learning (RL) bietet eine mathematische Form für die sequentielle Entscheidungsfindung, und auch Deep Reinforcement Learning (DRL) hat in den letzten Jahren große Fortschritte gemacht. Probleme mit der Stichprobeneffizienz behindern jedoch die weitverbreitete Anwendung von Deep-Reinforcement-Learning-Methoden in der realen Welt. Um dieses Problem zu lösen, besteht ein wirksamer Mechanismus darin, eine induktive Vorspannung in das DRL-Framework einzuführen. Beim Deep Reinforcement Learning sind Funktionsnäherungen sehr wichtig. Im Vergleich zum Architekturdesign beim überwachten Lernen (Supervised Learning, SL) werden die Fragen des Architekturdesigns beim DRL jedoch immer noch selten untersucht. Die meisten bestehenden Arbeiten zu RL-Architekturen wurden von der betreuten/halbüberwachten Lerngemeinschaft vorangetrieben. Um beispielsweise Eingaben basierend auf hochdimensionalen Bildern in DRL zu verarbeiten, besteht ein gängiger Ansatz in der Einführung von Convolutional Neural Networks (CNN) [
2023-04-13
Kommentar 0
781
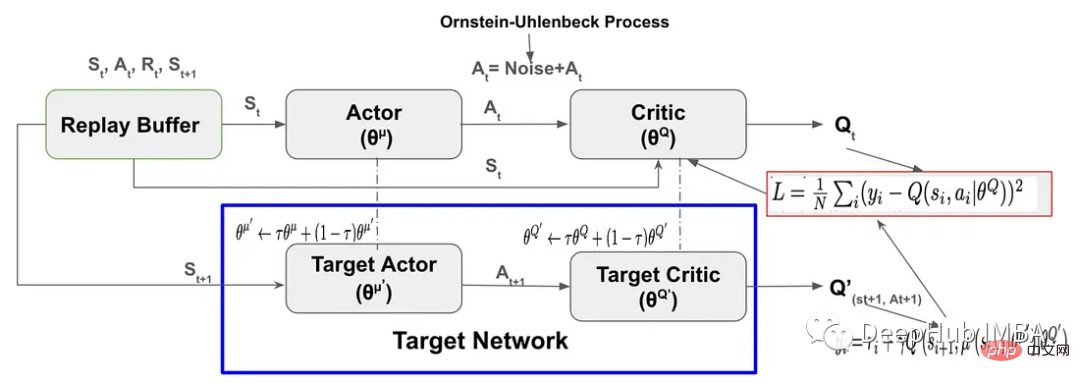
PyTorch-Code-Implementierung und Schritt-für-Schritt-Erklärung des DDPG-Verstärkungslernens
Artikeleinführung:Deep Deterministic Policy Gradient (DDPG) ist ein modellfreier, nicht richtlinienbasierter Tiefenverstärkungsalgorithmus. Er basiert auf Actor-Critic und verwendet Pytorch, um ihn vollständig zu implementieren Schlüsselkomponenten von DDPG sind Replay BufferActor-Critic Neural NetworkExploration NoiseTarget NetworkSoft Target Updates für Target Netwo
2023-04-13
Kommentar 0
1764

Was ist Deep Reinforcement Learning in Python?
Artikeleinführung:Was ist Deep Reinforcement Learning in Python? Deep Reinforcement Learning (DRL) hat sich in den letzten Jahren zu einem zentralen Forschungsschwerpunkt im Bereich der künstlichen Intelligenz entwickelt, insbesondere in Anwendungen wie Spielen, Robotern und der Verarbeitung natürlicher Sprache. Auf der Python-Sprache basierende Reinforcement-Learning- und Deep-Learning-Bibliotheken wie TensorFlow, PyTorch, Keras usw. ermöglichen uns eine einfachere Implementierung von DRL-Algorithmen. Die theoretischen Grundlagen des Deep Reinforcement Learning
2023-06-04
Kommentar 0
1826

So rüsten Sie Angelbegeisterte auf fortgeschrittene Ausrüstung auf. Tutorials für Angelbegeisterte, um ihre Ausrüstung aufzurüsten
Artikeleinführung:Dies ist ein Tutorial für Angelbegeisterte, um ihre Ausrüstung zu verbessern. Ich glaube, dass viele Spieler auch sehr darauf achten, wie sie ihre Ausrüstung verbessern können. Werfen wir einen Blick auf den spezifischen Inhalt dieses Abschnitts. Ich hoffe, er gefällt Ihnen. 1. Klicken Sie auf die Angelrute in Ihrer eigenen Ausrüstungsoberfläche. Anschließend wird die Verstärkungsschaltfläche angezeigt, wie im Bild gezeigt. Klicken Sie hier, um die Verstärkungsoberfläche aufzurufen. 2. Bei der gewöhnlichen Erweiterung gibt es zwei Optionen: bei der gewöhnlichen Erweiterung und bei der Barerhöhung kann es zu einem Scheitern des Upgrades kommen, während die Barerhöhung einen 100-prozentigen Erfolg beim Upgrade gewährleisten kann. Das Upgrade wird nicht vor +4 fehlschlagen, daher wird den Spielern empfohlen, es zunächst mit Goldmünzen zu stärken. 3. Erfolgreiche Stärkung Nach erfolgreicher Stärkung wird der Schaden der Angelrute erhöht. Der Schaden wirkt sich auf das Ausmaß der verbrauchten Körperkraft des Fisches aus. Je höher der Schaden, desto mehr Körperkraft wird jedes Mal verbraucht. Wenn Sie seltene Großfische fangen wollen, müssen Sie das tun
2024-07-20
Kommentar 0
511

Golangs Anwendung für maschinelles Lernen beim Reinforcement Learning
Artikeleinführung:Einführung in die maschinelle Lernanwendung von Golang beim Reinforcement Learning. Reinforcement Learning ist eine Methode des maschinellen Lernens, die optimales Verhalten durch Interaktion mit der Umgebung und basierend auf Belohnungsfeedback lernt. Die Go-Sprache verfügt über Funktionen wie Parallelität, Parallelität und Speichersicherheit, was ihr einen Vorteil beim verstärkenden Lernen verschafft. Praktischer Fall: Go Reinforcement Learning In diesem Tutorial verwenden wir die Go-Sprache und den AlphaZero-Algorithmus, um ein Go Reinforcement Learning-Modell zu implementieren. Schritt 1: Abhängigkeiten installieren gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
Kommentar 0
510

Probleme beim Belohnungsdesign beim verstärkenden Lernen
Artikeleinführung:Das Problem des Belohnungsdesigns beim Reinforcement Learning erfordert spezifische Codebeispiele. Reinforcement Learning ist eine Methode des maschinellen Lernens, deren Ziel darin besteht, zu lernen, wie man Aktionen durchführt, die die kumulativen Belohnungen durch Interaktion mit der Umgebung maximieren. Beim verstärkenden Lernen spielt die Belohnung eine entscheidende Rolle. Sie ist ein Signal im Lernprozess des Agenten und wird zur Steuerung seines Verhaltens verwendet. Das Belohnungsdesign ist jedoch ein herausforderndes Problem, und ein angemessenes Belohnungsdesign kann die Leistung von Verstärkungslernalgorithmen stark beeinträchtigen. Beim verstärkenden Lernen können Belohnungen als der Agent gegenüber der Umgebung betrachtet werden
2023-10-08
Kommentar 0
1448
