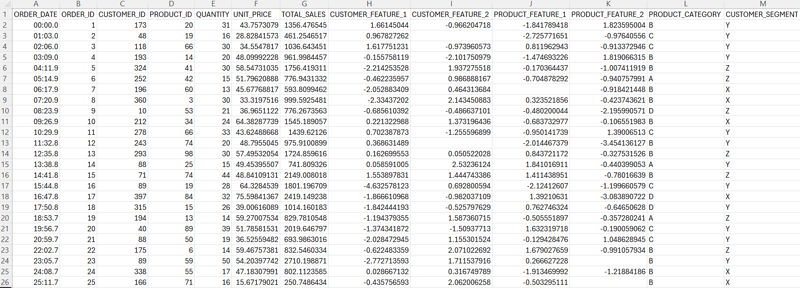
Insgesamt10000 bezogener Inhalt gefunden

So implementieren Sie verteilte Algorithmen und Modelltraining in PHP-Microservices
Artikeleinführung:So implementieren Sie verteilte Algorithmen und Modelltraining in PHP-Microservices. Einführung: Mit der rasanten Entwicklung von Cloud Computing und Big-Data-Technologie steigt die Nachfrage nach Datenverarbeitung und Modelltraining. Verteilte Algorithmen und Modelltraining sind der Schlüssel zum Erreichen von Effizienz, Geschwindigkeit und Skalierbarkeit. In diesem Artikel wird die Implementierung verteilter Algorithmen und Modelltrainings in PHP-Microservices vorgestellt und einige spezifische Codebeispiele bereitgestellt. 1. Was ist verteiltes Algorithmus- und Modelltraining? Verteiltes Algorithmus- und Modelltraining ist eine Technologie, die mehrere Maschinen oder Serverressourcen verwendet, um Datenverarbeitung und Modelltraining gleichzeitig durchzuführen.
2023-09-25
Kommentar 0
1465

Die Bedeutung der Datenvorverarbeitung beim Modelltraining
Artikeleinführung:Die Bedeutung der Datenvorverarbeitung beim Modelltraining und spezifische Codebeispiele Einführung: Beim Training von Modellen für maschinelles Lernen und Deep Learning ist die Datenvorverarbeitung ein sehr wichtiges und wesentliches Bindeglied. Der Zweck der Datenvorverarbeitung besteht darin, Rohdaten durch eine Reihe von Verarbeitungsschritten in eine für das Modelltraining geeignete Form umzuwandeln, um die Leistung und Genauigkeit des Modells zu verbessern. Ziel dieses Artikels ist es, die Bedeutung der Datenvorverarbeitung beim Modelltraining zu diskutieren und einige häufig verwendete Codebeispiele für die Datenvorverarbeitung zu geben. 1. Die Bedeutung der Datenvorverarbeitung. Datenbereinigung. Datenbereinigung ist die
2023-10-08
Kommentar 0
1296

Die zugrunde liegende Python-Technologie enthüllte: wie Modelltraining und -vorhersage implementiert werden
Artikeleinführung:Um die zugrunde liegende Technologie von Python aufzudecken: Für die Implementierung von Modelltraining und -vorhersage sind spezifische Codebeispiele erforderlich. Als leicht zu erlernende und benutzerfreundliche Programmiersprache wird Python häufig im Bereich des maschinellen Lernens verwendet. Python bietet eine große Anzahl von Open-Source-Bibliotheken und -Tools für maschinelles Lernen, wie Scikit-Learn, TensorFlow usw. Die Verwendung und Kapselung dieser Open-Source-Bibliotheken bietet uns viel Komfort, aber wenn wir ein tiefes Verständnis der zugrunde liegenden Technologie des maschinellen Lernens erlangen möchten, reicht die bloße Verwendung dieser Bibliotheken und Tools nicht aus. Dieser Artikel wird näher darauf eingehen
2023-11-08
Kommentar 0
1704

Die Auswirkungen der Datenknappheit auf das Modelltraining
Artikeleinführung:Die Auswirkungen der Datenknappheit auf das Modelltraining erfordern spezifische Codebeispiele. In den Bereichen maschinelles Lernen und künstliche Intelligenz sind Daten eines der Kernelemente für das Training von Modellen. Ein Problem, mit dem wir in der Realität jedoch häufig konfrontiert sind, ist die Datenknappheit. Unter Datenknappheit versteht man die unzureichende Menge an Trainingsdaten oder das Fehlen annotierter Daten. In diesem Fall hat dies einen gewissen Einfluss auf das Modelltraining. Das Problem der Datenknappheit spiegelt sich hauptsächlich in den folgenden Aspekten wider: Überanpassung: Wenn die Menge an Trainingsdaten nicht ausreicht, ist das Modell anfällig für Überanpassung. Überanpassung bezieht sich auf eine übermäßige Anpassung des Modells an die Trainingsdaten.
2023-10-08
Kommentar 0
1439

Kombinationspraxis und Modelltraining von MongoDB und künstlicher Intelligenz
Artikeleinführung:Mit der Weiterentwicklung der Technologie der künstlichen Intelligenz (KI) werden ihre Anwendungen in verschiedenen Bereichen immer weiter verbreitet. Als aufstrebende Datenbanktechnologie hat MongoDB auch großes Potenzial im Bereich der künstlichen Intelligenz gezeigt. In diesem Artikel werden die kombinierte Praxis und das Modelltraining von MongoDB und künstlicher Intelligenz sowie die positiven Auswirkungen untersucht, die sie gemeinsam haben. 1. Anwendung von MongoDB in der künstlichen Intelligenz MongoDB ist ein dokumentenorientiertes Datenbankverwaltungssystem, das eine JSON-ähnliche Datenstruktur verwendet. Im Vergleich zu herkömmlichen relationalen Datenbanken
2023-11-02
Kommentar 0
1508
So implementieren Sie eine lineare Regression in Python
Artikeleinführung:Die Schritte zum Implementieren der linearen Regression in Python sind: Importieren Sie die zu verwendende Bibliothek, lesen Sie die Daten und führen Sie eine Vorverarbeitung durch. Analysieren Sie Daten, erstellen Sie lineare Regressionsmodelle und führen Sie Modelltraining durch, um Modelleffekte zu testen.
2019-04-08
Kommentar 0
11579

Wie verwende ich SVM zur Klassifizierung in Python?
Artikeleinführung:SVM ist ein häufig verwendeter Klassifizierungsalgorithmus, der in den Bereichen maschinelles Lernen und Data Mining weit verbreitet ist. In Python ist die Implementierung von SVM sehr praktisch und kann durch die Verwendung relevanter Bibliotheken vervollständigt werden. In diesem Artikel wird die Verwendung von SVM zur Klassifizierung in Python vorgestellt, einschließlich Datenvorverarbeitung, Modelltraining und Parameteroptimierung. 1. Datenvorverarbeitung Bevor wir SVM zur Klassifizierung verwenden, müssen wir die Daten vorverarbeiten, um sicherzustellen, dass die Daten den Anforderungen des SVM-Algorithmus entsprechen. Typischerweise umfasst die Datenvorverarbeitung Folgendes
2023-06-03
Kommentar 0
2103

ChatGPT Python-Modell-Schulungsleitfaden: Schritte zum Anpassen eines Chatbots
Artikeleinführung:ChatGPTPython-Modellschulungsleitfaden: Übersicht über die Schritte zum Anpassen von Chat-Robotern: In den letzten Jahren haben Chat-Roboter mit der zunehmenden Entwicklung der NLP-Technologie (Natural Language Processing) immer mehr Aufmerksamkeit auf sich gezogen. ChatGPT von OpenAI ist ein leistungsstarkes vorab trainiertes Sprachmodell, das zum Erstellen von Multi-Domain-Chatbots verwendet werden kann. In diesem Artikel werden die Schritte zur Verwendung von Python zum Trainieren des ChatGPT-Modells vorgestellt, einschließlich Datenvorbereitung, Modelltraining und Generierung von Dialogbeispielen. Schritt 1: Datenaufbereitung, -erfassung und -bereinigung
2023-10-24
Kommentar 0
1344

Anwendung von Python-Lambda-Ausdrücken in der künstlichen Intelligenz: Erkundung unendlicher Möglichkeiten
Artikeleinführung:Der Lambda-Ausdruck ist eine anonyme Funktion in Python, die Code vereinfachen und die Effizienz verbessern kann. Im Bereich der künstlichen Intelligenz können Lambda-Ausdrücke für verschiedene Aufgaben verwendet werden, beispielsweise für die Datenvorverarbeitung, das Modelltraining und die Vorhersage. 1. Anwendungsszenarien von Lambda-Ausdrücken Datenvorverarbeitung: Lambda-Ausdrücke können zur Vorverarbeitung von Daten verwendet werden, z. B. zur Normalisierung, Standardisierung und Merkmalsextraktion. #Normalisierte DatennORMalisierte_Daten=Liste(map(lambdax:(x-min(Daten))/(max(Daten)-min(Daten)),Daten))#Standardisierte Daten standardisierte_Daten=Liste(m
2024-02-24
Kommentar 0
643

KI-Modelltraining: Verstärkungsalgorithmus und Evolutionsalgorithmus
Artikeleinführung:Der Reinforcement-Learning-Algorithmus (RL) und der Evolutionsalgorithmus (EA) sind zwei einzigartige Algorithmen im Bereich des maschinellen Lernens. Obwohl beide zur Kategorie des maschinellen Lernens gehören, gibt es offensichtliche Unterschiede in den Methoden und Konzepten der Problemlösung. Reinforcement-Learning-Algorithmus: Reinforcement-Learning ist eine Methode des maschinellen Lernens, deren Kern darin besteht, dass der Agent mit der Umgebung interagiert und durch Versuch und Irrtum optimale Verhaltensstrategien lernt, um die kumulativen Belohnungen zu maximieren. Der Schlüssel zum verstärkenden Lernen besteht darin, dass der Agent ständig verschiedene Verhaltensweisen ausprobiert und seine Strategie basierend auf Belohnungssignalen anpasst. Durch die Interaktion mit der Umgebung optimiert der Agent schrittweise seinen Entscheidungsprozess, um das festgelegte Ziel zu erreichen. Diese Methode imitiert die Art und Weise, wie Menschen lernen, und verbessert die Leistung durch kontinuierliches Ausprobieren und Anpassungen, sodass der Agent komplexe Aufgaben ausführen kann, einschließlich der Hauptkomponenten des verstärkenden Lernens.
2024-03-25
Kommentar 0
700

Wie gehe ich mit unstrukturierten und halbstrukturierten Daten in C++ um?
Artikeleinführung:Die Verarbeitung unstrukturierter Daten in C++ umfasst Datenvorverarbeitung, Merkmalsextraktion und Modelltraining. Die Verarbeitung halbstrukturierter Daten umfasst das Parsen, Extrahieren und Transformieren von Daten. Die spezifischen Schritte sind wie folgt: Unstrukturierte Daten: Datenvorverarbeitung: Rauschentfernung und Normalisierung. Merkmalsextraktion: Merkmale aus Daten extrahieren. Modelltraining: Verwenden Sie Algorithmen für maschinelles Lernen, um Muster zu lernen. Halbstrukturierte Daten: Datenanalyse: Konvertierung in geeignete Formate (XML, JSON, YAML). Datenextraktion: Erhalten Sie die Informationen, die Sie benötigen. Datenkonvertierung: in ein zur Weiterverarbeitung geeignetes Format.
2024-06-01
Kommentar 0
893

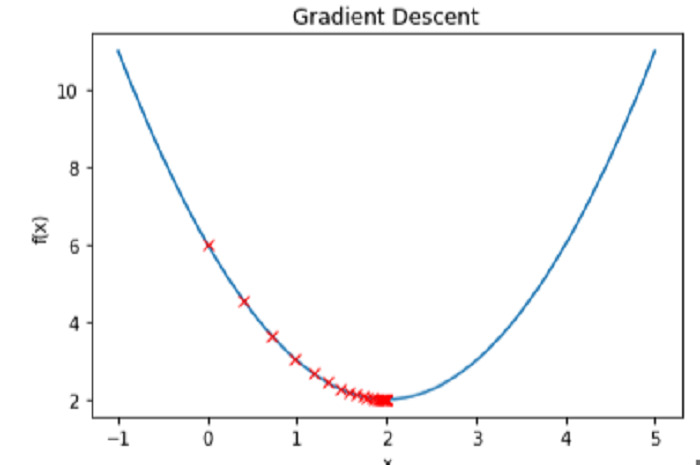
Wie implementiert man einen Gradientenabstiegsalgorithmus in Python, um lokale Minima zu finden?
Artikeleinführung:Der Gradientenabstieg ist eine wichtige Optimierungsmethode beim maschinellen Lernen, mit der die Verlustfunktion des Modells minimiert wird. Laienhaft ausgedrückt erfordert es eine wiederholte Änderung der Parameter des Modells, bis der ideale Wertebereich gefunden ist, der die Verlustfunktion minimiert. Die Methode funktioniert, indem sie winzige Schritte in Richtung des negativen Gradienten der Verlustfunktion durchführt, oder genauer gesagt, entlang des Pfads des steilsten Abfalls. Die Lernrate ist ein Hyperparameter, der den Kompromiss zwischen Geschwindigkeit und Genauigkeit des Algorithmus regelt und die Größe der Schrittweite beeinflusst. Viele Methoden des maschinellen Lernens, darunter lineare Regression, logistische Regression und neuronale Netze, um nur einige zu nennen, nutzen den Gradientenabstieg. Seine Hauptanwendung ist das Modelltraining, bei dem das Ziel darin besteht, die Differenz zwischen dem erwarteten und dem tatsächlichen Wert der Zielvariablen zu minimieren. In diesem Beitrag werden wir uns mit der Implementierung von Farbverläufen in Python befassen
2023-09-06
Kommentar 0
810

Die Golang-Technologie beschleunigt das Modelltraining beim maschinellen Lernen
Artikeleinführung:Durch die Nutzung der leistungsstarken Parallelität von Go kann das Training von maschinellen Lernmodellen beschleunigt werden: 1. Paralleles Laden von Daten unter vollständiger Nutzung von Goroutine zum Laden von Daten; 2. Optimierungsalgorithmus, verteiltes Rechnen über den Kanalmechanismus; Verwenden der nativen Netzwerkunterstützung. Trainieren Sie auf mehreren Computern.
2024-05-09
Kommentar 0
888

Mit ModelScope-Agent können Einsteiger auch exklusive Agenten erstellen, inklusive Tutorials auf Nanny-Niveau
Artikeleinführung:ModelScope-Agent bietet ein universelles, anpassbares Agenten-Framework, mit dem Benutzer ihre eigenen Agenten erstellen können. Das Framework basiert auf Open-Source-LLMs (Large Language Models) als Kern und bietet eine benutzerfreundliche Systembibliothek mit den folgenden Merkmalen: Anpassbares und umfassendes Framework: Bietet anpassbares Engine-Design, das Datenerfassung, Werkzeugabruf, Werkzeugregistrierung und Speicherung abdeckt Management, maßgeschneidertes Modelltraining und praktische Anwendungen usw. können verwendet werden, um Anwendungen schnell in tatsächlichen Szenarien umzusetzen. Open-Source-LLMs als Kernkomponenten: Unterstützen Sie das Modelltraining auf mehreren Open-Source-LLMs in der ModelScope-Community und öffnen Sie den unterstützenden chinesischen und englischen Tool-Anweisungsdatensatz MSAgent-Bench
2023-09-20
Kommentar 0
1257

Schritte zum Erstellen einer AI ML-Lösung
Artikeleinführung:Detaillierte Roadmap, die Sie durch die Datenerfassung, das Modelltraining und die Bereitstellung führt. Dieser Prozess ist iterativ, sodass Sie bei der Feinabstimmung Ihrer Lösung häufig auf frühere Schritte zurückgreifen.
Schritt 1: Verstehen Sie das Problem
Vor g
2024-12-24
Kommentar 0
587

JavaScript-Array-Manipulationen
Artikeleinführung:Die Bearbeitung von 2D-, 3D- oder 4D-Arrays in JavaScript ist für das KI-Modelltraining und die Bild-/Audio-/Videoanalyse erforderlich.
Nachfolgend finden Sie einige nützliche Funktionen zur Array-Manipulation mit reinem JavaScript ohne Matrixpakete wie Tensorflow.js.
Transponieren
2024-09-01
Kommentar 0
1214

Die Feinabstimmung von LLaMA reduziert den Speicherbedarf um die Hälfte, Tsinghua schlägt einen 4-Bit-Optimierer vor
Artikeleinführung:Das Training und die Feinabstimmung großer Modelle stellen hohe Anforderungen an den Videospeicher, und der Optimierungsstatus ist einer der Hauptkosten des Videospeichers. Kürzlich hat das Team von Zhu Jun und Chen Jianfei von der Tsinghua-Universität einen 4-Bit-Optimierer für das Training neuronaler Netze vorgeschlagen, der den Speicheraufwand beim Modelltraining einspart und eine Genauigkeit erreichen kann, die mit der eines Vollpräzisionsoptimierers vergleichbar ist. Der 4-Bit-Optimierer wurde an zahlreichen Vortrainings- und Feinabstimmungsaufgaben getestet und kann den Speicheraufwand für die Feinabstimmung von LLaMA-7B um bis zu 57 % reduzieren und gleichzeitig die Genauigkeit beibehalten. Papier: https://arxiv.org/abs/2309.01507 Code: https://github.com/thu-ml/low-bit-optimizers Speicherengpass beim Modelltraining
2023-09-12
Kommentar 0
656

Verwenden Sie Python, um ein Gadget zur Vorhersage von Immobilienpreisen zu erstellen!
Artikeleinführung:Hallo zusammen. Dies ist ein Fall der Immobilienpreisvorhersage, der von der Kaggle-Website stammt. Dies ist die erste Wettbewerbsfrage für viele Algorithmus-Anfänger. Dieser Fall umfasst einen vollständigen Prozess zur Lösung von Problemen des maschinellen Lernens, einschließlich EDA, Feature Engineering, Modelltraining, Modellfusion usw. Folgen Sie mir weiter unten zum Prozess der Hauspreisvorhersage, um mehr über diesen Fall zu erfahren. Es gibt keine langen Wörter, keinen überflüssigen Code, nur einfache Erklärungen. 1. EDA Der Zweck der explorativen Datenanalyse (EDA) besteht darin, uns ein umfassendes Verständnis des Datensatzes zu vermitteln. In diesem Schritt untersuchen wir den folgenden Inhalt: EDA-Inhalt 1.1 Eingabedatensatz train = pd.read_csv('
2023-04-12
Kommentar 0
1382