
Kurs Fortschrittlich 13830
Kurseinführung:Bei dieser Ausgabe handelt es sich immer noch um eine Live-Lehre von Branchenexperten, die sich an Studierende ohne Grundkenntnisse oder an Studierende richtet, die vom Back-End zum Front-End gewechselt sind. Das Kursdesign ist in vier Phasen mit insgesamt 50 Lerntagen unterteilt und basiert auf dem ursprünglichen HTML5+CSS3+JS+Vue3+Vant-Projekt. Das derzeit beliebteste Vue3+Vite+TS+ElementPlus wurde hinzugefügt, um die Multi-End-Entwicklung von Mall-Front-End, Mall-Back-End-Managementsystemen, Miniprogrammen, APPs usw. abzuschließen. Für detaillierte Anfragen wenden Sie sich bitte an WeChat: phpcn01 (Lehrer Yueyue)

Kurs Dazwischenliegend 11266
Kurseinführung:„Selbststudium IT-Netzwerk-Linux-Lastausgleich-Video-Tutorial“ implementiert hauptsächlich den Linux-Lastausgleich durch Ausführen von Skriptvorgängen im Web, LVS und Linux unter Nagin.

Kurs Fortschrittlich 17591
Kurseinführung:„Shang Xuetang MySQL Video Tutorial“ führt Sie in den Prozess von der Installation bis zur Verwendung der MySQL-Datenbank ein und stellt die spezifischen Vorgänge jedes Links im Detail vor.
Aktualisieren Sie die Bootstrap-Version in einem großen Laravel-Projekt
2023-09-03 19:24:13 0 1 604
2018-06-04 13:03:08 32 848 64145
2018-10-17 09:05:25 1 1 2974
2018-01-22 11:04:52 29 418 53856
2017-05-18 10:50:54 0 2 743
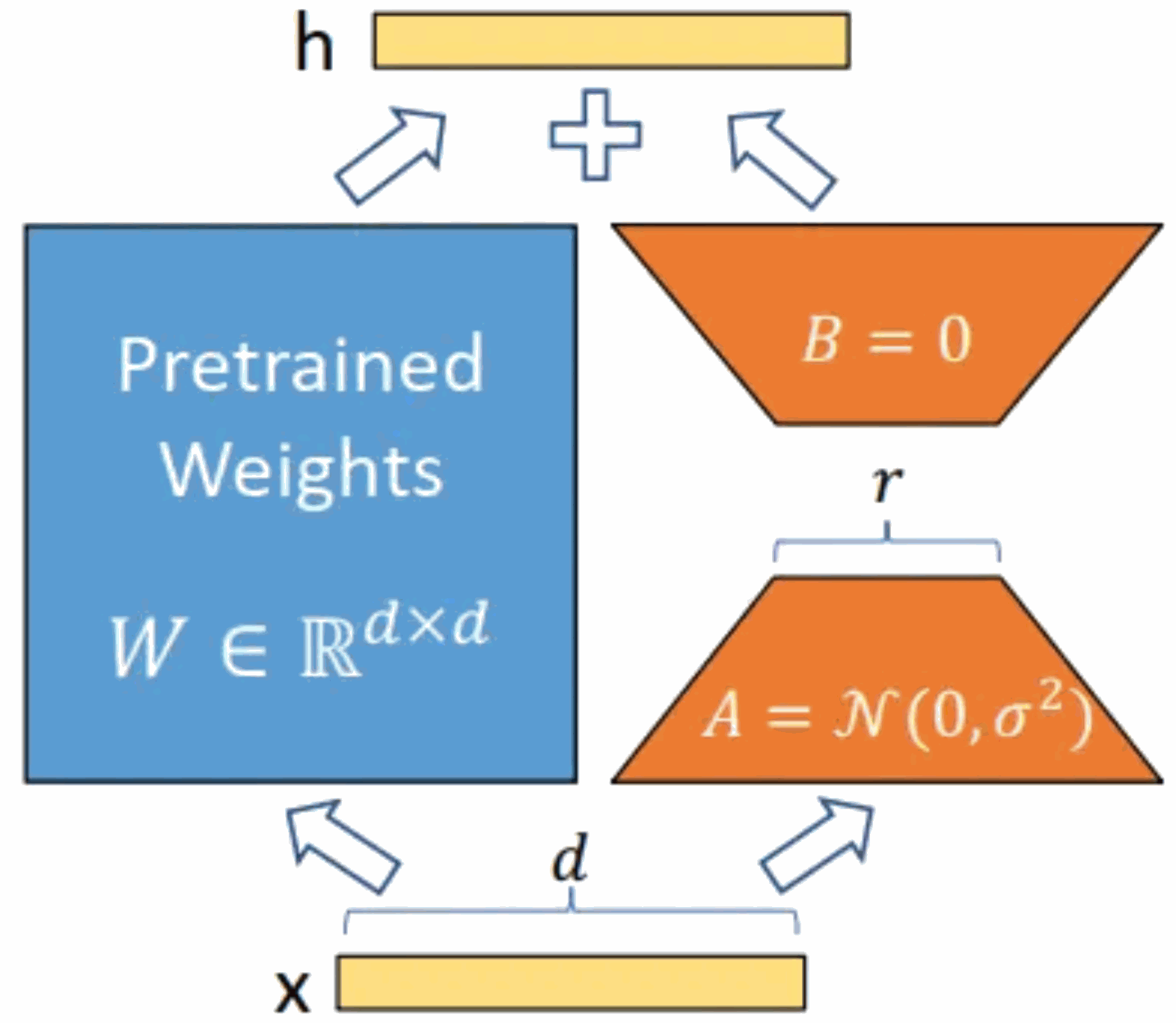
Kurseinführung:Modelleinführung: Das Alpaca-Modell ist ein von der Stanford University entwickeltes LLM-Modell (Large Language Model, große Sprache). Es basiert auf dem LLaMA7B-Modell (7B Open Source von Meta Company) und verfügt über 7 Milliarden Modellparameter (je größer die Modellparameter, desto größer die Modellparameter, desto stärker ist natürlich die Argumentationsfähigkeit des Modells, desto höher sind natürlich die Kosten für das Training des Modells). LoRA, der vollständige englische Name lautet „Low-RankAdaptation of Large Language Models“, wörtlich übersetzt „Low-Rank Adaptation of Large Language Models“. Hierbei handelt es sich um eine von Microsoft-Forschern entwickelte Technologie zur Lösung der Feinabstimmung großer Sprachmodelle. Wenn Sie möchten, dass ein vorab trainiertes großes Sprachmodell eine bestimmte Domäne ausführen kann
2023-06-01 Kommentar 0 1825

Kurseinführung:Große Sprachmodelle und Worteinbettungsmodelle sind zwei Schlüsselkonzepte in der Verarbeitung natürlicher Sprache. Sie können beide auf die Textanalyse und -generierung angewendet werden, die Prinzipien und Anwendungsszenarien sind jedoch unterschiedlich. Groß angelegte Sprachmodelle basieren hauptsächlich auf statistischen und probabilistischen Modellen und eignen sich zur Generierung von kontinuierlichem Text und semantischem Verständnis. Das Worteinbettungsmodell kann die semantische Beziehung zwischen Wörtern erfassen, indem es Wörter dem Vektorraum zuordnet, und eignet sich für die Inferenz der Wortbedeutung und die Textklassifizierung. 1. Worteinbettungsmodell Das Worteinbettungsmodell ist eine Technologie, die Textinformationen verarbeitet, indem Wörter in einen niedrigdimensionalen Vektorraum abgebildet werden. Es wandelt Wörter einer Sprache in Vektorform um, damit Computer Texte besser verstehen und verarbeiten können. Zu den häufig verwendeten Wörterinbettungsmodellen gehören Word2Vec und GloVe. Diese Modelle werden häufig bei der Verarbeitung natürlicher Sprache verwendet
2024-01-23 Kommentar 0 1455

Kurseinführung:Groß angelegte Sprachmodelle sind eine Schlüsseltechnologie im Bereich der Verarbeitung natürlicher Sprache und zeigen bei verschiedenen Aufgaben eine starke Leistung. Die Dekodierungsstrategie ist einer der wichtigen Aspekte der Textgenerierung durch das Modell. In diesem Artikel werden Dekodierungsstrategien in großen Sprachmodellen detailliert beschrieben und deren Vor- und Nachteile erörtert. 1. Überblick über Dekodierungsstrategien In großen Sprachmodellen sind Dekodierungsstrategien Methoden zur Generierung von Textsequenzen. Zu den gängigen Dekodierungsstrategien gehören Greedy Search, Beam Search und Random Search. Die gierige Suche ist eine einfache und unkomplizierte Methode, die jedes Mal das Wort mit der höchsten Wahrscheinlichkeit als nächstes Wort auswählt, andere Möglichkeiten jedoch möglicherweise ignoriert. Die Strahlsuche fügt der gierigen Suche eine Breitenbeschränkung hinzu und behält nur die Kandidatenwörter mit der höchsten Wahrscheinlichkeit bei, wodurch die Vielfalt erhöht wird. Bei der Zufallssuche wird das nächste Wort zufällig ausgewählt, was zu einer größeren Vielfalt führen kann
2024-01-22 Kommentar 0 1197

Kurseinführung:Das größte Risiko, dem die Technologie der künstlichen Intelligenz derzeit ausgesetzt ist, besteht darin, dass die Entwicklungs- und Anwendungsgeschwindigkeit von großen Sprachmodellen (LLM) und der generativen Technologie der künstlichen Intelligenz die Geschwindigkeit von Sicherheit und Governance bei weitem übertroffen hat. Die Nutzung generativer KI und großer Sprachmodellprodukte von Unternehmen wie OpenAI, Anthropic, Google und Microsoft nimmt exponentiell zu. Gleichzeitig nehmen auch Open-Source-Lösungen für große Sprachmodelle schnell zu. Open-Source-Communitys für künstliche Intelligenz wie HuggingFace bieten eine große Anzahl von Open-Source-Modellen, Datensätzen und KI-Anwendungen. Um die Entwicklung künstlicher Intelligenz voranzutreiben, entwickeln und stellen Branchenorganisationen wie OWASP, OpenSSF und CISA aktiv wichtige Ressourcen für die Sicherheit und Governance künstlicher Intelligenz bereit, beispielsweise OWASPAIExchange.
2024-04-17 Kommentar 0 1052

Kurseinführung:In diesem Artikel werden die am häufigsten verwendeten und zuverlässigsten Metriken zur Bewertung großer Sprachmodelle (LLMs) untersucht. Der Artikel bespricht die verschiedenen Kategorien von Metriken, darunter BLEU, ROUGE, METEOR und NIST, und wie sie die Leistung von L messen
2024-08-13 Kommentar 0 1056
