
Kurs Dazwischenliegend 11382
Kurseinführung:„Selbststudium IT-Netzwerk-Linux-Lastausgleich-Video-Tutorial“ implementiert hauptsächlich den Linux-Lastausgleich durch Ausführen von Skriptvorgängen im Web, LVS und Linux unter Nagin.

Kurs Fortschrittlich 17696
Kurseinführung:„Shang Xuetang MySQL Video Tutorial“ führt Sie in den Prozess von der Installation bis zur Verwendung der MySQL-Datenbank ein und stellt die spezifischen Vorgänge jedes Links im Detail vor.

Kurs Fortschrittlich 11395
Kurseinführung:„Brothers Band Front-End-Beispiel-Display-Video-Tutorial“ stellt jedem Beispiele für HTML5- und CSS3-Technologien vor, damit jeder die Verwendung von HTML5 und CSS3 besser beherrschen kann.
2023-09-05 11:18:47 0 1 884
Experimentieren Sie mit der Sortierung nach Abfragelimit
2023-09-05 14:46:42 0 1 769
2023-09-05 15:18:28 0 1 650
PHP-Volltextsuchfunktion mit den Operatoren AND, OR und NOT
2023-09-05 15:06:32 0 1 620
Der kürzeste Weg, alle PHP-Typen in Strings umzuwandeln
2023-09-05 15:34:44 0 1 1035

Kurseinführung:Deep Reinforcement Learning (DeepReinforcementLearning) ist eine fortschrittliche Technologie, die Deep Learning und Reinforcement Learning kombiniert. Sie wird häufig in der Spracherkennung, Bilderkennung, Verarbeitung natürlicher Sprache und anderen Bereichen eingesetzt. Als schnelle, effiziente und zuverlässige Programmiersprache kann die Go-Sprache bei der tiefgreifenden Forschung zum Reinforcement Learning hilfreich sein. In diesem Artikel wird erläutert, wie Sie mithilfe der Go-Sprache tiefgreifende Forschung zum verstärkten Lernen durchführen können. 1. Installieren Sie die Go-Sprache und die zugehörigen Bibliotheken und beginnen Sie mit der Verwendung der Go-Sprache für tiefgreifendes, verstärkendes Lernen.
2023-06-10 Kommentar 0 1220
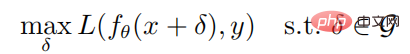
Kurseinführung:01 Einleitung In diesem Artikel geht es um die Arbeit des Deep Reinforcement Learning gegen Angriffe. In diesem Artikel untersucht der Autor die Robustheit von Deep-Reinforcement-Learning-Strategien gegenüber gegnerischen Angriffen aus der Perspektive einer robusten Optimierung. Im Rahmen der robusten Optimierung wird der optimale gegnerische Angriff durch die Minimierung der erwarteten Rendite der Strategie erreicht, und dementsprechend wird ein guter Abwehrmechanismus durch die Verbesserung der Leistung der Strategie bei der Bewältigung des Worst-Case-Szenarios erreicht. Da Angreifer in der Regel nicht in der Lage sind, in der Trainingsumgebung anzugreifen, schlägt der Autor einen gierigen Angriffsalgorithmus vor, der versucht, die erwartete Rendite der Strategie zu minimieren, ohne mit der Umgebung zu interagieren. Darüber hinaus schlägt der Autor auch einen Verteidigungsalgorithmus vor, der das gegnerische Training ermöglicht Deep Reinforcement Learning-Algorithmen unter Verwendung von Max-Min-Spielen. Experimentelle Ergebnisse in der Atari-Spielumgebung zeigen das
2023-04-08 Kommentar 0 1326
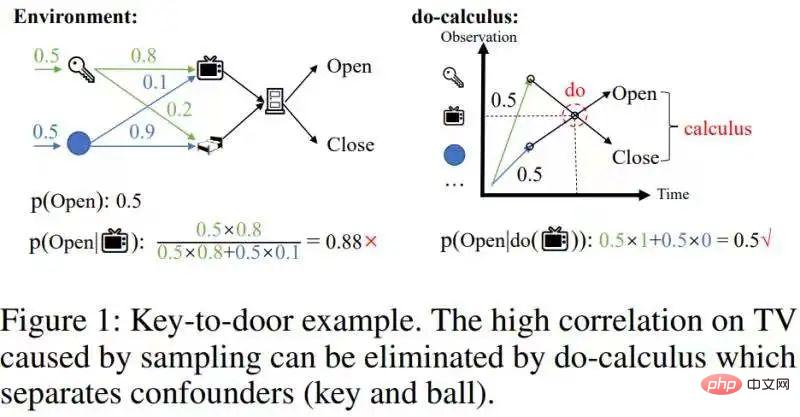
Kurseinführung:In diesem Artikel „Schnelle kontrafaktische Inferenz für geschichtsbasiertes Verstärkungslernen“ wird ein schneller Kausalinferenzalgorithmus vorgeschlagen, der die rechnerische Komplexität der Kausalinferenz erheblich reduziert – auf ein Niveau, das mit Online-Verstärkungslernen kombiniert werden kann. Die theoretischen Beiträge dieses Artikels umfassen hauptsächlich zwei Punkte: 1. Vorschlag des Konzepts der zeitlich gemittelten kausalen Effekte 2. Erweiterung des berühmten Backdoor-Kriteriums von der Schätzung des univariaten Interventionseffekts zur Schätzung des multivariablen Interventionseffekts, das als Step-Backdoor-Kriterium bezeichnet wird. Der Hintergrund erfordert die Vorbereitung von Grundkenntnissen über teilweise beobachtbares Verstärkungslernen und kausale Schlussfolgerungen. Ohne hier zu sehr auf die Einführung einzugehen, nennen wir ein paar Portale: Teilweise beobachtbare Verbesserung
2023-04-15 Kommentar 0 1081

Kurseinführung:Inverse Reinforcement Learning (IRL) ist eine Technik des maschinellen Lernens, die beobachtetes Verhalten nutzt, um auf die zugrunde liegende Motivation zu schließen. Im Gegensatz zum traditionellen Verstärkungslernen erfordert IRL keine expliziten Belohnungssignale, sondern leitet stattdessen potenzielle Belohnungsfunktionen durch Verhalten ab. Diese Methode bietet eine effektive Möglichkeit, menschliches Verhalten zu verstehen und zu simulieren. Das Arbeitsprinzip von IRL basiert auf dem Rahmenwerk des Markov Decision Process (MDP). Bei MDP interagiert der Agent mit der Umgebung, indem er verschiedene Aktionen auswählt. Die Umgebung gibt basierend auf den Aktionen des Agenten ein Belohnungssignal aus. Das Ziel von IRL besteht darin, aus dem beobachteten Agentenverhalten eine unbekannte Belohnungsfunktion abzuleiten, um das Verhalten des Agenten zu erklären. Durch die Analyse der von einem Agenten in verschiedenen Staaten gewählten Aktionen kann IRL die Aktionen eines Agenten modellieren
2024-01-22 Kommentar 0 885

Kurseinführung:AB-Tests sind eine Technik, die in Online-Experimenten weit verbreitet ist. Sein Hauptzweck besteht darin, zwei oder mehr Versionen einer Seite oder Anwendung zu vergleichen, um festzustellen, welche Version bessere Geschäftsziele erreicht. Diese Ziele können Klickraten, Konversionsraten usw. sein. Im Gegensatz dazu handelt es sich beim Reinforcement Learning um eine Methode des maschinellen Lernens, die mithilfe von Trial-and-Error-Lernen Entscheidungsstrategien optimiert. Policy Gradient Reinforcement Learning ist eine spezielle Reinforcement-Learning-Methode, die darauf abzielt, die kumulativen Belohnungen durch das Erlernen optimaler Richtlinien zu maximieren. Beide haben unterschiedliche Anwendungen bei der Optimierung von Geschäftszielen. Beim AB-Testen betrachten wir unterschiedliche Seitenversionen als unterschiedliche Aktionen und Geschäftsziele können als wichtige Indikatoren für Belohnungssignale betrachtet werden. Um maximale Geschäftsziele zu erreichen, müssen wir eine Strategie entwerfen, die wählbar ist
2024-01-24 Kommentar 0 995
