Es gibt kein Problem, wenn Sie auf das Laufwerk D herunterladen, aber es gibt ein Problem, wenn Sie in das von mir erstellte Verzeichnis herunterladen (hauptsächlich, weil ich auf dem Laufwerk D ein Verzeichnis mit der Nummer vor dem Fragezeichen in erstellen möchte). Die URL (z. B. (http://v.yupoo) .com/photos/196...') funktioniert einfach nicht, da es viele Links gibt und die Anzahl der einzelnen Links unterschiedlich ist Diese Nummer dient als Name des Ordners zum Speichern der über diesen Link heruntergeladenen Bilder.)
Der Quellcode lautet wie folgt: 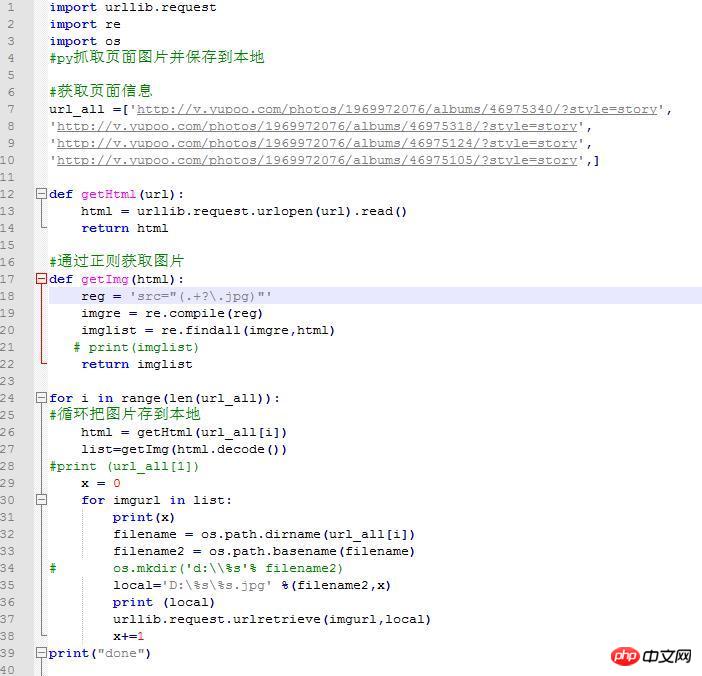
import urllib.request
import re
import os
url_all =['http://v.yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',
'http://v .yupoo.com/photos/196...',
'http://v.yupoo.com/photos/196...',]
def getHtml(url):
html = urllib.request.urlopen(url).read()
return html
def getImg(html):
reg = 'src="(.+?\.jpg)"'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)# print(imglist)
return imglist
für mich im Bereich(len(url_all)):
html = getHtml(url_all[i])
list=getImg(html.decode())x = 0
for imgurl in list:
print(x)
filename = os.path.dirname(url_all[i])
filename2 = os.path.basename(filename) local='D:\%s\%s.jpg' %(filename2,x)
print (local)
urllib.request.urlretrieve(imgurl,local)
x+=1Ausführungsfehler: (Win10 64-Bit-System, Python3.6)
Datei „C:Python36liburllibrequest.py“, Zeile 258, in urlretrieve
tfp = open(filename, 'wb')
Der letzte so geschriebene Satz kann ausgegeben werden: urllib.request.urlretrieve(imgurl,'d:%s.jpg'% str(i*10+x))
local='d:%s%s.jpg' %(filename2,x)
urllib.request.urlretrieve(imgurl,local)
Die Fehlermeldung lautet wie folgt: (Wie oben)
Datei „C:Python36liburllibrequest.py“, Zeile 258, in urlretrieve
tfp = open(filename, 'wb')
FileNotFoundError: [Errno 2] Keine solche Datei oder kein solches Verzeichnis: 'd:46975340
Bitte sagen Sie mir, gibt es ein Problem mit diesem Weg? Wie soll es geschrieben werden.














![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




在保存之前,先检查一下目录是否存在,不存在则建立