source_ip = line.split('- -')[0].strip()
if re.match('[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}',source_ip):
if source_ip_dict.get(source_ip,'-')=='-':
source_ip_dict[source_ip]=1
else:
source_ip_dict[source_ip]=source_ip_dict[source_ip]+1Extrahieren Sie die Apache-Protokoll-IP mit dem obigen Code und führen Sie eine statistische Deduplizierung durch.
Die extrahierten IP-Daten lauten wie folgt: 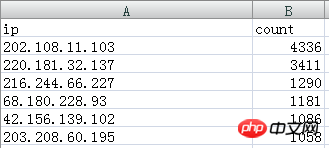
So benennen und klassifizieren Sie diese IP-Adressen:
Beispiel:
202.108.11.103 und 220.181.32.137 sind Baidu Spider-IPs
Der gewünschte Effekt ist wie folgt:
Nennen Sie diese beiden IPs als Baidu Spider und vergleichen Sie dann ihre statistischen Daten. Fügen Sie 4336+3411
Baidu Spider 7747
So bedienen Sie das














![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




可以尝试构建一个大型的以字典为键, 爬虫名字为值的字典;
使用pandas的数据透视表
这样多累啊!
为什么不给这个ip分组单独建立一张表, 名为IPGroup (id, ip, groupname)
之后一个SQL就搞定了,多么轻松(设楼主用的表明为IPStastics)