Ich möchte die Ergebnisse von Live-Übertragungsereignissen erfassen: Live-Übertragungslinks, aber ich kann das Datum, die Heim- und Auswärtsmannschaften usw. nur mit Scrapy erfassen. Meine Frage ist: Werden die Partituren per Script geladen? Ist es in bf4.js in diesem Skript? Wie erhalte ich die Punktzahl genau, wie unten in dieser Anforderungsmethode: GET-Situation gezeigt?
Der Quellcode der über die Entwicklertools angezeigten Webseite lautet wie folgt: <li label="足球,中甲,武汉卓尔" id="saishi93287" data-time="2017-06-24 15:00">15:00 <b>中甲第15轮</b> 云南丽江 <img src="//duihui.qiumibao.com/zuqiu/yunnanlijiang.png" > <span> - </span> <img src="//duihui.qiumibao.com/zuqiu/wuhanzhuoer.png" > 武汉卓尔 <a href="/zhibo/zuqiu/2017/0624yunnanlijiangvswuhanzhuoer.htm" target="_blank">武汉文体 广州竞赛 PPTV</a> <a href="http://wenzi.zhibo8.cc/zhibo/zuqiu/2017/0624yunnanlijiangvswuhanzhuoer.htm" target="_blank">文字</a> <a href="//www.zhibo8.cc/shouji.htm" target="_blank">手机看直播</a> <a href="http://www.188bifen.com/" target="_blank">比分</a> <a href="http://ogzq2.wanjiashe.com/game.php?sid=51&zhibo" target="_blank">欧冠足球新服</a> </li>
Das heißt, die Partitur wird nicht in <span> angezeigt. Wie kann ich die gerenderte Partitur-Webseite erfassen? 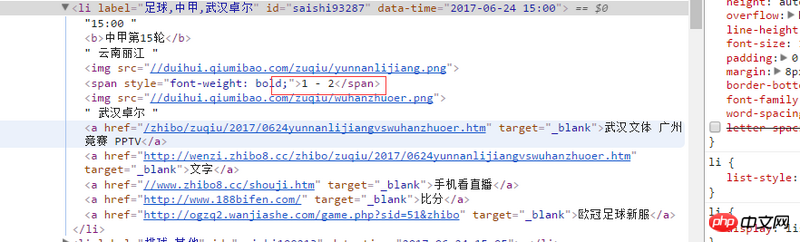















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




那就使用Selenium 来获取吧,
链接描述