- Frontend
- HTML| CSS| JavaScript| Vue.js
Neueste Empfehlungen
-

PHP8, ich komme auch
84669 Lernen von Personen
- einheimische Stiftung
- HTML| CSS| HTML5| CSS3| JavaScript
Neueste Empfehlungen
-

Lernen Sie das Website-Layout in 30 Minuten
152542 Lernen von Personen
- Einführung in die Grundlagen
- MySQL| SQL Server
Neueste Empfehlungen
-

Shangguan Oracle Video-Tutorial für Anfänger bis Fortgeschrittene
20005 Lernen von Personen
Neueste Empfehlungen
-

Ihre erste Zeile UNI-APP-Code
5487 Lernen von Personen
-

Flattern Sie von Grund auf bis zum App-Start
7821 Lernen von Personen
- Werkzeugnutzung
- PhpStudy| Git| Andere Werkzeuge
Neueste Empfehlungen
-

Brother Lian Neues Linux-Video-Tutorial
359900 Lernen von Personen
Neueste Empfehlungen
-

-

Zero Basic Proficiency PS-Video-Tutorial
180660 Lernen von Personen
-

16-tägiges UI-Video-Tutorial für den Einstieg
48569 Lernen von Personen
-

PS-Techniken und Slicing-Techniken-Video-Tutorial
18603 Lernen von Personen
- Klassifizierung der Klassenbibliothek
- HTTP| TCP/IP| grundlegende Programmierung
Neueste Empfehlungen
-

Video-Tutorial zum Bau und zur Projekteinführung der Alibaba Cloud-Umgebung
40936 Lernen von Personen
-

Überblick über Computernetzwerke – Grundkenntnisse, die Programmierer beherrschen müssen
1549 Lernen von Personen
-

Grundlegendes Tutorial für Programmierer – Erklärung des HTTP-Protokolls
1183 Lernen von Personen
-

Websocket-Video-Tutorial
32909 Lernen von Personen

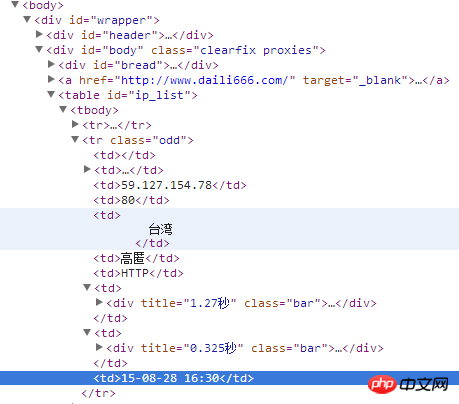
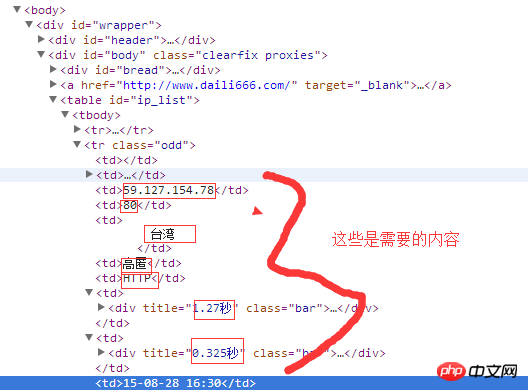



















以下代码可以解决了,谢谢各位的解答。。。
用xpath去找吧。。 lxml解析
感觉正则表达式可能有点问题。
首先看文档结构:
每一个
<tr>...</tr>标签里包含了一列完整的内容,而<td>...</td>标签里是一个单项内容。建议用正则表达是从
<tr>标签开始对每一个<td>标签进行解析。大概这样:
r'(<tr class.*?>.*?<td.*?<td.*?<td>(.*?)</td>.......</tr>)'这里面
(.*?)就是解析出来的ip地址了,后面类似。写起来有点麻烦,但应该不会错。
其实用BeautifulSoup会简单很多。
用re来操作html,也是醉了,xpath吧。
推荐用BeautifulSoup
BeautifulSoup 是一个很好的选择,自己写正则表达式代码也显得不够优雅。
……scrapy呀
scrapy...