简单的例子来说一说Python里的垃圾回收机制,O(∩_∩)O谢谢。
业精于勤,荒于嬉;行成于思,毁于随。
引用计数
为每个内存对象维护一个引用计数。当有新的引用指向某对象时就将该对象的引用计数加一,当指向该对象的引用被销毁时将该计数减一,当计数归零时,就回收该对象所占用的内存资源。
标记-清除
分两个步骤,一是标记,即从众多的内存对象中区分出不会再被使用的垃圾对象;二是清除,即把标记的垃圾对象清除掉。标记的时候需要确定内存对象的集合Root set,集合里的对象都是可以访问的。如果Root set中的对象引用了其他的对象,那么被引用的对象也不能被标记为垃圾对象。然后从Root set出发,递归遍历Root set能访问到的所有对象,进行标记为不是垃圾对象。遍历结束后,没有被标记的就是垃圾对象。
分代收集
根据一个统计学上的结论,如果一个内存对象在某次Mark过程中发现不是垃圾,那么它短期内成为垃圾的可能性就很小。分代收集将那些在多次垃圾收集过程中都没有被标记为垃圾对象的内存对象集中到另外一个区域——年老的区域,即这个区域中的内存对象年龄比较大。因为年老区域内内存对象短期内变成垃圾的概率很低,所以这些区域的垃圾收集频率可以降低,相对的,对年轻区域内的对象进行高频率的垃圾收集。这样可以提高垃圾收集的整体性能。
在CPython中,大多数对象的生命周期都是通过对象的引用计数来管理的。引用计数是一种最直观、最简单的垃圾收集计数,与其他主流GC算法比较,它的最大优点是实时性,即任何内存,一旦没有指向它的引用,就会立即被回收。
然而引用计数存在两个比较麻烦的缺陷:
当程序中出现循环引用时,引用计数无法检测出来,被循环引用的内存对象就成了无法回收的内存,引起内存泄露。比如:
list1 = [] list1.append(list1) del list1
list1循环引用了自身,第二行执行完后,list1的GC变成了2,执行完del操作后,list1的引用计数变为1,并没有归零,list1的内存空间并没有被释放,造成内存泄露。维护引用计数需要额外的操作。
list1
del
在每次内存对象呗引用或者引用被销毁时都需要修改引用计数,这类操作被称为footprint。引用计数的footprint是很高的,使得程序的整体性能受到很大的影响。
footprint
为了解决循环引用的问题,CPython特别设计了一个模块——GC module,其主要作用就是检查出循环引用的垃圾对象,并清除他们。该模块的实现,实际上也是引入了前面提到的两种主流的垃圾收集技术——标记清除和分代收集。
GC module
为了解决引用计数的性能问题,尽量再内存的分配和释放上获得最高的效率,Python因此还设计了大量的内存池机制。
Python的垃圾回收采用的引用计数的办法, 引用计数的原理可以自己从网上找.以下的python分配器的层级
其实不止引用计数法了, 还有标记-清除及分代回收, 这篇博文总结的很好
http://hbprotoss.github.io/po...
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。
ob_refcnt
优点:
简单
实时性
缺点:
维护引用计数消耗资源
循环引用
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。





















常见的GC算法
引用计数
标记-清除
分代收集
Python中的内存管理
在CPython中,大多数对象的生命周期都是通过对象的引用计数来管理的。引用计数是一种最直观、最简单的垃圾收集计数,与其他主流GC算法比较,它的最大优点是实时性,即任何内存,一旦没有指向它的引用,就会立即被回收。
然而引用计数存在两个比较麻烦的缺陷:
当程序中出现循环引用时,引用计数无法检测出来,被循环引用的内存对象就成了无法回收的内存,引起内存泄露。比如:
list1循环引用了自身,第二行执行完后,list1的GC变成了2,执行完del操作后,list1的引用计数变为1,并没有归零,list1的内存空间并没有被释放,造成内存泄露。维护引用计数需要额外的操作。
在每次内存对象呗引用或者引用被销毁时都需要修改引用计数,这类操作被称为
footprint。引用计数的footprint是很高的,使得程序的整体性能受到很大的影响。为了解决循环引用的问题,CPython特别设计了一个模块——
GC module,其主要作用就是检查出循环引用的垃圾对象,并清除他们。该模块的实现,实际上也是引入了前面提到的两种主流的垃圾收集技术——标记清除和分代收集。为了解决引用计数的性能问题,尽量再内存的分配和释放上获得最高的效率,Python因此还设计了大量的内存池机制。
Python的垃圾回收采用的引用计数的办法, 引用计数的原理可以自己从网上找.以下的python分配器的层级
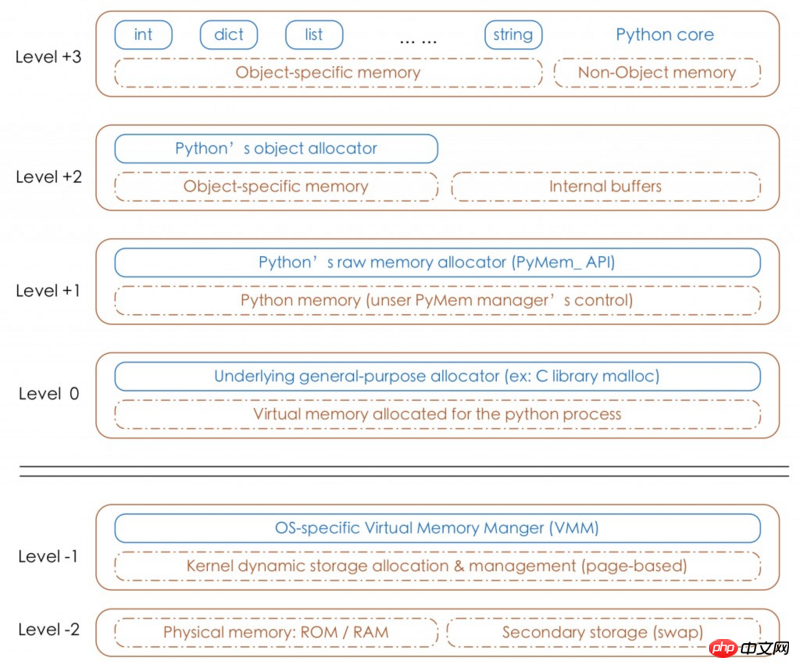
其实不止引用计数法了, 还有标记-清除及分代回收, 这篇博文总结的很好
http://hbprotoss.github.io/po...
Python GC主要使用引用计数(reference counting)来跟踪和回收垃圾。在引用计数的基础上,通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用问题,通过“分代回收”(generation collection)以空间换时间的方法提高垃圾回收效率。
1 引用计数
PyObject是每个对象必有的内容,其中
ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少.引用计数为0时,该对象生命就结束了。优点:
简单
实时性
缺点:
维护引用计数消耗资源
循环引用
2 标记-清除机制
基本思路是先按需分配,等到没有空闲内存的时候从寄存器和程序栈上的引用出发,遍历以对象为节点、以引用为边构成的图,把所有可以访问到的对象打上标记,然后清扫一遍内存空间,把所有没标记的对象释放。
3 分代技术
分代回收的整体思想是:将系统中的所有内存块根据其存活时间划分为不同的集合,每个集合就成为一个“代”,垃圾收集频率随着“代”的存活时间的增大而减小,存活时间通常利用经过几次垃圾回收来度量。
Python默认定义了三代对象集合,索引数越大,对象存活时间越长。