认证高级PHP讲师
"User-Agent": "Mozilla/5.0 (windows 6.0)"
python3
import urllib.request url = "http://www.qiushibaike.com/8hr/page/1" headers = { #"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)" "User-Agent": "Mozilla/5.0 (windows 6.0)" } request = urllib.request.Request(url, headers=headers) response = urllib.request.urlopen(request) c = response.read() h = c.decode('utf-8') print(h)
python3 不需要转码
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




"User-Agent": "Mozilla/5.0 (windows 6.0)"python3
python3 不需要转码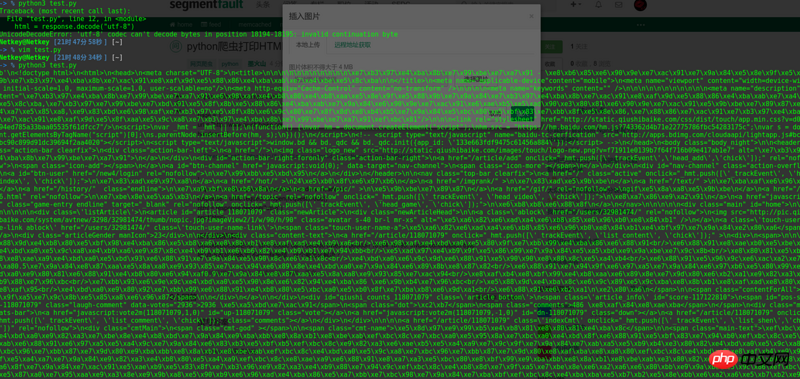
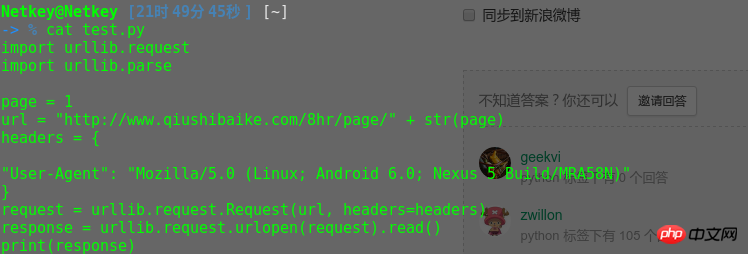
我又尝试了以下。发现response.decode('UTF-8')就可以。是的大写!!!