
aktueller Standort: Heim > Herunterladen > Manueller Download > Andere Handbücher > Big-Data-Verarbeitung mit Apache Spark

Big-Data-Verarbeitung mit Apache Spark
| Klassifizieren: Manueller Download / Andere Handbücher | Veröffentlichkeitsdatum: 2024-01-29 | Besuche: 1316 |
| Herunterladen: 0 |
Neueste Downloads

Himalaya -Kinder
Zebra ai
Supermarktmanager Simulator
Alarmstufe Rot OL
Operationsdelta
Pokémon-Versammlung
Fantasy-Aquarium
Girls Frontline

Flügel der Sterne
24 StundenBestenliste lesen
- 1 Wie benutze ich Chatgpt mit Siri auf dem iPhone? Siehe einen detaillierten Leitfaden! - Minitool
- 2 Vergleichen von Photoshop -Preisgestaltung: Optionen und Vorteile
- 3
- 4 So machen Sie PHP -Anwendungen schneller
- 5 Microsoft 365 Personal Review und Download Vollversion - Minitool
- 6 Die besten Open World -Spiele auf dem PC - Minitool
- 7 Diablo 4 Erscheinungsdatum, Gameplay und alles, was wir wissen - Minitool
- 8 Windows 11 Installationsassistent nicht öffnet? So reparieren Sie! - Minitool
- 9 Wie überprüfe ich, ob HDR auf Ihrem Windows 11 -PC unterstützt wird? - Minitool
- 10 Windows 11: Sollten Sie für Gaming -PCs ein Upgrade - Minitool
- 11 Was macht Java großartig? Schlüsselmerkmale und Vorteile
- 12 Sagen Sie "Hey Google, öffnen Sie die Assistenteneinstellungen", um Assistenten zu setzen - Minitool
- 13 Beste Epson -Drucker | So verbinden Sie den Epson -Drucker mit WiFi - Minitool
- 14 CSS -IDs gegen Klassen: Die wirklichen Unterschiede
- 15 Laravel -Migrationen erläutert: Erstellen, ändern und verwalten Ihre Datenbank
Neueste Tutorials
![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)
-
- Gehen Sie zur praktischen Anwendung von GraphQL
- 3273 2024-04-19
-
- Erste Schritte mit MySQL (Teacher Mosh)
- 2642 2024-04-07
-
- Mock.js |. Axios.js |. Ajax – Zehn Tage Qualitätsunterricht
- 3329 2024-03-29
In diesem Dokument geht es hauptsächlich um die Verwendung von Apache Spark für die Big-Data-Verarbeitung – Teil 1: Erste Schritte; Apache Spark ist ein Big-Data-Verarbeitungsframework, das auf Geschwindigkeit, Benutzerfreundlichkeit und komplexe Analysen basiert. Es wurde ursprünglich 2009 vom AMPLab der University of California, Berkeley entwickelt und wurde 2010 zu einem der Open-Source-Projekte von Apache.
In diesem ersten Teil der Apache Spark-Artikelreihe erfahren wir, was Spark ist, wie es im Vergleich zu typischen MapReduce-Lösungen abschneidet und wie es einen vollständigen Satz an Tools für die Verarbeitung großer Datenmengen bereitstellt. Ich hoffe, dass dieses Dokument Freunden in Not hilft; interessierte Freunde können vorbeikommen und einen Blick darauf werfen

Verwandte Empfehlungen

Tutorials und Notizen zur Android-Entwicklung als PDF-Version

Unity3d-Spieleentwicklungskamera, die die chinesische WORD-Version umschaltet
CHM-Version der chinesischen API-Sammlung für Android

Lucene-Lernen und Zusammenfassung der chinesischen WORD-Version
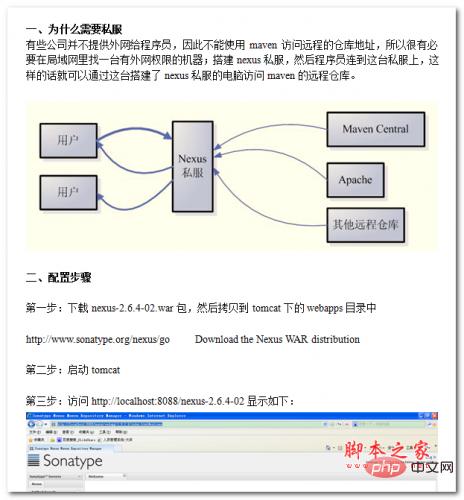
Maven-Serie

Netty-Codeanalyse Chinesische WORD-Version
Problem beim Einrichten der Windows-Thinkpad-Android-Umgebung. Chinesische WORD-Version

Ausführliche Erläuterung der chinesischen WORD-Version des UML-Klassendiagramms


Beliebte Empfehlungen
PHP7.3.8 Offline-Chinesisch-Handbuch (offizielle Version)
PHP7.2 Chinesisches Handbuch
Chinesisches HTML5-Handbuch (CHM-Version)
PHP 5.6 Chinesisches Handbuch
PHP7.2-Handbuch (neueste Version)
HTML-Chinesisch-Handbuch (CHM-Version)
ThinkPHP5.0-Entwicklungshandbuch
JavaScript-Referenzhandbuch