

如何理解 Web 语义化?

回复内容:
什么是语义化?其实简单说来就是让机器可以读懂内容。先随便扯扯。对于当前的 Web 而言,HTML 是联系大多数 Web 资源的纽带,也是内容的载体。在 Web 被刚刚设计出来的时候,Tim Berners-Lee 可能不会想到它现在会达到的规模以及深入到我们生活的那么多方面。也许起初的想法很简单:用来发布 Web 内容和资源的索引,方便人们查看。
但是随着 Web 规模的不断扩大,信息量之大已经不在人肉处理的范围之内了。这个时候人们开始用机器来处理 Web 上发布的各种内容,搜索引擎就诞生了。再后来,人们又设计了各种智能程序来对索引好的内容作各种处理和挖掘。所以让机器能够更好地读懂 Web 上发布的各种内容就变得越来越重要。
其实 HTML 在刚开始设计出来的时候就是带有一定的「语义」的,包括段落、表格、图片、标题等等,但这些更多地只是方便浏览器等 UA 对它们作合适的处理。但逐渐地,机器也要借助 HTML 提供的语义以及自然语言处理的手段来「读懂」它们从网上获取的 HTML 文档,但它们无法读懂例如「红色的文字」或者是深度嵌套的表格布局中内容的含义,因为太多已有的内容都是专门为了可视化的浏览器设计的。面对这种情况,出现了两种观点:
- 我们可以让机器的理解能力越来越接近人类,人能看懂、听懂的东西,机器也能理解;
- 我们应该在发布内容的时候,就用机器可读的、被广泛认可的语义信息来描述内容,来降低机器处理 Web 内容的难度(HTML 本身就已经是朝这个方向迈出的一小步了)。
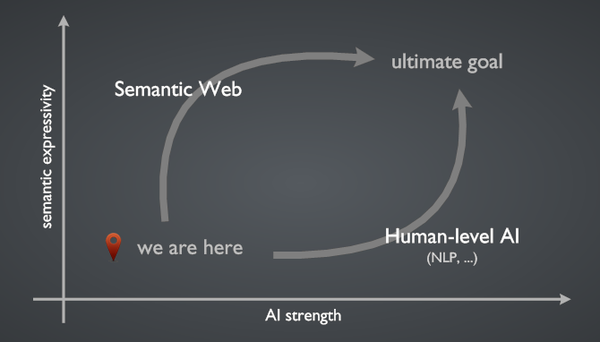
 我画的这个图,意思是说,内容的语义表达能力和 AI 的智能程度决定了机器分析处理 Web 内容能力的高低。上面观点 1 的方向是朝着人类水平的人工智能努力,而观点 2 的方向正是万维网创始人 Tim Berners-Lee 爵士提出的美好愿景:语义网。语义网我就不多说了,简单来说就是让一切内容和包括对关系的描述都成为 Web 上的资源,都可以由唯一的 URI 定义,语义明确、机器可读。显然,两条路都的终极目标都很遥远,第一条路技术上难以实现,而第二条路实施起来障碍太多。
我画的这个图,意思是说,内容的语义表达能力和 AI 的智能程度决定了机器分析处理 Web 内容能力的高低。上面观点 1 的方向是朝着人类水平的人工智能努力,而观点 2 的方向正是万维网创始人 Tim Berners-Lee 爵士提出的美好愿景:语义网。语义网我就不多说了,简单来说就是让一切内容和包括对关系的描述都成为 Web 上的资源,都可以由唯一的 URI 定义,语义明确、机器可读。显然,两条路都的终极目标都很遥远,第一条路技术上难以实现,而第二条路实施起来障碍太多。我认为我们当前能够看得见摸得着的 Web 语义化,其实就是在往第二条路的方向上,迈出的一小步,即对已经有的被广泛认可的 HTML 标准做改进。我们刚开始意识到,我们必须回归内容本身,将内容本身的语义合理地表述出来,再为不同的用户代理设计不同的样式描述,也就是我们说的内容与样式分离。这样我们在提供内容的时候,首先要做的就是将内容本身进行合理的描述,暂时不用考虑它的最终呈现会是什么样子。
HTML 规范其实一直在往语义化的方向上努力,许多元素、属性在设计的时候,就已经考虑了如何让各种用户代理甚至网络爬虫更好地理解 HTML 文档。HTML5 更是在之前规范的基础上,将所有表现层(presentational)的语义描述都进行了修改或者删除,增加了不少可以表达更丰富语义的元素。为什么这样的语义元素是有意义的?因为它们被广泛认可。所谓语义本身就是对符号的一种共识,被认可的程度越高、范围越广,人们就越可以依赖它实现各种各样的功能。
HTML5 并非 Web 语义唯一倚仗的规范,除了 W3C 和 WHATWG 外,还有其它的组织在为扩展、标准化 Web 语义做着贡献。只要有浏览器厂商、搜索引擎原意支持,它们的规范一样可以成为通用的基础设施。例如 microformats 社区以及 http://Schema.org 上都有对 HTML 以及 Microdata(http://www.w3.org/TR/html5/microdata.html) 规范的扩展词汇表,Google、Bing、Yahoo! 等搜索引擎以及各个主流浏览器都不同程度地接纳了其中定义的语义扩展,并应用在了生产中。
下面举两个 Google 应用扩展语义的例子。
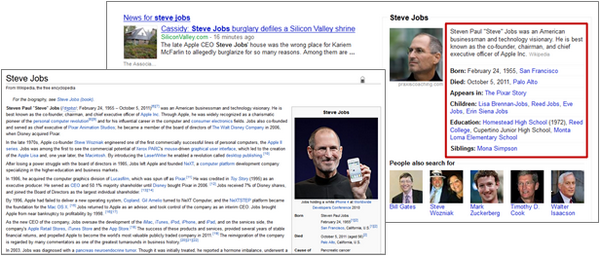
Google 的搜索结果,可以根据 microformats 的 hCard 语法从抓取的页面识别出人物信息:
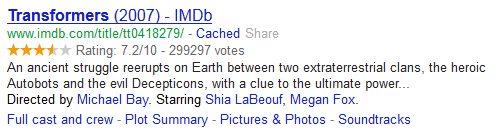
也可通过网页内嵌的 Microdata 数据读取作品评分等信息:
 关于 HTML5 的各个元素语义的描述,我之前做过一份 slides,上面提到的例子都是那里面的,也可以参考一下:Semantic HTML(http://justineo.github.com/slideshows/semantic-html/)。
首先需要注意,本人回答一向漏洞百出,请意会。
关于 HTML5 的各个元素语义的描述,我之前做过一份 slides,上面提到的例子都是那里面的,也可以参考一下:Semantic HTML(http://justineo.github.com/slideshows/semantic-html/)。
首先需要注意,本人回答一向漏洞百出,请意会。语义网是让机器可以理解数据。语义网技术,它包括一套描述语言和推理逻辑。它包通过一些格式对本体(Ontology)进行描述。如W3C的 RDF就是这样一种描述规范,它描述这些数据所表达的含义还有这些词之间可能产生的关系(动词?),那么计算机就可以通过查询(推理规则)来产生我们需要的数据视图了。也就是说如果你对计算机提问,因为计算机理解数据,所以可以推理出你所想要的答案,即使这个答案不是预先准备好的。大部分的语义网的表示规范都基于XML,因为它是一种完备的通用描述语言。
HTML选择文本协议是因为文本协议便于人类与计算机阅读。其实要注意一个重要的历史细节,是email激发并帮助产生了互联网技术。email相关的第一个RFC(RFC 561)在1973年就有了,而TBL大神在1989年提出超链接技术才标志着WWW的产生。
使用文本协议是因为原先传递消息不是为了让计算机存储和理解的。最早的email就和我们现在的短信的想法差不多,两个计算机同时在线用modem传递一些文本信息给使用计算机的人去读,这个时候的文本信息没有链接(没有链接就不是网),纯粹就是文本块。
而后来为了让email里面能保存非文本的数据,并且不破坏原来的协议兼容性,所以催生了非常非常重要的MIME协议(Multipurpose Internet Mail Extensions)。
因为有了email的协议族(包括传输协议和MIME)以后,在计算机之间通过纯文本消息体已经可以交换各种数据了。但是这个时候传递的只是数据,数据之间是没有关系的。
Hypertext是在文本协议上面扩展了表示文档关系(超链接)的能力,它就让原先的文本变成了网络(关系)。这种文本表述协议HTML的第一个RFC是1995年的RFC 1866。而我们可爱的HTTP在1996年才有了HTTP 1.0(RFC 1945)。
你基本上可以按照RFC来排这些技术的辈份……
强调这个历史是想说明计算机可理解不是这组协议的目的,因为计算机可以解析二进制,用二进制更高效(传输和解析)。这些协议最早是为了人类可读而设计的,所以都基于对计算机不那么有好的文本协议。文本协议人类调试起来会高效很多。
那么这和语义网有什么关系呢?
因为HTML不是为了计算机可读而优化,所以HTML的解析实际上是一个比较头疼的地方,这个是所有写过HTML解析器的朋友都知道的。HTML很多时候真的是一锅粥,模糊的语义很多时候靠猜。
所以,有了著名XHTML,它的目的是让HTML套上XML的外衣。XML是啥呢?XML的最初目的就是设计一种计算机和人类都可读的协议,由于人也就能读文本,所以它是一种文本描述语言。让HTML符合XML的规范就计算机(机器人)和人类都皆大欢喜了。而后有了XHTML 1.0,当时的“网站重构”活动所有经历过那个时代的朋友都亲身体会到了。多了一些强制的写法,写XHMTL解析器的朋友们就不用哭泣了。不过后来大家发现写XHTML的朋友经常会有语法错误,另外一些朋友则对HTML 4.x灵活(模糊)的语法恋恋不忘。
由于还是有很多朋友发现XHTML让计算机真的跟容易理解文本的结构,所以那些人继续狂热的做XHMTL 2.0,但是这是个不归路。而且对于消费HTML的大部分人类来说这都没有爱,所以最后这个标准被抛弃了。
人类理解文本字面以外更重要的是把这些概念抽出来理解,人类需要知道文档的结构是什么。研究协议的人们都是高端人才,天天写paper……(我这个是纯演绎)所以他们觉得应该让HTML能够很好的展现他们的写的字(文本)的这种章回的结构,所以就把文档的结构的隐喻放在了HTML的文档模型(BOM和DOM)上面,所以HTML协议里面是包括tag和tag所表述的文档中的隐喻的定义的,这样人类阅读这些文本的时候就把文本和一个文档(某个paper)的结构映射出来了,那么浏览器就可以把他渲染的让这些标准制定者高兴了。
但是后来大家发现光有文档没有索引不行,所以搜索引擎越来越重要。可是搜索引擎不是都像Yahoo那样是人肉编辑的,后来的主流搜索引擎都是基于对查询文本和网络上的文本的相关度进行搜索的。但是网络上的文本要取下来并按照文档结构解析是需要机器人(爬虫)的。所以机器人读网页的权利被越来越多的重视起来,那些搜索引擎优化不就是想骗过这些机器人的算法么。
当然这里又回到一开始的语义网了,因为人们的查询不光是字面匹配,人们希望使用更聪明的搜索引擎。那么搜索引擎应该知道用户的意图,这不是什么人工智能,而是一些基于统计的算法。但是这些算法都和语义网中的一些东西有相关性,因为人们需要得到数据,并且找到这些数据的本体,通过一些预先定义好的本体之间的关系进行逻辑推演(目前都是写死的算法,而没有使用语义网里面的推演系统)。也就是说这个模型从概念上和语义网相似,但是由于技术上还不太可行,所以走了其它的路。不过从理解文本的这个地方来说,所有的现代搜索引擎都有这方面的逻辑。它希望把搜集到的文本描述成一种可以推演的数据,在语义网里面描述这些数据的方式之一是RDF。RDF基于XML,而HTML中的XHTML是一种XML。通过HTML的attribute储存语义网数据叫RDFa(Resource Description Framework – in – attributes),这就把HTML/XHTML和语义网技术拉到了一起,当然光表示数据只是语义网的一部分。
和RDFa相似的东西还有microformats(老早我就力挺microformats,不过后来这东西被好多人断言说已经死了,还好后来micro-data火起来了),它把语义数据放在node text或者属性里面,并且通过css class来表达数据结构。但是他们只表示了结构,我们还没法映射到本体。那么Microdata就是这样的尝试,它定义了一些词汇表,表达某一些常见的格式,通过这些词汇表就对应到了数据的本体。
到这里这个圈子就转好了。语义化需要让数据和表述的本体的映射成为可能,那么结构首先要可以表达出来,并且通过一些结构的约定俗成(或者直接声明)让计算机可以找到这些结构的本体,然后计算机就可以通过本体的关系来进行逻辑演绎。目前我们能真的达到约定俗称的东西还很少,大家看看micro data。但是先不要说终极理想,也就是让我们的大网成为语义网。我们目前可用的技术里面应该充分的考虑到可怜的机器人非常弱的理解能力,尽量说一些约定俗称的东西,这样机器人就可以帮我们进行一些我们人类不太擅长但是它很擅长的推理计算了。那么最好我们能够让我们的文档在描述相关的本体的时候使用计算机更容易理解的结构,这就是语义化。也就是说用某一种模式来表达计算机可以理解的词汇,这就是HTML的语义化。
当然现在又一个巨大的问题,那就是HTML的文档模型和我们平常要表达的映射直接没有隐喻的关系,而且这个差距是巨大的。我们开发Web Application无处不受这种限制的影响,所以性急的人们才把HTML5变成一个永远演化的协议,来保证我们更及时的把我们想要的一些新的结构、语义加入到HTML这个文本描述协议里面。
那么最后强调一下,语义化真的不是为了我们人类。语义化是我们人类博爱的体现,我们也要照顾可怜的机器人,让他们能够很好的通过自描述的结构逐渐掌握我们人类的词汇,理解我们人来在说什么,这样它就可以更好的为我们服务。语义化真的是Web开发人员表现出来的可贵的人性!
相关词条链接:
- [Semantic Web](http://en.wikipedia.org/wiki/Semantic_Web)
- [Email](http://en.wikipedia.org/wiki/Email)
- [World Wide Web](http://en.wikipedia.org/wiki/World_Wide_Web)
- [HTML](http://en.wikipedia.org/wiki/HTML)
- [Hypertext Transfer Protocol](http://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol)
- [XML](http://en.wikipedia.org/wiki/XML)
- [RDFa](http://en.wikipedia.org/wiki/RDFa)
- [XHTML+RDFa](http://en.wikipedia.org/wiki/XHTML%2BRDFa)
- [Microdata (HTML)](http://en.wikipedia.org/wiki/Microdata_(HTML))
- [Microformat](http://en.wikipedia.org/wiki/Microformat)
1、浏览器和W3C组织推出的如h1~h6、thead、ul、ol的HTML标签,用于在Web页面中组织对应的内容,如网页标题、表头、无序、有序列表,以达到更方便的协作及传播互联网内容。搜索引擎很好的利用了这些语义化标签抓取内容,又鉴于搜索引擎的巨大流量推荐,Web前端不得不考虑SEO,从而两者实现有益的循环,共同推进着语义化标签的使用。
2、但Web的发展超乎想象,起初定义的HTML语义化标签,不足以实现对Web页面各个部分的功能或位置描述,所以Web前端人员利用HTML标签的id和class属性,进一步对HTML标签进行描述,如对页脚HTML标签添加如id="footer"或者class="footer"的属性(值),以“无声”的方式在不同的前端程序员或者前后端程序员间实现交流。
3、W3C组织意识到了之前HTML版本的不足,推出的HTML5进一步推进了Web语义化发展,采用了诸如footer、section等语义化标签,弥补了采用id="footer"或者class="footer"形式的不足,以更好的推动Web的发展。 说一下个人的愚见:所谓 web 语义化,从广义上来说,不仅要使机器(搜索引擎等)易于理解,也要使人易于理解。在团队协作开发中,对人的易于理解显得尤为重要了,一个莫名其妙的 class 会让后续的开发或者维护者一头雾水,增加了协作成本。 具体来说,就是在书写html时,尽量使用具有语义信息的标签,例如header,nav,aside,section等代替那些没有语义信息的标签,例如big,center,strike,font等(完全可以用css来取代的标签)。这样不仅有利于页面DOM的组织,也有利于机器(主要是搜索引擎)的理解。
而语义网的目标就是为了使得网络上的信息更加容易被机器理解和查找,从而提升人类使用网络获取信息的体验。
也可以:google "semantic web" 这个问题让我想起了大三时做的一个search
也来说说几句吧,
我所理解的web语义化是互联网信息处理的自动化、智能化。
LBS,Apple Siri,搜索引擎,数字图书馆,车载导航,其实都可以理解为web语义化。
只是程度的深和浅而已。
当时我做search的时候,应该是08,09年的时候,国内对于web语义化的研究还处于体系结构上的研究,对应用层面的研究还是相对较少。
那个时候,国内对于语义网的相关概念:本体,资源描述框架,Web2.0,数据挖掘,xml,描述逻辑,智能化,知识地图,语义检索,数字图书馆....不断的在陌生中熟悉着...那个时候听得最多的就是web2.0
11年,12年,Apple Siri的现身,LBS,百度框,地图导航....可以看到,目前web语义化已经在朝着应用层面走去。
(我会认为,基于用户社交关系的内容传播也是一种web语义化...包括根据标签对用户进行描述,获取用户属性然后进行分析,地理位置信息推送,浏览信息智能排序——热度啊/感兴趣啊....)
附上:
1.语义网通过扩展现有的互联网,在信息中加入表示其含义的内容,使计算机可以自动与人协同工作。也就是说,语义网中的各种资源不再只是各种相连的信息,还包括其信息的真正含义,从而提高计算机处理信息的自动化和智能化。当然,计算机并不具有真正的智能,语义网的建立需要研究者们对信息进行有效的表示,制定统一的标准,使计算机可以对信息进行有效的自动处理。
(来源:何斌 张立厚《信息管理原理与方法》 清华大学出版社 2007年7月第二版)
2.语义网体系结构

第一层:Unicode与URI,是整个体系结构的基础。
第二层:XML+NS+XMLSchema,负责语法上表示数据的内容和结构,通过使用标准的格式语言将网络信息的表现形式、数据结构和内容分离。
第三层:RDF+RDF Schema,它提供语义模型用于描述网上的信息和类型。其中,RDF(Resource Description Framework),即资源描述框架,是W3C推荐的用来描述WWW上的信息资源及其之间关系的语言规范。RDF(S)是语义网的重要组成部分,它使用URI来标识不同的对象(包括资源节点、属性类或属性值)并可将不同的URI连接起来,清楚表达对象间的关系。
第四层:本体词汇层,本体是关于领域知识的概念化、形式化的明确规范。在语义网体系结构中,本体的作用主要表现在:(1).概念描述,即通过概念描述揭示领域知识;(2).语义揭示,本体具有比RDF更强的表达能力,可以揭示更为丰富的语义关系;(3).一致性,本体作为领域知识的明确规范,可以保证语义的一致性,从而彻底解决一词多义、多词一义和词义含糊现象;(4). 推理支持,本体在概念描述上的确定性及其强大的语义揭示能力在数据层面有力地保证了推理的有效性。
第五层:逻辑层,负责提供公理和推理原则,为智能服务提供基础。其中,描述逻辑(DescriptionLogic)是基于对象的知识表示的形式化,它吸取了KL-ONE的主要思想,是一阶谓词逻辑的一个可判定子集。它与一阶谓词逻辑不同的是,描述逻辑系统能提供可判定的推理服务。除了知识表示以外,描述逻辑还用在其它许多领域,它被认为是以对象为中心的表示语言的最为重要的归一形式。描述逻辑的重要特征是很强的表达能力和可判定性,它能保证推理算法总能停止,并返回正确的结果。在众多知识表示的形式化方法中,描述逻辑在十多年来受到人们的特别关注,主要原因在于:它们有清晰的模型-理论机制;很适合于通过概念分类学来表示应用领域;并提供了很用的推理服务。
第六层证明层和第七层信任层负责提供认证和信任机制。 语义化的html标签是一种元数据,用来描述其包裹的内容。
从这个角度来说语义化更具体的描述了作者对被显示数据的理解。这样看不管是人和机器都可以在既定的规范中理解作者的意图,以便更好的维护和使用数据。 学术届将其称为Web3.0的核心,目标是将当前的网页提升为计算机能够“理解”和处理的网页。 核心思想是标注网页对象使其对应本体中的实体,并通过逻辑等手段进行自动推理。 作用在于更好整合网络上的资源,使计算机能够处理分布于不同位置的信息,自动产生问题的解决方案。 就是人告诉机器 我所理解的web语义化就是一句话:“标题就是标题,段落就是段落...”。
其实 html 文档和 word 文档本质上没什么区别,只不过是 html 可以使用 css/js 为其附加样式和交互,并且能够在互联网上快速传播而已。所以在写 html 的时候也要像写 word 文档一样,标题就是标题,段落就是段落,图片就是图片,列表就是列表,表格就是表格,不要啥都用 div、span 这种什么都是又什么都不是的无语义的标签来描述。看一张网页是否符合语义化,只要把它所有的 css 文件都拿掉后是否还能结构分明、阅读顺畅。
当然这还只是 html 标记的语义化, @斯迪 也提到了css的ID、class名同样也应该具有语义化。同时语义化还有从抽象到具体的概念,比如:内容>列表>有序列表>排行榜,html只能描述到抽象的语义,具体的语义就需要 css 的ID、class名去补充了。
个人观点,欢迎拍砖~

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to Add Audio to My HTML5 Website?
Mar 10, 2025 pm 03:01 PM
How to Add Audio to My HTML5 Website?
Mar 10, 2025 pm 03:01 PM
This article explains how to embed audio in HTML5 using the <audio> element, including best practices for format selection (MP3, Ogg Vorbis), file optimization, and JavaScript control for playback. It emphasizes using multiple audio f
 How do I handle user location privacy and permissions with the Geolocation API?
Mar 18, 2025 pm 02:16 PM
How do I handle user location privacy and permissions with the Geolocation API?
Mar 18, 2025 pm 02:16 PM
The article discusses managing user location privacy and permissions using the Geolocation API, emphasizing best practices for requesting permissions, ensuring data security, and complying with privacy laws.
 How to Use HTML5 Forms for User Input?
Mar 10, 2025 pm 02:59 PM
How to Use HTML5 Forms for User Input?
Mar 10, 2025 pm 02:59 PM
This article explains how to create and validate HTML5 forms. It details the <form> element, input types (text, email, number, etc.), and attributes (required, pattern, min, max). The advantages of HTML5 forms over older methods, incl
 How do I use the HTML5 Page Visibility API to detect when a page is visible?
Mar 13, 2025 pm 07:51 PM
How do I use the HTML5 Page Visibility API to detect when a page is visible?
Mar 13, 2025 pm 07:51 PM
The article discusses using the HTML5 Page Visibility API to detect page visibility, improve user experience, and optimize resource usage. Key aspects include pausing media, reducing CPU load, and managing analytics based on visibility changes.
 How do I use viewport meta tags to control page scaling on mobile devices?
Mar 13, 2025 pm 08:00 PM
How do I use viewport meta tags to control page scaling on mobile devices?
Mar 13, 2025 pm 08:00 PM
The article discusses using viewport meta tags to control page scaling on mobile devices, focusing on settings like width and initial-scale for optimal responsiveness and performance.Character count: 159
 How to Create Interactive Games with HTML5 and JavaScript?
Mar 10, 2025 pm 06:34 PM
How to Create Interactive Games with HTML5 and JavaScript?
Mar 10, 2025 pm 06:34 PM
This article details creating interactive HTML5 games using JavaScript. It covers game design, HTML structure, CSS styling, JavaScript logic (including event handling and animation), and audio integration. Essential JavaScript libraries (Phaser, Pi
 How do I use the HTML5 Drag and Drop API for interactive user interfaces?
Mar 18, 2025 pm 02:17 PM
How do I use the HTML5 Drag and Drop API for interactive user interfaces?
Mar 18, 2025 pm 02:17 PM
The article explains how to use the HTML5 Drag and Drop API to create interactive user interfaces, detailing steps to make elements draggable, handle key events, and enhance user experience with custom feedback. It also discusses common pitfalls to a
 How do I use the HTML5 WebSockets API for bidirectional communication between client and server?
Mar 12, 2025 pm 03:20 PM
How do I use the HTML5 WebSockets API for bidirectional communication between client and server?
Mar 12, 2025 pm 03:20 PM
This article explains the HTML5 WebSockets API for real-time, bidirectional client-server communication. It details client-side (JavaScript) and server-side (Python/Flask) implementations, addressing challenges like scalability, state management, an
