

hive分区(partition)简介

网上有篇关于hive的partition的使用讲解的比较好,转载了: 一、背景 1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。 2、分区表指的是在创建表时指定
网上有篇关于hive的partition的使用讲解的比较好,转载了:
一、背景
1、在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。
2、分区表指的是在创建表时指定的partition的分区空间。
3、如果需要创建有分区的表,需要在create表的时候调用可选参数partitioned by,详见表创建的语法结构。
二、技术细节
1、一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。
2、表和列名不区分大小写。
3、分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
4、建表的语法(建分区可参见PARTITIONED BY参数):
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_comment], ...)] [COMMENT table_comment] [PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] [CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] [ROW FORMAT row_format] [STORED AS file_format] [LOCATION hdfs_path]
5、分区建表分为2种,一种是单分区,也就是说在表文件夹目录下只有一级文件夹目录。另外一种是多分区,表文件夹下出现多文件夹嵌套模式。
a、单分区建表语句:create table day_table (id int, content string) partitioned by (dt string);单分区表,按天分区,在表结构中存在id,content,dt三列。
b、双分区建表语句:create table day_hour_table (id int, content string) partitioned by (dt string, hour string);双分区表,按天和小时分区,在表结构中新增加了dt和hour两列。
表文件夹目录示意图(多分区表):
6、添加分区表语法(表已创建,在此基础上添加分区):
ALTER TABLE table_name ADD partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ... partition_spec: : PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)
用户可以用 ALTER TABLE ADD PARTITION 来向一个表中增加分区。当分区名是字符串时加引号。例:
ALTER TABLE day_table ADD PARTITION (dt='2008-08-08', hour='08') location '/path/pv1.txt' PARTITION (dt='2008-08-08', hour='09') location '/path/pv2.txt';
7、删除分区语法:
ALTER TABLE table_name DROP partition_spec, partition_spec,...
用户可以用 ALTER TABLE DROP PARTITION 来删除分区。分区的元数据和数据将被一并删除。例:
ALTER TABLE day_hour_table DROP PARTITION (dt='2008-08-08', hour='09');
8、数据加载进分区表中语法:
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
例:
LOAD DATA INPATH '/user/pv.txt' INTO TABLE day_hour_table PARTITION(dt='2008-08- 08', hour='08'); LOAD DATA local INPATH '/user/hua/*' INTO TABLE day_hour partition(dt='2010-07- 07');
当数据被加载至表中时,不会对数据进行任何转换。Load操作只是将数据复制至Hive表对应的位置。数据加载时在表下自动创建一个目录,文件存放在该分区下。
9、基于分区的查询的语句:
SELECT day_table.* FROM day_table WHERE day_table.dt>= '2008-08-08';
10、查看分区语句:
hive> show partitions day_hour_table; OK dt=2008-08-08/hour=08 dt=2008-08-08/hour=09 dt=2008-08-09/hour=09
三、总结
1、在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在最字集的目录中。
2、总的说来partition就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
——————————————————————————————————————
hive中关于partition的操作:
hive> create table mp (a string) partitioned by (b string, c string);
OK
Time taken: 0.044 seconds
hive> alter table mp add partition (b='1', c='1');
OK
Time taken: 0.079 seconds
hive> alter table mp add partition (b='1', c='2');
OK
Time taken: 0.052 seconds
hive> alter table mp add partition (b='2', c='2');
OK
Time taken: 0.056 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.046 seconds
hive> explain extended alter table mp drop partition (b='1');
OK
ABSTRACT SYNTAX TREE:
(TOK_ALTERTABLE_DROPPARTS mp (TOK_PARTSPEC (TOK_PARTVAL b '1')))
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Drop Table Operator:
Drop Table
table: mp
Time taken: 0.048 seconds
hive> alter table mp drop partition (b='1');
FAILED: Error in metadata: table is partitioned but partition spec is not specified or tab: {b=1}
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=2/c=2
Time taken: 0.044 seconds
hive> alter table mp add partition ( b='1', c = '3') partition ( b='1' , c='4');
OK
Time taken: 0.168 seconds
hive> show partitions mp ;
OK
b=1/c=1
b=1/c=2
b=1/c=3
b=1/c=4
b=2/c=2
b=2/c=3
Time taken: 0.066 seconds
hive>insert overwrite table mp partition (b='1', c='1') select cnt from tmp_et3 ;
hive>alter table mp add columns (newcol string);
location指定目录结构
hive> alter table alter2 add partition (insertdate='2008-01-01') location '2008/01/01';
hive> alter table alter2 add partition (insertdate='2008-01-02') location '2008/01/02';

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1393
1393
 52
1206
24
52
1206
24

![[Linux system] fdisk related partition commands.](https://img.php.cn/upload/article/000/887/227/170833682614236.jpg?x-oss-process=image/resize,m_fill,h_207,w_330) [Linux system] fdisk related partition commands.
Feb 19, 2024 pm 06:00 PM
[Linux system] fdisk related partition commands.
Feb 19, 2024 pm 06:00 PM
fdisk is a commonly used Linux command line tool used to create, manage and modify disk partitions. The following are some commonly used fdisk commands: Display disk partition information: fdisk-l This command will display the partition information of all disks in the system. Select the disk you want to operate: fdisk/dev/sdX Replace /dev/sdX with the actual disk device name you want to operate, such as /dev/sda. Create new partition:nThis will guide you to create a new partition. Follow the prompts to enter the partition type, starting sector, size and other information. Delete Partition:d This will guide you to select the partition you want to delete. Follow the prompts to select the partition number to be deleted. Modify Partition Type: This will guide you to select the partition you want to modify the type of. According to mention
 Solution to the problem of unable to partition after win10 installation
Jan 02, 2024 am 09:17 AM
Solution to the problem of unable to partition after win10 installation
Jan 02, 2024 am 09:17 AM
When we reinstalled the win10 operating system, when it came to the disk partitioning step, we found that the system prompted that a new partition could not be created and the existing partition could not be found. In this case, I think you can try to reformat the entire hard disk and reinstall the system to partition, or reinstall the system through software, etc. Let’s see how the editor did it for the specific content~ I hope it can help you. What to do if you cannot create a new partition after installing win10. Method 1: Format the entire hard disk and repartition it or try plugging and unplugging the USB flash drive several times and refreshing it. If there is no important data on your hard disk, when it comes to the partitioning step, delete all the data on the hard disk. Partitions are deleted. Reformat the entire hard drive, then repartition it, and then install it normally. Method 2: P
 Detailed explanation of how to set up Linux Opt partition
Mar 20, 2024 am 11:30 AM
Detailed explanation of how to set up Linux Opt partition
Mar 20, 2024 am 11:30 AM
How to set up the Linux Opt partition and code examples In Linux systems, the Opt partition is usually used to store optional software packages and application data. Properly setting the Opt partition can effectively manage system resources and avoid problems such as insufficient disk space. This article will detail how to set up a LinuxOpt partition and provide specific code examples. 1. Determine the partition space size. First, we need to determine the space size required for the Opt partition. It is generally recommended to set the size of the Opt partition to 5%-1 of the total system space.
 Python ORM Performance Benchmark: Comparing Different ORM Frameworks
Mar 18, 2024 am 09:10 AM
Python ORM Performance Benchmark: Comparing Different ORM Frameworks
Mar 18, 2024 am 09:10 AM
Object-relational mapping (ORM) frameworks play a vital role in python development, they simplify data access and management by building a bridge between object and relational databases. In order to evaluate the performance of different ORM frameworks, this article will benchmark against the following popular frameworks: sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM Test Method The benchmarking uses a SQLite database containing 1 million records. The test performed the following operations on the database: Insert: Insert 10,000 new records into the table Read: Read all records in the table Update: Update a single field for all records in the table Delete: Delete all records in the table Each operation
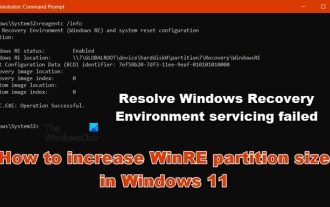 How to increase WinRE partition size in Windows 11
Feb 19, 2024 pm 06:06 PM
How to increase WinRE partition size in Windows 11
Feb 19, 2024 pm 06:06 PM
In this article, we will show you how to change or increase WinRE partition size in Windows 11/10. Microsoft will now update Windows Recovery Environment (WinRE) alongside monthly cumulative updates, starting with Windows 11 version 22H2. However, not all computers have a recovery partition large enough to accommodate the new updates, which can cause error messages to appear. Windows Recovery Environment Service Failed How to Increase WinRE Partition Size in Windows 11 To increase WinRE partition size manually on your computer, follow the steps mentioned below. Check and disable WinRE Shrink OS partition Create new recovery partition Confirm partition and enable WinRE
 Deepin Linux hard disk partitioning and installation tutorial: step by step to achieve efficient system deployment
Feb 10, 2024 pm 07:06 PM
Deepin Linux hard disk partitioning and installation tutorial: step by step to achieve efficient system deployment
Feb 10, 2024 pm 07:06 PM
Before installing Deepin Linux, we need to partition the hard disk. Hard disk partitioning is the process of dividing a physical hard disk into multiple logical areas. Each area can be used and managed independently. The correct partitioning method can improve the performance and performance of the system. Stability, so this step is very important. This article will provide you with detailed and in-depth Linux hard disk partitioning and installation tutorials. Preparation 1. Make sure you have backed up important data, as the partitioning process will erase all data on the hard drive. 2. Prepare a Deepin Linux installation media, such as a USB flash drive or CD. Hard disk partition 1. Boot into the BIOS settings and set the boot media as the preferred boot device. 2. Restart the computer and boot from the boot media to enter the system installation interface. 3.Select
 Application of Python ORM in big data projects
Mar 18, 2024 am 09:19 AM
Application of Python ORM in big data projects
Mar 18, 2024 am 09:19 AM
Object-relational mapping (ORM) is a programming technology that allows developers to use object programming languages to manipulate databases without writing SQL queries directly. ORM tools in python (such as SQLAlchemy, Peewee, and DjangoORM) simplify database interaction for big data projects. Advantages Code Simplicity: ORM eliminates the need to write lengthy SQL queries, which improves code simplicity and readability. Data abstraction: ORM provides an abstraction layer that isolates application code from database implementation details, improving flexibility. Performance optimization: ORMs often use caching and batch operations to optimize database queries, thereby improving performance. Portability: ORM allows developers to
 How to partition hard disk in Win11? Tutorial on how to partition the hard disk in win11 disk
Feb 19, 2024 pm 06:01 PM
How to partition hard disk in Win11? Tutorial on how to partition the hard disk in win11 disk
Feb 19, 2024 pm 06:01 PM
Many users feel that the default partition space of the system is too small, so how to partition the hard disk in Win11? Users can directly click on the management under this computer, and then click on the disk management to perform operation settings. Let this site give users a detailed tutorial on how to partition a hard drive in Win11. Tutorial on how to partition a hard disk in win11 1. First, right-click this computer and open Computer Management. 3. Then check the disk status on the right to see if there is available space. (If there is free space, skip to step 6). 5. Then select the amount of space you need to free up and click Compress. 7. Enter the desired simple volume size and click Next. 9. Finally, click Finish to create a new partition.
