

手动安装cloudera cdh4.2 hadoop + hbase + hive(一)

安装版本 hadoop-2.0.0-cdh4.2.0hbase-0.94.2-cdh4.2.0hive-0.10.0-cdh4.2.0jdk1.6.0_38 安装前说明 安装目录为/opt 检查hosts文件 关闭防火墙 设置时钟同步 使用说明 安装hadoop、hbase、hive成功之后启动方式为: 启动dfs和mapreduce desktop1上执行start-
安装版本
<code>hadoop-2.0.0-cdh4.2.0 hbase-0.94.2-cdh4.2.0 hive-0.10.0-cdh4.2.0 jdk1.6.0_38 </code>
安装前说明
- 安装目录为/opt
- 检查hosts文件
- 关闭防火墙
- 设置时钟同步
使用说明
安装hadoop、hbase、hive成功之后启动方式为:
- 启动dfs和mapreduce desktop1上执行start-dfs.sh和start-yarn.sh
- 启动hbase desktop3上执行start-hbase.xml
- 启动hive desktop1上执行hive
规划
<code> 192.168.0.1 NameNode、Hive、ResourceManager
192.168.0.2 SSNameNode
192.168.0.3 DataNode、HBase、NodeManager
192.168.0.4 DataNode、HBase、NodeManager
192.168.0.6 DataNode、HBase、NodeManager
192.168.0.7 DataNode、HBase、NodeManager
192.168.0.8 DataNode、HBase、NodeManager
</code>部署过程
系统和网络配置
-
修改每台机器的名称
[root@desktop1 ~]# cat /etc/sysconfig/network NETWORKING=yes HOSTNAME=desktop1
Copy after login -
在各个节点上修改/etc/hosts增加以下内容:
[root@desktop1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.0.1 desktop1 192.168.0.2 desktop2 192.168.0.3 desktop3 192.168.0.4 desktop4 192.168.0.6 desktop6 192.168.0.7 desktop7 192.168.0.8 desktop8
Copy after login -
配置ssh无密码登陆 以下是设置desktop1上可以无密码登陆到其他机器上。
[root@desktop1 ~]# ssh-keygen
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop2
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop3
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop4
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop6
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop7
[root@desktop1 ~]# ssh-copy-id -i .ssh/id_rsa.pub desktop8
- 每台机器上关闭防火墙:
<code> [root@desktop1 ~]# service iptables stop </code>
安装Hadoop
配置Hadoop
将jdk1.6.0_38.zip上传到/opt,并解压缩。 将hadoop-2.0.0-cdh4.2.0.zip上传到/opt,并解压缩。
在NameNode上配置以下文件:
<code>core-site.xml fs.defaultFS指定NameNode文件系统,开启回收站功能。
hdfs-site.xml
dfs.namenode.name.dir指定NameNode存储meta和editlog的目录,
dfs.datanode.data.dir指定DataNode存储blocks的目录,
dfs.namenode.secondary.http-address指定Secondary NameNode地址。
开启WebHDFS。
slaves 添加DataNode节点主机
</code>- core-site.xml 该文件指定fs.defaultFS连接desktop1,即NameNode节点。
<code>[root@desktop1 hadoop]# pwd
/opt/hadoop-2.0.0-cdh4.2.0/etc/hadoop
[root@desktop1 hadoop]# cat core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!--fs.default.name for MRV1 ,fs.defaultFS for MRV2(yarn) -->
<property>
<name>fs.defaultFS</name>
<!--这个地方的值要和hdfs-site.xml文件中的dfs.federation.nameservices一致-->
<value>hdfs://desktop1</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<property>
<name>fs.trash.checkpoint.interval</name>
<value>10080</value>
</property>
</configuration>
</code>- hdfs-site.xml 该文件主要设置数据副本保存份数,以及namenode、datanode数据保存路径以及http-address。
<code>[root@desktop1 hadoop]# cat hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop-${user.name}</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>desktop1:50070</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>desktop2:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
</code>- masters 设置namenode和secondary namenode节点。
<code>[root@desktop1 hadoop]# cat masters desktop1 desktop2 </code>
- slaves 设置哪些机器上安装datanode节点。
<code>[root@desktop1 hadoop]# cat slaves desktop3 desktop4 desktop6 desktop7 desktop8 </code>
配置MapReduce
- mapred-site.xml 配置使用yarn计算框架,以及jobhistory的地址。
<code>[root@desktop1 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>desktop1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>desktop1:19888</value> </property> </configuration> </code>
- yarn-site.xml 主要配置resourcemanager地址以及
yarn.application.classpath(这个路径很重要,要不然集成hive时候会提示找不到class)
<code>[root@desktop1 hadoop]# cat yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>desktop1:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>desktop1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>desktop1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>desktop1:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>desktop1:8088</value>
</property>
<property>
<description>Classpath for typical applications.</description>
<name>yarn.application.classpath</name>
<value>$HADOOP_CONF_DIR,$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_HDFS_HOME/share/hadoop/hdfs/*,$HADOOP_HDFS_HOME/share/hadoop/hdfs/lib/*,
$YARN_HOME/share/hadoop/yarn/*,$YARN_HOME/share/hadoop/yarn/lib/*,
$YARN_HOME/share/hadoop/mapreduce/*,$YARN_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce.shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/opt/data/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/opt/data/yarn/logs</value>
</property>
<property>
<description>Where to aggregate logs</description>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/opt/data/yarn/logs</value>
</property>
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
</configuration>
</code>同步配置文件
修改.bashrc环境变量,并将其同步到其他几台机器,并且source .bashrc
<code>[root@desktop1 ~]# cat .bashrc
# .bashrc
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
# User specific environment and startup programs
export LANG=zh_CN.utf8
export JAVA_HOME=/opt/jdk1.6.0_38
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=./:$JAVA_HOME/lib:$JRE_HOME/lib:$JRE_HOME/lib/tools.jar
export HADOOP_HOME=/opt/hadoop-2.0.0-cdh4.2.0
export HIVE_HOME=/opt/hive-0.10.0-cdh4.2.0
export HBASE_HOME=/opt/hbase-0.94.2-cdh4.2.0
export HADOOP_MAPRED_HOME=${HADOOP_HOME}
export HADOOP_COMMON_HOME=${HADOOP_HOME}
export HADOOP_HDFS_HOME=${HADOOP_HOME}
export YARN_HOME=${HADOOP_HOME}
export HADOOP_YARN_HOME=${HADOOP_HOME}
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HDFS_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HBASE_HOME/bin:$HIVE_HOME/bin
</code>修改配置文件之后,使其生效。
<code>[root@desktop1 ~]# source .bashrc </code>
将desktop1上的/opt/hadoop-2.0.0-cdh4.2.0拷贝到其他机器上
启动脚本
第一次启动hadoop需要先格式化NameNode,该操作只做一次。当修改了配置文件时,需要重新格式化
<code>[root@desktop1 hadoop]hadoop namenode -format </code>
在desktop1上启动hdfs:
<code>[root@desktop1 hadoop]#start-dfs.sh </code>
在desktop1上启动mapreduce:
<code>[root@desktop1 hadoop]#start-yarn.sh </code>
在desktop1上启动historyserver:
<code>[root@desktop1 hadoop]#mr-jobhistory-daemon.sh start historyserver </code>
查看MapReduce:
<code>http://desktop1:8088/cluster </code>
查看节点:
<code>http://desktop2:8042/ http://desktop2:8042/node </code>
检查集群进程
<code>[root@desktop1 ~]# jps 5389 NameNode 5980 Jps 5710 ResourceManager 7032 JobHistoryServer [root@desktop2 ~]# jps 3187 Jps 3124 SecondaryNameNode [root@desktop3 ~]# jps 3187 Jps 3124 DataNode 5711 NodeManager</code>

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1391
1391
 52
52

 Solution to the problem that Win11 system cannot install Chinese language pack
Mar 09, 2024 am 09:48 AM
Solution to the problem that Win11 system cannot install Chinese language pack
Mar 09, 2024 am 09:48 AM
Solution to the problem that Win11 system cannot install Chinese language pack With the launch of Windows 11 system, many users began to upgrade their operating system to experience new functions and interfaces. However, some users found that they were unable to install the Chinese language pack after upgrading, which troubled their experience. In this article, we will discuss the reasons why Win11 system cannot install the Chinese language pack and provide some solutions to help users solve this problem. Cause Analysis First, let us analyze the inability of Win11 system to
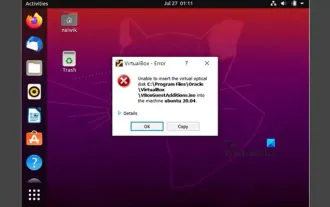 Unable to install guest additions in VirtualBox
Mar 10, 2024 am 09:34 AM
Unable to install guest additions in VirtualBox
Mar 10, 2024 am 09:34 AM
You may not be able to install guest additions to a virtual machine in OracleVirtualBox. When we click on Devices>InstallGuestAdditionsCDImage, it just throws an error as shown below: VirtualBox - Error: Unable to insert virtual disc C: Programming FilesOracleVirtualBoxVBoxGuestAdditions.iso into ubuntu machine In this post we will understand what happens when you What to do when you can't install guest additions in VirtualBox. Unable to install guest additions in VirtualBox If you can't install it in Virtua
 What should I do if Baidu Netdisk is downloaded successfully but cannot be installed?
Mar 13, 2024 pm 10:22 PM
What should I do if Baidu Netdisk is downloaded successfully but cannot be installed?
Mar 13, 2024 pm 10:22 PM
If you have successfully downloaded the installation file of Baidu Netdisk, but cannot install it normally, it may be that there is an error in the integrity of the software file or there is a problem with the residual files and registry entries. Let this site take care of it for users. Let’s introduce the analysis of the problem that Baidu Netdisk is successfully downloaded but cannot be installed. Analysis of the problem that Baidu Netdisk downloaded successfully but could not be installed 1. Check the integrity of the installation file: Make sure that the downloaded installation file is complete and not damaged. You can download it again, or try to download the installation file from another trusted source. 2. Turn off anti-virus software and firewall: Some anti-virus software or firewall programs may prevent the installation program from running properly. Try disabling or exiting the anti-virus software and firewall, then re-run the installation
 How to install Android apps on Linux?
Mar 19, 2024 am 11:15 AM
How to install Android apps on Linux?
Mar 19, 2024 am 11:15 AM
Installing Android applications on Linux has always been a concern for many users. Especially for Linux users who like to use Android applications, it is very important to master how to install Android applications on Linux systems. Although running Android applications directly on Linux is not as simple as on the Android platform, by using emulators or third-party tools, we can still happily enjoy Android applications on Linux. The following will introduce how to install Android applications on Linux systems.
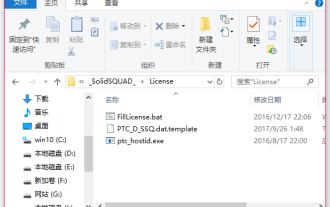 How to install creo-creo installation tutorial
Mar 04, 2024 pm 10:30 PM
How to install creo-creo installation tutorial
Mar 04, 2024 pm 10:30 PM
Many novice friends still don’t know how to install creo, so the editor below brings relevant tutorials on creo installation. Friends in need should take a look at it. I hope it can help you. 1. Open the downloaded installation package and find the License folder, as shown in the figure below: 2. Then copy it to the directory on the C drive, as shown in the figure below: 3. Double-click to enter and see if there is a license file, as shown below As shown in the picture: 4. Then copy the license file to this file, as shown in the following picture: 5. In the PROGRAMFILES file of the C drive, create a new PLC folder, as shown in the following picture: 6. Copy the license file as well Click in, as shown in the figure below: 7. Double-click the installation file of the main program. To install, check the box to install new software.
 How to install Podman on Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
How to install Podman on Ubuntu 24.04
Mar 22, 2024 am 11:26 AM
If you have used Docker, you must understand daemons, containers, and their functions. A daemon is a service that runs in the background when a container is already in use in any system. Podman is a free management tool for managing and creating containers without relying on any daemon such as Docker. Therefore, it has advantages in managing containers without the need for long-term backend services. Additionally, Podman does not require root-level permissions to be used. This guide discusses in detail how to install Podman on Ubuntu24. To update the system, we first need to update the system and open the Terminal shell of Ubuntu24. During both installation and upgrade processes, we need to use the command line. a simple
 How to Install and Run the Ubuntu Notes App on Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
How to Install and Run the Ubuntu Notes App on Ubuntu 24.04
Mar 22, 2024 pm 04:40 PM
While studying in high school, some students take very clear and accurate notes, taking more notes than others in the same class. For some, note-taking is a hobby, while for others, it is a necessity when they easily forget small information about anything important. Microsoft's NTFS application is particularly useful for students who wish to save important notes beyond regular lectures. In this article, we will describe the installation of Ubuntu applications on Ubuntu24. Updating the Ubuntu System Before installing the Ubuntu installer, on Ubuntu24 we need to ensure that the newly configured system has been updated. We can use the most famous "a" in Ubuntu system
 Detailed steps to install Go language on Win7 computer
Mar 27, 2024 pm 02:00 PM
Detailed steps to install Go language on Win7 computer
Mar 27, 2024 pm 02:00 PM
Detailed steps to install Go language on Win7 computer Go (also known as Golang) is an open source programming language developed by Google. It is simple, efficient and has excellent concurrency performance. It is suitable for the development of cloud services, network applications and back-end systems. . Installing the Go language on a Win7 computer allows you to quickly get started with the language and start writing Go programs. The following will introduce in detail the steps to install the Go language on a Win7 computer, and attach specific code examples. Step 1: Download the Go language installation package and visit the Go official website
