

The mode switching included in this article applies to Firefox and other Gecko-based browsers, Safari, Chrome and other Webkit-based browsers, Opera, Konqueror, Internet Explorer for Mac, Internet Explorer for Windows, and embedded IE browser. Avoid mentioning the name of the browser engine and instead mention the name of the most well-known browser using that engine.
This article focuses on the mode selection mechanism rather than documenting the exact behavior of each mode.
Here are the different modes:
The mode selection for text/html content depends on doctype sniffing (discussed later in this article). In IE8, the mode depends on other factors as well. However, by default in IE8, the mode for non-intranet sites that are not on Microsoft's blacklist depends on the document type.
It cannot be overemphasized that the precise behavior of modes differs in each browser, even though it is discussed uniformly in this article.
In Firefox, Safari, Chrome and Opera, the application/xhtml xml HTTP content type (not a meta element nor a doctype!) will trigger XML mode. In XML mode, the browser attempts to give the XML document specification-correct processing to the extent specified in the browser.
IE6, 7 and 8 do not support application/xhtml xml, nor does Mac IE5.
In the Nokia S60 browser based on WebKit, the application/xhtml xml HTTP content type cannot trigger XML mode, because the focus in mobile walled gardens is compatibility with non-standard content. (Older “mobile browsers” cannot use real XML parsers because non-canonical content is tagged as XML.)
Having not tested Konqueror enough, I can't say exactly what will happen in this browser.
Some engines have modes that have nothing to do with web content. For completeness, they are only mentioned here. Opera has a WML2.0 mode. WebKit on Leopard has a specific mode for legacy Dashboard widgets.
Here are the main impacts of these patterns:
The text/html mode mainly affects CSS layout. For example, it's a quirk that tables don't inherit styles. In some browser quirks mode, the box model becomes the IE5.5 box model. This document does not list all layout quirks.
In semi-standard mode (in browsers with this mode), only the height of the table cell containing the image is different from that in standard mode.
In XML mode, selectors have different case-sensitive behavior. Additionally, the specific rules for the HTML body element do not apply to older browsers that do not implement the latest CSS 2.1 changes.
There are also quirks that affect the parsing of HTML and CSS and can cause standards-compliant web pages to be parsed incorrectly. Quirk layout determines whether these quirks are enabled or not. Regardless, it's important to understand the main similarities and differences between Quirks mode and Standards mode in CSS layout and parsing (not HTML parsing).
Some people mistakenly refer to standards mode as "strict parsing mode", which misunderstands the browser's ability to enforce HTML syntax rules and the browser's ability to evaluate markup for correctness. This is not the case. Even when standards mode layout is in effect, browsers still do tag soup (http://en.wikipedia.org/wiki/Tag_soup) correction work. (Before the release of Netscape 6 in 2000, Mozilla did have parsing modes for enforcing HTML syntax rules. These modes were incompatible with existing Web content and were abandoned.)
Another common misconception is about XHTML parsing. It is generally believed that using the XHTML doctype results in different parsing. In fact, this is not the case. XHTML documents with content type text/html use the same parser as HTML documents. Currently all browsers care about is that XHTML with document type text/html is just "tag soup with croutons" (extra slashes everywhere).
Only when documents using XML document type (for example: application/xhtml xml or xmapplication/) will trigger XML mode for parsing, the parser at this time is completely different from the HTML parser.
While Quirks Mode is mostly about CSS, there is also a bit about scripting. For example, in Firefox's quirks mode, the HTML id attribute establishes a global script-scoped object reference just like in IE. The impact of scripting in IE8 deserves more attention than in other browsers.
In XML mode, the behavior of some DOM APIs is completely different, because the behavior of XML's DOM API is not compatible with the behavior of HTML when it is defined.
Modern browsers use doctype sniffing to determine the engine mode of text/html documents. This means that the choice of mode is based on the document type declaration (or lack thereof) at the beginning of the HTML document. (This does not apply to documents using the XML document type.)
The document type declaration (doctype) is a grammatical forgery of SGML. SGML is an old-style markup framework, and HTML before HTML5 was defined based on it. In the HTML4.01 specification, the document type declaration describes the version information of HTML. Despite the name "Document Type Declaration" and the HTML 4.01 specification describing "version information", a Document Type Declaration does not classify an SGML or XML document as a specific type of document, even if it looks like it (because of the name) . (More in the appendix)
Neither the HTML4.01 specification nor ISO 8879 (SGML) say anything about using document type declarations as engine mode conversions. Doctype sniffing is based on the observation that at the time doctype sniffing was designed, the vast majority of quirky documents had neither a document type declaration nor a reference to an older DTD. HTML5 accepts this fact and defines the doctype in text/html as the only mode conversion.
A typical pre-HTML5 document type declaration contains (separated by whitespace) the "". The document type declaration is placed before the opening tag of the document's root element.
Here is a simple guide on how to choose a doctype when creating a new text/html document:
I do not recommend any XHTML doctype because XHTML used as text/html is considered harmful . Regardless, if you choose to use the XHTML doctype, be aware that XML declarations will trigger quirks mode in IE6 (but not IE7!).
A simple guideline for application/xhtml xml is to never use doctype. Web pages in this manner are not "strictly consistent" with XHMTL 1.0, but that doesn't matter. (Please see the Appendix at the back)
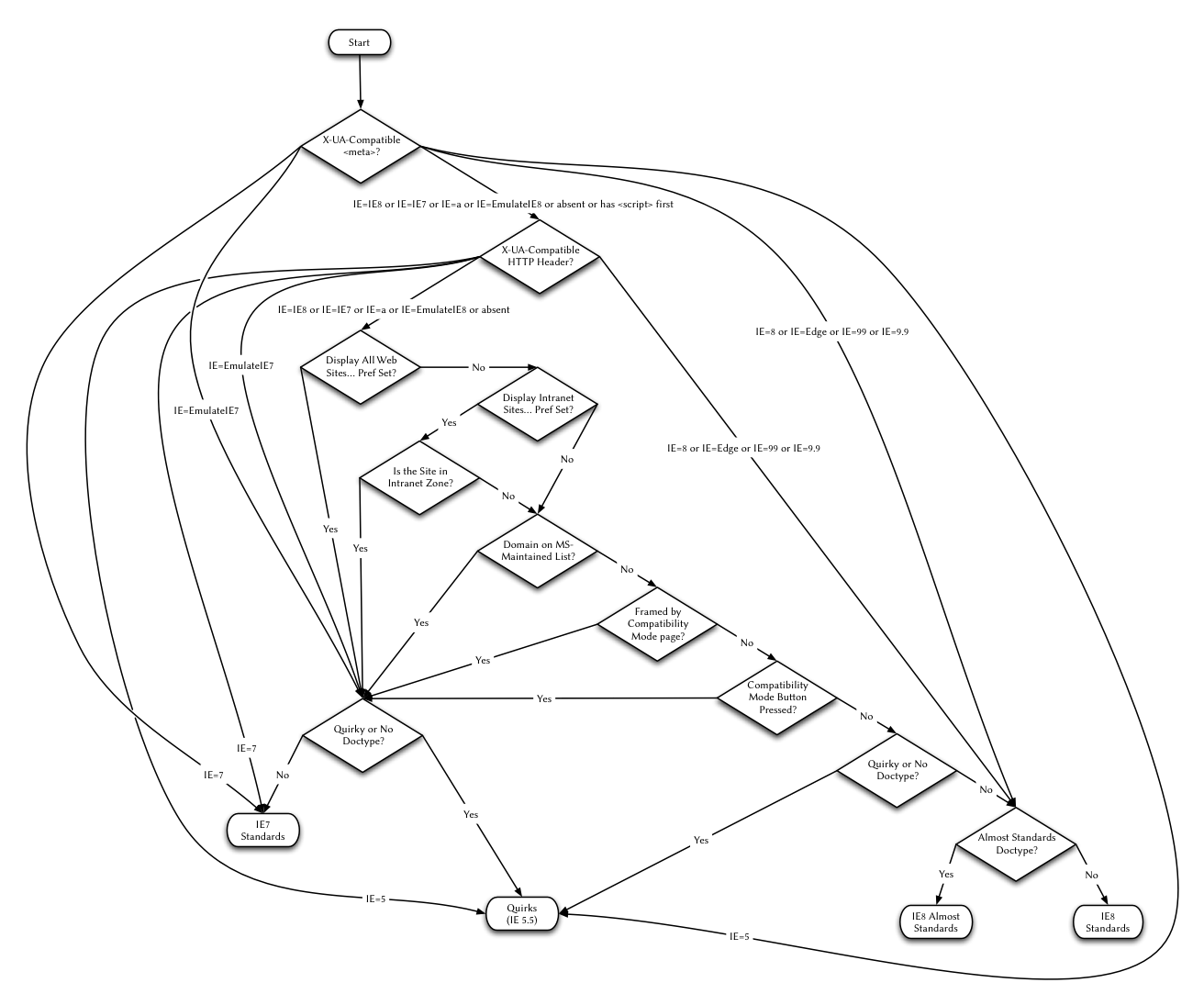
A List Apart once introduced that in addition to doctype, IE8 will use mode conversion based on meta elements as one of the factors in mode selection. (See Ian Hickson, David Baron, David Baron again, Robert O'Callahan and Maciej Stachowiak comments. )
IE8 has 4 modes: IE5.5 quirks mode, IE7 standards mode, IE8 quasi-standards mode and IE8 standards mode. The choice of mode depends on data from several sources: doctype, meta elements, HTTP headers, periodic download data from Microsoft, LAN domain, settings made by the user, settings made by the LAN administrator, and the mode of the parent frame (if any) Compatible with the address bar view button is triggered by the user. (For other apps embedded in the engine, the mode also depends on the embedded app.)
Fortunately, IE8 will generally use doctype sniffing like other browsers if:
Except for the two cases above regarding X-UA-Compatible, IE8 performs doctype sniffing like IE7. IE7 emulation is called compatibility view.
In the case of X-UA-Compatible, IE8 behaves completely differently from other browsers. I would like to see the Appendix or the flow chart in PDF and PNG formats on this page.
Unfortunately, without the X-UA-Compatible HTTP header or meta tag, even with the appropriate doctype, IE8 allows users to inadvertently downgrade the page from IE8's standards mode to IE7 mode, which is an emulation IE7 standards mode. Worse, LAN administrators can do this too. Microsoft can also blacklist all domain names you use.
To deal with these effects, doctype is not enough, you need X-UA-Compatible HTTP header and meta tag.
The following is a simple guide on how to select the X-UA-Compatible HTTP header or meta tag for new text/html documents that already have a doctype that triggers standards mode or quasi-standards mode in other browsers:
Doctype sniffing is a tag chowder-like approach to solving a tag chowder problem. Doctype sniffing is a heuristic designed after the release of the HTML4 and CSS2 specifications that distinguishes stale documents from documents that conform to behavior that their authors might have expected.
Occasionally it is suggested to use doctype sniffing on XML to schedule different processing, identify the vocabulary in use or activate features. This is a bad idea. Scheduling and vocabulary identification should be based on namespaces, while feature activation should be based on explicit processing instructions or elements.
The whole idea of well-formedness is to introduce DTD-free parsing of XML and promote doctype-free documentation. In the formal case where two XML documents have the same canonical form and the application processes them differently (and the difference is not due to a lack of choice to process external entities), the application may be broken. In practice, if two XML documents cause the same content to be reported (qnames ignored) to a SAX2
content handler and the application processes the documents differently, the application may be broken. Considering that as web authors you can't trust that everyone will use an XML processor that resolves extra entities to parse their pages (even though some browsers appear to do so because they map certain public identifiers to a truncated entity-defining DTD), Inserting doctypes into XML for the Web is pointless and often leads to cargo cultish habits. (You still use W3C Validator's DTD override feature to validate a DTD, although W3C Validator will say that the result is only temporarily valid. Or better yet, you can relax NG with Validate , it doesn't pollute the document referenced by the schema. ) Requiring a doctype in order to sniff is pretty stupid, even if that's the workaround in HTML practice. Also, when a lower-level specification defines two things as equal, a higher-level specification should not try to give them different meanings. Please consider . If you remove the public identifier, the same DTD is still specified, so doctype means the same as the previous doctype. Should they be sniffed differently? Can further theorize. Assume that a DTD called foobar.dtd is copied to example.com: . How to sniff this? It should mean the same thing. Even the entire DTD can be attached to the document. In other words, if there is #include "foo.h", you should not bind any black magic to the name foo.h, because it should allow copying the contents of foo.h into the document or copying foo.h into in bar.h and means #include "bar.h". The reason I'm not worried about HTML and SGML constructing the same parameters is that web browsers don't use real SGML parsers to parse HTML, so I don't think pretending to be SGML is useful. Anyway, if you’re not convinced yet, here’s W. Eliot Kimber’s article on the matter comp.text.sgml In the table below, quirk mode, standard mode and quasi-standard are represented by Q, S and A respectively. When the browser has only two modes, if the row height of the table cell is consistent with Mozilla's standard mode, the standard mode is marked "S". If the row height of the table cell is consistent with Mozilla's quasi-standard mode, , then it is marked as "A". Please note that XHTML served using the XML content model is rendered in XML mode. The purpose of this table is not to say that all doctypes in the table are reasonable choices for new pages. The purpose of this table is to show what data my recommendations are based on. The following abbreviation symbols are used for column headers: Appendix: How to handle some doctypes in text/html
Moziila's doctype sniffing code was significantly modified in October 2000, September 2001 and June 2002. The status of the Mozilla (and Netscape 6.x) build described in this document can be seen at ftp.mozilla.org as of 2000.10.19. This document does not cover how doctype sniffing works in Mozilla M18 (and Netscape 6.0 PR3). Safari's doctype sniffing code has also been significantly modified since the first public beta version. This document does not cover behavior earlier than version V73 also called 0.9.
The doctype sniffing code before Konqueror 3.5 seems to come from a very early version of Safari. Konqueror now matches Safari, and its doctype sniffing code comes from Mozilla.
As can be seen from the table, Opera's doctype sniffing is regularly changing from being similar to IE to being similar to Mozilla, although Opera 9.5 and 9.6 are on the way back. At the same time, Opera's quirks mode layout behavior has been switched from emulating IE6's quirks mode to Mozilla's quirks mode.
formats. Thanks Thanks to Simon Pieters, Simon Pieters and Anne van Kesteren for helping me correct the pattern sheets for various Opera versions and for their comments. Thanks to Simon Pieters for creating another IE8 flowchart.
 The computer has Internet access but the browser cannot open the web page
The computer has Internet access but the browser cannot open the web page
 What does browser mean
What does browser mean
 Browser compatibility
Browser compatibility
 How to solve the problem of garbled characters when opening a web page
How to solve the problem of garbled characters when opening a web page
 What is the basic concept of artificial intelligence
What is the basic concept of artificial intelligence
 lte
lte
 insert statement usage
insert statement usage
 How to get the input number in java
How to get the input number in java








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




{kind=link}